Tutorial: Creación de clústeres de Apache Hadoop a petición en HDInsight mediante Azure Data Factory
En este tutorial, aprenderá a crear un clúster de Apache Hadoop a petición en Azure HDInsight mediante Azure Data Factory. A continuación, puede usar canalizaciones en Azure Data Factory para ejecutar trabajos de Hive y eliminar el clúster. Al final de este tutorial, aprenderá a aplicar operationalize la ejecución de un trabajo de macrodatos donde la creación del clúster, la ejecución del trabajo y la eliminación del clúster tienen lugar según una programación.
En este tutorial se describen las tareas siguientes:
- Creación de una cuenta de Azure Storage
- Conocer la actividad de Azure Data Factory
- Crear una factoría de datos mediante Azure Portal
- Crear servicios vinculados
- Crear una canalización
- Desencadenar una canalización
- Supervisión de una canalización
- Comprobación del resultado
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Prerrequisitos
Instalación del módulo Az de PowerShell.
Una entidad de servicio de Microsoft Entra. Una vez que haya creado la entidad de servicio, asegúrese de recuperar el identificador de la aplicación y la clave de autenticación siguiendo las instrucciones del artículo vinculado. Necesitará estos valores más adelante en el tutorial. Asimismo, asegúrese de que la entidad de servicio es miembro del rol de colaborador de la suscripción o del grupo de recursos en el que se crea el clúster. Para obtener instrucciones para recuperar los valores necesarios y asignar los roles adecuados, vea Crear una entidad de servicio de Microsoft Entra.
Creación de objetos de Azure previos
En esta sección, puede crear diversos objetos que se usarán para el clúster de HDInsight que cree a petición. La cuenta de almacenamiento creada contendrá el script de HiveSQL de ejemplo, partitionweblogs.hql, que se usa para simular un trabajo de Apache Hive de ejemplo que se ejecuta en el clúster.
En esta sección se usa un script de Azure PowerShell para crear la cuenta de almacenamiento y copiar los archivos necesarios en ella. El script de ejemplo de Azure PowerShell de esta sección realiza las siguientes tareas:
- Inicia sesión en Azure.
- Crea un grupo de recursos de Azure.
- Crea una cuenta de Azure Storage.
- Crea un contenedor de blobs en la cuenta de almacenamiento.
- Copia el ejemplo de script de HiveQL (partitionweblogs.hql) en el contenedor de blobs. El ejemplo de script ya está disponible en otro contenedor de blobs público. El script de PowerShell siguiente realiza una copia de estos archivos en la cuenta de Azure Storage que crea.
Creación de una cuenta de almacenamiento y copia de archivos
Importante
Especifique los nombres del grupo de recursos de Azure y la cuenta de Azure Storage que creará el script. Anote el nombre del grupo de recursos, el nombre de la cuenta de almacenamiento y la clave de la cuenta de almacenamiento que genere el script. Los necesitará en la siguiente sección.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Comprobación de una cuenta de almacenamiento
- Inicie sesión en Azure Portal.
- Desde la izquierda, vaya a Todos los servicios>General>Grupos de recursos.
- Seleccione el nombre del grupo de recursos que creó en el script de PowerShell. Utilice el filtro si se muestran demasiados grupos de recursos.
- En la vista Información general verá un recurso en la lista, a menos que comparta el grupo de recursos con otros proyectos. Ese recurso es la cuenta de almacenamiento con el nombre que especificó anteriormente. Escriba el nombre de la cuenta de almacenamiento.
- Seleccione el icono Contenedores.
- Seleccione el contenedor adfgetstarted. Verá una carpeta llamada
hivescripts. - Abra la carpeta y asegúrese de que contiene el ejemplo de archivo de script, partitionweblogs.hql.
Conocer la actividad de Azure Data Factory
Azure Data Factory organiza y automatiza el movimiento y la transformación de datos. Azure Data Factory puede crear un clúster de Hadoop de HDInsight Just-In-Time para procesar un segmento de datos de entrada y eliminar el clúster cuando el procesamiento está completo.
En Azure Data Factory, una factoría de datos puede tener una o varias canalizaciones de datos. Una canalización de datos consta de una o varias actividades. Existen dos tipos de actividades:
- Actividades de movimiento de datos. Las actividades de movimiento de datos se usan para mover datos de un almacén de datos de origen a un almacén de datos de destino.
- Actividades de transformación de datos. Los actividades de transformación de datos se usan para procesar o transformar datos. La actividad de Hive de HDInsight es una de las actividades de transformación de datos compatibles con Data Factory. En este tutorial se usa la actividad de transformación de Hive.
En este artículo, se configura la actividad de Hive para crear un clúster Hadoop de HDInsight a petición. Cuando se ejecuta la actividad para procesar datos, esto es lo que ocurre:
Se crea automáticamente un clúster de Hadoop de HDInsight para que just-in-time procese el segmento.
Los datos de entrada se procesan mediante la ejecución de un script de HiveQL en el clúster. En este tutorial, el script de HiveQL asociado a la actividad de Hive realiza las siguientes acciones:
- Usa la tabla existente (hivesampletable) para crear otra tabla HiveSampleOut.
- Rellena la tabla HiveSampleOut solo con columnas específicas de la hivesampletable original.
El clúster de Hadoop de HDInsight se elimina cuando se ha completado el procesamiento y el clúster está inactivo durante el período configurado (valor timeToLive). Si el siguiente segmento de datos está disponible para su procesamiento con en este tiempo de inactividad timeToLive, el mismo clúster se usa para procesar el segmento.
