Uso de Azure Data Factory para migrar datos de Amazon S3 a Azure Storage
SE APLICA A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Azure Data Factory proporciona un mecanismo eficaz, sólido y rentable para migrar datos a escala desde Amazon S3 a Azure Blob Storage o Azure Data Lake Storage Gen2. En este artículo se proporciona la siguiente información para ingenieros de datos y desarrolladores:
- Rendimiento
- Resistencia de copia
- Seguridad de las redes
- Arquitectura de soluciones de alto nivel
- Procedimientos recomendados para la implementación
Rendimiento
ADF ofrece una arquitectura sin servidor que permite paralelismo en diferentes niveles, lo que permite a los desarrolladores crear canalizaciones para aprovechar al máximo el ancho de banda de red, y el ancho de banda y las IOPS de almacenamiento para maximizar el rendimiento del movimiento de datos para su entorno.
Nuestros clientes han migrado correctamente petabytes de datos, compuestos por cientos de millones de archivos, de Amazon S3 a Azure Blob Storage, con un rendimiento sostenido de 2 Gbps y superior.
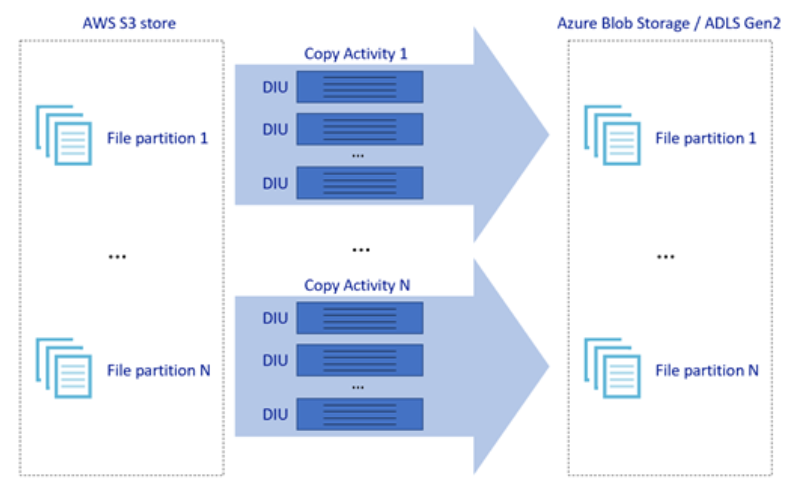
La imagen anterior muestra cómo puede lograr una gran velocidad de movimiento de datos a través de diferentes niveles de paralelismo:
- Una única actividad de copia puede aprovechar recursos de proceso escalables: si usa Azure Integration Runtime, puede especificar hasta 256 DIU para cada actividad de copia en modo sin servidor; si usa un entorno de ejecución de integración autohospedado, puede escalar verticalmente la máquina o escalar horizontalmente a varias máquinas (hasta cuatro nodos) manualmente y una única actividad de copia creará particiones de su conjunto de archivos en todos los nodos.
- Una única actividad de copia lee y escribe en el almacén de datos mediante varios subprocesos.
- El flujo de control de ADF puede iniciar varias actividades de copia en paralelo, por ejemplo, mediante un bucle ForEach.
Resistencia
Dentro de una ejecución de una única actividad de copia, ADF tiene un mecanismo de reintento integrado para que pueda controlar cierto nivel de errores transitorios en los almacenes de datos o en la red subyacente.
Al realizar copias binarias de S3 a BLOB y de S3 a ADLS Gen2, ADF realiza automáticamente puntos de control. Si se ha producido un error en la ejecución de la actividad de copia o se ha agotado el tiempo de espera, en un reintento posterior la copia se reanuda desde el último punto de error en lugar de comenzar desde el principio.
Seguridad de las redes
De forma predeterminada, ADF transfiere datos de Amazon S3 a Azure Blob Storage o Azure Data Lake Storage Gen2 mediante una conexión cifrada a través del protocolo HTTPS. HTTPS proporciona cifrado de datos en tránsito y evita la interceptación y ataques de tipo "Man in the middle".
Como alternativa, si no desea que los datos se transfieran a través de la red pública de Internet, puede lograr una mayor seguridad mediante la transferencia de datos a través de un vínculo de emparejamiento privado entre AWS Direct Connect y Azure Express Route. Consulte la arquitectura de la solución en la sección siguiente para obtener información sobre cómo lograr esto.
