Copia de datos en Azure Data Explorer o desde ahí mediante Azure Data Factory o Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
En este artículo se describe el uso de la actividad de copia en canalizaciones de Azure Data Factory y Synapse Analytics para copiar datos en Azure Data Explorer o desde ahí. Se basa en el artículo Actividad de copia en Azure Data Factory, en el que se ofrece información general acerca de la actividad de copia.
Sugerencia
Para más información sobre la integración de Azure Data Explorer con el servicio en general, lea Integración de Azure Data Explorer.
Funcionalidades admitidas
Este conector de Azure Data Explorer es compatible con las funcionalidades siguientes:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/receptor) | ① ② |
| Flujo de datos de asignación (origen/receptor) | ① |
| Actividad de búsqueda | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Puede copiar datos desde cualquier almacén de datos de origen compatible a Azure Data Explorer. Además, puede copiar datos desde Azure Data Explorer a cualquier almacén de datos de receptor compatible. Consulte la tabla de almacenes de datos que se admiten para ver una lista de los almacenes de datos que la actividad de copia admite como orígenes o receptores.
Nota
La copia de datos con Azure Data Explorer como origen o destino a través de un almacén de datos local mediante un entorno de ejecución de integración autohospedado se admite en la versión 3.14 y versiones posteriores.
El conector de Azure Data Explorer permite hacer lo siguiente:
- Copiar datos mediante la autenticación de tokens de aplicaciones de Microsoft Entra con una entidad de servicio.
- Como origen, recupere los datos mediante una consulta KQL (Kusto).
- Como receptor, anexe datos a una tabla de destino.
Introducción
Sugerencia
Para ver un tutorial sobre el uso del conector de Azure Data Explorer, consulte Copia de datos con Azure Data Explorer como origen o destino mediante Azure Data Factory y Copia masiva desde una base de datos a Azure Data Explorer.
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado a Azure Data Explorer mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado a Azure Data Explorer en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Explorer y seleccione el conector de Azure Data Explorer (Kusto).
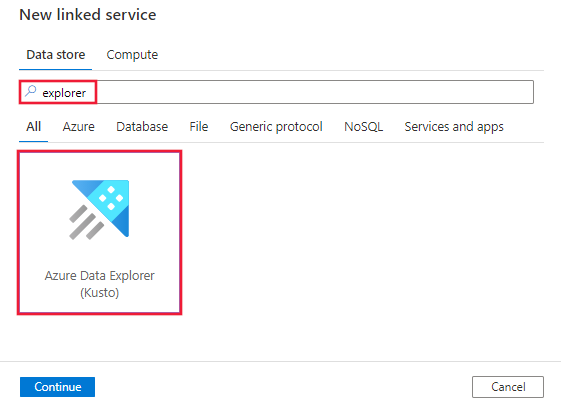
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
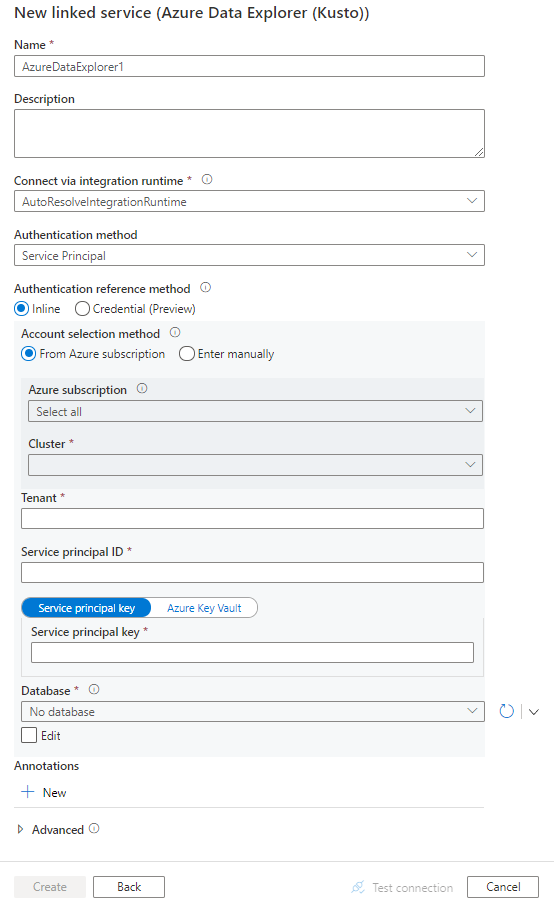
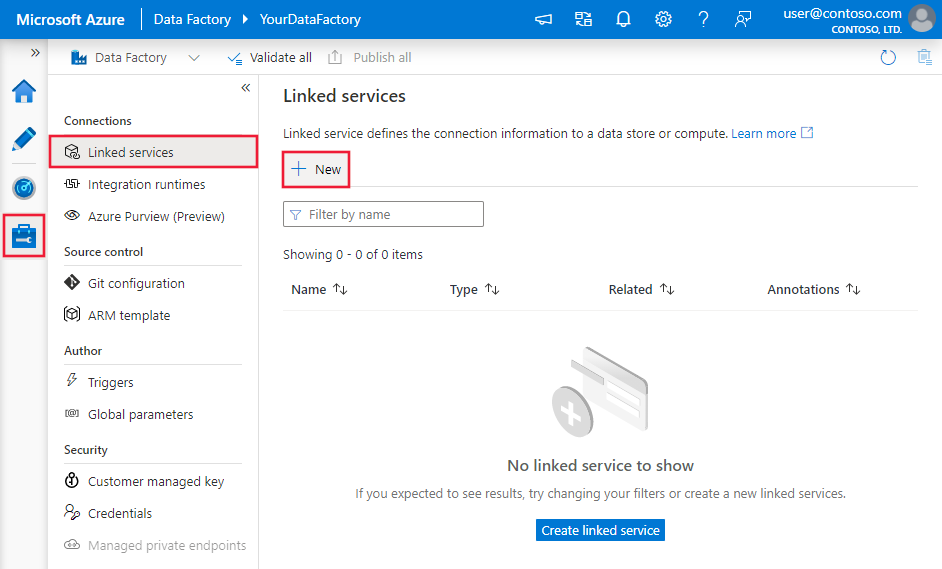
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades específicas del conector de Azure Data Explorer.
Propiedades del servicio vinculado
El conector de Azure Data Explorer admite los siguientes tipos de autenticación. Consulte las secciones correspondientes para más información:
- Autenticación de entidad de servicio
- Autenticación de identidad administrada asignada por el sistema
- Autenticación de identidad administrada asignada por el usuario
Autenticación de entidad de servicio