Crear una factoría de datos
Inicie sesión en Azure Portal.
En el menú de la izquierda, vaya a
+ Create a resource>Analytics>Data Factory.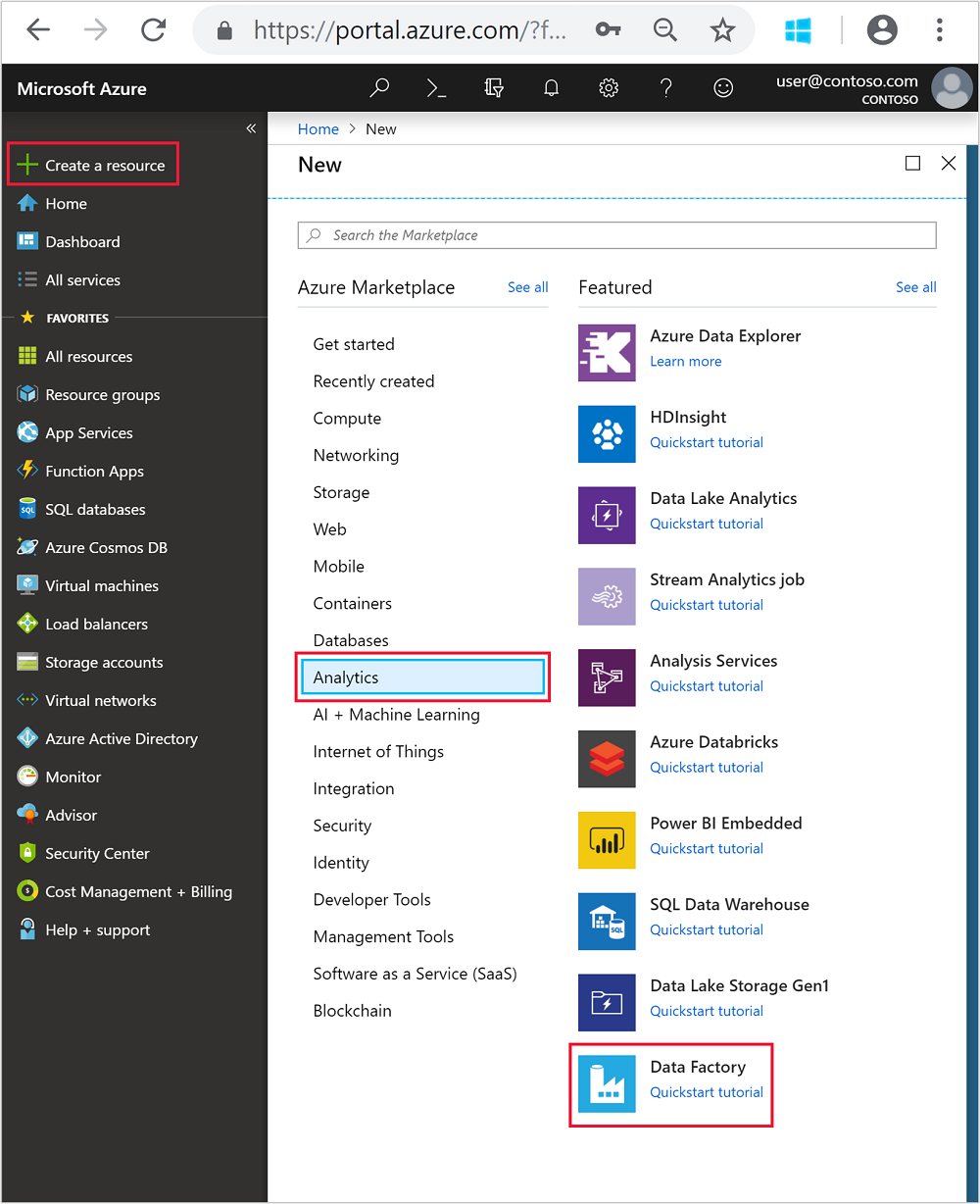
Escriba o seleccione los siguientes valores del icono Nueva factoría de datos:
Propiedad Valor Nombre Escriba un nombre para la factoría de datos. Este nombre debe ser único globalmente. Versión Déjela en V2. Subscription Seleccione su suscripción a Azure. Resource group Seleccione el grupo de recursos que ha creado mediante el script de PowerShell. Location La ubicación se establece automáticamente en la ubicación que ha especificado anteriormente durante la creación del grupo de recursos. En este tutorial, la ubicación se establece en Este de EE. UU. Habilitar GIT Desactive esta casilla. 
Seleccione Crear. La creación de una factoría de datos podría tardar entre dos y cuatro minutos.
Una vez creada la factoría de datos, recibirá una notificación Implementación correcta con el botón Ir al recurso. Seleccione Ir al recurso para abrir la vista predeterminada de Data Factory.
Seleccione Crear y supervisar para iniciar el portal de creación y supervisión de Azure Data Factory.
