Migración de datos de Amazon S3 a Azure Data Lake Storage Gen2
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Use las plantillas para migrar petabytes de datos compuestos por cientos de millones de archivos de Amazon S3 a Azure Data Lake Storage Gen2.
Nota
Si desea copiar pequeños volúmenes de datos de AWS S3 a Azure (por ejemplo, menos de 10 TB), es más eficaz y fácil usar la herramienta Copiar datos de Azure Data Factory. La plantilla que se describe en este artículo es más de lo que necesita.
Sobre las plantillas de solución
La partición de datos se recomienda especialmente al migrar más de 10 TB de datos. Para crear una partición de los datos, utilice el valor de "prefijo" para filtrar las carpetas y los archivos en Amazon S3 por nombre y, a continuación, cada trabajo de copia de ADF podrá copiar una partición cada vez. Puede ejecutar varios trabajos de copia de ADF simultáneamente para mejorar el rendimiento.
La migración de datos normalmente requiere una migración de datos históricos única más la sincronización periódica de los cambios de AWS S3 a Azure. A continuación se presentan dos plantillas; una de ellas cubre la migración de datos históricos única y la otra la sincronización de los cambios de AWS S3 a Azure.
Para la plantilla para migrar datos históricos de Amazon S3 a Azure Data Lake Storage Gen2
En esta plantilla (nombre de plantilla: Migrar datos históricos desde AWS S3 en Azure Data Lake Storage Gen2) se asume que ha escrito una lista de particiones en una tabla de control externa en Azure SQL Database. Por lo tanto, usará una actividad Lookup para recuperar la lista de particiones de la tabla de control externa, iterar en cada partición y hacer que cada trabajo de copia de ADF copie una partición cada vez. Una vez completado cualquier trabajo de copia, utiliza la actividad Stored Procedure para actualizar el estado de copia de cada partición en la tabla de control.
La plantilla contiene cinco actividades:
- Lookup recupera las particiones que no se han copiado a Azure Data Lake Storage Gen2 de una tabla de control externa. El nombre de la tabla es s3_partition_control_table y la consulta para cargar datos de la tabla es "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0" .
- ForEach obtiene la lista de particiones de la actividad Lookup e itera cada partición para la actividad TriggerCopy. Puede establecer batchCount para ejecutar varios trabajos de copia de ADF simultáneamente. Hemos establecido 2 en esta plantilla.
- ExecutePipeline ejecuta la canalización CopyFolderPartitionFromS3. El motivo por el que creamos otra canalización para que cada trabajo de copia copie una partición es porque le facilitará volver a ejecutar el trabajo de copia con errores para volver a cargar esa partición específica desde AWS S3. El resto de los trabajos de copia que cargan otras particiones no se verán afectados.
- Copy copia cada partición desde AWS S3 en Azure Data Lake Storage Gen2.
- SqlServerStoredProcedure actualiza el estado de copia de cada partición en la tabla de control.
La plantilla contiene dos parámetros:
- AWS_S3_bucketName es el nombre del cubo en AWS S3 desde el que desea migrar los datos. Si quiere migrar datos de varios cubos en AWS S3, puede agregar una columna más en la tabla de control externa para almacenar el nombre de cubo de cada partición y también actualizar la canalización para recuperar los datos de esa columna en consecuencia.
- Azure_Storage_fileSystem es el nombre del sistema de archivos en Azure Data Lake Storage Gen2 a donde desea migrar los datos.
Para que la plantilla copie los archivos modificados solo desde Amazon S3 en Azure Data Lake Storage Gen2
Esta plantilla (nombre de plantilla: Copiar datos delta desde AWS S3 en Azure Data Lake Storage Gen2) usa LastModifiedTime de cada archivo para copiar los archivos nuevos o actualizados solo desde AWS S3 en Azure. Tenga en cuenta que si los archivos o carpetas ya se han particionado con información del período de tiempo como parte del nombre de archivo o carpeta en AWS S3 (por ejemplo, /aaaa/mm/dd/archivo.csv), puede ir a este tutorial para obtener el mejor enfoque de rendimiento para la carga incremental de nuevos archivos. En esta plantilla se supone que ha escrito una lista de particiones en una tabla de control externa en Azure SQL Database. Por lo tanto, usará una actividad Lookup para recuperar la lista de particiones de la tabla de control externa, iterar en cada partición y hacer que cada trabajo de copia de ADF copie una partición cada vez. Cuando cada trabajo de copia comienza a copiar los archivos desde AWS S3, se basa en la propiedad LastModifiedTime para identificar y copiar solo los archivos nuevos o actualizados. Una vez completado cualquier trabajo de copia, utiliza la actividad Stored Procedure para actualizar el estado de copia de cada partición en la tabla de control.
La plantilla contiene siete actividades:
- Lookup recupera las particiones desde una tabla de control externa. El nombre de la tabla es s3_partition_delta_control_table y la consulta para cargar datos desde la tabla es "select distinct PartitionPrefix from s3_partition_delta_control_table" .
- ForEach obtiene la lista de particiones de la actividad Lookup e itera cada partición para la actividad TriggerDeltaCopy. Puede establecer batchCount para ejecutar varios trabajos de copia de ADF simultáneamente. Hemos establecido 2 en esta plantilla.
- ExecutePipeline ejecuta la canalización DeltaCopyFolderPartitionFromS3. El motivo por el que creamos otra canalización para que cada trabajo de copia copie una partición es porque le facilitará volver a ejecutar el trabajo de copia con errores para volver a cargar esa partición específica desde AWS S3. El resto de los trabajos de copia que cargan otras particiones no se verán afectados.
- Lookup recupera la hora en la que se realizó la última ejecución del trabajo de copia de la tabla de control externa para que los archivos nuevos o actualizados se puedan identificar a través de LastModifiedTime. El nombre de la tabla es s3_partition_delta_control_table y la consulta para cargar datos de la tabla es "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1" .
