Generación de expresiones del flujo de datos de asignación
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En el flujo de datos de asignación, muchas propiedades de transformación se especifican como expresiones. Estas expresiones se componen de valores de columna, parámetros, funciones, operadores y literales que se evalúan como un tipo de datos de Spark en tiempo de ejecución. La asignación de flujos de datos tiene una experiencia dedicada orientada a ayudarle a crear estas expresiones denominada Generador de expresiones. Al utilizar la finalización de código de IntelliSense para el resaltado, la comprobación de sintaxis y autocompletar, el diseño del generador de expresiones facilita la creación de flujos de datos. En este artículo se explica cómo usar el generador de expresiones para crear eficazmente la lógica de negocios.
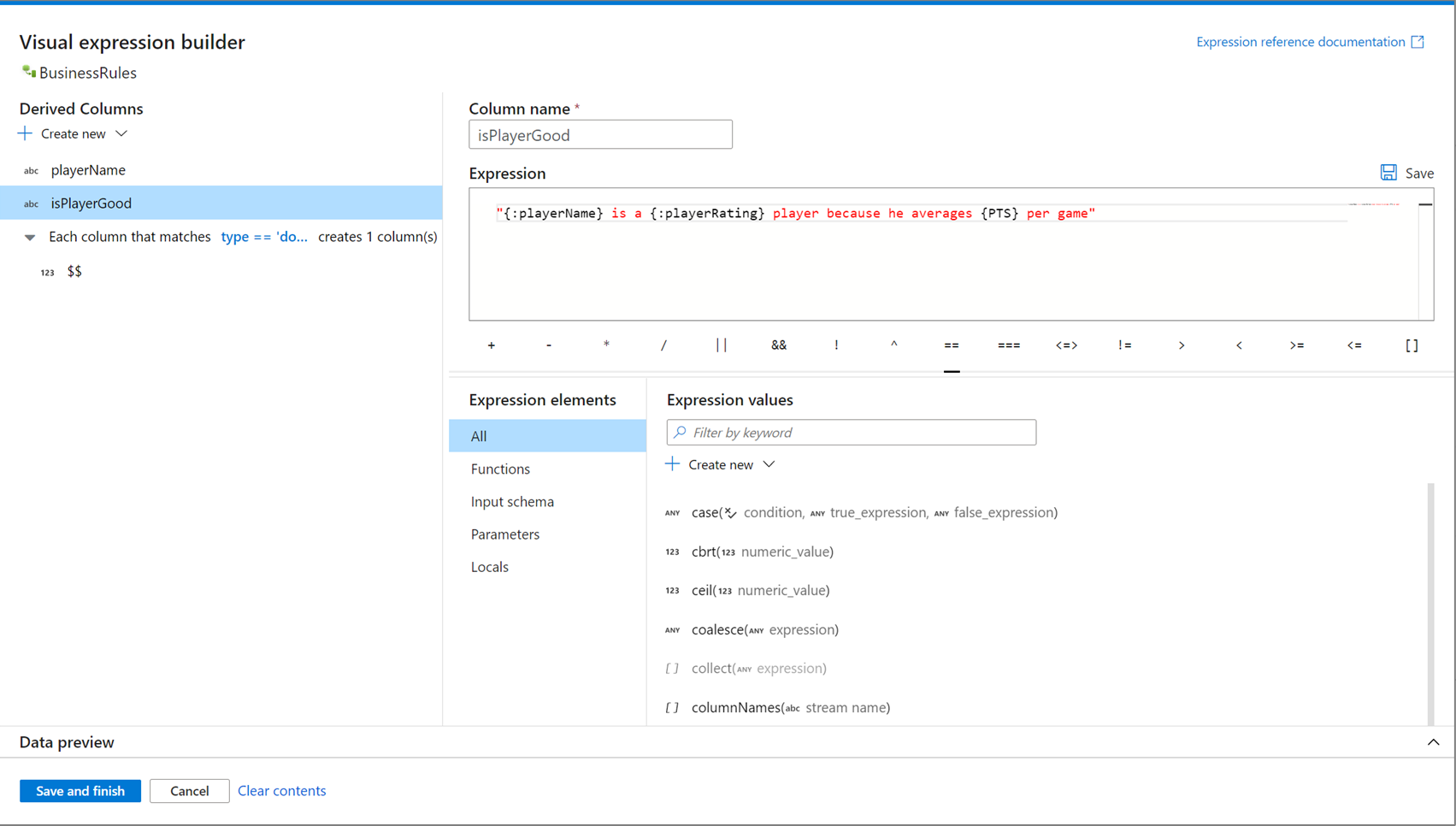
Apertura del generador de expresiones
Hay varios puntos de entrada para abrir el generador de expresiones. Todos ellos dependen del contexto específico de la transformación del flujo de datos. El caso de uso más común se da en las transformaciones como columna derivada y agregado, donde los usuarios crean o actualizan columnas con el lenguaje de expresiones de flujo de datos. El generador de expresiones se puede abrir al seleccionar Abrir el generador de expresiones encima de la lista de columnas. También puede seleccionar un contexto de columna y abrir el generador de expresiones directamente en esa expresión.
