¿Qué es el Generador de modelos y cómo funciona?
El Generador de modelos de ML.NET es una extensión gráfica intuitiva de Visual Studio para compilar, entrenar e implementar modelos de Machine Learning personalizados. Usa el aprendizaje automático automatizado (AutoML) para explorar diferentes algoritmos y configuraciones de aprendizaje automático para ayudarle a encontrar el que mejor se adapte a su escenario.
Para usar el Generador de modelos no se necesita experiencia previa con el aprendizaje automático. Lo único que se necesita son algunos datos y un problema para resolver. El Generador de modelos genera el código para agregar el modelo a la aplicación de .NET.

Creación de un proyecto de Model Builder
Al iniciar Model Builder por primera vez, le pide que asigne un nombre al proyecto y, a continuación, crea un archivo de configuración mbconfig dentro del proyecto. El archivo mbconfig realiza el seguimiento de todo lo que hace en Model Builder para permitirle volver a abrir la sesión.
Después del entrenamiento, se generan tres archivos en el archivo *.mbconfig:
- Model.consumption.cs: este archivo contiene los esquemas
ModelInputyModelOutput, así como la funciónPredictgenerada para consumir el modelo. - Model.training.cs: este archivo contiene la canalización de entrenamiento (transformaciones de datos, algoritmos, hiperparámetros de algoritmo) elegida por Model Builder para entrenar el modelo. Puede usar esta canalización para volver a entrenar el modelo.
- Model.zip: se trata de un archivo ZIP serializado que representa el modelo de ML.NET entrenado.
Al crear el archivo mbconfig, se le pedirá un nombre. Este nombre se aplica a los archivos de consumo, entrenamiento y modelo. En este caso, el nombre que se usa es Model.
Escenario
Se pueden incorporar muchos escenarios diferentes al Generador de modelos a fin de generar un modelo de Machine Learning para la aplicación.
Un escenario es una descripción del tipo de predicción que se quiere realizar usando los datos. Por ejemplo:
- Predecir el volumen futuro de ventas de productos en función de los datos históricos de ventas.
- Clasifique las opiniones como positivas o negativas en función de las opiniones de los clientes.
- Detecte si una transacción bancaria es fraudulenta.
- Dirija los problemas de comentarios de los clientes al equipo correcto de su empresa.
Cada escenario se asigna a una tarea de aprendizaje automático diferente, que incluye:
| Tarea | Escenario |
|---|---|
| Clasificación binaria | Clasificación de los datos |
| Clasificación multiclase | Clasificación de los datos |
| Clasificación de imágenes | Clasificación de imágenes |
| Clasificación de textos | Clasificación de textos |
| Regresión | Predicción de valores |
| Recomendación | Recomendación |
| Previsión | Previsión |
Por ejemplo, el escenario de clasificación de opiniones como positivas o negativas se correspondería a la tarea de clasificación binaria.
Para obtener más información sobre las distintas tareas de ML admitidas por ML.NET, vea Tareas de aprendizaje automático en ML.NET.
¿Qué escenario de aprendizaje automático es el más adecuado en cada caso?
En el Generador de modelos, debe seleccionar un escenario. El tipo de escenario depende del tipo de predicción que intenta realizar.
Tabular
Clasificación de datos
La clasificación se utiliza para clasificar los datos en categorías.
Entrada de ejemplo
Salida de ejemplo
| Longitud del sépalo | Ancho del sépalo | Longitud del pétalo | Ancho del pétalo | Especie |
|---|---|---|---|---|
| 5,1 | 3,5 | 1.4 | 0,2 | setosa |
| Especie prevista |
|---|
| setosa |
Predicción de valores
La predicción de valores, que se corresponde a la tarea de regresión, se usa para predecir números.
Entrada de ejemplo
Salida de ejemplo
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| Tarifa prevista |
|---|
| 4.5. |
Recomendación
El escenario de recomendaciones predice una lista de elementos sugeridos para un usuario determinado, en función de la similitud y la diferencia entre los usuarios de otros usuarios.
Puede usar el escenario de recomendación cuando tenga un conjunto de usuarios y un conjunto de "productos", como artículos para comprar, películas, libros o programas de TV, junto con un conjunto de "clasificaciones" de los usuarios de esos productos.
Entrada de ejemplo
Salida de ejemplo
| UserId | ProductId | Rating |
|---|---|---|
| 1 | 2 | 4,2 |
| Clasificación prevista |
|---|
| 4.5. |
Previsión
El escenario de previsión usa datos históricos con un componente de serie temporal o estacional.