- Copy copia cada archivo nuevo o cambiado solo para partición desde AWS S3 en Azure Data Lake Storage Gen2. La propiedad de modifiedDatetimeStart se establece en la hora en la que se realizó la ejecución del trabajo de copia por última vez. La propiedad de modifiedDatetimeEnd se establece en la hora actual de ejecución del trabajo de copia. Tenga en cuenta que la hora se aplica a la zona horaria UTC.
- SqlServerStoredProcedure actualiza el estado de copia de cada partición y la hora de ejecución de copia en la tabla de control cuando se realiza correctamente. La columna de SuccessOrFailure se establece en 1.
- SqlServerStoredProcedure actualiza el estado de copia de cada partición y la hora de ejecución de copia en la tabla de control cuando da error. La columna de SuccessOrFailure se establece en 0.
La plantilla contiene dos parámetros:
- AWS_S3_bucketName es el nombre del cubo en AWS S3 desde el que desea migrar los datos. Si quiere migrar datos de varios cubos en AWS S3, puede agregar una columna más en la tabla de control externa para almacenar el nombre de cubo de cada partición y también actualizar la canalización para recuperar los datos de esa columna en consecuencia.
- Azure_Storage_fileSystem es el nombre del sistema de archivos en Azure Data Lake Storage Gen2 a donde desea migrar los datos.
Uso de estas dos plantillas de soluciones
Para la plantilla para migrar datos históricos de Amazon S3 a Azure Data Lake Storage Gen2
Cree una tabla de control en Azure SQL Database para almacenar la lista de particiones de AWS S3.
Nota
El nombre de la tabla es s3_partition_control_table. El esquema de la tabla de control es PartitionPrefix y SuccessOrFailure, donde PartitionPrefix es el valor de prefijo de S3 para filtrar las carpetas y los archivos de Amazon S3 por nombre y SuccessOrFailure es el estado de copia de cada partición: 0 significa que esta partición no se ha copiado en Azure y 1 significa que esta partición se ha copiado en Azure correctamente. Hay 5 particiones definidas en la tabla de control y el estado predeterminado de copia de cada partición es 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Cree un procedimiento almacenado en la misma instancia de Azure SQL Database para la tabla de control.
Nota
El nombre del procedimiento almacenado es sp_update_partition_success. Lo invocará la actividad SqlServerStoredProcedure en la canalización de ADF.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOVaya a la plantilla Migrar datos históricos desde AWS S3 en Azure Data Lake Storage Gen2. Introduzca las conexiones en la tabla de control externa, AWS S3 como el almacén de origen de datos y Azure Data Lake Storage Gen2 como el almacén de destino. Tenga en cuenta que la tabla de control externa y el procedimiento almacenado hacen referencia a la misma conexión.
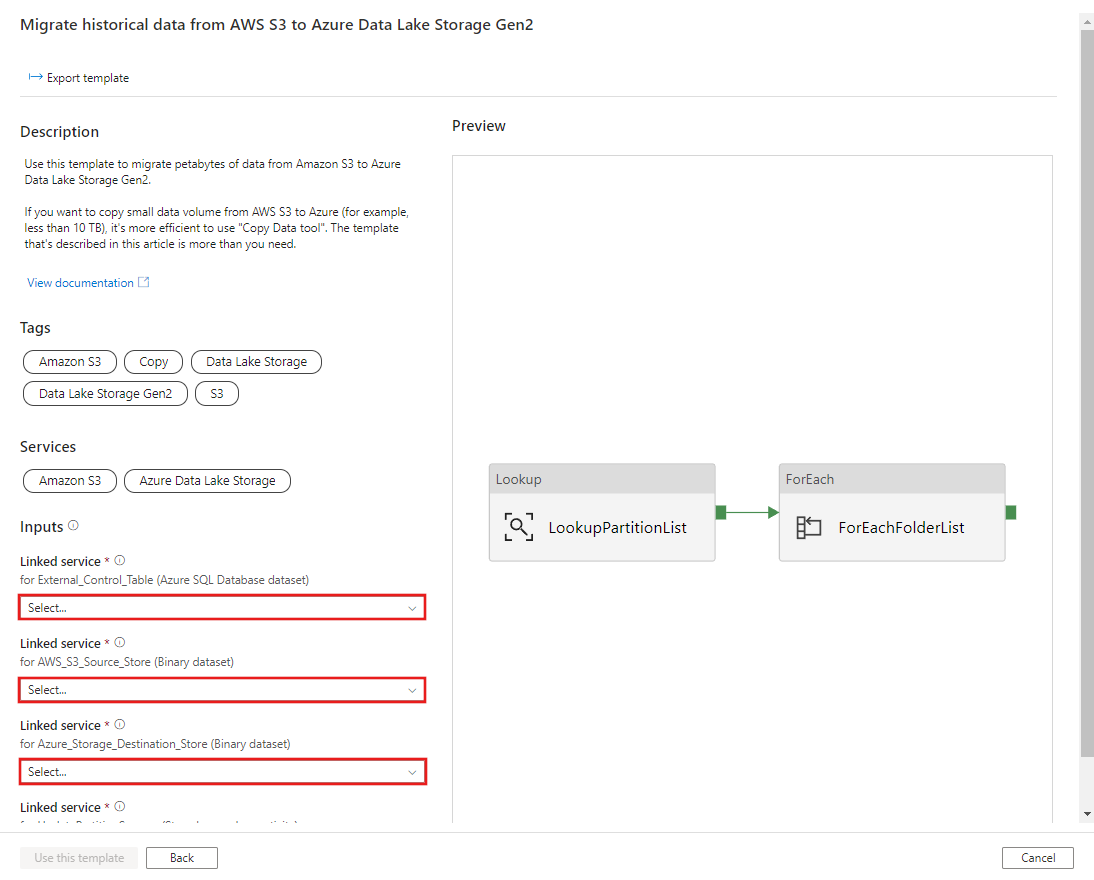
Seleccione Usar esta plantilla.