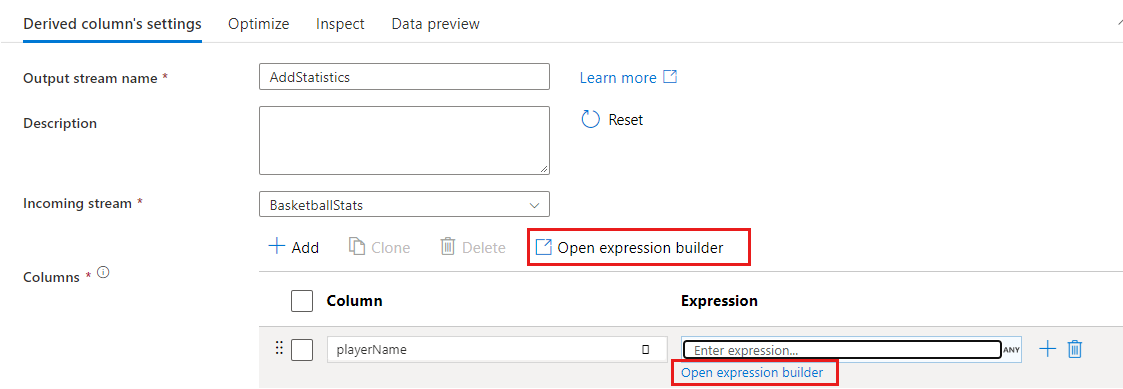
En algunas transformaciones, como Filtrar, al hacer clic en un cuadro de texto de expresión azul, se abre el generador de expresiones.
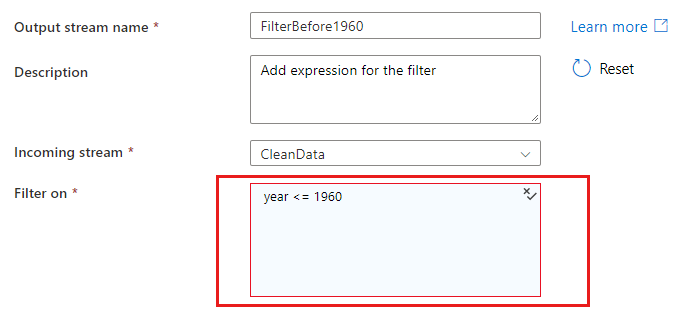
Al hacer referencia a columnas en una coincidencia o grupo por condición, una expresión puede extraer valores de las columnas. Para crear una expresión, seleccione la opción Columna calculada.

En los casos en los que una expresión o un valor literal son entradas válidas, Agregar contenido dinámico le permitirá crear una expresión que se evalúe como un literal.

Elementos de expresión
En la asignación de flujos de datos, las expresiones pueden estar compuestas de valores de columna, parámetros, funciones, variables locales, operadores y literales. Estas expresiones deben evaluarse como un tipo de datos de Spark, como una cadena, un valor booleano o un entero.
Functions
Los flujos de datos de asignación tienen funciones y operadores integrados que se pueden usar en las expresiones. Para obtener una lista de las funciones disponibles, vea la referencia sobre el lenguaje de flujos de datos de asignación.
Funciones definidas por el usuario (versión preliminar)
Los flujos de datos de asignación admiten la creación y el uso de funciones definidas por el usuario. Para ver cómo crear y usar funciones definidas por el usuario, consulte funciones definidas por el usuario.
Índices de matriz de direcciones
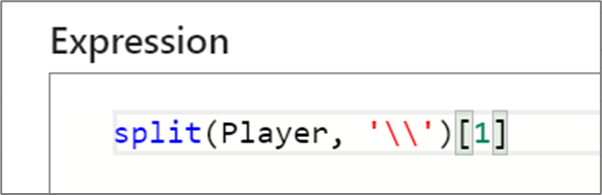
Cuando trabaje con columnas o funciones que devuelven tipos de matriz, use corchetes ([]) para acceder a un elemento específico. Si el índice no existe, la expresión se evalúa como NULL.