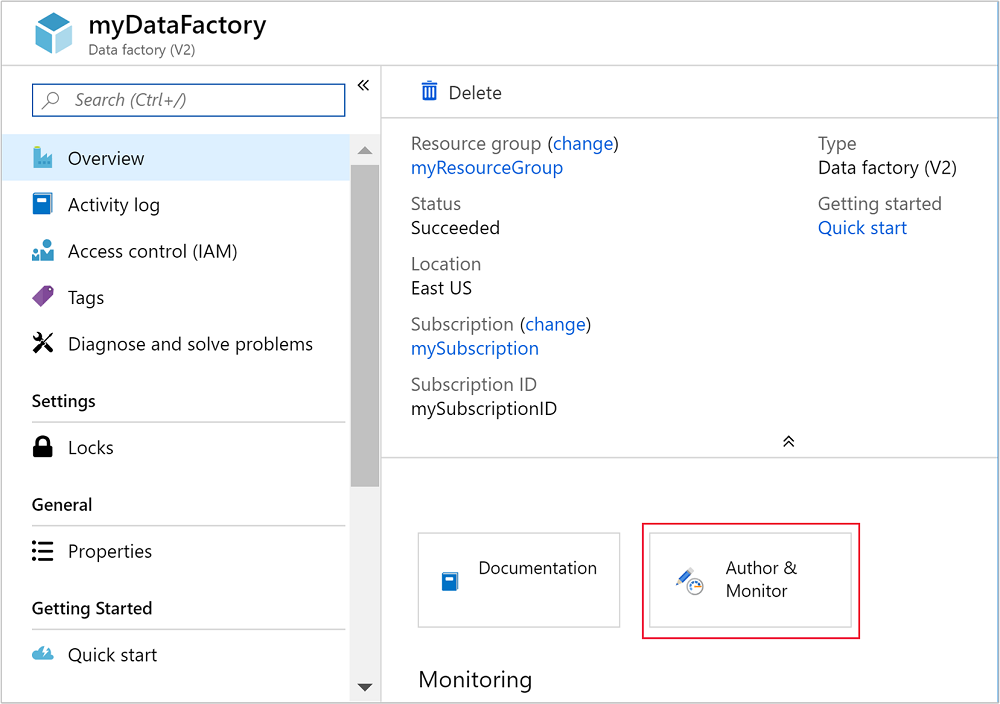
Crear servicios vinculados
En esta sección, puede crear dos servicios vinculados dentro de su factoría de datos.
- Un servicio vinculado a Azure Storage que vincule una cuenta de Azure Storage con la factoría de datos. Este almacenamiento lo usa el clúster HDInsight a petición. También contiene el script de Hive que se ejecuta en el clúster.
- Un servicio vinculado de HDInsight a petición. Azure Data Factory permite crear automáticamente un clúster de HDInsight y ejecutar el script de Hive. A continuación, elimina el clúster de HDInsight si el clúster está inactivo durante un tiempo configurado previamente.
Creación de un servicio vinculado de Azure Storage
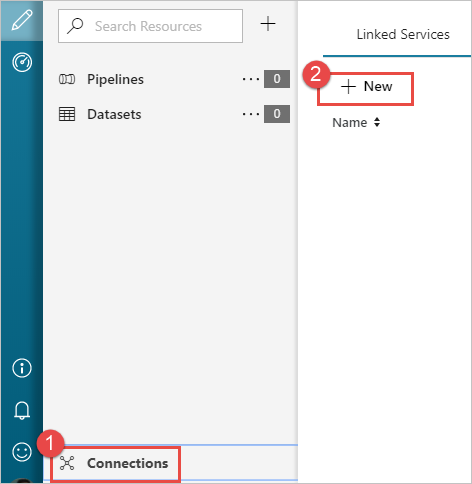
En el panel izquierdo de la página de introducción, seleccione el icono Autor.

Seleccione Conexiones en la esquina inferior izquierda de la ventana y seleccione + Nuevo.
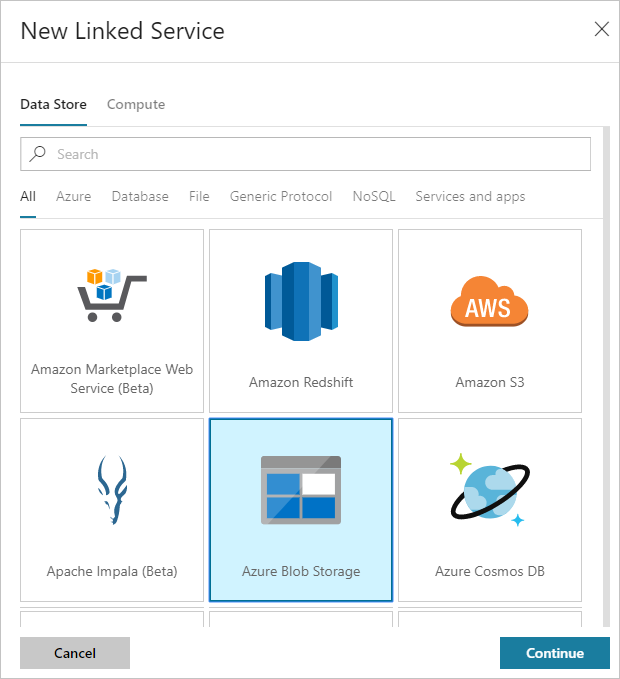
En el cuadro de diálogo Nuevo servicio vinculado, seleccione Azure Blob Storage y después Continuar.