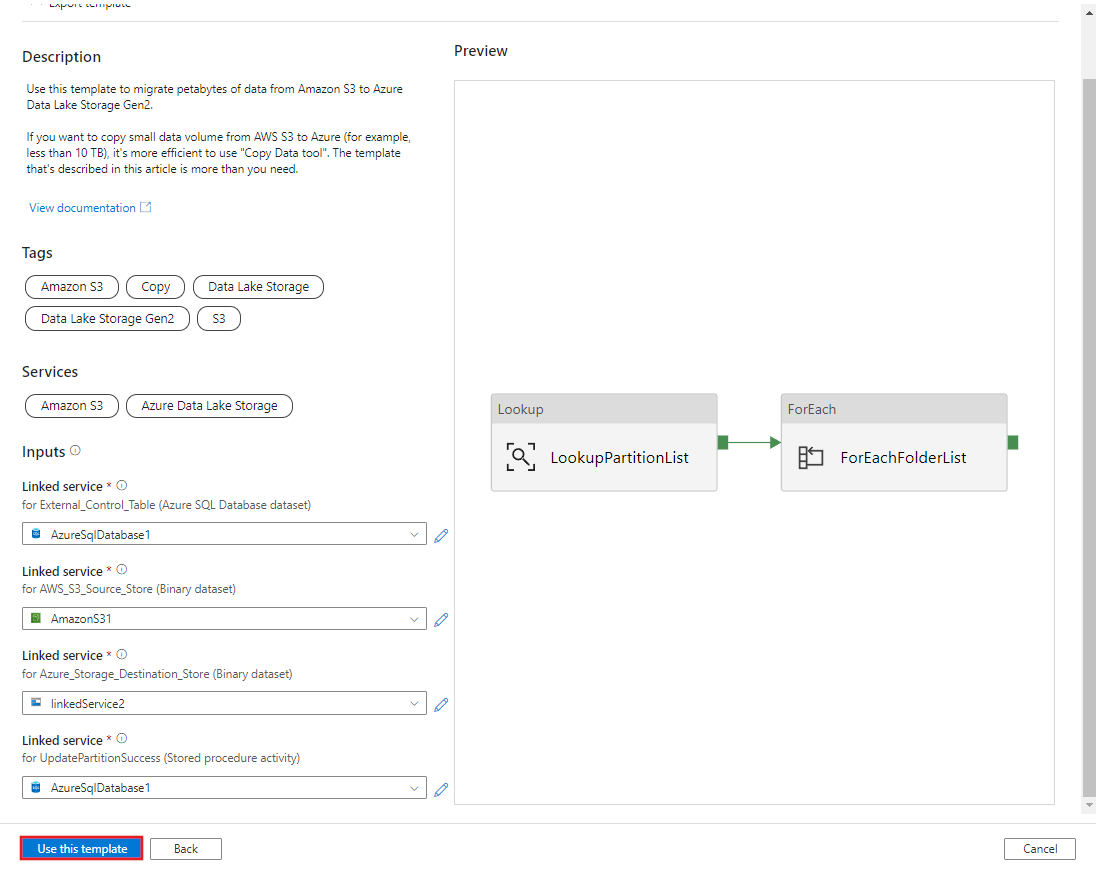
Verá que se crearon dos canalizaciones y tres conjuntos de valores, tal como se muestra en el ejemplo siguiente:
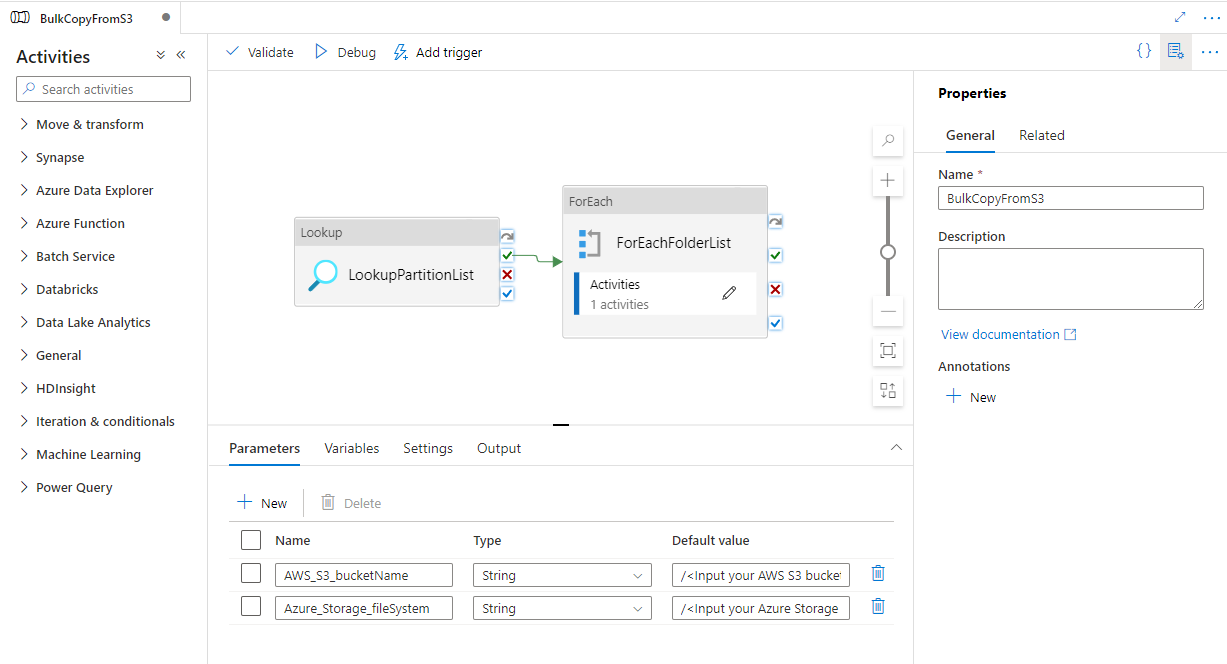