Importante
En los flujos de datos de asignación, las matrices se basan en uno, lo que significa que al primer elemento se hace referencia mediante la indexación de uno. Por ejemplo, myArray[1] accederá al primer elemento de una matriz denominada "myArray".
Esquema de entrada
Si el flujo de datos usa un esquema definido en cualquiera de sus orígenes, puede hacer referencia a una columna por nombre en muchas expresiones. Si usa el desfase de esquema, puede hacer referencia a las columnas explícitamente con las funciones byName() o byNames(), o bien buscar coincidencias con los patrones de columna.
Nombres de columna con caracteres especiales
Si tiene nombres de columna que incluyen caracteres especiales o espacios, escriba el nombre entre llaves para hacer referencia a estos en una expresión.
{[dbo].this_is my complex name$$$}
Parámetros
Los parámetros son valores que se pasan a un flujo de datos en tiempo de ejecución desde una canalización. Para hacer referencia a un parámetro, selecciónelo en la vista Elementos de expresión o haga referencia a él con un signo de dólar delante de su nombre. Por ejemplo, con $parameter1 se haría referencia a un parámetro denominado parameter1. Para más información, vea Parametrización de flujos de datos de asignación.
Búsqueda en caché
Una búsqueda en caché le permite realizar una búsqueda alineada de la salida de un receptor almacenado en la memoria caché. Hay dos funciones que se pueden usar en cada receptor, lookup() y outputs(). La sintaxis para hacer referencia a estas funciones es cacheSinkName#functionName(). Para obtener más información, vea el tema sobre receptores de caché.
lookup() toma las columnas coincidentes de la transformación actual como parámetros y devuelve una columna compleja igual a la fila que coincide con las columnas de clave del receptor de caché. La columna compleja devuelta contiene una subcolumna para cada columna asignada en el receptor de caché. Por ejemplo, si tuviera un receptor de caché con código de error errorCodeCache que tiene una columna de clave que coincide con el código y una columna llamada Message. La llamada a errorCodeCache#lookup(errorCode).Message devolvería el mensaje correspondiente al código que se ha pasado.
