Transformación Ordenar en el flujo de datos de asignación
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Los flujos de datos están disponibles en las canalizaciones Azure Data Factory y Azure Synapse. Este artículo se aplica a los flujos de datos de asignación. Si carece de experiencia con las transformaciones, consulte el artículo de introducción Transformación de datos mediante flujos de datos de asignación.
La transformación Ordenar permite ordenar las filas entrantes de la secuencia de datos actual. Puede elegir columnas individuales y ordenarlas en orden ascendente o descendente.
Nota
Los flujos de datos de asignación se ejecutan en clústeres Spark con datos distribuidos en varios nodos y particiones. Si decide volver a particionar los datos en una transformación posterior, puede perder la ordenación porque los datos se vuelven a mezclar. La mejor manera de mantener el criterio de ordenación en el flujo de datos es establecer una sola partición en la pestaña Optimizar de la transformación y mantener la transformación Ordenar lo más parecida posible al receptor.
Configuración
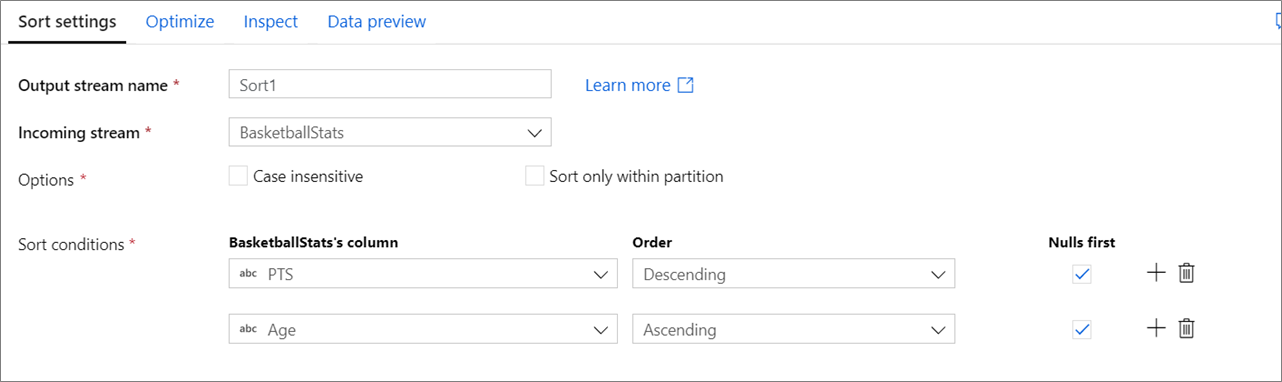
No distinguir entre mayúsculas y minúsculas: si desea tener en cuenta la distinción entre mayúsculas y minúsculas al ordenar campos de cadena o texto.
Ordenar solo dentro de las particiones: a medida que los flujos de datos se ejecutan en Spark, cada flujo de datos se divide en particiones. Esta configuración ordena datos solo dentro de particiones entrantes, en lugar de ordenar todo el flujo de datos.
Condiciones de ordenación: elija las columnas por las que va a ordenar y en qué orden se realiza la ordenación. El orden determina la prioridad de ordenación. Elija si se van a mostrar o no los valores NULL al principio o al final del flujo de datos.
Columnas calculadas
Para modificar o extraer un valor de columna antes de aplicar la ordenación, mantenga el ratón sobre la columna y seleccione "Columna calculada". Se abrirá el generador de expresiones para crear una expresión para la operación de ordenación en lugar de utilizar un valor de columna.
Script de flujo de datos
Sintaxis
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
Ejemplo
El script de flujo de datos para la configuración de ordenación anterior se encuentra en el siguiente fragmento de código.
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
Contenido relacionado
Después de la ordenación, es posible que quiera usar la transformación Agregar.