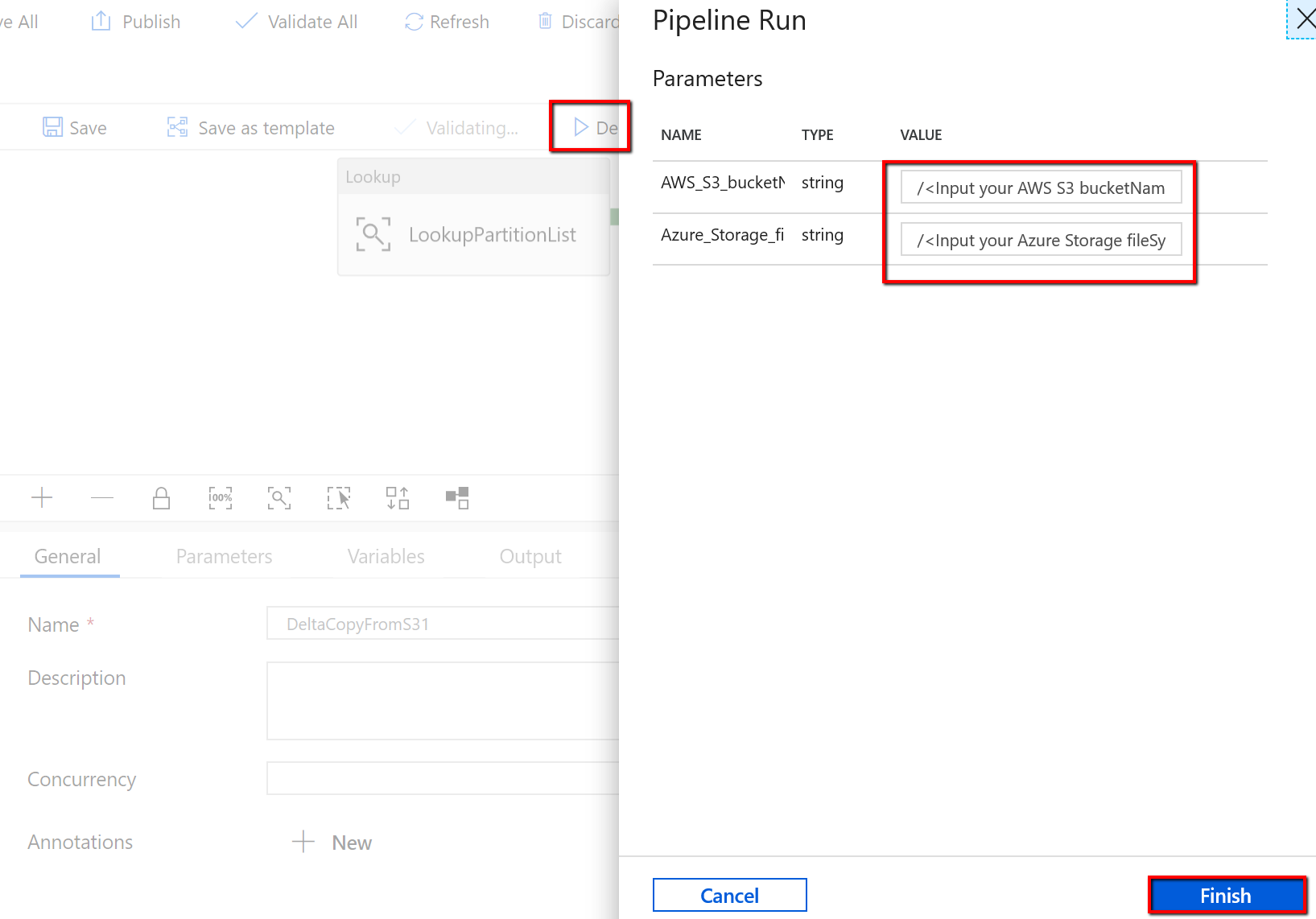
Vaya a la canalización "BulkCopyFromS3", seleccione Depurar y escriba los parámetros. A continuación, seleccione Finish (Finalizar).