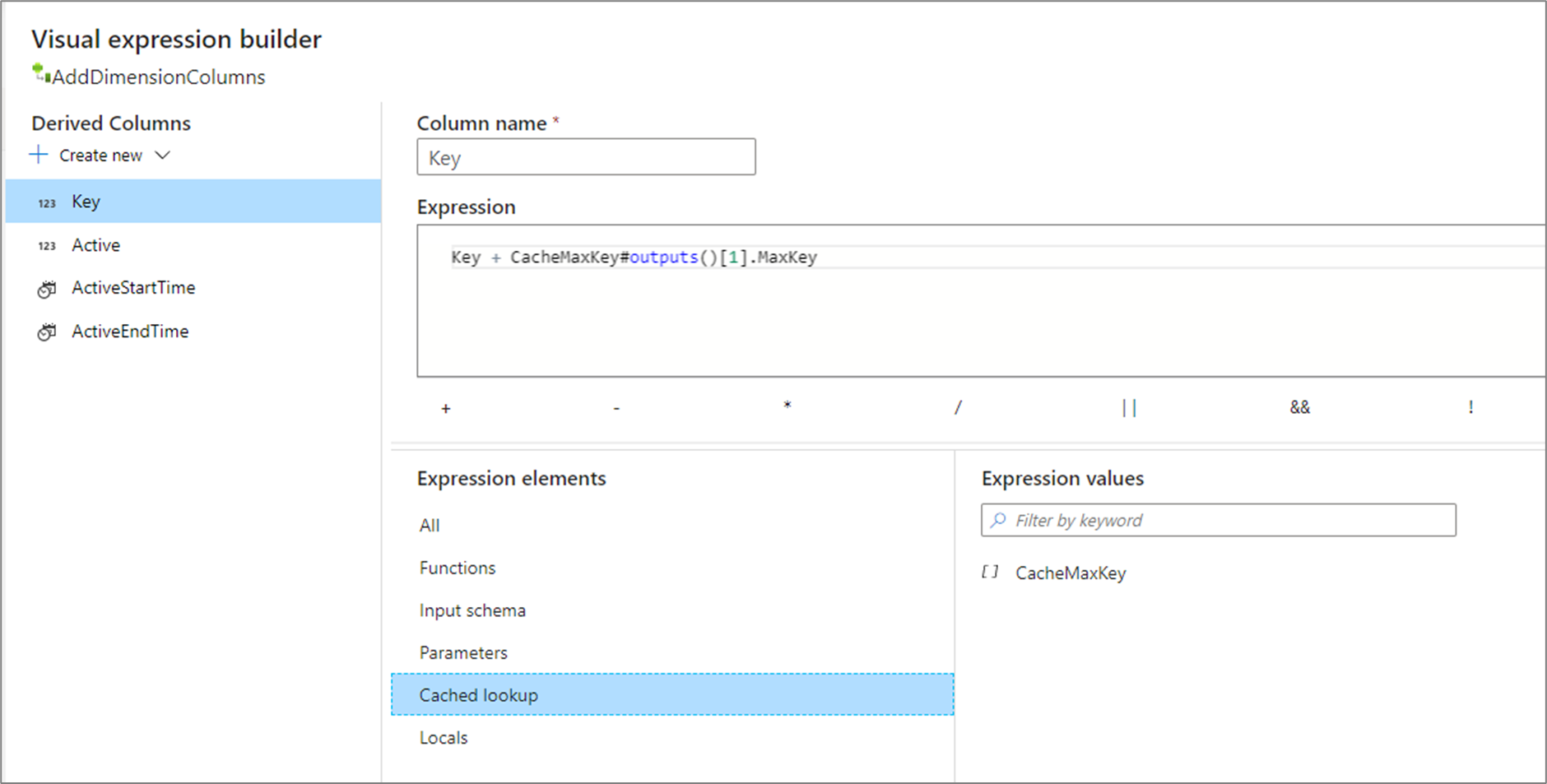
outputs() no toma ningún parámetro y devuelve el receptor de caché completo como una matriz de columnas complejas. No se puede llamar a este método si se especifican columnas de clave en el receptor y solo debe usarse si hay algunas filas en el receptor de caché. Un caso de uso común es anexar el valor máximo de una clave de incremento. Si una sola fila agregada almacenada en caché CacheMaxKey contiene una columna MaxKey, puede hacer referencia al primer valor llamando a CacheMaxKey#outputs()[1].MaxKey.
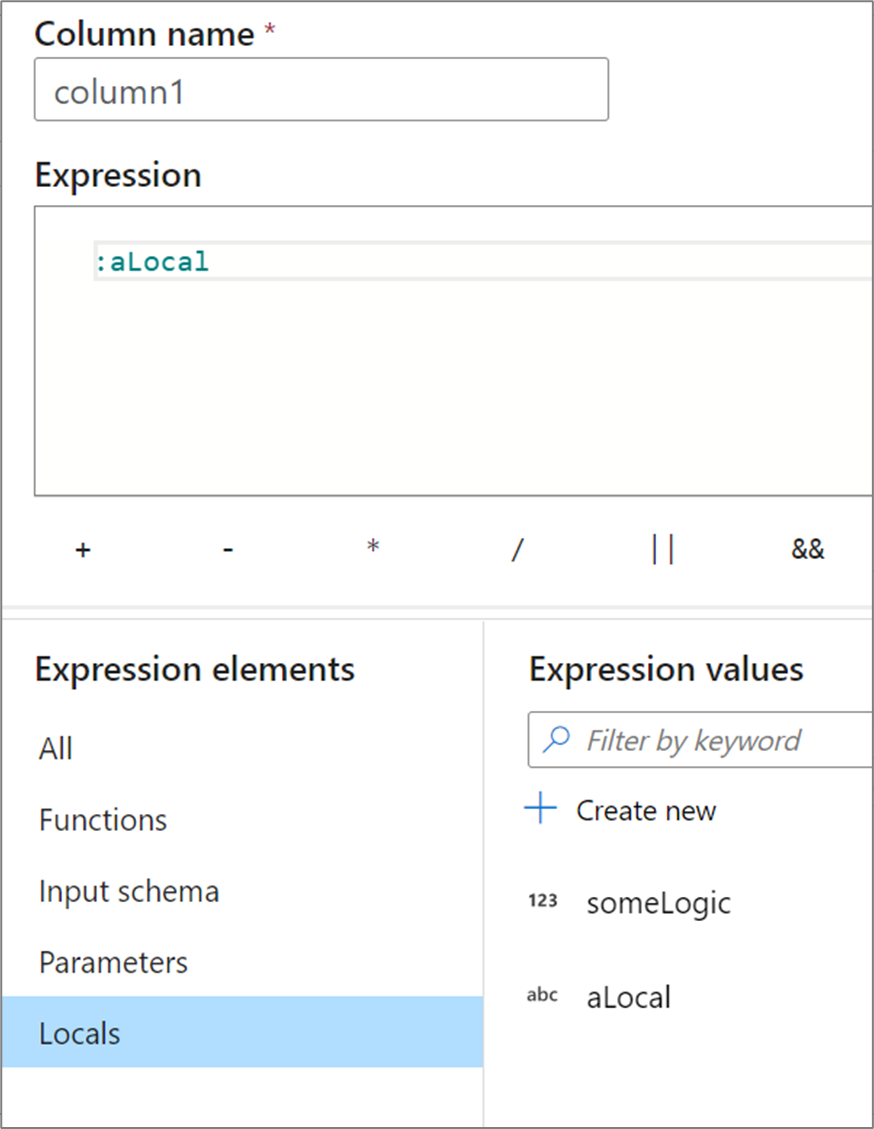
Locals
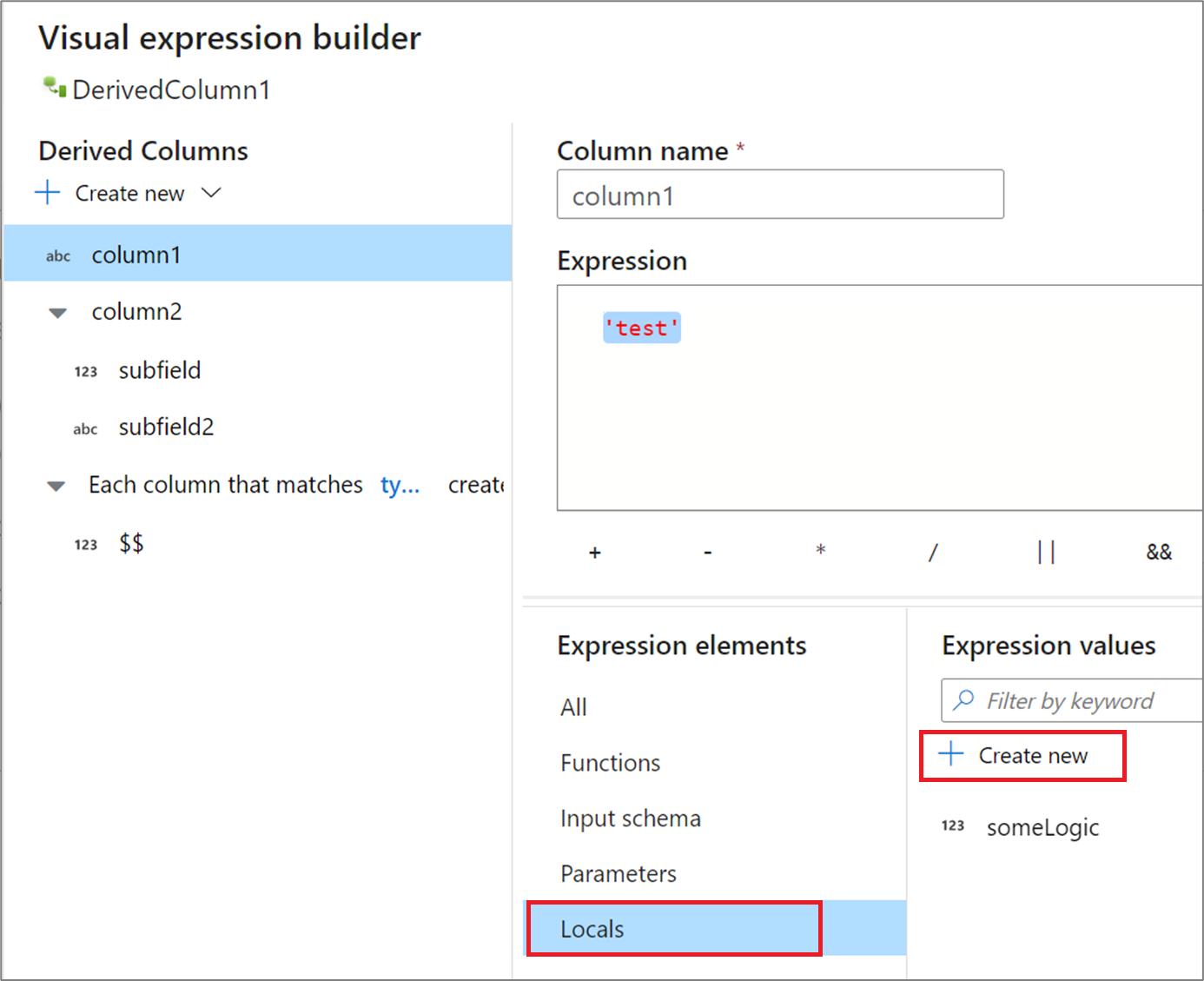
Si utiliza la misma lógica en varias columnas o desea compartimentarla, puede crear una variable local. Un conjunto local es un conjunto de la lógica que no se propaga a los elementos de nivel inferior durante la siguiente transformación. Los conjuntos locales pueden crearse en el generador de expresiones; para ello, vaya a Expression elements (Elementos de expresión) y seleccione Locals (Locales). Seleccione Create new (Crear nuevo) para crear un nuevo conjunto local.