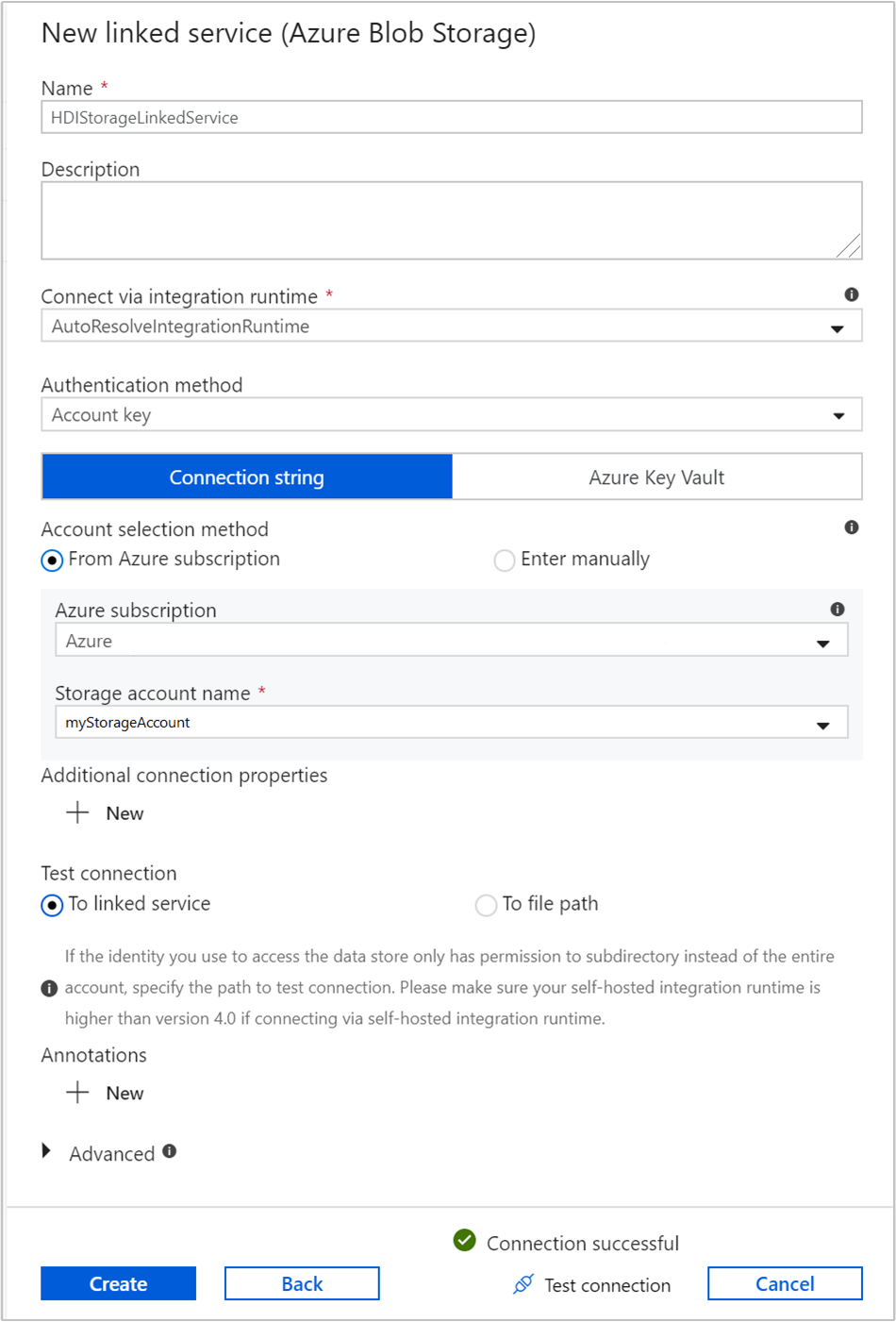
Proporcione los siguientes valores del servicio vinculado de almacenamiento:
Propiedad Valor Nombre Escriba HDIStorageLinkedService.Suscripción de Azure Seleccione la suscripción en la lista desplegable. Nombre de la cuenta de almacenamiento Seleccione la cuenta de Azure Storage que creó como parte del script de PowerShell. Seleccione Prueba de conexión y, si es correcta, seleccione Crear.
Creación de un servicio vinculado de HDInsight a petición
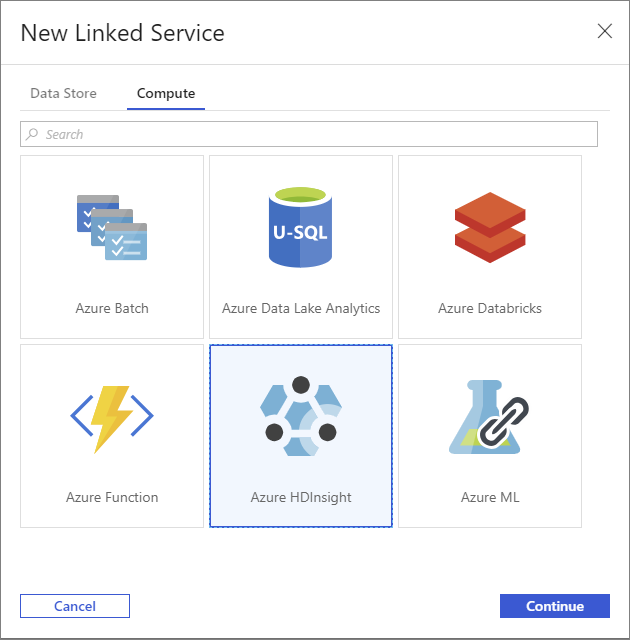
Seleccione el botón + New (+ Nuevo) una vez más para crear otro servicio vinculado.
En la ventana Nuevo servicio vinculado, seleccione la pestaña Proceso.
Seleccione Azure HDInsight y, a continuación, Continuar.
