Transformación de datos mediante flujos de datos de asignación
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Si no está familiarizado con Azure Data Factory, consulte Introducción a Azure Data Factory.
En este tutorial, usará la interfaz de usuario de Azure Data Factory (UX) para crear una canalización que copie y transforme los datos desde un origen de Azure Data Lake Storage (ADLS) Gen2 hasta un receptor de ADLS Gen2 mediante un flujo de datos de asignación. El patrón de configuración de este tutorial se puede expandir al transformar los datos mediante el flujo de datos de asignación.
Nota
Este tutorial está pensado para los flujo de datos de asignación en general. Los flujos de datos están disponibles en las canalizaciones Azure Data Factory y Synapse. Si no está familiarizado con los flujos de datos en las canalizaciones de Azure Synapse, siga el flujo de datos con las canalizaciones de Azure Synapse.
En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Creación de una canalización con una actividad de Data Flow.
- Cree un flujo de datos de asignación con cuatro transformaciones.
- Realización de la serie de pruebas de la canalización.
- Supervisión de una actividad de Data Flow
Requisitos previos
- Suscripción de Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita de Azure antes de empezar.
- Cuenta de Azure Storage. El almacenamiento ADLS se puede usar como almacén de datos de origen y receptor. Si no tiene una cuenta de almacenamiento, consulte Crear una cuenta de almacenamiento para crear una.
El archivo que se está transformando en este tutorial es MoviesDB. csv, que se puede encontrar aquí. Para recuperar el archivo de GitHub, copie el contenido en un editor de texto de su elección para guardarlo localmente como un archivo. csv. Para cargar el archivo en la cuenta de almacenamiento, vea Carga de blobs con Azure Portal. Los ejemplos harán referencia a un contenedor denominado "Sample-Data".
Crear una factoría de datos
En este paso, creará una factoría de datos y abrirá la interfaz de usuario de Data Factory para crear una canalización en la factoría de datos.
Abra Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
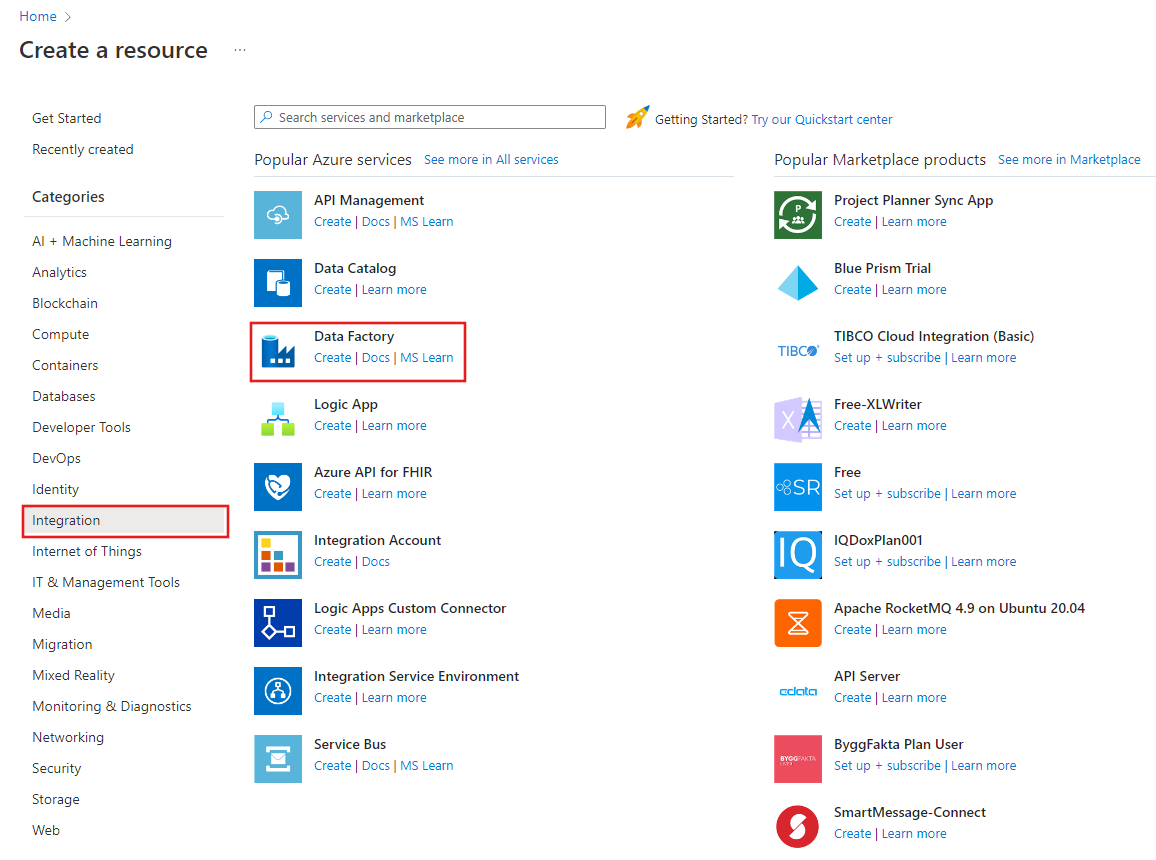
En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory:
En la página Nueva factoría de datos, en Nombre, escriba ADFTutorialDataFactory.
El nombre de la instancia de Azure Data Factory debe ser único de forma global. Si recibe un mensaje de error sobre el valor de nombre, escriba un nombre diferente para la factoría de datos. (Por ejemplo, utilice SuNombreADFTutorialDataFactory). Para conocer las reglas de nomenclatura de los artefactos de Data Factory, consulte Azure Data Factory: reglas de nomenclatura.
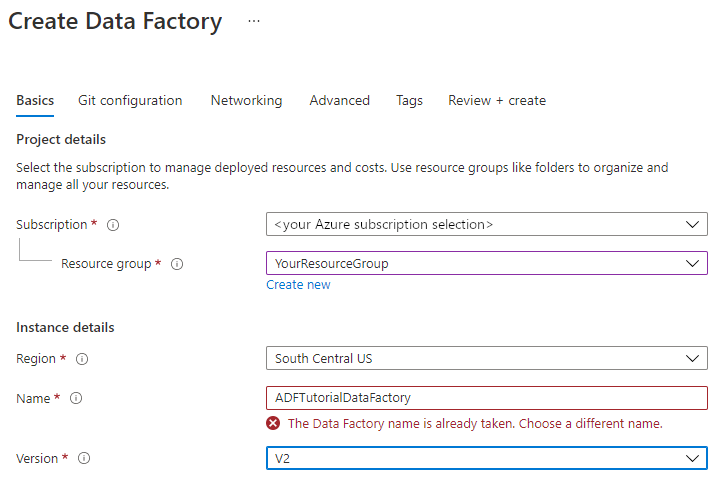
Seleccione la suscripción de Azure en la que quiere crear la factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
a. Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
b. Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
En Versión, seleccione V2.
En Ubicación, seleccione la ubicación de la factoría de datos. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) que la factoría de datos usa pueden estar en otras regiones.
Seleccione Crear.
Una vez finalizada la creación, verá el aviso en el centro de notificaciones. Seleccione Ir al recurso para ir a la página de Data Factory.
Haga clic en Author & Monitor (Creación y supervisión) para iniciar la interfaz de usuario de Data Factory en una pestaña independiente.
Creación de una canalización con una actividad de Data Flow
En este paso, creará una canalización que contiene una actividad de Data Flow.
En la página principal de Azure Data Factory, seleccione Orchestrate (Organizar).
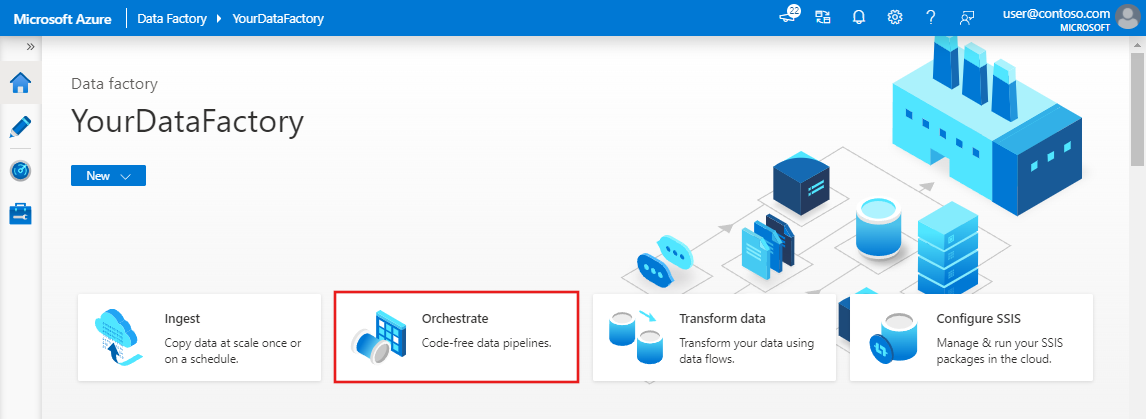
En la pestaña General de la canalización, escriba TransformMovies como Nombre de la canalización.
En el panel Actividades expanda el acordeón Movimiento y transformación. Arrastre y coloque la actividad Data Flow del panel al lienzo de la canalización.