Puede usar el escenario de previsión para predecir la demanda o la venta de un producto.
Entrada de ejemplo
Salida de ejemplo
| Fecha | Cant. de venta |
|---|---|
| 1/1/1970 | 1000 |
| Previsión de 3 días |
|---|
| [1000,1001,1002] |
Visión informática
Clasificación de la imagen
La clasificación de imágenes se usa para identificar imágenes de distintas categorías. Por ejemplo, diferentes tipos de terreno, animales o defectos de fabricación.
Puede usar el escenario de clasificación de la imagen si tiene un conjunto de imágenes y desea clasificar las imágenes en distintas categorías.
Entrada de ejemplo
Salida de ejemplo

| Etiqueta prevista |
|---|
| Perro |
Detección de objetos
La detección de objetos se usa para ubicar y categorizar entidades dentro de las imágenes. Por ejemplo, para buscar e identificar automóviles y personas en una imagen.
Puede usar la detección de objetos cuando las imágenes contengan varios objetos de tipos diferentes.
Entrada de ejemplo
Salida de ejemplo

Procesamiento de lenguaje natural
Clasificación de textos
La clasificación de texto clasifica la entrada de texto sin formato.
El escenario de clasificación de texto se puede usar si tiene un conjunto de documentos o comentarios y quiere clasificarlos en distintas categorías.
Entrada de ejemplo
Salida de ejemplo
| Revisar |
|---|
| ¡Cómo me gusta este filete! |
| Opinión |
|---|
| Positivo |
Entorno
Puede entrenar el modelo de Machine Learning localmente en el equipo o en la nube en Azure, en función del escenario.
Al entrenar localmente, se trabaja dentro de las restricciones de los recursos del equipo (CPU, memoria y disco). Al entrenar en la nube, puede escalar verticalmente los recursos para satisfacer las demandas de su escenario, especialmente para grandes conjuntos de valores.
| Escenario | CPU local | GPU local | Azure |
|---|---|---|---|
| Clasificación de datos | ✔️ | ❌ | ❌ |
| Predicción de valores | ✔️ | ❌ | ❌ |
| Recomendación | ✔️ | ❌ | ❌ |
| Previsión | ✔️ | ❌ | ❌ |
| Clasificación de imágenes | ✔️ | ✔️ | ✔️ |
| Detección de objetos | ❌ | ❌ | ✔️ |
| Clasificación de textos | ✔️ | ✔️ | ❌ |
Data
Una vez que ha elegido el escenario, Model Builder pide que se proporcione un conjunto de datos. Los datos se usan para entrenar, evaluar y elegir el mejor modelo para el escenario.
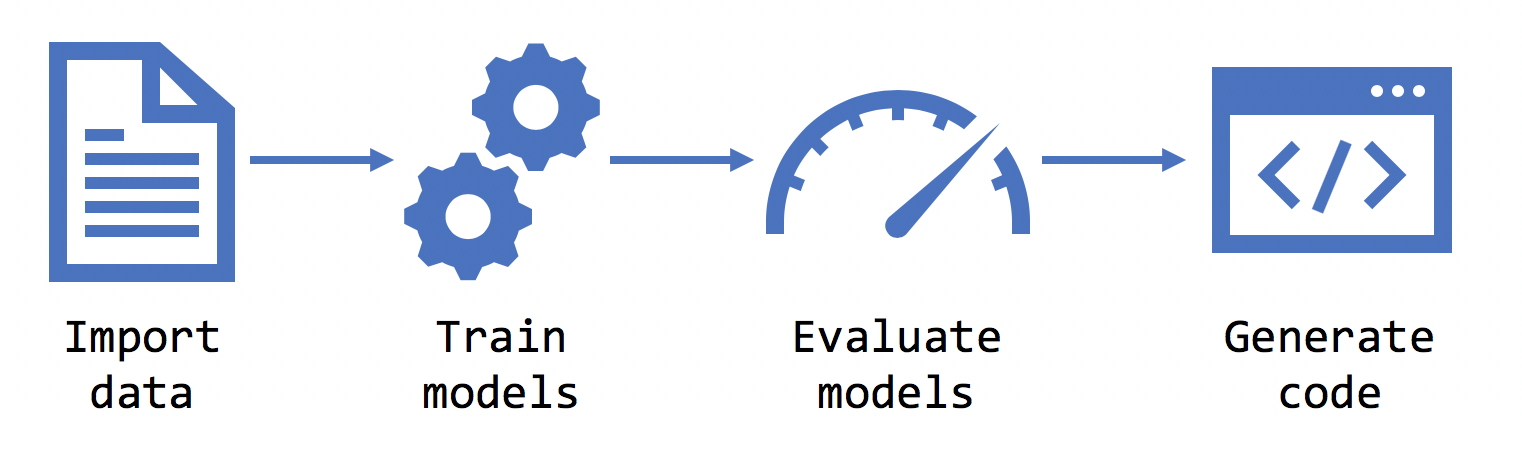
Model Builder admite conjuntos de datos en formatos de base de datos .tsv, .csv, .txt y SQL Database. Si tiene un archivo .txt, las columnas se deben separar con ,, ; o \t.