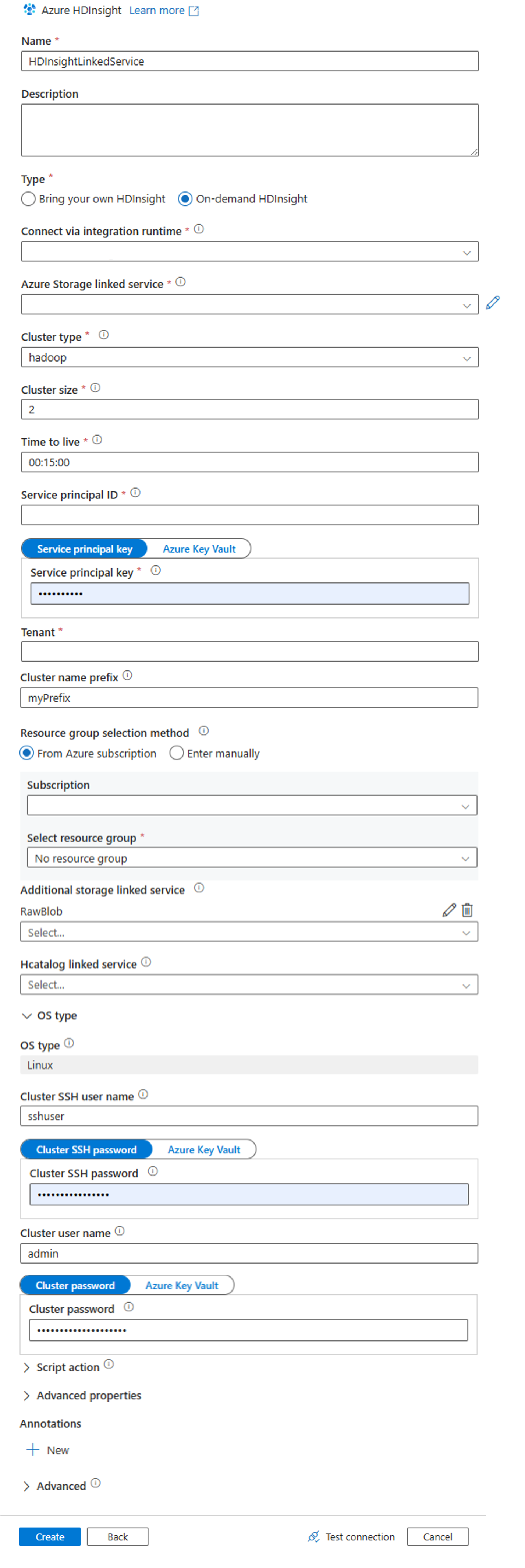
En la ventana Nuevo servicio vinculado, escriba los siguientes valores y deje el resto como valor predeterminado:
Propiedad Valor Nombre Escriba HDInsightLinkedService.Tipo Seleccione HDInsight a petición. Servicio vinculado de Azure Storage Seleccione HDIStorageLinkedService.Tipo de clúster Seleccione hadoop Período de vida Proporcione la duración que desea que tenga la disponibilidad del clúster de HDInsight antes de eliminarse automáticamente Id. de entidad del servicio Proporcione el identificador de aplicación de la entidad de servicio de Microsoft Entra que creó como parte de los requisitos previos. Clave de entidad de servicio Proporcione la clave de autenticación para la entidad de servicio de Microsoft Entra. Prefijo del nombre del clúster Proporcione un valor que se agregará como prefijo a todos los tipos de clúster creados por la factoría de datos. Subscription Seleccione la suscripción en la lista desplegable. Selección de un grupo de recursos Seleccione el grupo de recursos que ha creado como parte del script de PowerShell que ha usado anteriormente. Nombre de usuario de SSH del clúster o tipo de SO Especifique un nombre de usuario de SSH, habitualmente sshuser.Contraseña de SSH del clúster o tipo de SO Proporcione una contraseña para el usuario de SSH Nombre de usuario de clúster o tipo de SO Escriba un nombre de usuario de clúster, habitualmente admin.Contraseña del clúster o tipo de SO Proporcione una contraseña para el usuario del clúster. Seleccione Crear.
Crear una canalización
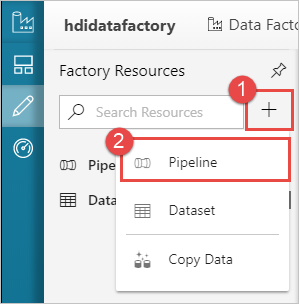
Haga clic en el botón ++ (Más) y seleccione Pipeline (Canalización).
En el cuadro de herramientas Actividades, expanda HDInsight y arrastre la actividad Hive en la superficie del diseñador de canalizaciones. En la pestaña General, proporcione un nombre para la actividad.