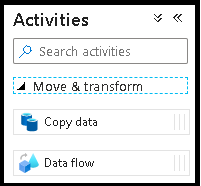
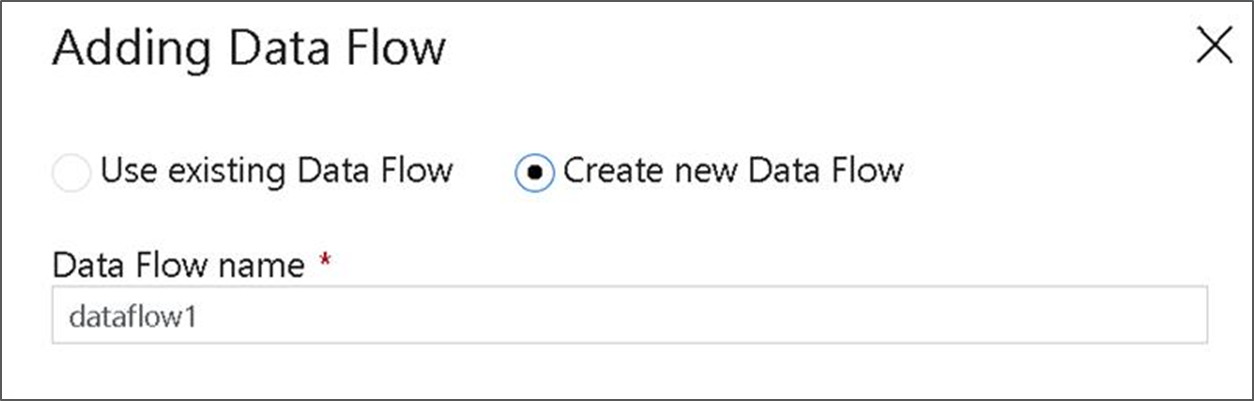
En el menú emergente Adding Data Flow (Agregando Data Flow), seleccione Create New Data Flow (Crear nuevo Data Flow) y, a continuación, asigne el nombre TransformMovies al flujo de datos. Haga clic en Finalizar cuando haya terminado.
En la barra superior del lienzo de la canalización, mueva el control deslizante Depuración de flujo de datos a la posición de activado. El modo de depuración permite realizar pruebas interactivas de la lógica de transformación en un clúster de Spark activo. Los clústeres de Data Flow tardan de 5 a 7 minutos en prepararse y se recomienda que los usuarios activen primero la depuración si planean realizar el desarrollo de Data Flow. Para más información, consulte Modo de depuración.

Generación de la lógica de transformación en el lienzo de flujo de datos
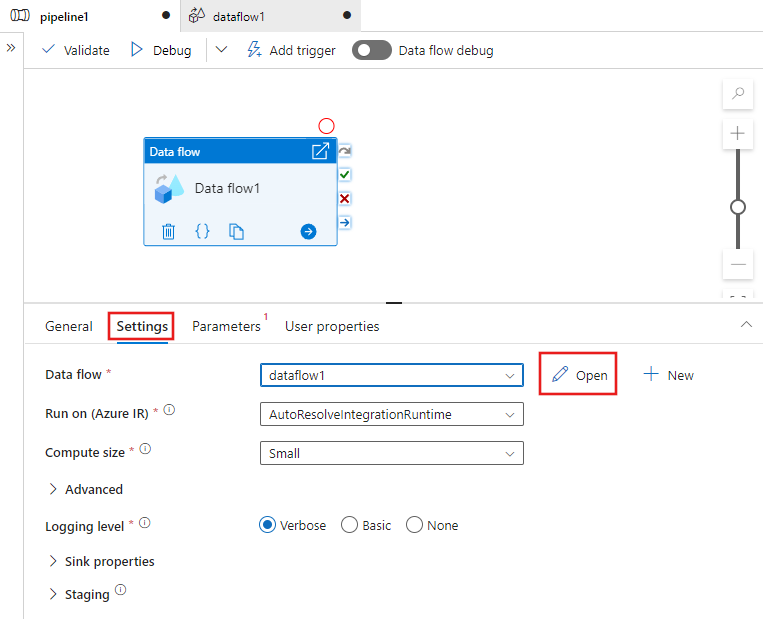