Para usar la autenticación de la entidad de servicio, siga estos pasos para obtener una entidad de servicio y para conceder permisos:
Registro de una aplicación en la Plataforma de identidad de Microsoft. Para aprender cómo, consulte Inicio rápido: Registrar una aplicación con la plataforma de identidad de Microsoft. Anote estos valores; los usará para definir el servicio vinculado:
- Identificador de aplicación
- Clave de la aplicación
- Id. de inquilino
Conceda a la entidad de servicio los permisos correctos en Azure Data Explorer. Consulte Administración de permisos de base de datos de Azure Data Explorer para obtener información detallada sobre los roles y los permisos, así como información sobre la administración de permisos. En general, debe:
- Como origen, conceder al menos el rol Visor de base de datos a la base de datos.
- Como receptor, conceda al menos el rol de Usuario de la base de datos a su base de datos
Nota
Cuando utiliza la interfaz de usuario para crear, de forma predeterminada se usa la cuenta de usuario de inicio de sesión para enumerar los clústeres, las bases de datos y las tablas de Azure Data Explorer. Para mostrar los objetos mediante la entidad de servicio, haga clic en la lista desplegable situada junto al botón Actualizar o escriba manualmente el nombre si no tiene permiso para estas operaciones.
Las siguientes propiedades son compatibles con el servicio vinculado de Azure Data Explorer:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type se debe establecer en AzureDataExplorer. | Sí |
| endpoint | Dirección URL del punto de conexión del clúster de Azure Data Explorer, con el formato como https://<clusterName>.<regionName>.kusto.windows.net. |
Sí |
| database | Nombre de la base de datos. | Sí |
| tenant | Especifique la información del inquilino (nombre de dominio o identificador de inquilino) en el que reside la aplicación. Esto se conoce como "Id. de autoridad" en la cadena de conexión de Kusto. Para recuperarlo, mantenga el puntero del mouse en la esquina superior derecha de Azure Portal. | Sí |
| servicePrincipalId | Especifique el id. de cliente de la aplicación. Esto se conoce como "identificador de cliente de aplicación de Microsoft Entra" en la cadena de conexión de Kusto. | Sí |
| servicePrincipalKey | Especifique la clave de la aplicación. Esto se conoce como "clave de aplicación de Microsoft Entra" en la cadena de conexión de Kusto. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a los datos seguros almacenados en Azure Key Vault. | Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Si el almacén de datos está en una red privada, se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Ejemplo: uso de la autenticación de claves de entidad de servicio
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Autenticación de identidad administrada asignada por el sistema
Para obtener más información sobre las identidades administradas para los recursos de Azure, vea Identidades administradas para recursos de Azure.