Si el conjunto de archivos se compone de imágenes, los tipos de archivo admitidos son .jpg y .png.
Para obtener más información, vea Carga de datos de entrenamiento en el Generador de modelos.
Selección del resultado que se va a predecir (etiqueta)
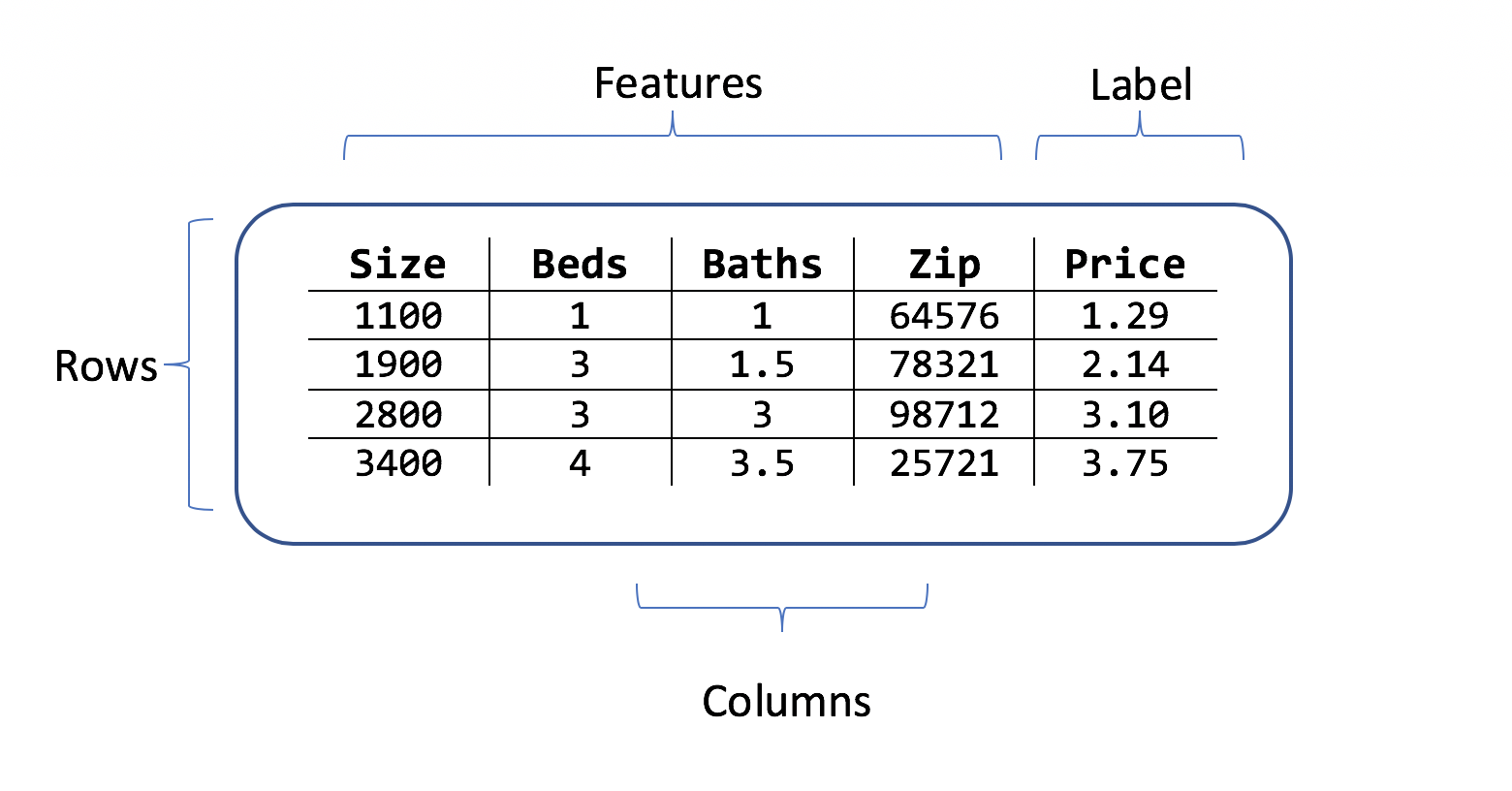
Un conjunto de datos es una tabla de filas de ejemplos de entrenamiento y columnas de atributos. Cada fila tiene:
- una etiqueta (el atributo que se quiere predecir)
- características (atributos que se usan como entradas para predecir la etiqueta)
En el escenario de predicción del precio de las viviendas, las características podrían ser:
- Los metros cuadrados de la vivienda.