Una vez creado el flujo de datos, se le enviará automáticamente al lienzo flujo de datos. En caso de que no se le redirija al lienzo del flujo de datos, en el panel situado debajo del lienzo, vaya a Configuración y seleccione Abrir al lado del campo del flujo de datos. De esta forma, se abrirá el lienzo del flujo de datos.
En este paso, creará un flujo de datos que toma el archivo moviesDB. csv en el almacenamiento de ADLS y agrega el promedio de clasificación de Comedias de 1910 a 2000. Después, volverá a escribir este archivo en el almacenamiento de ADLS.
Para agregar un lienzo de flujo de datos, haga clic en el cuadro Agregar origen y agregue un origen.
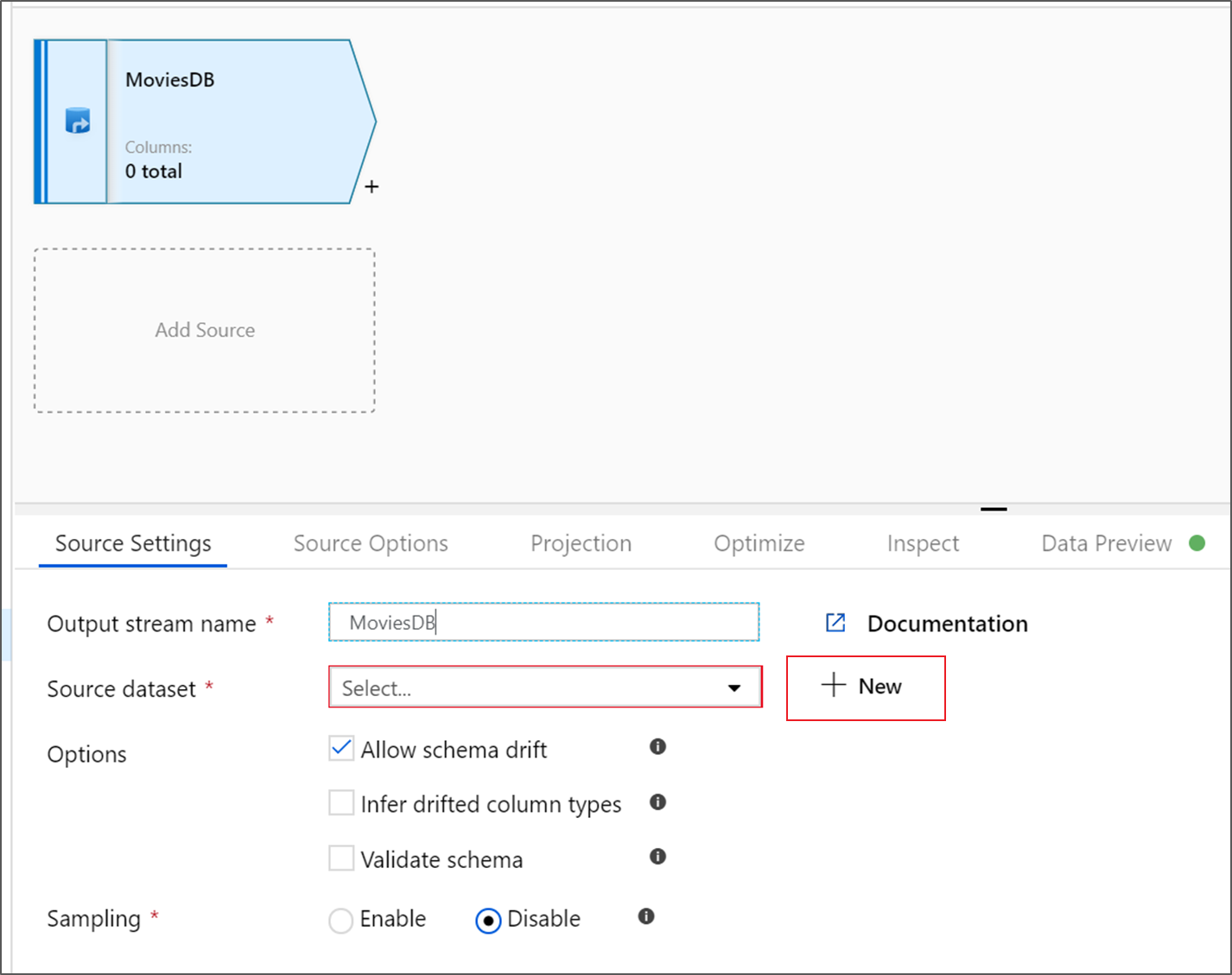
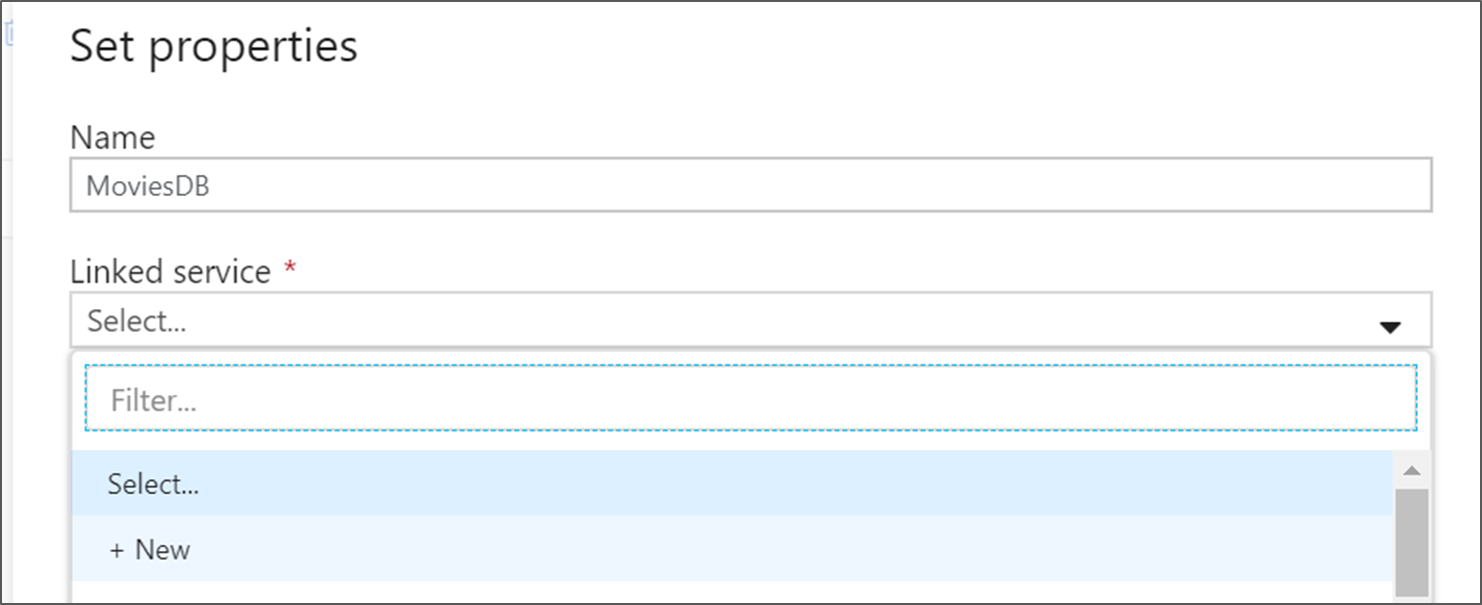
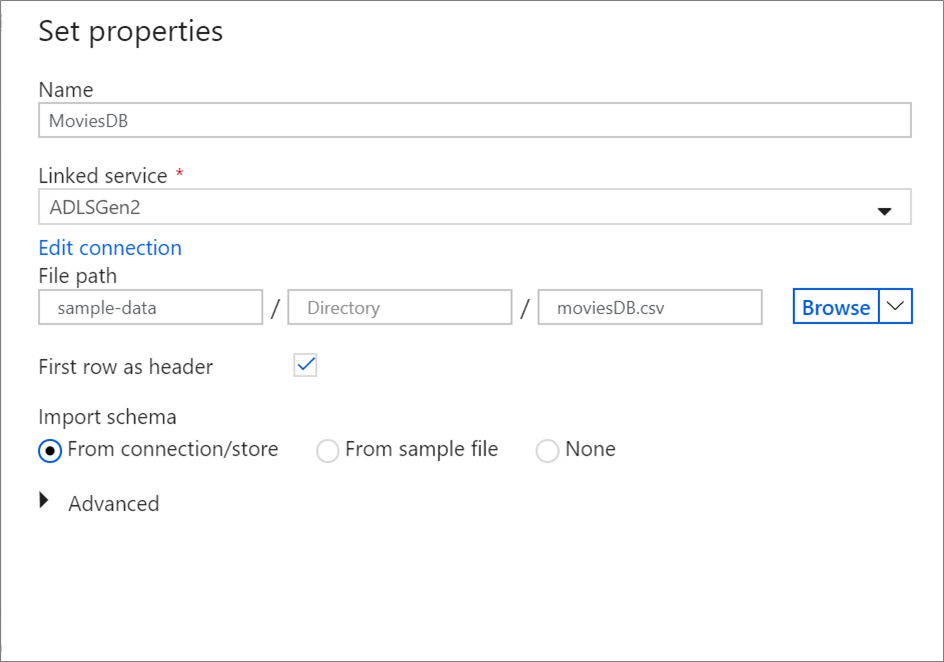
Asigne un nombre al origen MoviesDB. Haga clic en Nuevo para crear un conjunto de datos de origen nuevo.
Elija Azure Data Lake Storage Gen2. Haga clic en Continue.
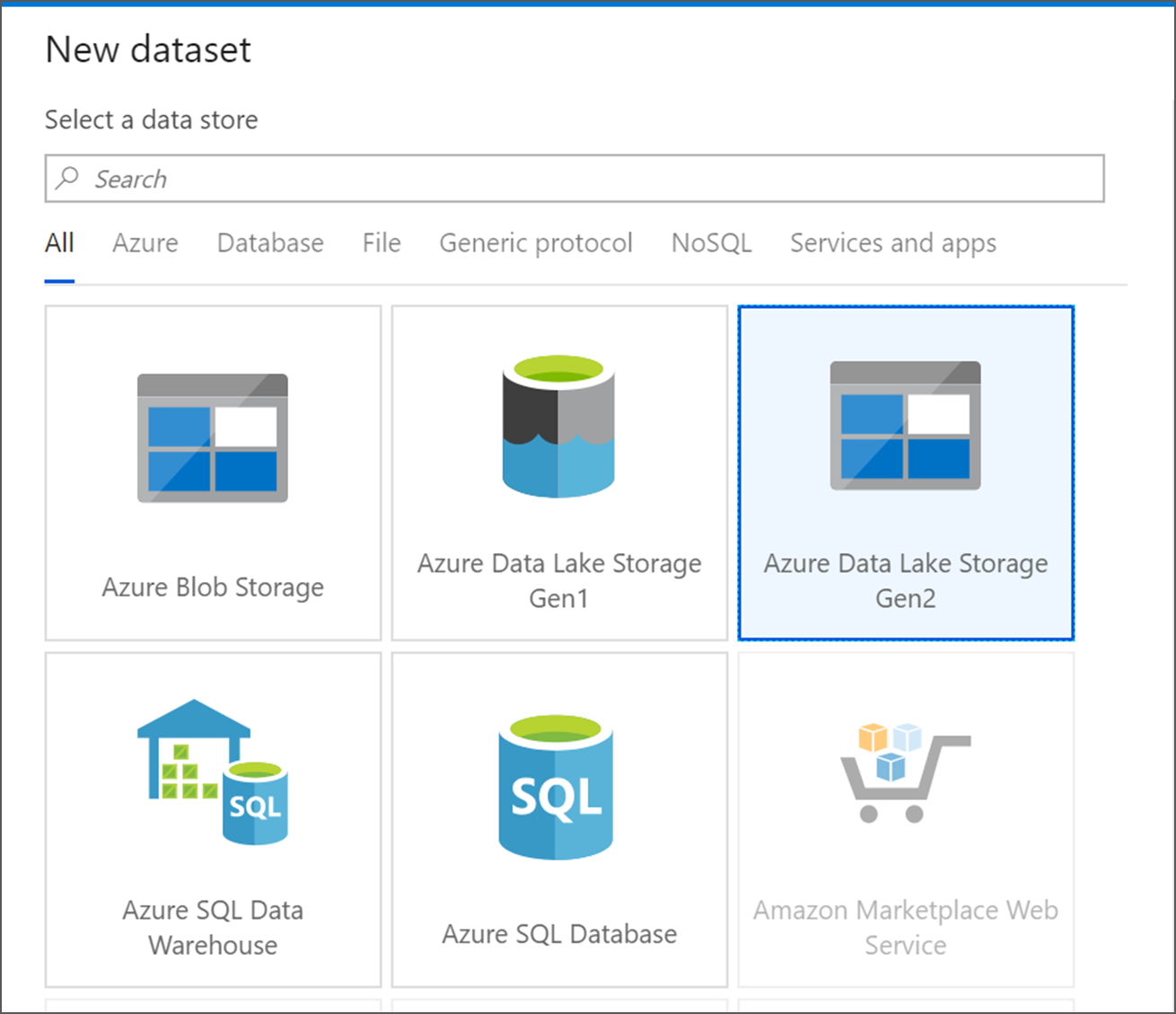
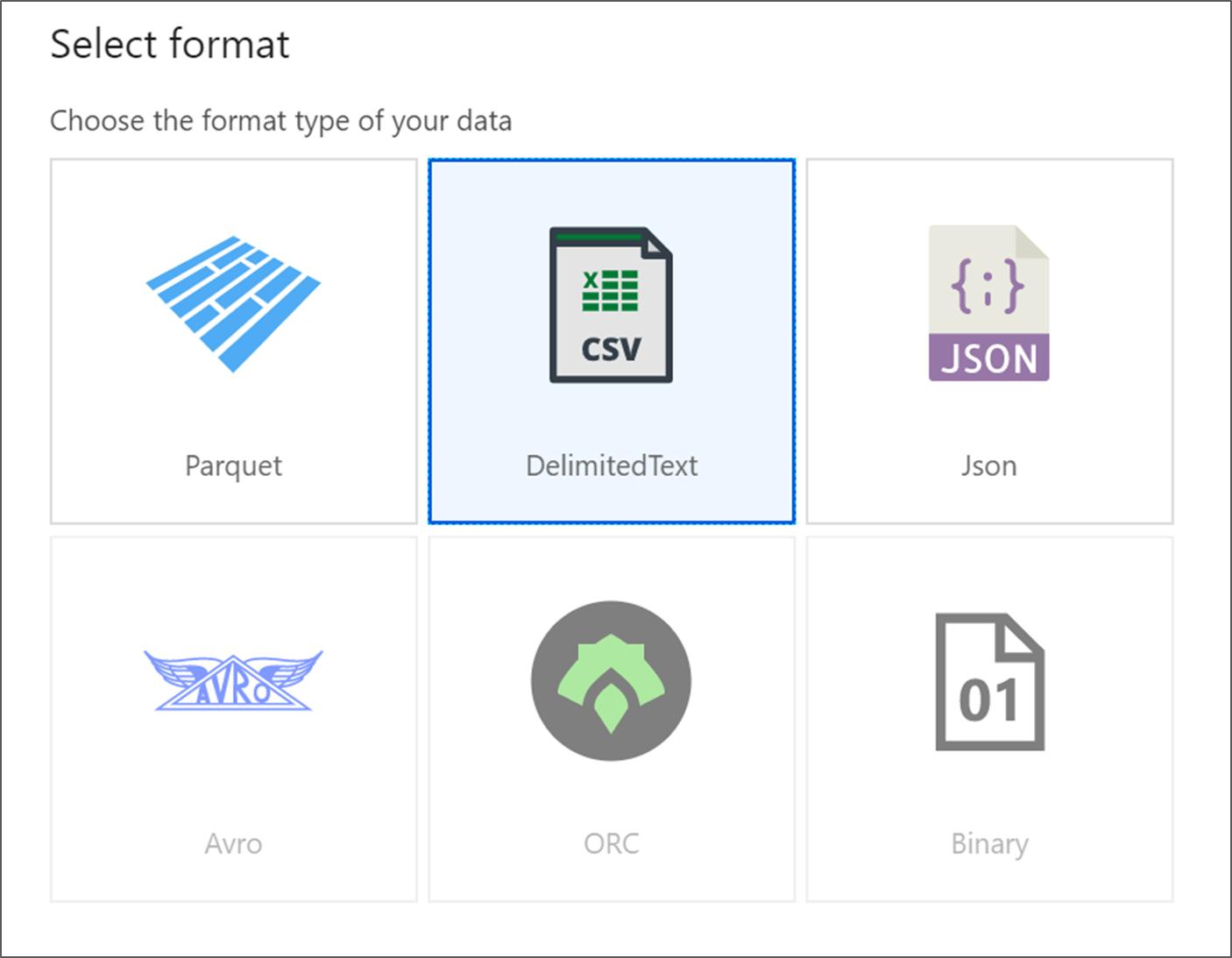
Elija DelimitedText. Haga clic en Continue.