Los conjuntos locales pueden referenciar cualquier elemento de expresión, como funciones, el esquema de entrada, parámetros y otros conjuntos locales. Cuando se hace referencia a otros conjuntos locales, el orden es importante, ya que el conjunto local al que se hace referencia debe ser "anterior" al actual.
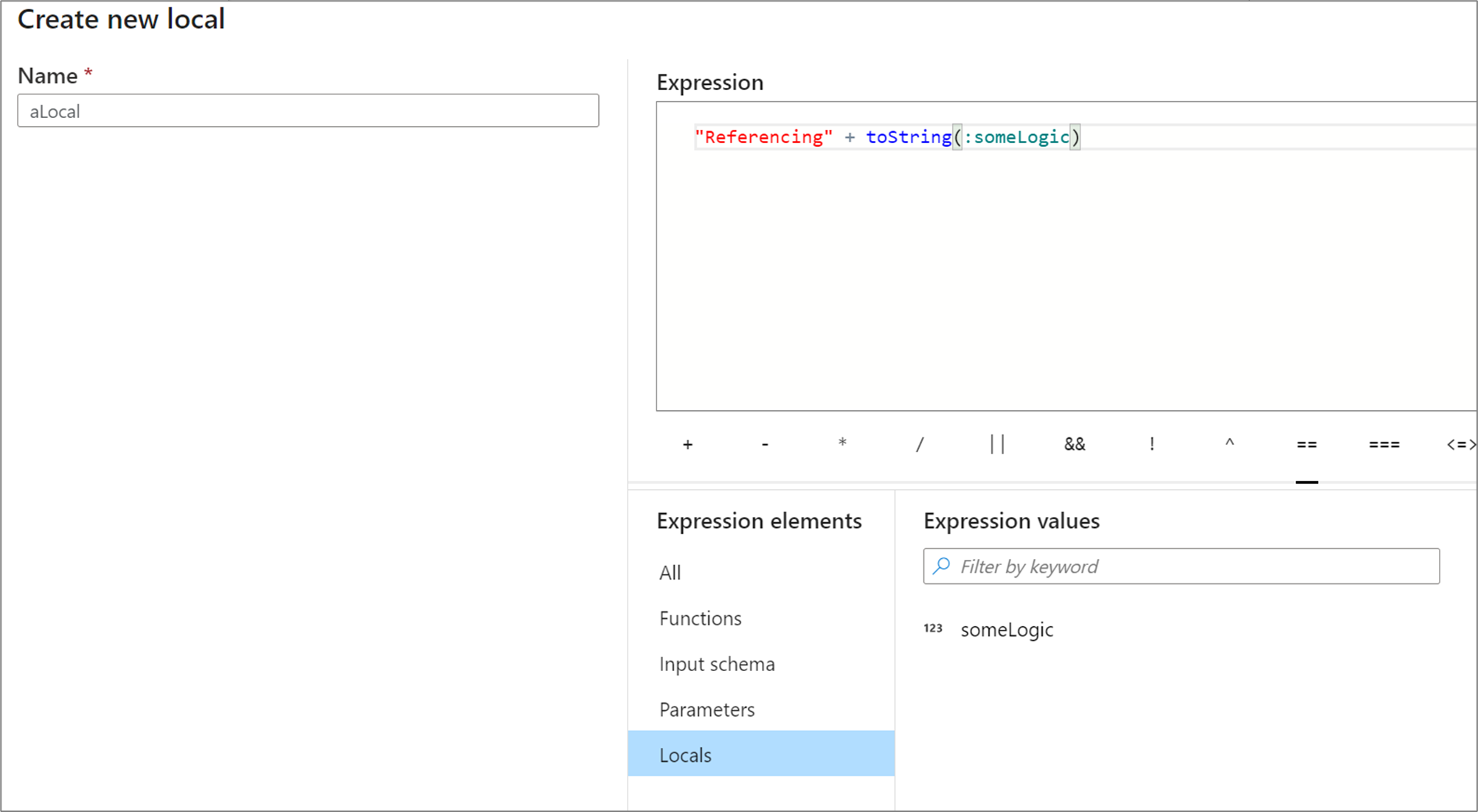
Para hacer referencia a una variable local en una transformación, selecciónela en la vista Elementos de expresión o haga referencia a ella escribiendo el signo de dos puntos delante del nombre. Por ejemplo, :local1 haría referencia a un conjunto local llamado local1. Para modificar la definición de una variable local, mantenga el mouse sobre ella en la vista Elementos de expresión y seleccione el icono de lápiz.