- El número de dormitorios y baños.
- El código postal.
La etiqueta es el precio histórico de la vivienda para esa fila de valores de metros cuadrados, baños y dormitorios y el código postal.
Conjuntos de datos de ejemplo
Si aún no tiene datos propios, pruebe uno de estos conjuntos de datos:
| Escenario | Ejemplo | Datos | Etiqueta | Características |
|---|---|---|---|---|
| Clasificación | Predicción de anomalías de ventas | datos de ventas de productos | Ventas de productos | Mes |
| Predicción de sentimiento de comentarios de sitios web | datos de comentarios de sitio web | Etiqueta (1 si la opinión es negativa, 0 si es positiva) | Comentario, año | |
| Predicción de transacciones de tarjetas de crédito fraudulentas | datos de tarjetas de crédito | Clase (1 si es fraudulenta, en caso contrario, 0) | Cantidad, V1-V28 (características anónimas) | |
| Predecir el tipo de problema en un repositorio de GitHub | datos de problemas de GitHub | Área | Título, descripción | |
| Predicción de valores | Predicción del precio de los taxis | datos de carreras de taxi | Carrera | Tiempo de viaje, distancia |
| Clasificación de la imagen | Predicción de la categoría de una flor | imágenes de flores | El tipo de flor: margarita, diente de león, rosas, girasoles o tulipanes | Los propios datos de la imagen |
| Recomendación | Predicción de películas que le gusten a alguien | clasificaciones de películas | Usuarios, películas | Clasificaciones |
Entrenamiento
Una vez que se seleccionan el escenario, el entorno, los datos y la etiqueta, el Generador de modelos entrena el modelo.
¿Qué es el entrenamiento?
El entrenamiento es un proceso automático mediante el cual el Generador de modelos enseña al modelo a responder a preguntas del escenario. Una vez entrenado, el modelo puede realizar predicciones con datos de entrada que no ha visto antes. Por ejemplo, si está prediciendo los precios de la vivienda y se pone en el mercado un nuevo inmueble, puede predecir su precio de venta.
Dado que el Generador de modelos usa aprendizaje automático automatizado (AutoML), no requiere ninguna entrada ni ajuste por parte del usuario durante el entrenamiento.
¿Durante cuánto tiempo debe entrenarse?
El generador de modelos usa AutoML para explorar varios modelos y encontrar el mejor modelo de rendimiento.
Los períodos de entrenamiento más largos permiten a AutoML explorar más modelos con una mayor variedad de opciones de configuración.
En la tabla siguiente se resume el tiempo promedio necesario para obtener un buen rendimiento en un conjunto de conjuntos de valores de ejemplo, en un equipo local.
| Tamaño del conjunto de datos | Promedio de tiempo para entrenar |
|---|---|
| 0-10 MB | 10 s |
| 10-100 MB | 10 min |
| 100-500 MB | 30 min |
| 500-1 GB | 60 min |
| 1 GB o más | 3 horas o más |
Estos números son solo una guía. La duración exacta del entrenamiento depende de varios factores:
- El número de características (columnas) que se usan como entrada para el modelo.
- El tipo de columnas.
- La tarea de ML.
- El rendimiento de la CPU, el disco y la memoria de la máquina usada para el entrenamiento.
Por lo general, se aconseja usar más de 100 filas, ya que es posible que los conjuntos de datos con una cantidad menor no generen ningún resultado.