Arquitectura de la solución
Migración de datos a través de la red pública de Internet:
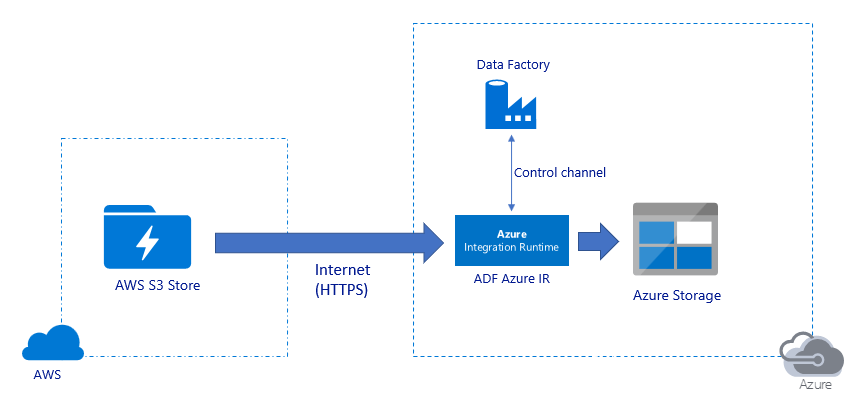
- En esta arquitectura, los datos se transfieren de forma segura mediante HTTPS a través de la red pública de Internet.
- El origen en Amazon S3 y el destino en Azure Blob Storage o Azure Data Lake Storage Gen2 están configurados para permitir el tráfico desde todas las direcciones IP de red. Consulte la segunda arquitectura que se menciona más adelante en esta página para obtener información sobre cómo puede restringir el acceso a la red a un intervalo de IP específico.
- Puede escalar fácilmente la cantidad de potencia en modo sin servidor para utilizar totalmente la red y el ancho de banda de almacenamiento, para obtener así el mejor rendimiento para su entorno.
- Tanto la migración de la instantánea inicial como la migración de datos diferencial se pueden realizar con esta arquitectura.
Migración de datos a través de un vínculo privado:
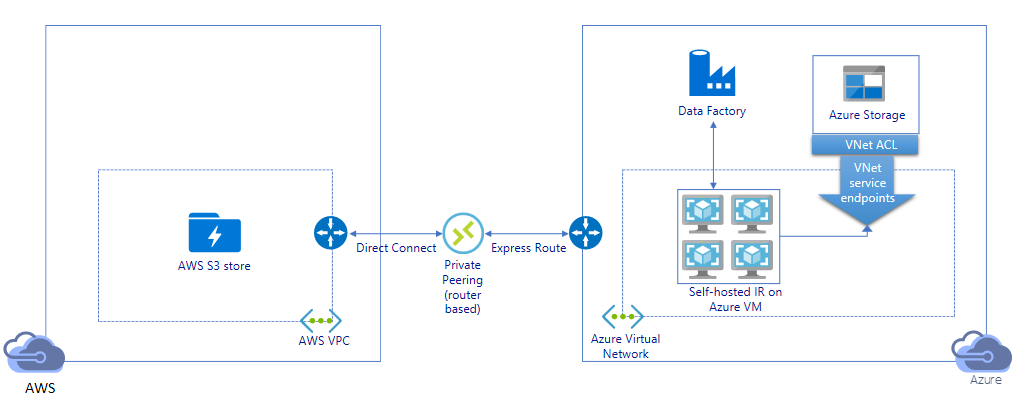
- En esta arquitectura, la migración de datos se realiza a través de un vínculo de emparejamiento privado entre AWS Direct Connect y Azure Express Route, de modo que los datos nunca atraviesan la red pública de Internet. Requiere el uso de AWS VPC y la red virtual de Azure.
- Debe instalar el entorno de ejecución de integración autohospedado de ADF en una máquina virtual de Windows dentro de la red virtual de Azure para lograr esta arquitectura. Puede escalar verticalmente las máquinas virtuales del entorno de ejecución de integración autohospedado o escalar horizontalmente a varias máquinas virtuales (hasta cuatro nodos) manualmente para aprovechar al máximo el ancho de banda/IOPS de almacenamiento y de la red.
- Tanto la migración de datos de la instantánea inicial como la migración de datos diferencial se pueden realizar con esta arquitectura.
Procedimientos recomendados para la implementación
Autenticación y administración de identidades
- Para autenticarse en una cuenta de Amazon S3, debe usar la clave de acceso para la cuenta de IAM.