Para usar la autenticación de identidad administrada asignada por el sistema, siga estos pasos a fin de conceder los permisos:
Recupere la información de la identidad administrada mediante la copia del valor de Id. del objeto de identidad administrada que se ha generado junto con la factoría o el área de trabajo de Synapse.
Conceda a la identidad administrada los permisos correctos en Azure Data Explorer. Consulte Administración de permisos de base de datos de Azure Data Explorer para obtener información detallada sobre los roles y los permisos, así como información sobre la administración de permisos. En general, debe:
- Como origen, conceder el rol Visor de base de datos a la base de datos.
- Como receptor, conceder los roles Agente de ingesta de base de datos y Visor de base de datos a la base de datos.
Nota:
Cuando utiliza la interfaz de usuario para crear, se usa la cuenta de usuario de inicio de sesión para enumerar los clústeres, las bases de datos y las tablas de Azure Data Explorer. Escriba manualmente el nombre si no tiene permiso para realizar estas operaciones.
Las siguientes propiedades son compatibles con el servicio vinculado de Azure Data Explorer:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type se debe establecer en AzureDataExplorer. | Sí |
| endpoint | Dirección URL del punto de conexión del clúster de Azure Data Explorer, con el formato como https://<clusterName>.<regionName>.kusto.windows.net. |
Sí |
| database | Nombre de la base de datos. | Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Si el almacén de datos está en una red privada, se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Ejemplo: uso de la autenticación de identidad administrada asignada por el sistema
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Autenticación de identidad administrada asignada por el usuario
Para obtener más información sobre las identidades administradas para los recursos de Azure, vea Identidades administradas para recursos de Azure
Para usar la autenticación de identidad administrada asignada por el usuario, siga estos pasos:
Cree una o varias identidades administradas asignadas por el usuario y conceda permiso en Azure Data Explorer. Consulte Administración de permisos de base de datos de Azure Data Explorer para obtener información detallada sobre los roles y los permisos, así como información sobre la administración de permisos. En general, debe:
- Como origen, conceder al menos el rol Visor de base de datos a la base de datos.
- Como receptor, conceder al menos el rol Agente de ingesta de base de datos a la base de datos.
Asigne una o varias identidades administradas asignadas por el usuario a la factoría de datos o al área de trabajo de Synapse y cree credenciales para cada una de estas entidades.
Las siguientes propiedades son compatibles con el servicio vinculado de Azure Data Explorer:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type se debe establecer en AzureDataExplorer. | Sí |
| endpoint | Dirección URL del punto de conexión del clúster de Azure Data Explorer, con el formato como https://<clusterName>.<regionName>.kusto.windows.net. |
Sí |
| database | Nombre de la base de datos. | Sí |
| credentials | Especifique la identidad administrada asignada por el usuario como objeto de credencial. | Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Si el almacén de datos está en una red privada, se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Ejemplo: uso de la autenticación de identidad administrada asignada por el usuario
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte Conjuntos de datos. En esta sección se enumeran las propiedades compatibles con el conjunto de datos de Azure Data Explorer.
Para copiar datos a Azure Data Explorer, establezca la propiedad type del conjunto de datos en AzureDataExplorerTable.
Se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureDataExplorerTable. | Sí |
| table | El nombre de la tabla a la que hace referencia el servicio vinculado. | Sí para el receptor, no para el origen |
Ejemplo de propiedades del conjunto de datos:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propiedades de la actividad de copia
Para ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte Canalizaciones y actividades. En esta sección se proporciona una lista de las propiedades compatibles con los orígenes y los receptores de Azure Data Explorer.
Azure Data Explorer como origen
Para copiar datos desde Azure Data Explorer, establezca la propiedad type del origen de la actividad de copia en AzureDataExplorerSource. Se admiten las siguientes propiedades en la sección source de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en: AzureDataExplorerSource | Sí |
| Query | Una solicitud de solo lectura dada en un formato KQL. Use la consulta KQL personalizada como referencia. | Sí |
| queryTimeout | El tiempo de espera antes de que se agote el tiempo de espera de la solicitud de consulta. El valor predeterminado es de 10 minutos (00:10:00); el valor máximo permitido es de 1 hora (01: 00:00). | No |
| noTruncation | Indica si se debe truncar el conjunto de resultados devuelto. De forma predeterminada, el resultado se trunca pasados los 500 000 registros o los 64 megabytes (MB). Se recomienda encarecidamente el truncamiento para garantizar el comportamiento correcto de la actividad. | No |
Nota
De forma predeterminada, el origen de Azure Data Explorer tiene un límite de tamaño de 500 000 registros o 64 MB. Para recuperar todos los registros sin que se produzca truncamiento, puede especificar set notruncation; al principio de la consulta. Para más información, consulte Límites de la consulta.