Evaluate
La evaluación es el proceso por el que se mide el grado de calidad del modelo. El Generador de modelo usa el modelo entrenado para realizar predicciones con nuevos datos de prueba y luego mide la calidad de las predicciones.
El Generador de modelos divide los datos de entrenamiento en un conjunto de entrenamiento y un conjunto de prueba. Los datos de entrenamiento (80 %) se usan para entrenar el modelo y los datos de prueba (20 %) se incluyen para evaluar el modelo.
¿Cómo puedo interpretar el rendimiento de mi modelo?
Un escenario se asigna a una tarea de aprendizaje automático. Cada tarea de ML tiene su propio conjunto de métricas de evaluación.
Predicción de valores
La métrica predeterminada para los problemas de predicción de valores es RSquared, y el valor de RSquared oscila entre 0 y 1. 1 es el mejor valor posible o, en otras palabras, cuanto más se acerque el valor de RSquared a 1, mejor será el rendimiento del modelo.
Otras métricas notificadas, como pérdida absoluta, pérdida al cuadrado y pérdida RMS son métricas adicionales, que pueden usarse para comprender el rendimiento del modelo y compararlo con otros modelos de predicción de valores.
Clasificación (2 categorías)
La métrica predeterminada para los problemas de clasificación es la precisión. La precisión define la proporción de predicciones correctas que realiza el modelo en el conjunto de datos de prueba. Cuanto más cerca esté del 100 % o 1.0, mejor será el modelo.
Otras métricas notificadas, como AUC (área bajo la curva), que mide la tasa de positivos verdaderos frente a la tasa de falsos positivos, deben ser superiores a 0,50 para que los modelos sean aceptables.
Se pueden usar métricas adicionales como la puntuación F1 para controlar el equilibrio entre la precisión y la coincidencia.
Clasificación (3 categorías)
La métrica predeterminada para la clasificación multiclase es la microprecisión. Cuanto más se acerque la microprecisión al 100 % o 1,0, mejor será el modelo.
Otra métrica importante para la clasificación multiclase es la macroprecisión, que, de forma similar a la de la microprecisión, cuanto más se acerque a 1,0 mejor será el modelo. Una buena manera de imaginarse estos dos tipos de precisión es el siguiente:
- Microprecisión: ¿con qué frecuencia se clasifica una incidencia entrante en el equipo adecuado?
- Macroprecisión: para un equipo promedio, ¿con qué frecuencia es correcta una incidencia entrante para su equipo?
Más información sobre las métricas de evaluación
Para obtener más información, vea Métricas de evaluación de modelos.
Mejora
Si la puntuación de rendimiento del modelo no es tan buena como se quiere que sea, se puede:
Entrenar durante más tiempo. Con más tiempo, el motor de aprendizaje automático automatizado experimenta con más algoritmos y configuraciones.
Agregar más datos. A veces la cantidad de datos no es suficiente para entrenar un modelo de Machine Learning de alta calidad. Esto es especialmente cierto en el caso de conjuntos de datos que tienen un número de ejemplos menor.
Equilibrar los datos. En las tareas de clasificación, asegúrese de que el conjunto de entrenamiento esté equilibrado entre las categorías. Por ejemplo, si tiene cuatro clases de 100 ejemplos de entrenamiento y las dos primeras (etiqueta1 y etiqueta2) se usan para 90 registros, pero las otras dos (etiqueta3 y etiqueta4) solo se usan en los 10 registros restantes, la falta de datos equilibrados puede hacer que el modelo se esfuerce por predecir correctamente etiqueta3 o etiqueta4.
Consumo
Después de la fase de evaluación, el Generador de modelos genera un archivo de modelo y el código que se puede usar para agregar el modelo a la aplicación. Los modelos de ML.NET se guardan como un archivo zip. El código para cargar y usar el modelo se agrega como un nuevo proyecto a la solución. El Generador de modelos también agrega una aplicación de consola de ejemplo que se puede ejecutar para ver el modelo en acción.
Además, Model Builder ofrece la opción de crear proyectos que consumen el modelo. Actualmente, Model Builder creará los proyectos siguientes:
- Aplicación de consola: crea una aplicación de consola de .NET para realizar predicciones a partir del modelo.
- API web: crea una API web de ASP.NET Core que permite consumir el modelo por Internet.
A continuación
Instalar la extensión de Visual Studio de Model Builder.
Pruebe la predicción de precios o cualquier escenario de regresión.