- Se admiten varios tipos de autenticación para conectarse a Azure Blob Storage. Se recomienda encarecidamente el uso de identidades administradas para recursos de Azure: sobre la base de una identidad de ADF administrada automáticamente en Microsoft Entra ID, permite configurar canalizaciones sin proporcionar credenciales en la definición del servicio vinculado. Como alternativa, puede autenticarse en Azure Blob Storage mediante la entidad de servicio, la firma de acceso compartido o la clave de la cuenta de almacenamiento.
- También se admiten varios tipos de autenticación para conectarse a Azure Data Lake Storage Gen2. Se recomienda encarecidamente el uso de identidades administradas para recursos de Azure, aunque también se puede usar la entidad de servicio o la clave de la cuenta de almacenamiento.
- Si no usa identidades administradas para recursos de Azure, es muy recomendable almacenar las credenciales en Azure Key Vault para facilitar la administración y la rotación de las claves de forma centralizada sin modificar los servicios vinculados de ADF. Este es también uno de los procedimientos recomendados para CI/CD.
Migración de datos de instantánea inicial
Se recomienda la partición de los datos especialmente al migrar más de 100 TB. Para crear una partición de los datos, use el valor de "prefijo" para filtrar las carpetas y los archivos de Amazon S3 por nombre y, a continuación, cada trabajo de copia de ADF podrá copiar una partición cada vez. Puede ejecutar varios trabajos de copia de ADF simultáneamente para mejorar el rendimiento.
Si se produce un error en alguno de los trabajos de copia debido a una incidencia transitoria de la red o del almacén de datos, puede volver a ejecutar el trabajo de copia con errores para volver a cargar esa partición específica de AWS S3. El resto de los trabajos de copia que cargan otras particiones no se verán afectados.
Migración de datos diferencial
La manera más eficaz de identificar archivos nuevos o modificados de AWS S3 es mediante la convención de nomenclatura con particiones de tiempo: cuando los datos de AWS S3 se han particionado en el tiempo con información del intervalo de tiempo en el nombre de archivo o carpeta (por ejemplo,/aaaa/mm/dd/archivo.csv), la canalización puede identificar fácilmente qué archivos o carpetas copiar de forma incremental.
Como alternativa, si los datos de AWS S3 no tienen particiones de tiempo, ADF puede identificar los archivos nuevos o modificados por el valor de LastModifiedDate (fecha de la última modificación). Para ello, ADF examinará todos los archivos de AWS S3 y solo copiará el archivo nuevo y actualizado cuya marca de tiempo de última modificación sea mayor que un valor determinado. Si tiene un gran número de archivos en S3, el análisis de archivos inicial podría tardar mucho tiempo, independientemente de la cantidad de archivos que cumplan la condición de filtro. En este caso, se recomienda crear primero particiones de los datos, con el mismo valor de "prefijo" para la migración de instantánea inicial, de modo que el análisis de archivos pueda realizarse en paralelo.
Escenarios que requieren un entorno de ejecución de integración autohospedado en una máquina virtual de Azure
Si va a migrar datos a través de un vínculo privado o si desea permitir un intervalo de IP específico en el firewall de Amazon S3, debe instalar un entorno de ejecución de integración autohospedado en la máquina virtual Windows de Azure.
- La configuración recomendada para empezar para cada máquina virtual de Azure es Standard_D32s_v3 con 32 vCPU y 128 GB de memoria. Puede seguir supervisando el uso de la CPU y la memoria de la máquina virtual del entorno de ejecución de integración durante la migración de datos para ver si necesita escalar verticalmente la máquina virtual para mejorar el rendimiento o reducir verticalmente la máquina virtual para ahorrar costos.
- También, para escalar horizontalmente, puede asociar hasta cuatro nodos de VM a un único IR autohospedado. Un único trabajo de copia que se ejecute en un entorno de ejecución de integración autohospedado particionará automáticamente el conjunto de archivos y usará todos los nodos de máquina virtual para copiar los archivos en paralelo. Para lograr una alta disponibilidad, se recomienda empezar con dos nodos de máquina virtual para evitar que haya un único punto de error durante la migración de datos.
Limitación de frecuencia
Como procedimiento recomendado, lleve a cabo una prueba de concepto de rendimiento con un conjunto de datos de ejemplo representativo, a fin de determinar el tamaño de partición adecuado.
Comience con una sola partición y una única actividad de copia con la configuración de DIU predeterminada. Aumente gradualmente el valor de DIU hasta alcanzar el límite de ancho de banda de la red o el límite de ancho de banda/IOPS de los almacenes de datos, o hasta alcanzar el máximo de 256 DIU permitido en una única actividad de copia.