Ejemplo:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Azure Data Explorer como receptor
Para copiar datos en Azure Data Explorer, establezca la propiedad type del receptor de la actividad de copia en AzureDataExplorerSink. Se admiten las siguientes propiedades en la sección sink de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en: AzureDataExplorerSink. | Sí |
| ingestionMappingName | Nombre de una asignación creada previamente en una tabla de Kusto. Para asignar las columnas del origen a Azure Data Explorer (lo que se aplica a todos los almacenes y formatos de origen admitidos, incluidos los formatos CSV, JSON o Avro), puede usar la asignación de columnas de la actividad de copia (implícitamente por nombre o explícitamente según la configuración) o las asignaciones de Azure Data Explorer. | No |
| additionalProperties | Un contenedor de propiedades que se puede usar para especificar cualquiera de las propiedades de ingesta que aún no ha establecido el receptor de Azure Data Explorer. En concreto, puede ser útil para especificar etiquetas de ingesta. Más información en la documentación sobre ingesta de datos de Azure Data Explore. | No |
Ejemplo:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Propiedades de Asignación de instancias de Data Flow
Al transformar datos en un flujo de datos de asignación, puede leer y escribir en tablas de Azure Data Explorer. Para más información, vea la transformación de origen y la transformación de receptor en los flujos de datos de asignación. Puede optar por usar un conjunto de datos de Azure Data Explorer o un conjunto de datos en línea como tipo de origen y de receptor.
Transformación de origen
En la tabla siguiente se enumeran las propiedades compatibles con el origen de Azure Data Explorer. Puede editar estas propiedades en la pestaña Source options (Opciones de origen).
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Tabla | Si selecciona Tabla como entrada, el flujo de datos captura todos los datos de la tabla especificada en el conjunto de datos de Azure Data Explorer, o en las opciones del origen al usar un conjunto de datos en línea. | No | String | (solo para conjunto de datos en línea) tableName |
| Consultar | Una solicitud de solo lectura dada en un formato KQL. Use la consulta KQL personalizada como referencia. | No | String | Query |
| Tiempo de espera | Tiempo para que se agote el tiempo de espera de la solicitud de consulta. El valor predeterminado es 172000 (2 días). | No | Entero | timeout |
Ejemplos de scripts de origen de Azure Data Explorer
Cuando se usa un conjunto de datos de Azure Data Explorer como tipo de origen, el script de flujo de datos asociado es:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Si se usa un conjunto de datos en línea, el script de flujo de datos asociado es:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Transformación de receptor
En la tabla siguiente se enumeran las propiedades compatibles con el receptor de Azure Data Explorer. Puede editar estas propiedades en la pestaña Configuración. Al usar un conjunto de datos en línea, se ven opciones adicionales, que son las mismas que las propiedades descritas en la sección Propiedades del conjunto de datos.
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Acción Table | determina si se deben volver a crear o quitar todas las filas de la tabla de destino antes de escribir. - Ninguno: no se realizará ninguna acción en la tabla. - Volver a crear: se quitará la tabla y se volverá a crear. Obligatorio si se crea una nueva tabla dinámicamente. - Truncar: se quitarán todas las filas de la tabla de destino. |
No | true o false |
recreate truncate |
| Scripts SQL anteriores y posteriores | Especifique varios scripts de comandos de control de Kusto que se ejecuten antes (procesamiento previo) y después (procesamiento posterior) de que los datos se escriban en la base de datos del receptor. | No | String | preSQLs; postSQLs |
| Tiempo de espera | Tiempo para que se agote el tiempo de espera de la solicitud de consulta. El valor predeterminado es 172000 (2 días). | No | Entero | timeout |
Ejemplos de scripts de receptor de Azure Data Explorer
Cuando se usa un conjunto de datos de Azure Data Explorer como tipo de receptor, el script de flujo de datos asociado es:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Si se usa un conjunto de datos en línea, el script de flujo de datos asociado es:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Propiedades de la actividad de búsqueda
Para más información sobre las propiedades, consulte Actividad de búsqueda.
Contenido relacionado
Para ver una lista de los almacenes de datos que la actividad de copia admite como orígenes y receptores, consulte Almacenes de datos admitidos.
Más información sobre la copia de datos de Azure Data Factory y Synapse Analytics a Azure Data Explorer.