Asigne un nombre al conjunto de datos MoviesDB. En la lista desplegable de servicios vinculados, elija Nuevo.
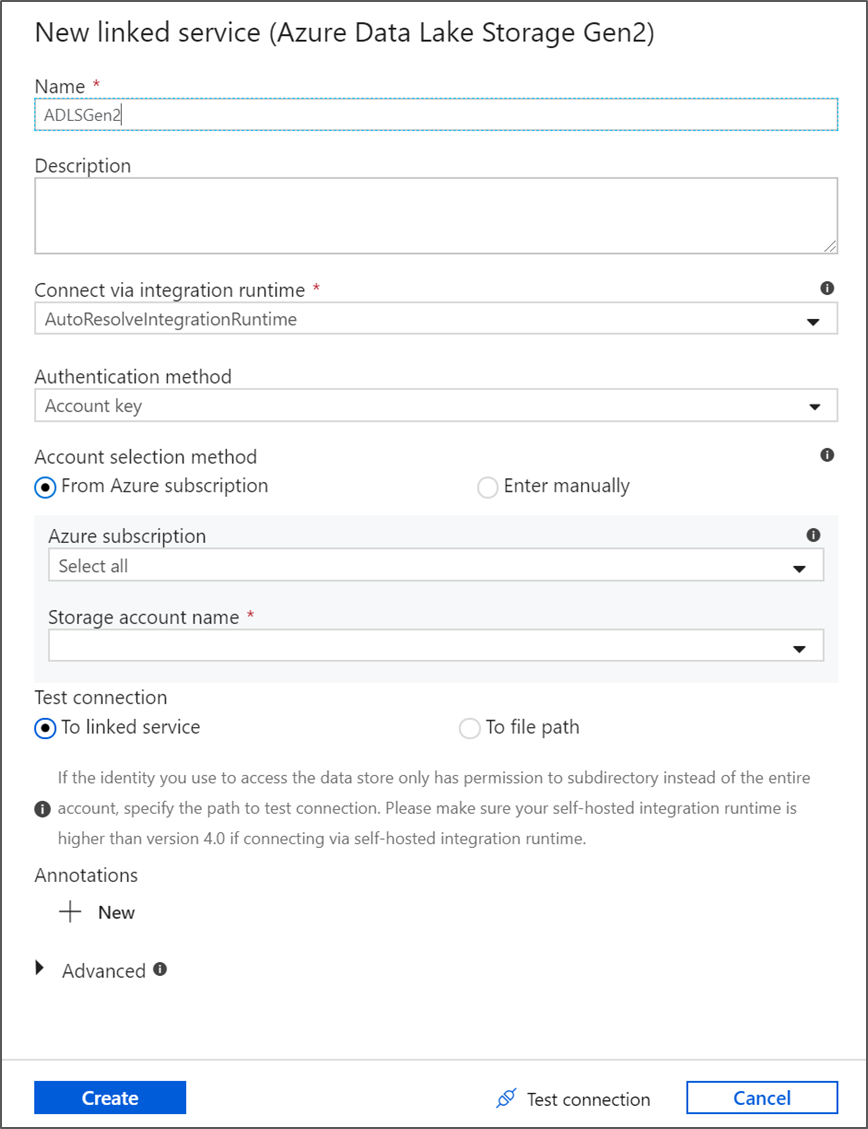
En la pantalla de creación de un servicio vinculado, asigne el nombre ADLSGen2 al servicio vinculado ADLS gen2 y especifique el método de autenticación. A continuación, escriba las credenciales de conexión. En este tutorial, vamos a usar la clave de cuenta para conectarse a la cuenta de almacenamiento. Puede hacer clic en Prueba de conexión para comprobar que las credenciales se escribieron correctamente. Cuando haya terminado, haga clic en Crear.
Una vez que vuelva a la pantalla de creación del conjunto de datos, escriba la ubicación del archivo en el campo Ruta de acceso de archivo. En este tutorial, el archivo moviesDB.csv se encuentra en el contenedor sample-data. Como el archivo tiene encabezados, active First row as header (Primera fila como encabezado). Seleccione From Connection/Store (Desde la conexión o almacén) para importar el esquema de encabezado directamente desde el archivo en el almacenamiento. Haga clic en Aceptar cuando haya terminado.
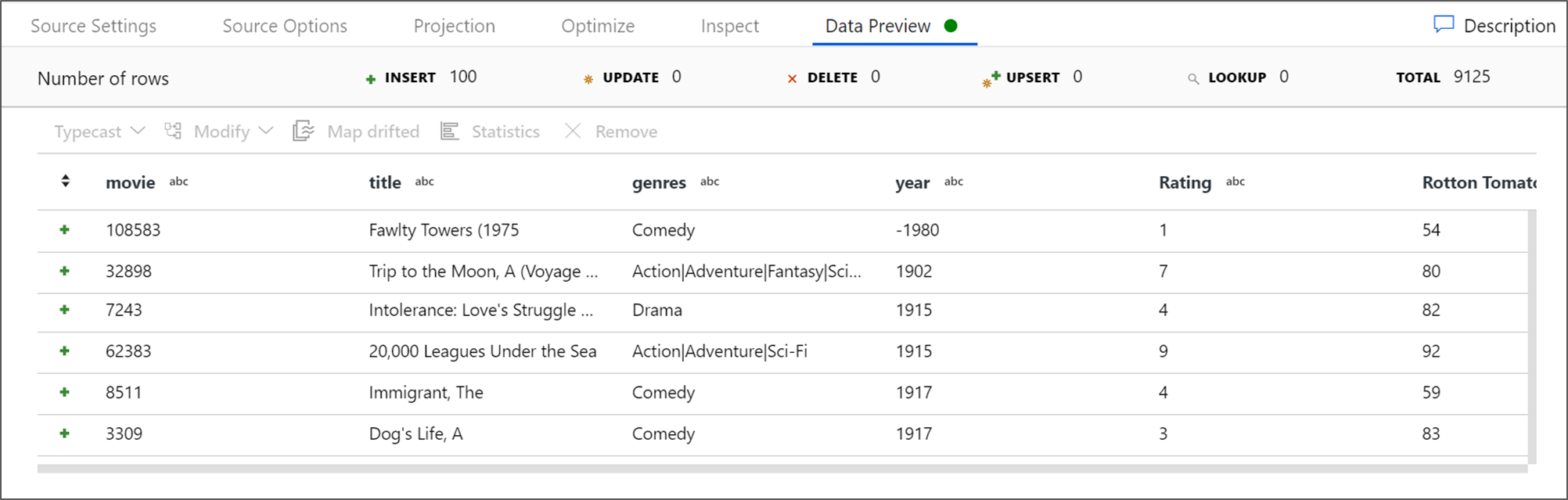
Si se ha iniciado el clúster de depuración, vaya a la pestaña Vista previa de los datos de la transformación de origen y haga clic en Actualizar para obtener una instantánea de los datos. Puede usar la vista previa de los datos para comprobar que la transformación está configurada correctamente.
Junto al nodo de origen en el lienzo de flujo de datos, haga clic en el icono de signo más para agregar una nueva transformación. La primera transformación que va a agregar es un filtro.