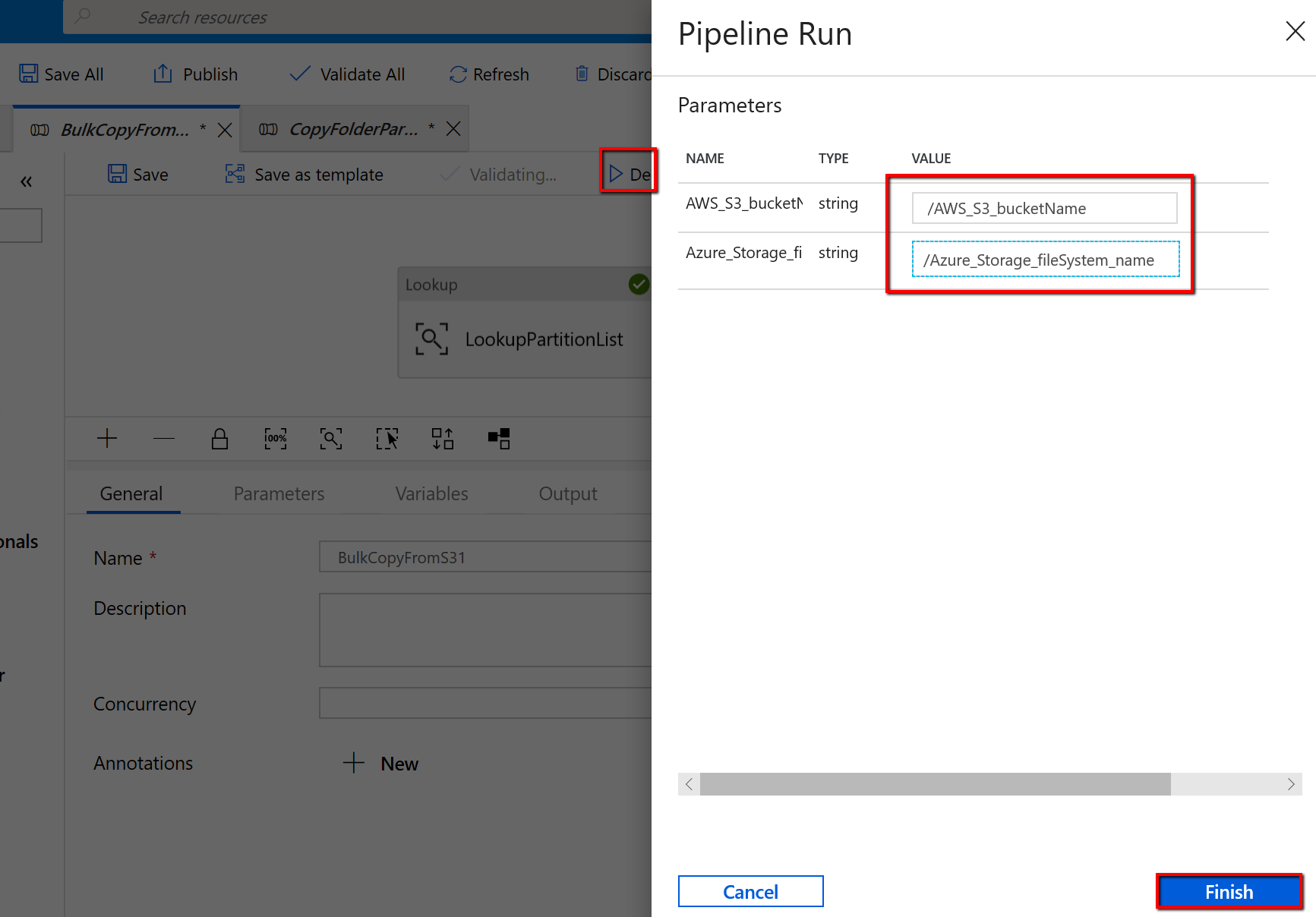
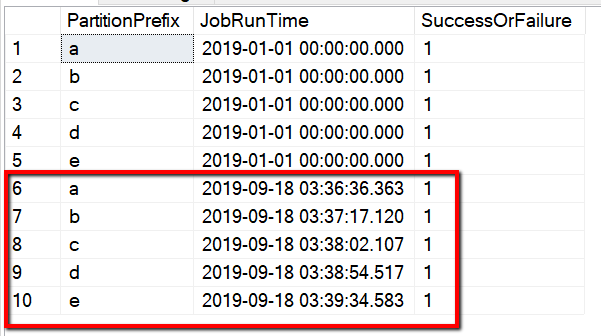
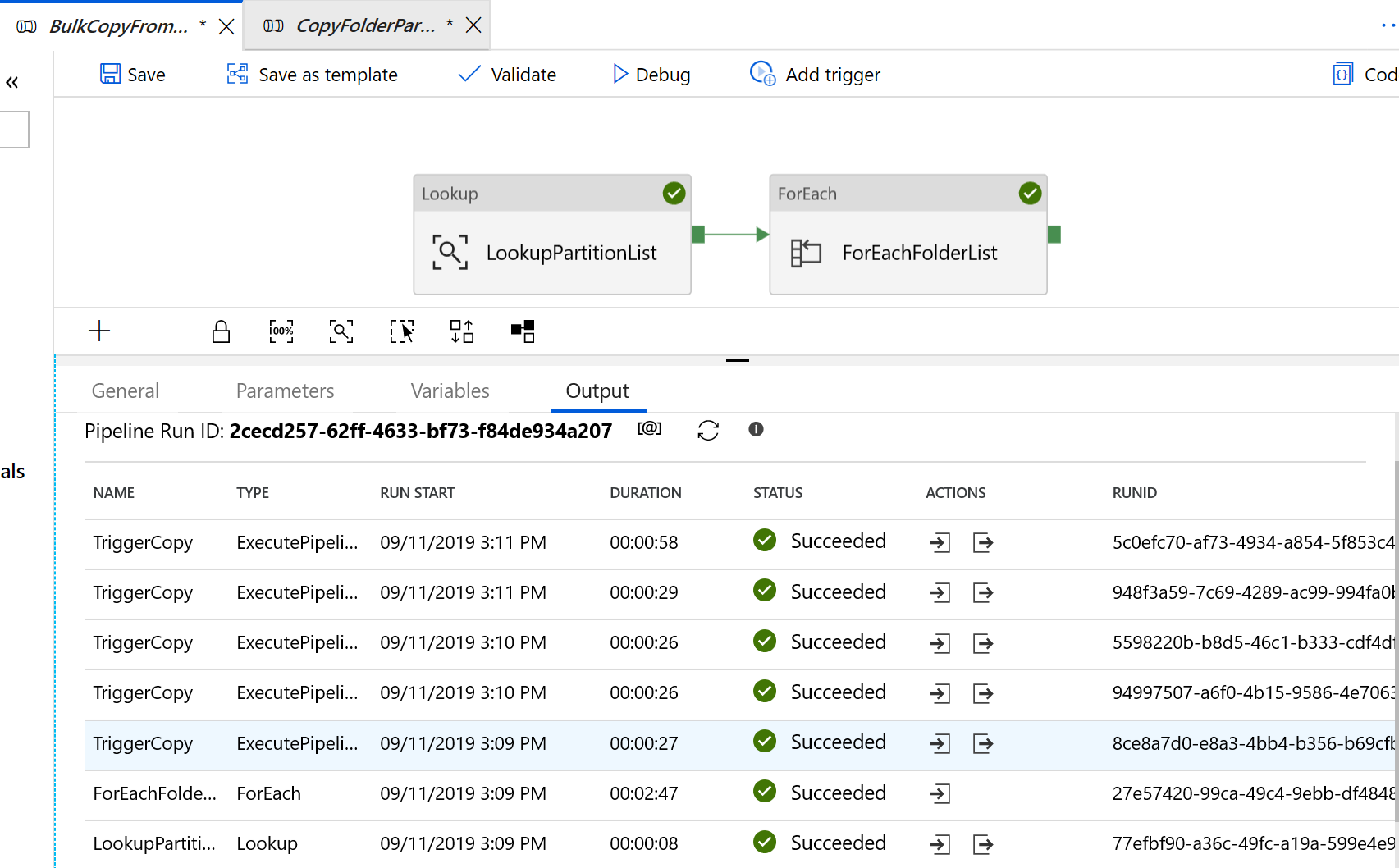
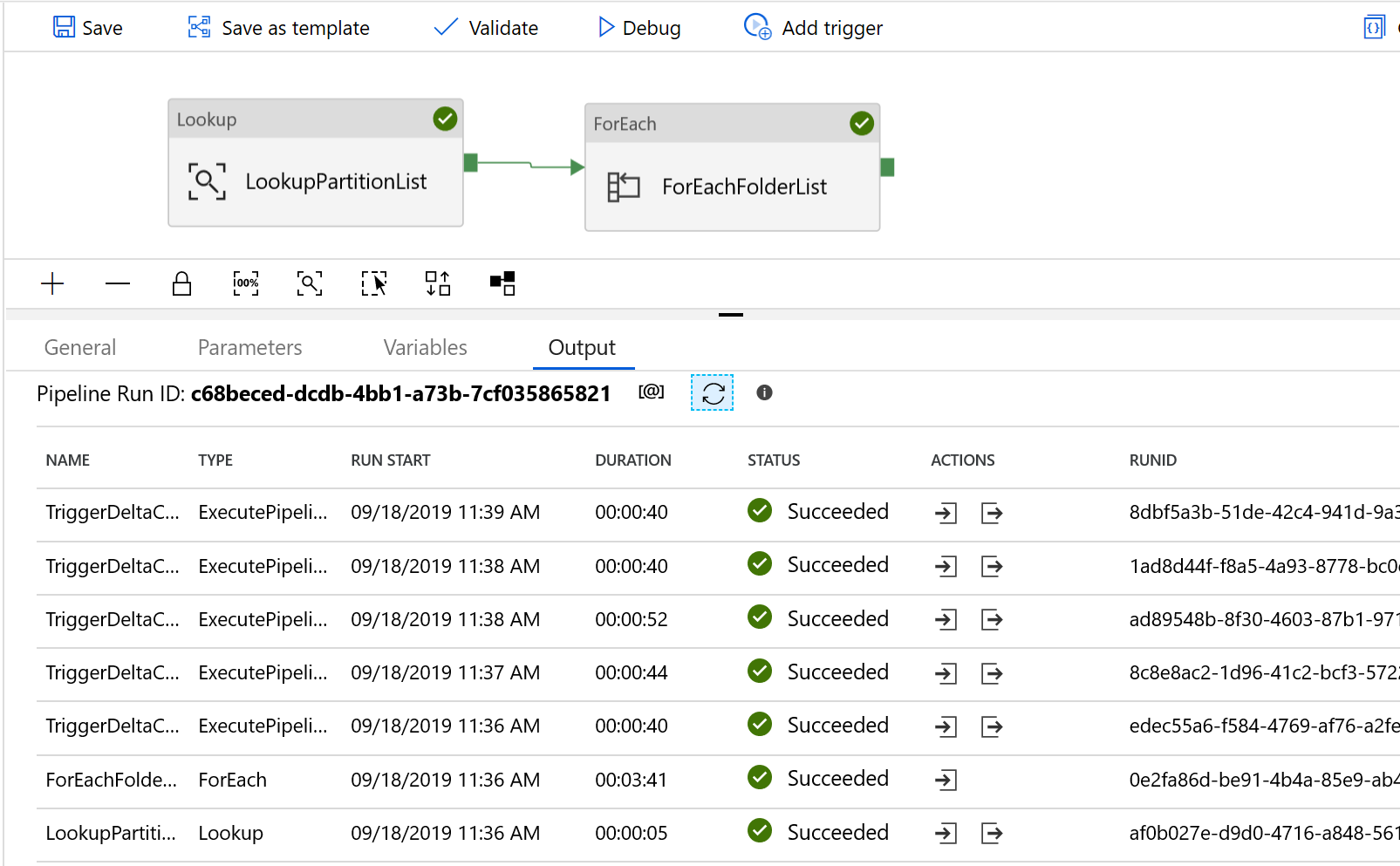
Ve resultados similares al ejemplo siguiente:
Para que la plantilla copie los archivos modificados solo desde Amazon S3 en Azure Data Lake Storage Gen2
Cree una tabla de control en Azure SQL Database para almacenar la lista de particiones de AWS S3.
Nota
El nombre de la tabla es s3_partition_delta_control_table. El esquema de la tabla de control es PartitionPrefix, JobRunTime y SuccessOrFailure, donde PartitionPrefix es el valor de prefijo de S3 para filtrar las carpetas y los archivos de Amazon S3 por nombre, JobRunTime es el valor de la fecha y hora cuando se ejecutan los trabajos de copia y SuccessOrFailure es el estado de copia de cada partición: 0 significa que esta partición no se ha copiado en Azure y 1 significa que esta partición se ha copiado en Azure correctamente. Hay cinco particiones definidas en la tabla de control. El valor predeterminado de JobRunTime puede ser la hora a la que se inicia la migración de datos históricos única. La actividad de copia de ADF copiará los archivos en AWS S3 que se han modificado por última vez después de esa hora. El estado predeterminado de copia de cada partición es 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Cree un procedimiento almacenado en la misma instancia de Azure SQL Database para la tabla de control.