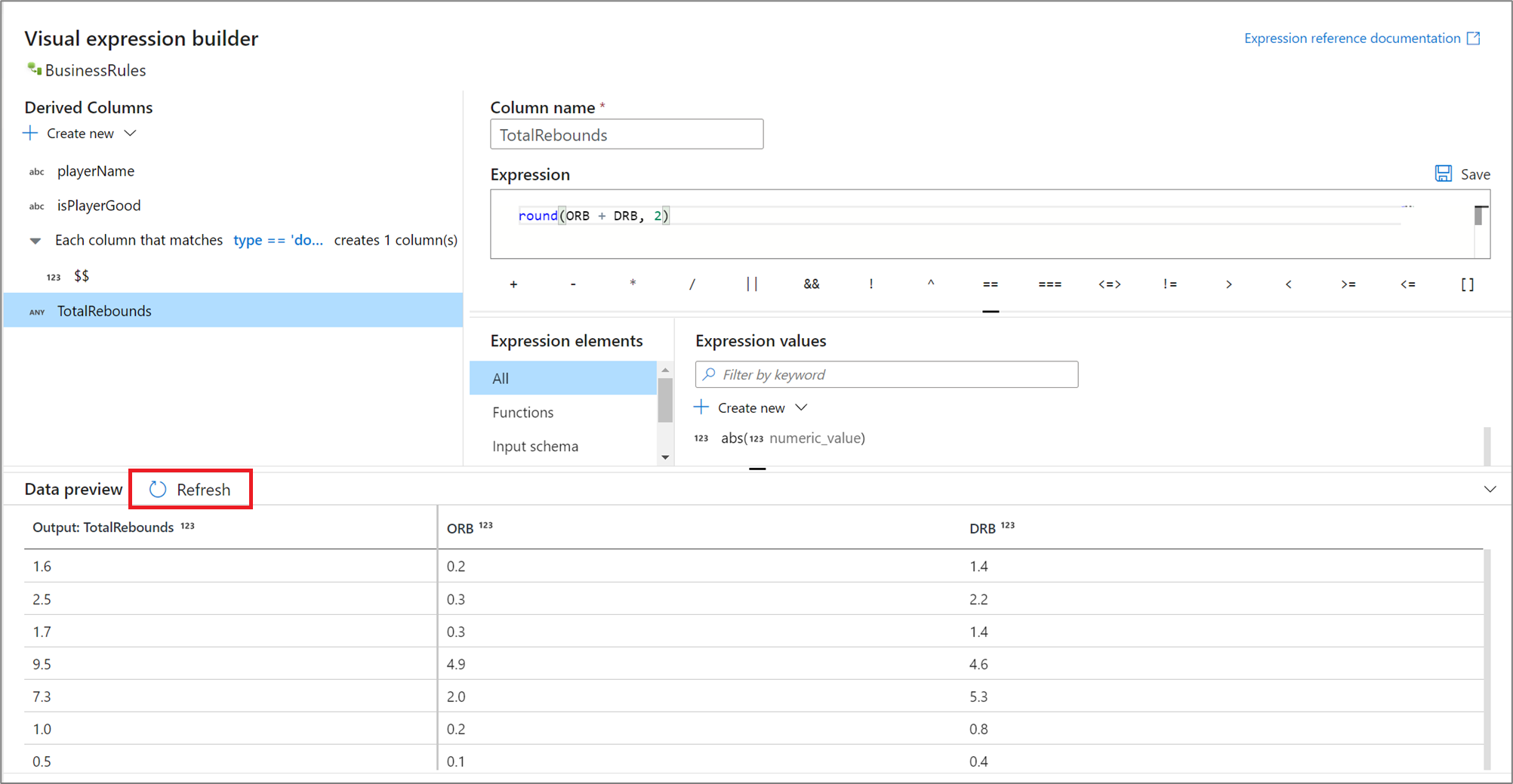
Resultados de la expresión en versión preliminar
Si el modo de depuración está activado, puede usar el clúster de depuración de manera interactiva para obtener una vista previa de lo que evalúa la expresión. Seleccione Actualizar junto a la vista previa de los datos para actualizar los resultados de la vista previa de los datos. Puede ver la salida de cada fila a partir de las columnas de entrada.