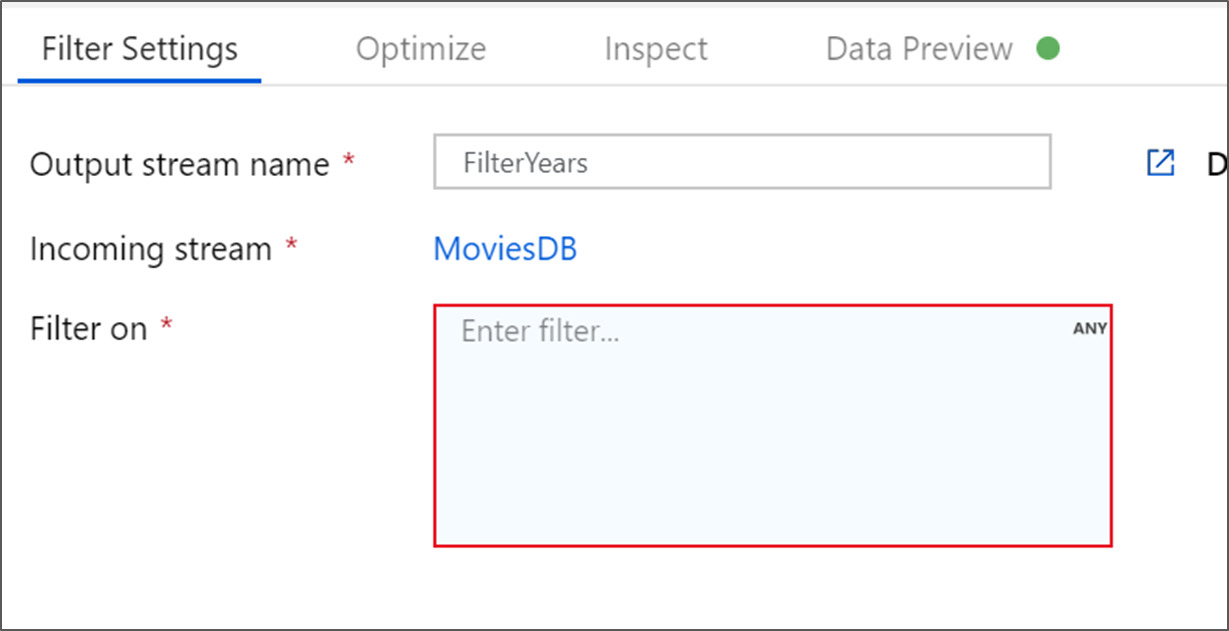
Denomine FilterYears a la transformación de filtro. Haga clic en el cuadro de expresión junto a Filtro en para abrir el generador de expresiones. Aquí especificará la condición de filtrado.
El generador de expresiones de flujo de datos le permite compilar de forma interactiva expresiones para utilizarlas en varias transformaciones. Las expresiones pueden incluir funciones integradas, columnas del esquema de entrada y parámetros definidos por el usuario. Para más información sobre cómo compilar expresiones, vea Generador de expresiones de Mapping Data Flow.
En este tutorial, desea filtrar las películas del género de comedia que se estrenaron entre los años 1910 y 2000. Dado que el año es actualmente una cadena, debe convertirlo en un entero mediante la función
toInteger(). Use los operadores mayor o igual que (>=) y menor o igual que (<=) para comparar con los valores de año literal 1910 y 2000. Una estas expresiones junto con el operador and (&&). La expresión aparece como:toInteger(year) >= 1910 && toInteger(year) <= 2000Para averiguar qué películas son comedias, puede usar la función
rlike()para buscar el patrón " comedia" en la columna de géneros. Una la expresiónrlikecon la comparación de año para obtener:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Si tiene un clúster de depuración activo, puede comprobar la lógica; para ello, haga clic en Actualizar para ver la salida de la expresión en comparación con las entradas usadas. Hay más de una respuesta correcta sobre cómo puede realizar esta lógica mediante el lenguaje de expresiones de flujo de datos.
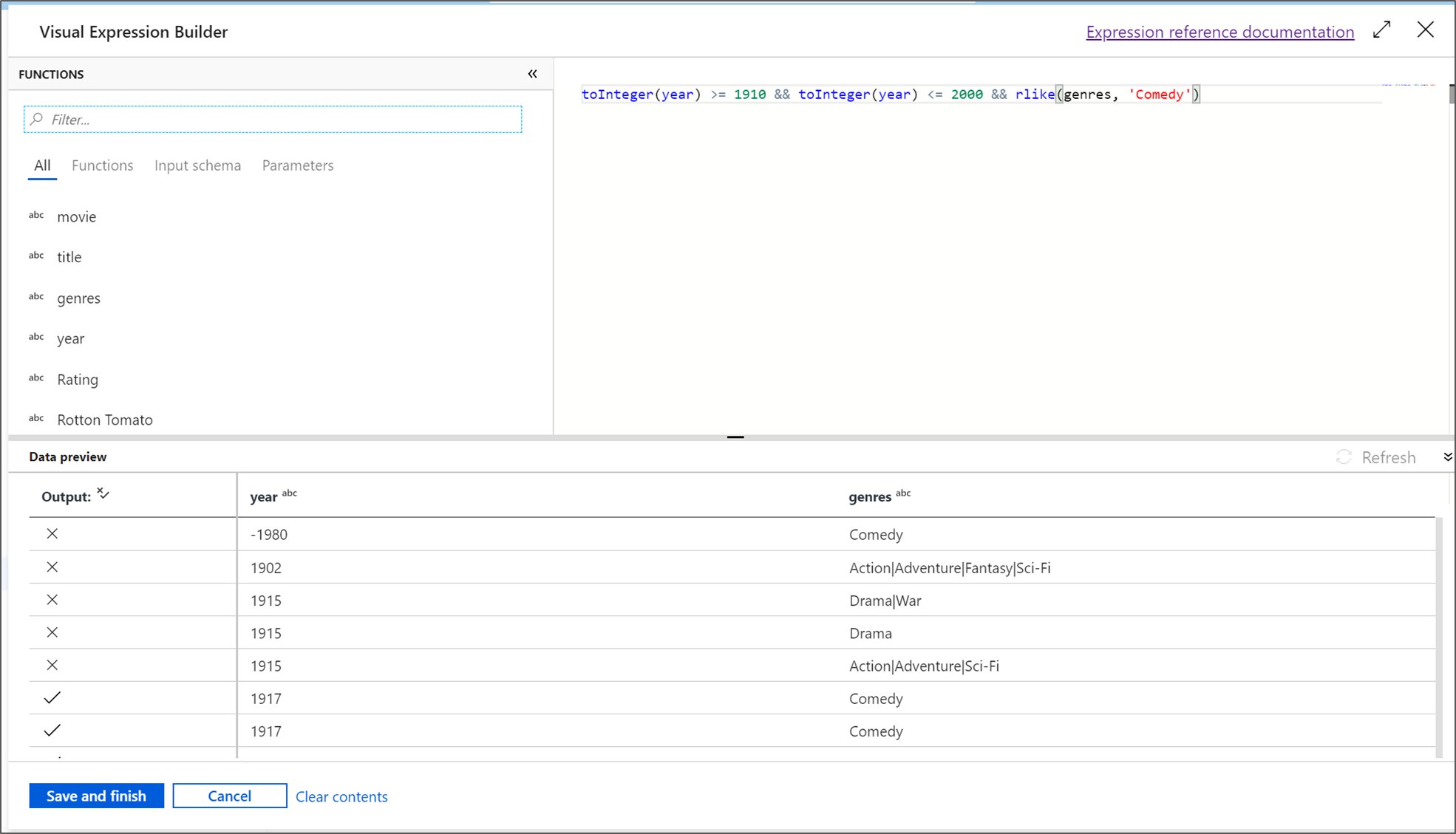
Haga clic en Guardar y finalizar una vez que haya terminado con la expresión.
Capture una Vista previa de datos para comprobar que el filtro funciona correctamente.
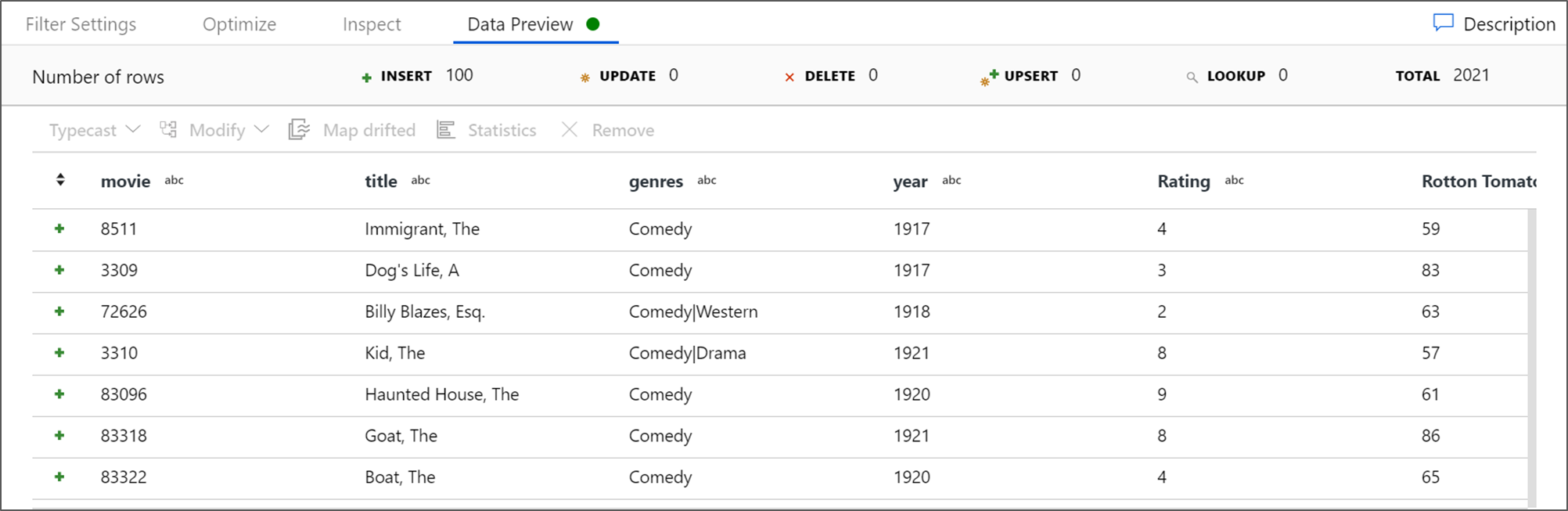
La transformación siguiente que se va a agregar es una transformación de agregado en Schema Modifier (Modificador de esquema).