A continuación, aumente gradualmente el número de actividades de copia simultáneas hasta alcanzar los límites de su entorno.
Si encuentra errores de limitación notificados por la actividad de copia de ADF, reduzca el valor de simultaneidad o DIU en ADF, o considere la posibilidad de aumentar los límites de ancho de banda/IOPS de la red y los almacenes de datos.
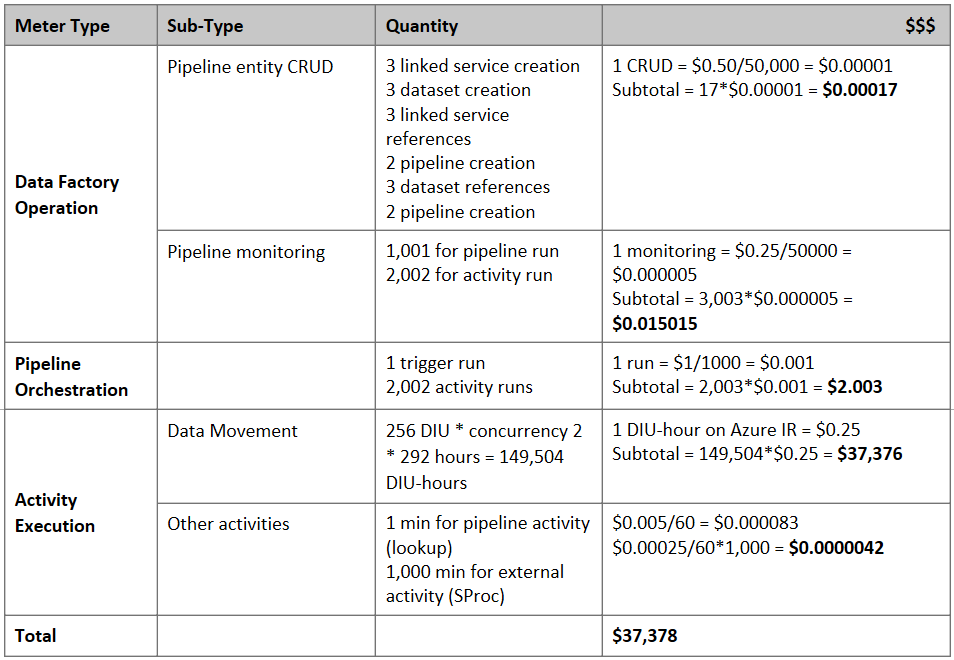
Estimación del precio
Nota
Este es un ejemplo de precios hipotético. Los precios reales dependen del rendimiento real de su entorno.
Considere la siguiente canalización construida para migrar datos de S3 a Azure Blob Storage:
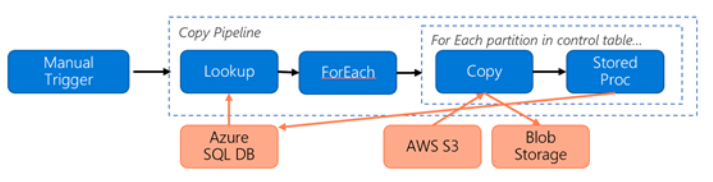
Supongamos lo siguiente:
- El volumen total de datos es de 2 PB.
- La migración de datos a través de HTTPS usa la primera arquitectura de la solución.
- Los 2 PB se dividen en particiones de 1 KB y cada copia mueve una partición.
- Cada copia se configura con DIU = 256 y consigue un rendimiento de 1 Gbps.
- La simultaneidad de ForEach se establece en 2 y el rendimiento agregado es de 2 Gbps.
- En total, se tardan 292 horas en completar la migración.
Este es el precio estimado en función de las suposiciones anteriores:
Referencias adicionales
- Conector de Amazon Simple Storage Service
- Conector de Azure Blob Storage
- Conector de Azure Data Lake Storage Gen2
- Guía de optimización y rendimiento de la actividad de copia
- Creación y configuración de un entorno de ejecución de integración autohospedado
- Alta disponibilidad y escalabilidad de un entorno de ejecución de integración autohospedado
- Consideraciones sobre la seguridad del movimiento de datos
- Almacenamiento de credenciales en Azure Key Vault
- Copia incremental de nuevos archivos por el nombre de archivo con particiones de tiempo
- Copia incremental de archivos nuevos y modificados según LastModifiedDate
- Página de precios de ADF
Plantilla
A continuación tiene la plantilla para migrar petabytes de datos compuestos por cientos de millones de archivos de Amazon S3 a Azure Data Lake Storage Gen2.