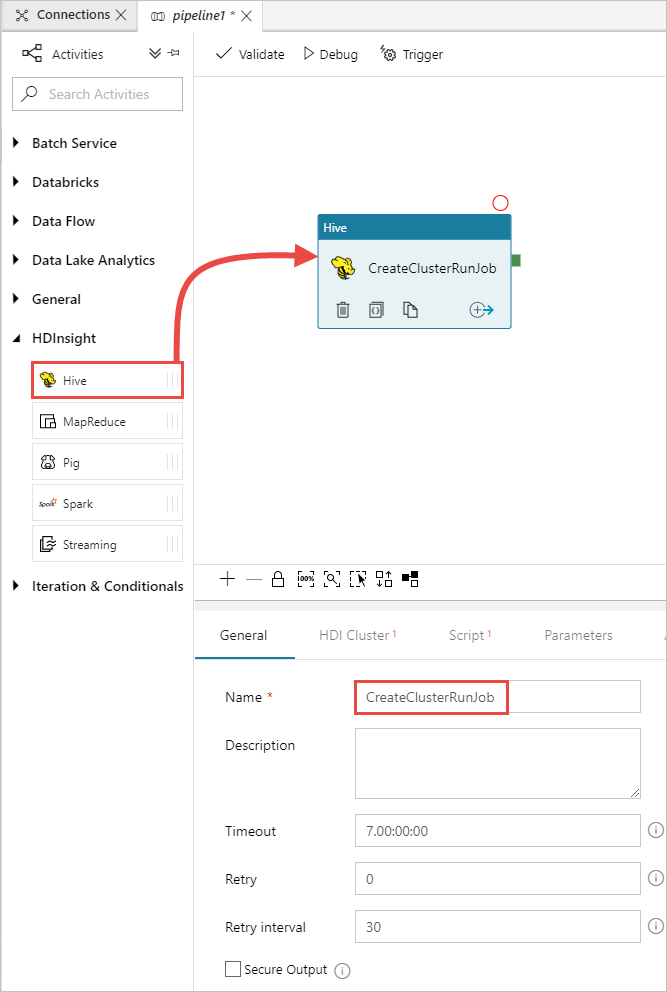
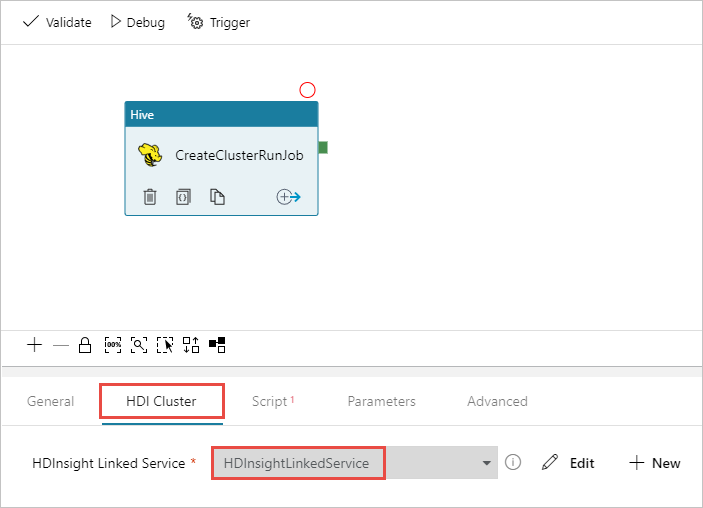
Para asegurarse de que tiene seleccionada la actividad de Hive, seleccione la pestaña HDI Cluster (Clúster de Hive). Luego, en la lista desplegable HDInsight Linked Service (Servicio vinculado de HDInsight), seleccione el servicio vinculado que creó anteriormente, HDInsightLinkedService, para HDInsight.
Seleccione la pestaña Script y complete los siguientes pasos:
En Servicio vinculado de script, seleccione HDIStorageLinkedService en la lista desplegable. Este valor es el servicio vinculado de almacenamiento que ha creado anteriormente.
En Ruta de acceso del archivo, seleccione Examinar almacenamiento y vaya a la ubicación donde el ejemplo de script de Hive se encuentra disponible. Si ha ejecutado el script de PowerShell anteriormente, esta ubicación debe ser
adfgetstarted/hivescripts/partitionweblogs.hql.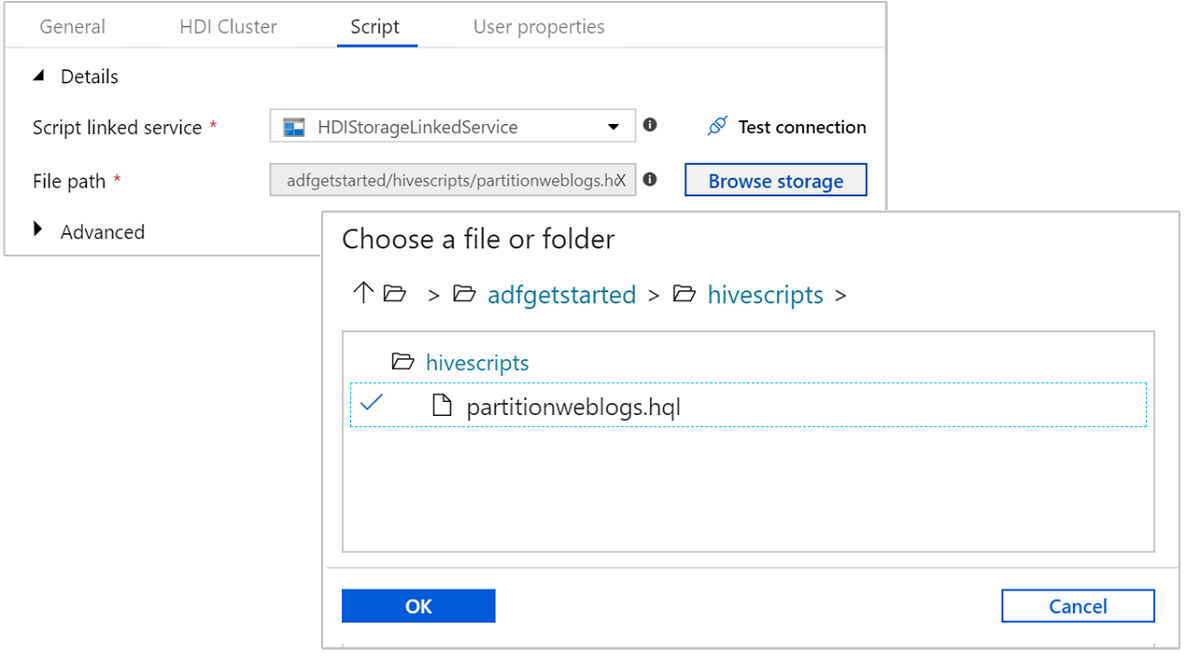