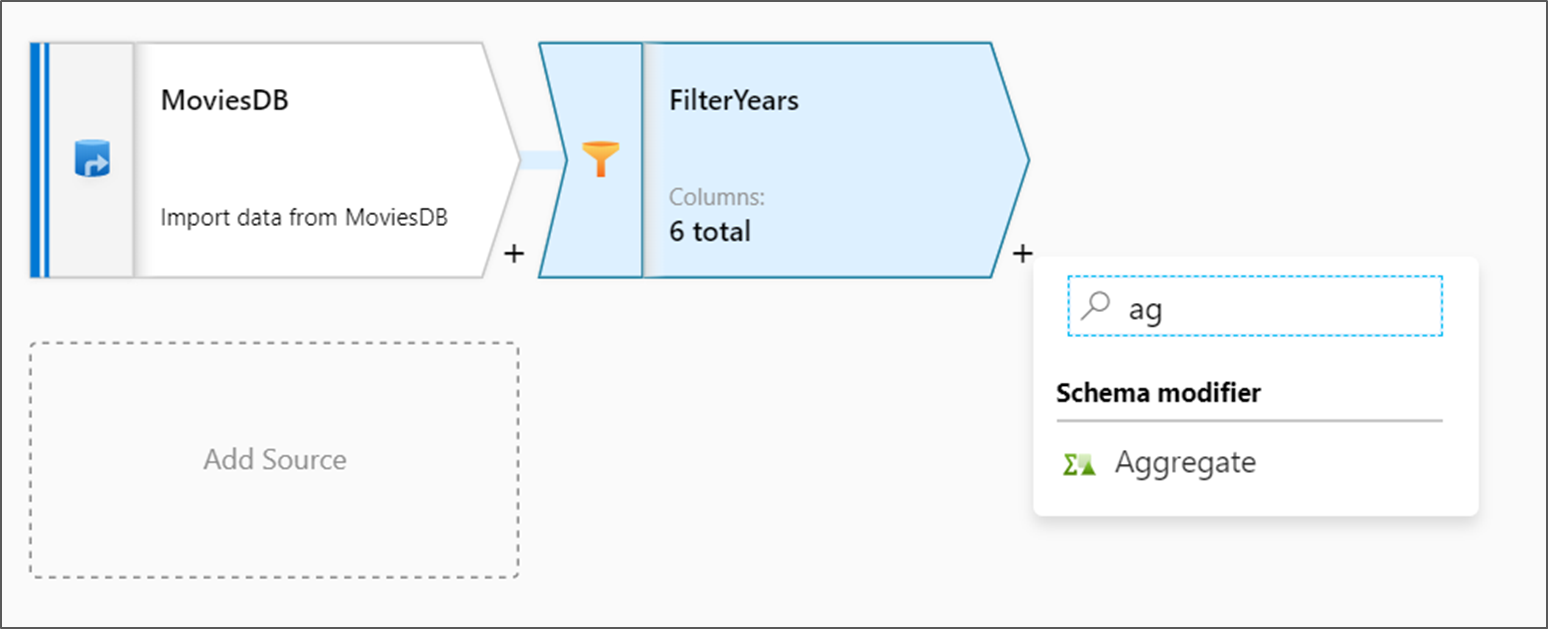
Denomine AggregateComedyRatings a la transformación de agregado. En la pestaña Agrupar por, seleccione year (año) en la lista desplegable para agrupar las agregaciones por el año en que apareció la película.
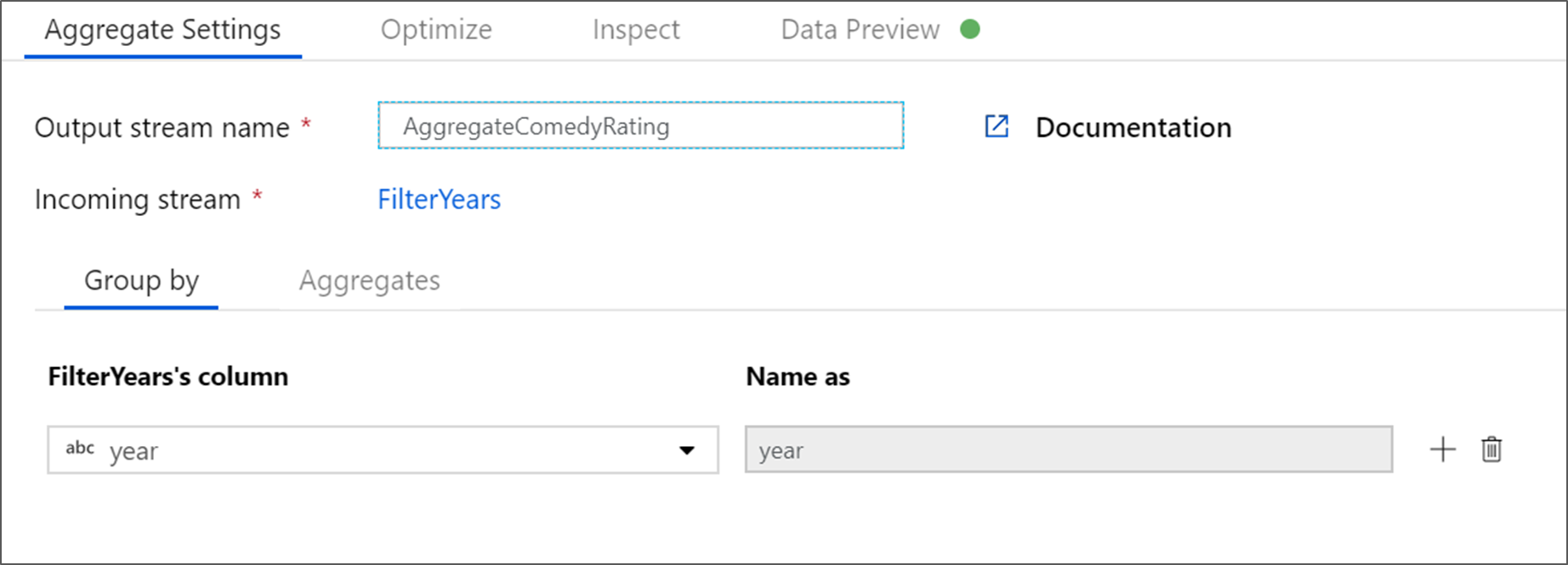
Vaya a la pestaña Agregados. En el cuadro de texto de la izquierda, asigne a la columna agregada el nombre AverageComedyRating. Haga clic en el cuadro de la expresión derecha para especificar la expresión de agregado a través del generador de expresiones.
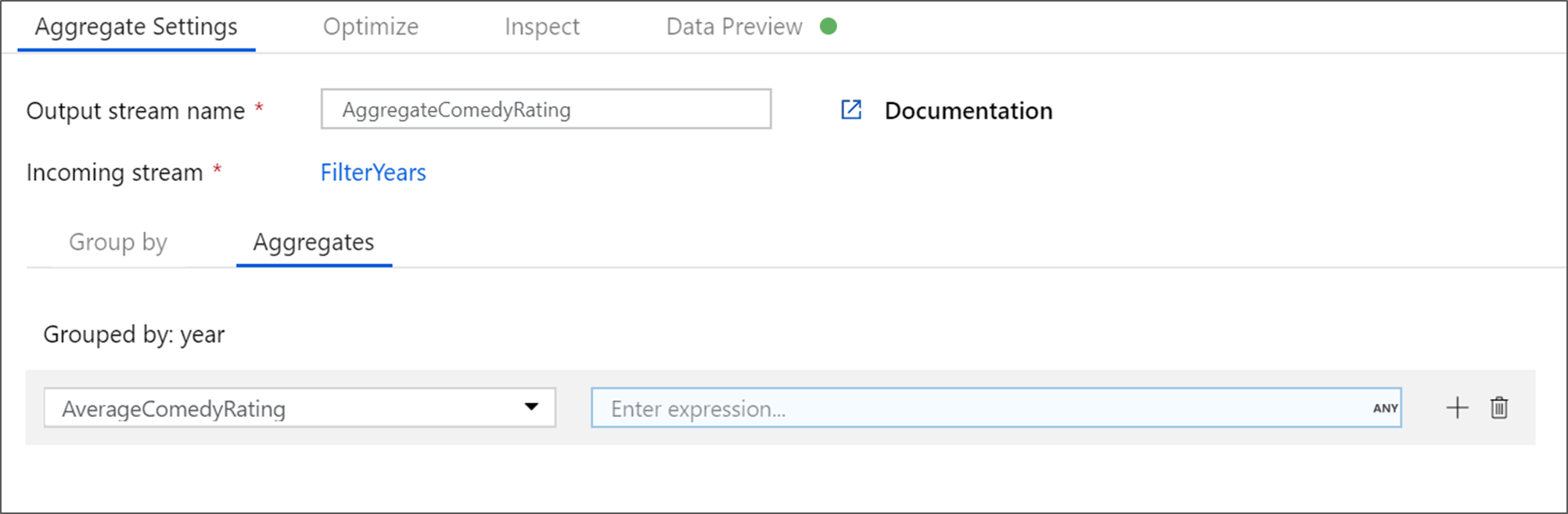
Para obtener el promedio de la columna Rating (Clasificación), use la función de agregado
avg(). Como Rating (Clasificación) es una cadena yavg()toma una entrada numérica, debemos convertir el valor en un número a través de la funcióntoInteger(). Se trata de una expresión similar a la siguiente:avg(toInteger(Rating))Haga clic en Guardar y finalizar cuando haya terminado.