Interpolación de cadenas
Al crear cadenas largas que usan elementos de expresión, utilice la interpolación de cadenas para crear fácilmente una lógica de cadena compleja. La interpolación de cadena evita el uso extensivo de la concatenación de cadenas al incluir parámetros en cadenas de consulta. Use comillas dobles para incluir texto de cadena literal junto con expresiones. Puede incluir parámetros, columnas y funciones de expresión. Para usar la sintaxis de expresión, escríbala entre llaves.
Algunos ejemplos de interpolación de cadena:
"My favorite movie is {iif(instr(title,', The')>0,"The {split(title,', The')[1]}",title)}""select * from {$tablename} where orderyear > {$year}""Total cost with sales tax is {round(totalcost * 1.08,2)}""{:playerName} is a {:playerRating} player"
Nota
Cuando se usa la sintaxis de interpolación de cadenas en consultas de origen SQL, la cadena de consulta debe estar en una sola línea, sin "/n".
Comentarios de las expresiones
Agregue comentarios a sus expresiones mediante la sintaxis de comentarios de una línea y de varias líneas.
Los ejemplos siguientes son comentarios válidos:
/* This is my comment *//* This is amulti-line comment */
Si coloca un comentario al comienzo de la expresión, aparecerá en el cuadro de texto de transformación para documentar las expresiones de transformación.

Expresiones regulares
Muchas funciones de lenguaje de expresiones usan la sintaxis de expresión regular. Al utilizar las funciones de expresión regular, el Generador de expresiones intentará interpretar la barra diagonal inversa (\) como una secuencia de caracteres de escape. Al usar barras diagonales inversas en una expresión regular, encierre toda la expresión regular entre comillas simples (`) o utilice una doble barra diagonal inversa.
Un ejemplo que usa acentos graves:
regex_replace('100 and 200', `(\d+)`, 'digits')
Un ejemplo que usa barras diagonales dobles:
regex_replace('100 and 200', '(\\d+)', 'digits')
Accesos directos del teclado
A continuación, se muestra una lista de los accesos directos disponibles en el generador de expresiones. La mayoría de los accesos directos de IntelliSense están disponibles al crear expresiones.
- Ctrl+K, Ctrl+C: Línea entera de comentario.
- Ctrl+K, Ctrl+U: Quitar marca de comentario.
- F1: Proporcionar comandos de ayuda del editor.
- Flecha abajo: Bajar la línea actual.
- Alt+Flecha arriba: Subir la línea actual.
- Ctrl+Barra espaciadora: Mostrar ayuda contextual.
Expresiones de uso frecuente
Conversión en fechas o marcas de tiempo
Para incluir literales de cadena en la salida de la marca de tiempo, debe ajustar la conversión en toString().
toString(toTimestamp('12/31/2016T00:12:00', 'MM/dd/yyyy\'T\'HH:mm:ss'), 'MM/dd /yyyy\'T\'HH:mm:ss')
Para convertir los milisegundos de la época a una fecha o marca de tiempo, use toTimestamp(<number of milliseconds>). Si el tiempo estará disponible en segundos, multiplíquelo por 1000.
toTimestamp(1574127407*1000l)
El signo "l" final al final de la expresión anterior indica que hay una conversión a un tipo long como sintaxis insertada.
Búsqueda de hora desde época o tiempo UNIX
toLong( currentTimestamp() - toTimestamp('1970-01-01 00:00:00.000', 'yyyy-MM-dd HH:mm:ss.SSS') ) * 1000l
Evaluación del tiempo de flujo de datos
El flujo de datos procesa hasta milisegundos. Para 2018-07-31T20:00:00.2170000, verá 2018-07-31T20:00:00.217 en la salida. En el portal del servicio, la marca de tiempo se muestra en la configuración actual del explorador, que puede eliminar los 217 milisegundos. Sin embargo, si ejecuta el flujo de datos de un extremo a otro, se procesan también los milisegundos. Puede usar toString(myDateTimeColumn) como expresión y ver los datos de precisión completa en la versión preliminar. Procese datetime como datetime y no como string para todos los propósitos prácticos.
Contenido relacionado
Expresiones de transformación de datos en Asignación de Data Flow.