En Opciones avanzadas>Parámetros, seleccione
Auto-fill from script. Esta opción busca cualquier parámetro en el script de Hive que necesite valores en tiempo de ejecución.En el cuadro de texto valor, agregue la carpeta existente en el formato
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. La ruta de acceso distingue mayúsculas de minúsculas. Esta es la ruta de acceso donde se almacenará la salida del script. El esquemawasbses necesario porque ahora las cuentas de almacenamiento tienen habilitada de forma predeterminada la transferencia segura.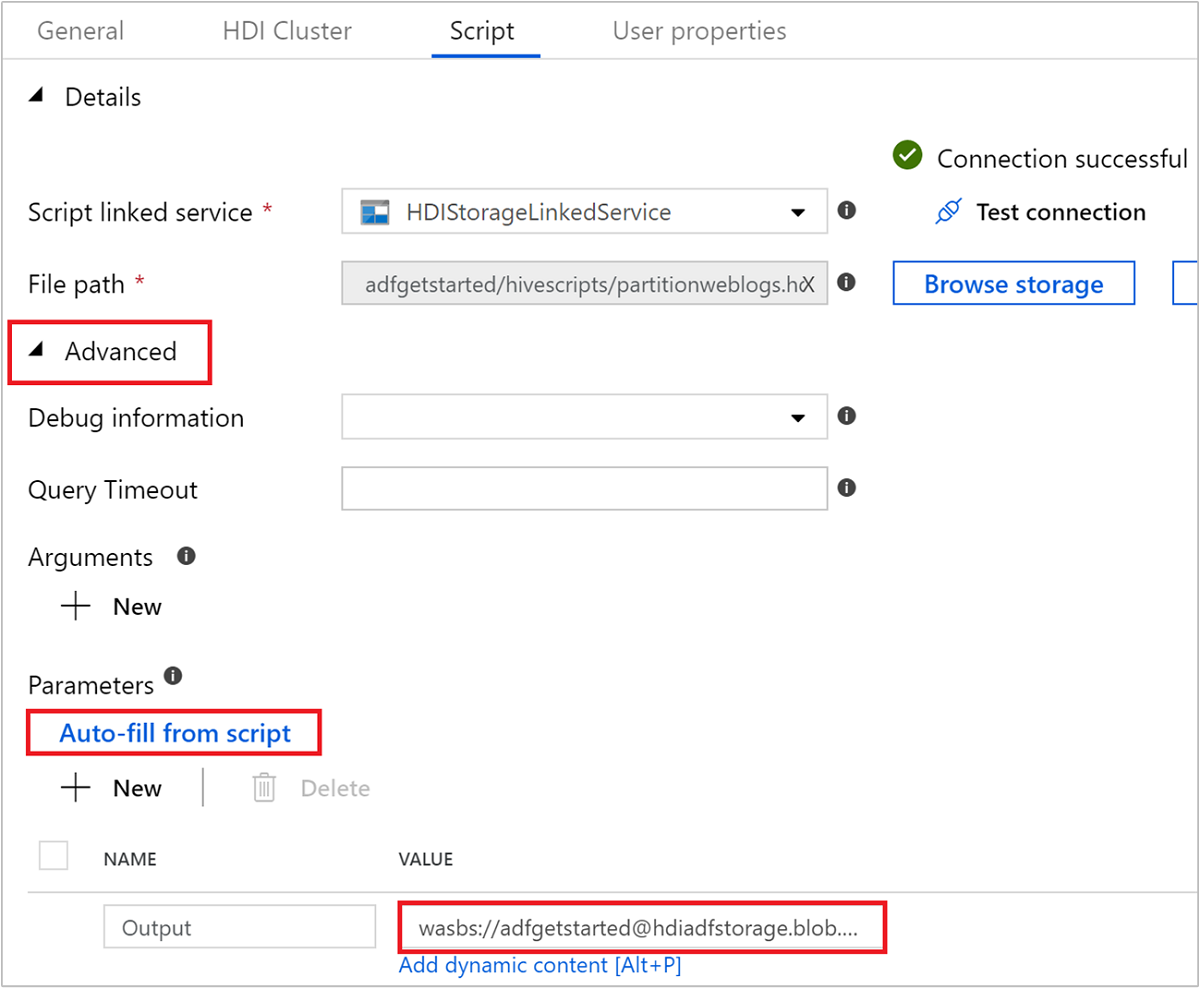
Seleccione Validar para validar la canalización. Seleccione el botón >> (flecha derecha) para cerrar la ventana de comprobación.
Por último, seleccione Publicar todo para publicar los artefactos en Azure Data Factory.
Desencadenar una canalización
En la barra de herramientas de la superficie del diseñador, seleccione Agregar desencadenador>Desencadenar ahora.