Vaya a la pestaña Vista previa de datos para ver la salida de la transformación. Observe que solo hay dos columnas, year y AverageComedyRating.
A continuación, desea agregar una transformación de receptor en Destino.
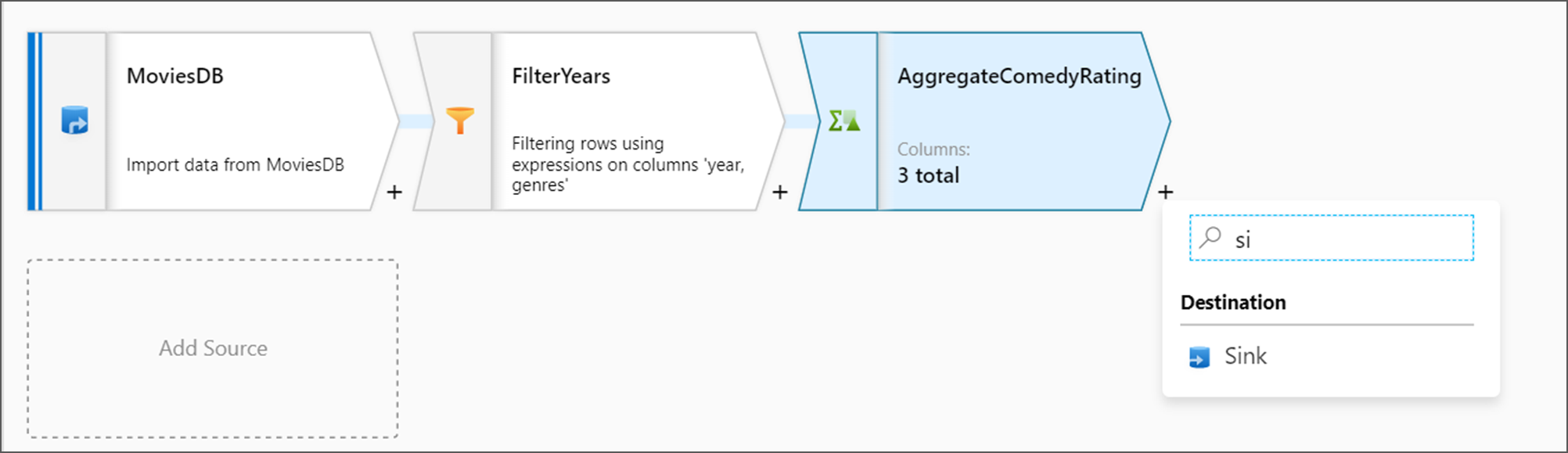
Asigne un nombre al receptor Sink (Receptor). Haga clic en Nuevo para crear un conjunto de datos de receptor.
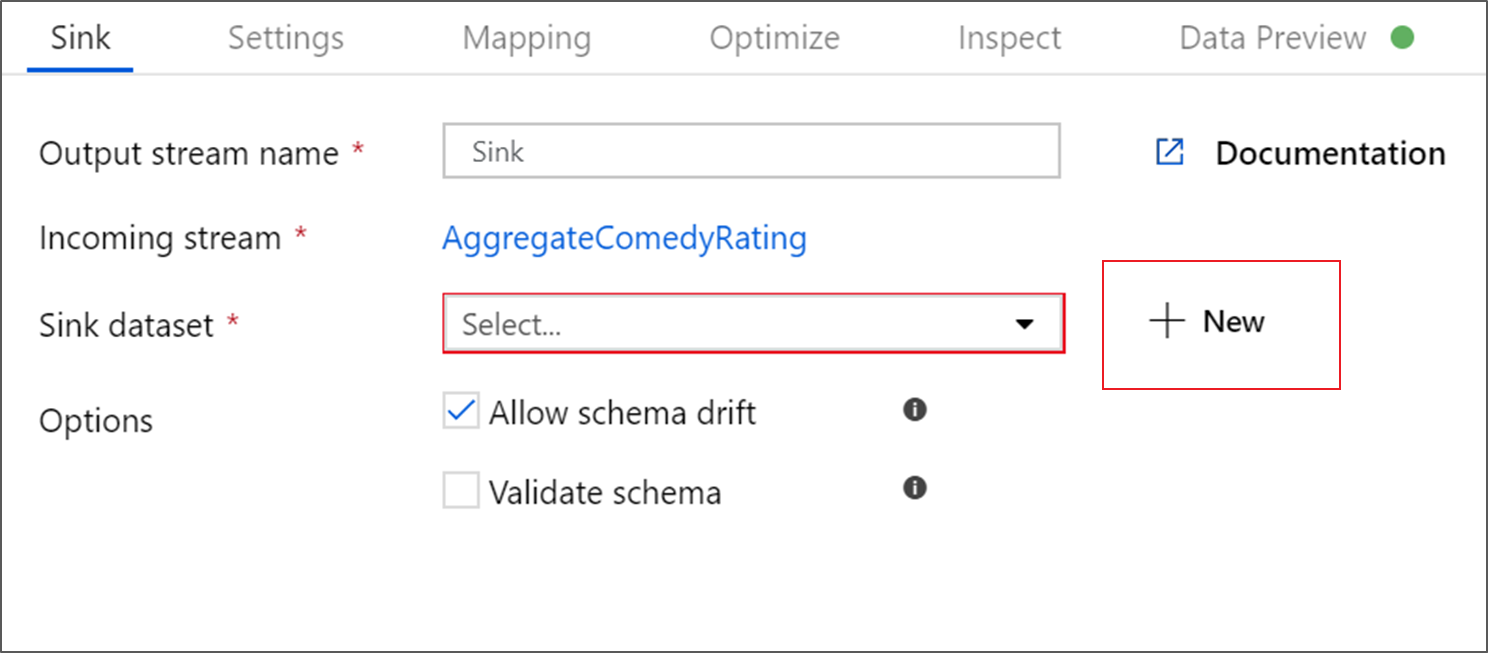
Elija Azure Data Lake Storage Gen2. Haga clic en Continue.
Elija DelimitedText. Haga clic en Continue.
Asigne el nombre MoviesSink al conjunto de datos de receptor. Para el servicio vinculado, elija el servicio vinculado ADLS gen2 que creó en el paso 6. Escriba una carpeta de salida en la que escribir los datos. En este tutorial, vamos a escribir en la carpeta "output" (salida) en el contenedor "sample-data" (datos de ejemplo). No es necesario que la carpeta exista de antemano y se puede crear dinámicamente. Establezca Usar la primera fila como encabezado en true y seleccione Ninguna en Importar esquema. Haga clic en Finish.
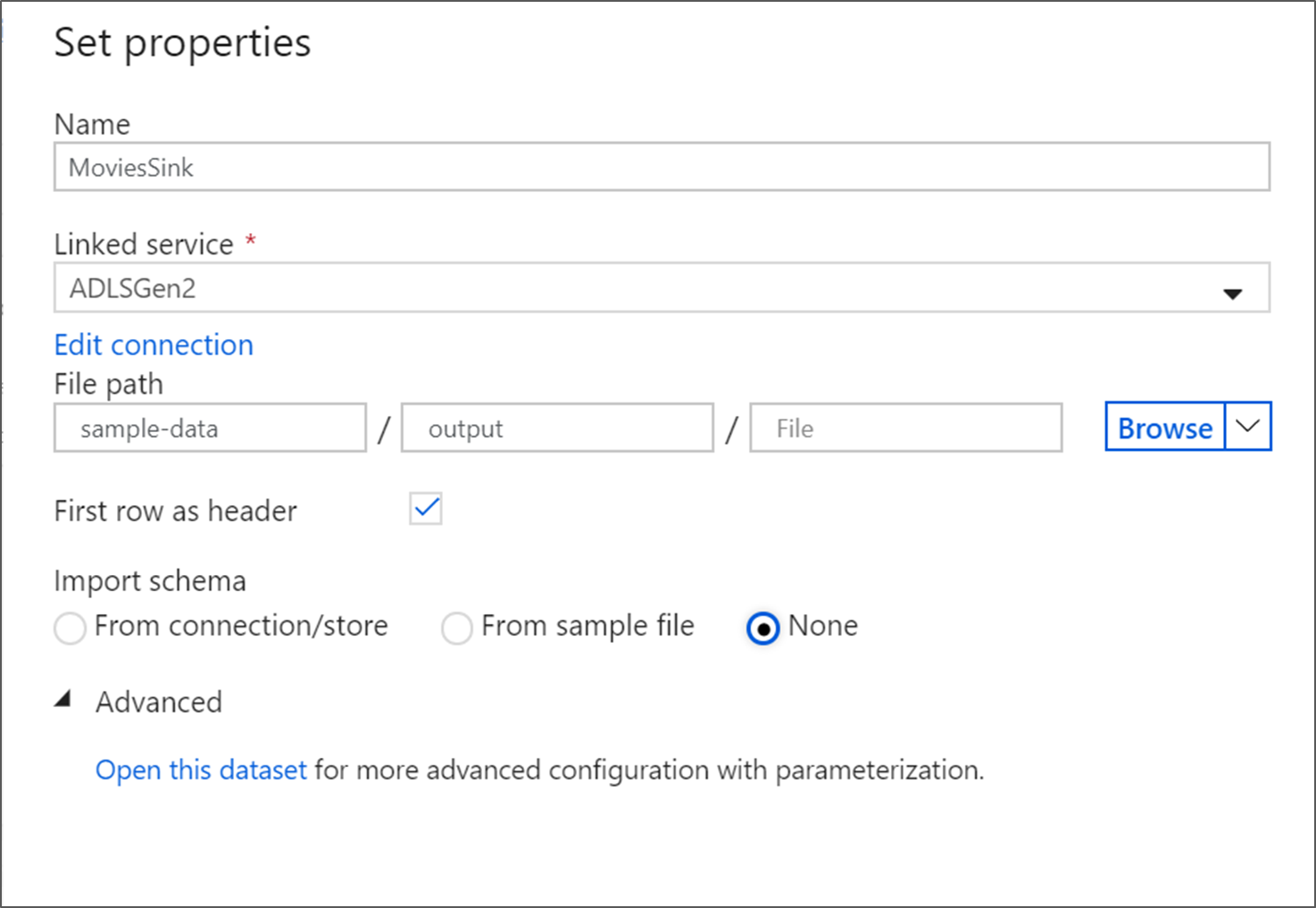
Ahora ha terminado de crear el flujo de datos. Está preparado para ejecutarlo en la canalización.