Nota
El nombre del procedimiento almacenado es sp_insert_partition_JobRunTime_success. Lo invocará la actividad SqlServerStoredProcedure en la canalización de ADF.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOVaya a la plantilla Copiar datos delta desde AWS S3 en Azure Data Lake Storage Gen2. Introduzca las conexiones en la tabla de control externa, AWS S3 como el almacén de origen de datos y Azure Data Lake Storage Gen2 como el almacén de destino. Tenga en cuenta que la tabla de control externa y el procedimiento almacenado hacen referencia a la misma conexión.
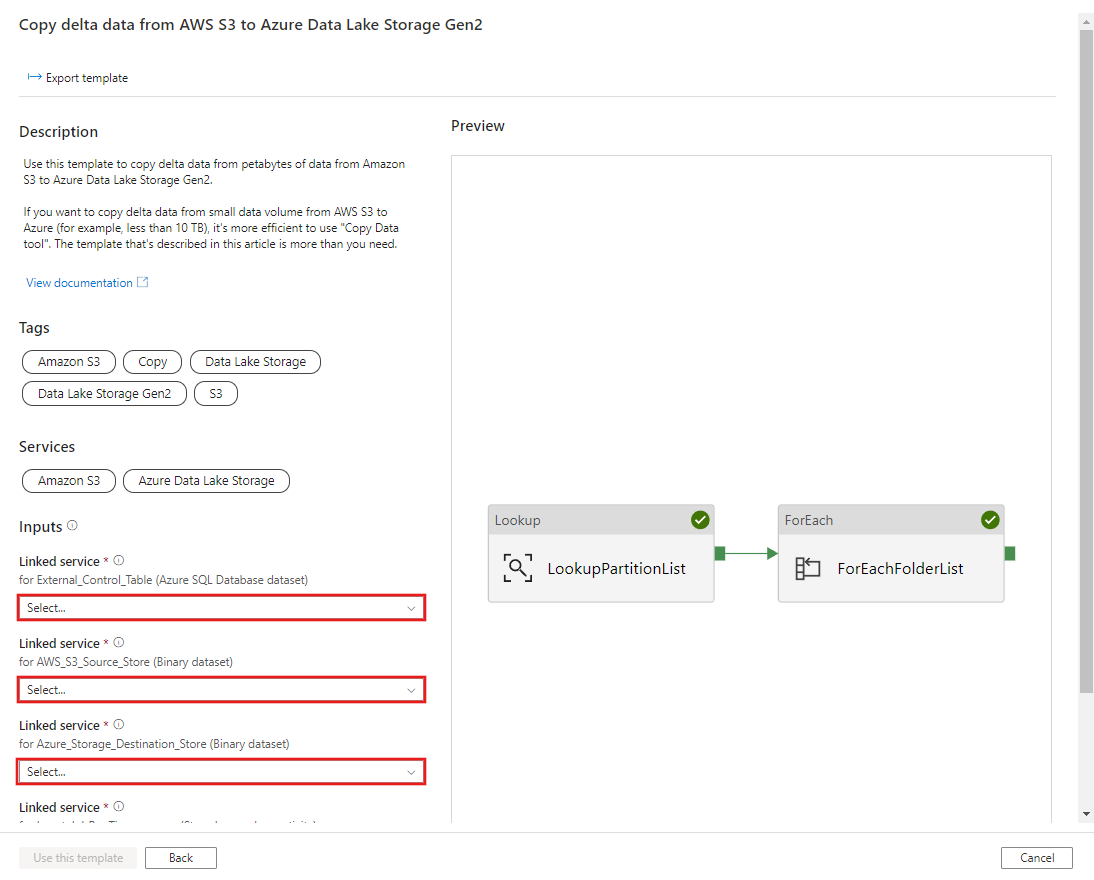
Seleccione Usar esta plantilla.