Seleccione Aceptar en la barra lateral emergente.
Supervisión de una canalización
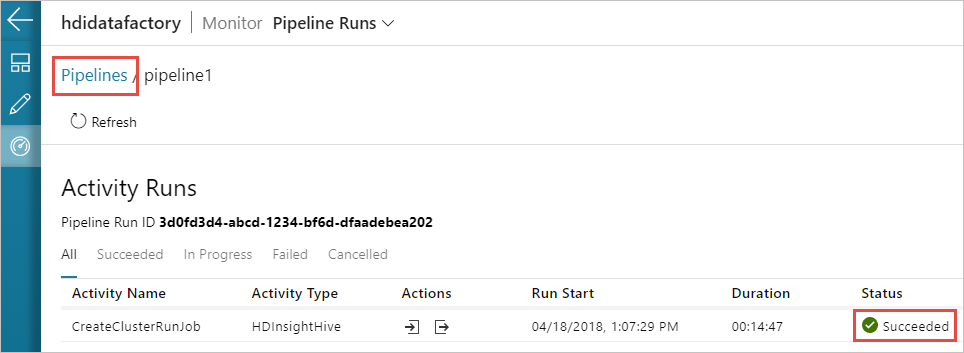
Cambie a la pestaña Monitor (Supervisar) de la izquierda. Puede ver una ejecución de canalización en la lista Pipeline Runs (Ejecuciones de canalización). Tenga en cuenta el estado de la ejecución en la columna Estado.
Seleccione Refresh (Actualizar) para actualizar el estado.
También puede seleccionar el icono Ver ejecuciones de actividad para ver la ejecución de actividad asociada a la canalización. En la siguiente captura de pantalla verá solo una ejecución de actividad, ya que solo hay una actividad en la canalización que ha creado. Para cambiar de nuevo a la vista anterior, seleccione Canalizaciones hacia la parte superior de la página.
Comprobación del resultado
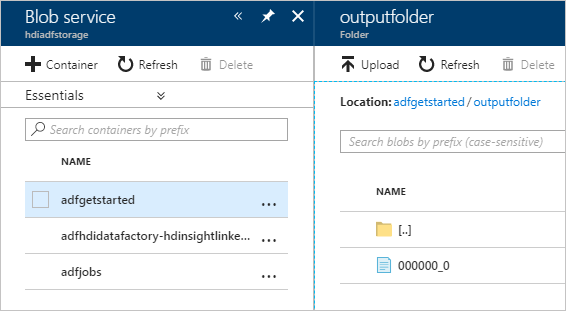
Para comprobar el resultado, en Azure Portal, vaya a la cuenta de almacenamiento que ha usado para este tutorial. Debe ver las siguientes carpetas o contenedores:
Verá un adfgerstarted/outputfolder que contiene el resultado del script de Hive que se ha ejecutado como parte de la canalización.
Verá un contenedor adfhdidatafactory-<linked-service-name>-<timestamp>. Este contenedor es la ubicación de almacenamiento predeterminada del clúster de HDInsight que se ha creado como parte de la ejecución de la canalización.
Verá un contenedor adfjobs que tiene los registros de trabajo de Azure Data Factory.
Limpieza de recursos
Con la creación del clúster de HDInsight a petición, no es necesario que elimine de forma explícita el clúster de HDInsight. El clúster se elimina en función de la configuración que ha proporcionado durante la creación de la canalización. Incluso tras la eliminación del clúster, las cuentas de almacenamiento asociadas al clúster continúan existiendo. Este comportamiento es por diseño para que pueda mantener intactos sus datos. Sin embargo, si no desea conservar los datos, puede eliminar la cuenta de almacenamiento que ha creado.
También, puede eliminar todo el grupo de recursos que ha creado para este tutorial. Este proceso elimina la cuenta de almacenamiento y la instancia de Azure Data Factory que ha creado.
Eliminar el grupo de recursos
Inicie sesión en Azure Portal.
Seleccione Grupos de recursos en el panel izquierdo.
Seleccione el nombre del grupo de recursos que creó en el script de PowerShell. Utilice el filtro si se muestran demasiados grupos de recursos. Se abrirá el grupo de recursos.
En el icono Recursos , aparecerá la cuenta de almacenamiento predeterminada y Data Factory a menos que comparta el grupo de recursos con otros proyectos.
Seleccione Eliminar grupo de recursos. Así se eliminan también la cuenta de almacenamiento y los datos almacenados en ella.
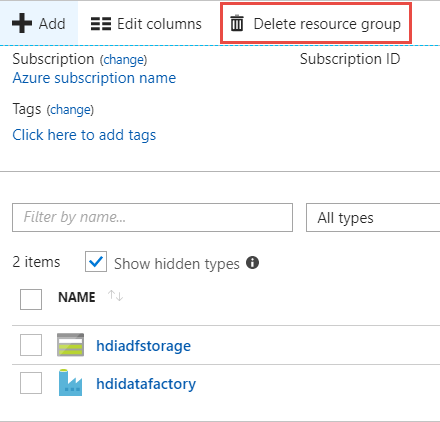
Escriba el nombre del grupo de recursos para confirmar la eliminación y, después, seleccione Eliminar.
Pasos siguientes
En este artículo, ha aprendido a usar Azure Data Factory para crear el clúster de HDInsight a petición y ejecutar los trabajos de Apache Hive. Adelántese al siguiente artículo para aprender a crear clústeres de HDInsight con una configuración personalizada.