Ejecución y supervisión del flujo de datos
Puede depurar una canalización antes de publicarla. En este paso, va a desencadenar una ejecución de depuración de la canalización de flujo de datos. Aunque la vista previa de los datos no escribe datos, una ejecución de depuración escribirá datos en el destino del receptor.
Vaya al lienzo de la canalización. Haga clic en Depurar para desencadenar una ejecución de depuración.
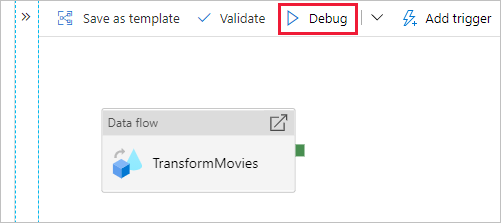
La depuración de canalización de actividades de Data Flow usa el clúster de depuración activo, pero sigue tardando al menos un minuto en inicializarse. Puede realizar un seguimiento del progreso a través de la pestaña Salida. Una vez que la ejecución se realice correctamente, haga clic en el icono de anteojos para abrir el panel de supervisión.
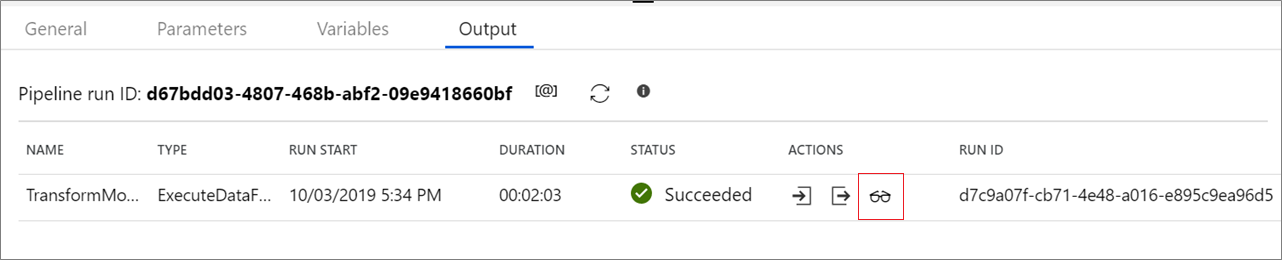
En el panel supervisión, puede ver el número de filas y el tiempo invertido en cada paso de transformación.
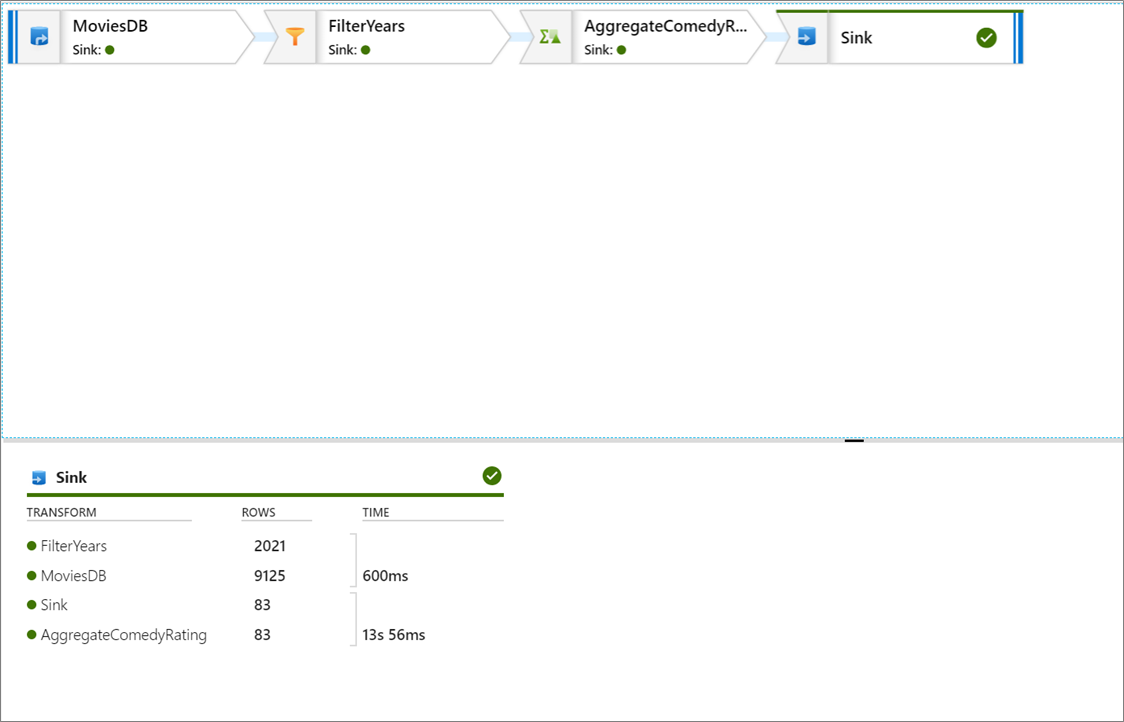
Haga clic en una transformación para obtener información detallada sobre las columnas y las particiones de los datos.
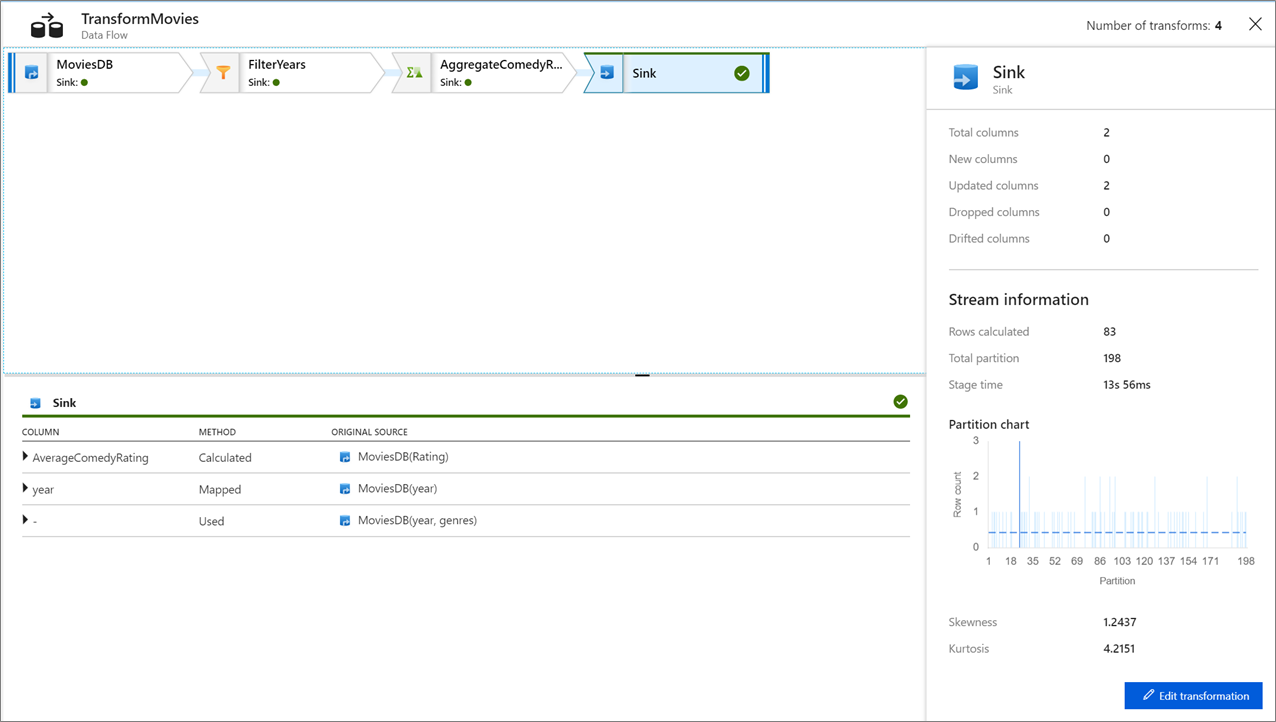
Si siguió correctamente este tutorial, debe haber escrito 83 filas y 2 columnas en la carpeta del receptor. Puede comprobar el almacenamiento de blobs para confirmar que los datos son correctos.
Contenido relacionado
La canalización de este tutorial ejecuta un flujo de datos que agrega el promedio de la clasificación de comedias de 1910 a 2000 y escribe los datos en ADLS. Ha aprendido a:
- Creación de una factoría de datos.
- Creación de una canalización con una actividad de Data Flow.
- Cree un flujo de datos de asignación con cuatro transformaciones.
- Realización de la serie de pruebas de la canalización.
- Supervisión de una actividad de Data Flow
Obtenga más información sobre el lenguaje de expresiones de flujo de datos.