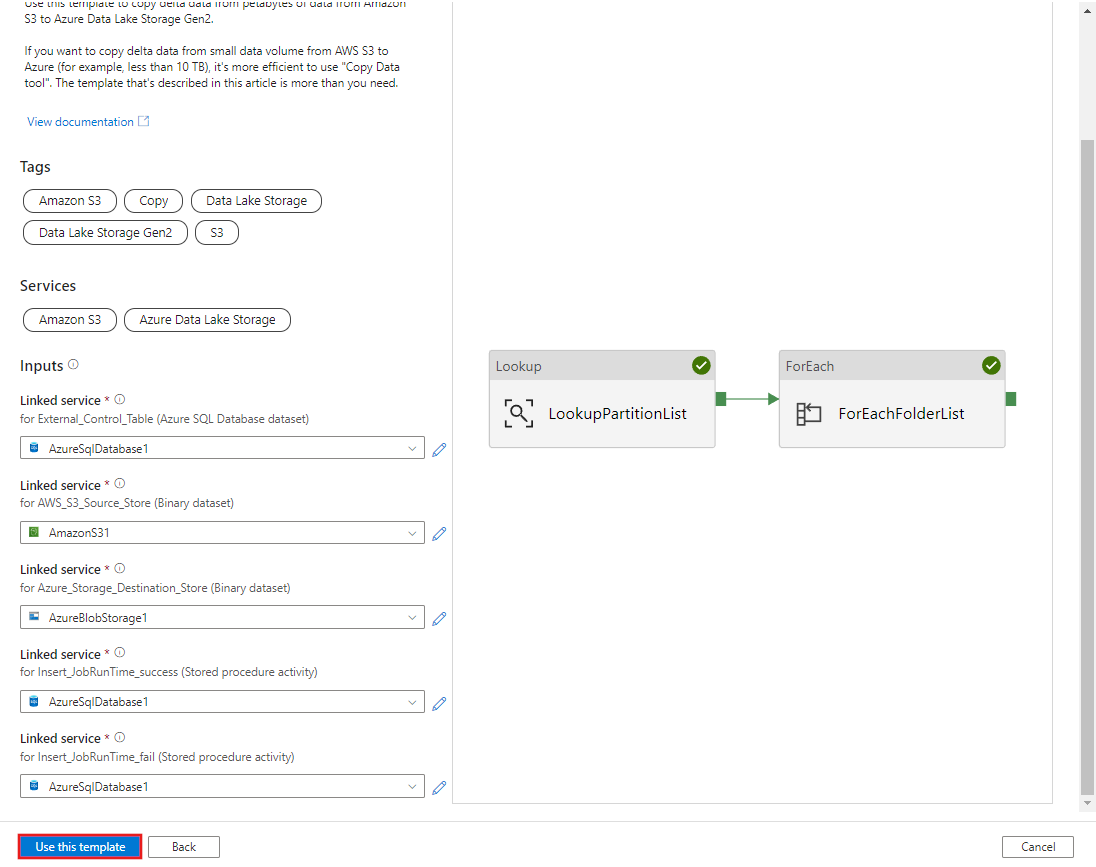
Verá que se crearon dos canalizaciones y tres conjuntos de valores, tal como se muestra en el ejemplo siguiente:
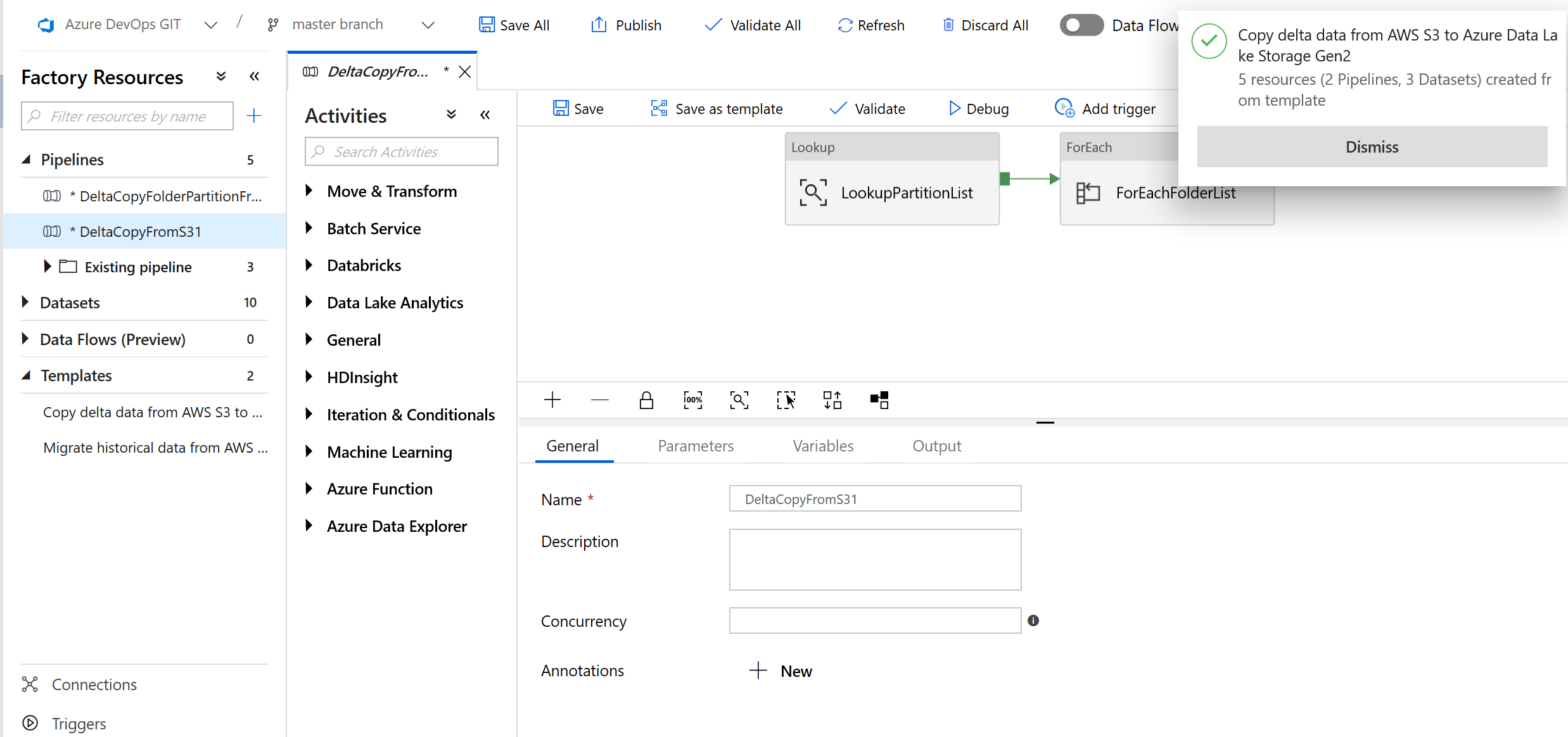
Vaya a la canalización "DeltaCopyFromS3", seleccione Depurar y escriba los parámetros. A continuación, seleccione Finish (Finalizar).
Ve resultados similares al ejemplo siguiente:
También puede comprobar los resultados de la tabla de control mediante una consulta "select * from s3_partition_delta_control_table" . Verá que la salida es similar a la del ejemplo siguiente: