Flujos de datos de asignación en Azure Data Factory
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
¿Qué son los flujos de datos de asignación?
La asignación de flujos de datos es una transformación de datos diseñada visualmente en Azure Data Factory. Los flujos de datos permiten a los ingenieros de datos desarrollar lógica de transformación de datos sin necesidad de escribir código. Los flujos de datos resultantes se ejecutan como actividades en las canalizaciones de Azure Data Factory que usan clústeres de Apache Spark con escalabilidad horizontal. Las actividades de flujo de datos pueden ponerse en marcha mediante las capacidades de programación, control, flujo y supervisión existentes de Azure Data Factory.
Los flujos de datos de asignación proporcionan una experiencia completamente visual que no requiere programación. Los flujos de datos se ejecutan en clústeres de ejecución administrados por ADF durante el procesamiento de datos de escalabilidad horizontal. Asimismo, Azure Data Factory controla toda la traducción de código, la optimización de rutas de acceso y la ejecución de los trabajos de flujo de datos.
Introducción
Los flujos de datos se crean desde el panel Factory Resources (Recursos de fábrica) como canalizaciones y conjuntos de datos. Para crear un flujo de datos, seleccione el signo más junto a Factory Resources (Recursos de fábrica) y luego Data Flow.
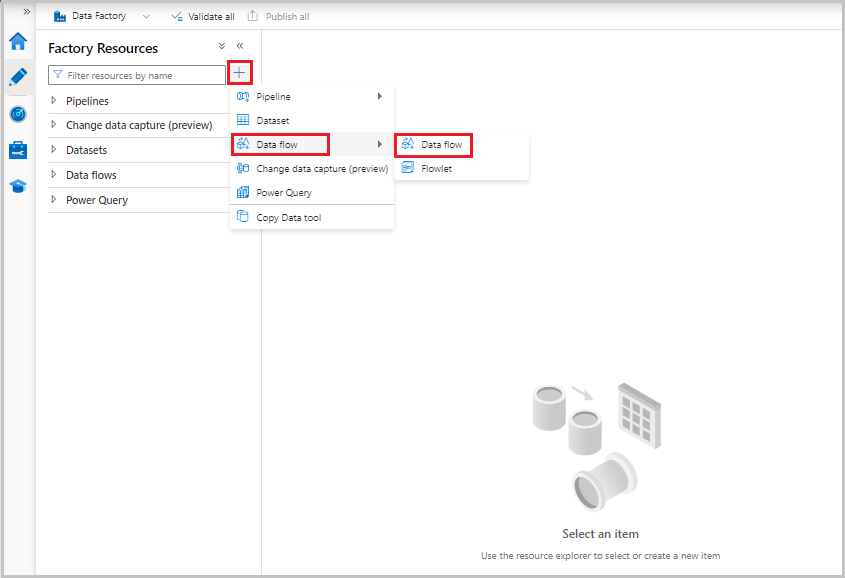 Con esta acción, accederá al lienzo de flujo de datos, donde podrá crear la lógica de transformación. Seleccione Agregar origen para comenzar a configurar la transformación de origen. Para más información, consulte Transformación de origen.
Con esta acción, accederá al lienzo de flujo de datos, donde podrá crear la lógica de transformación. Seleccione Agregar origen para comenzar a configurar la transformación de origen. Para más información, consulte Transformación de origen.
Creación de flujos de datos
El flujo de datos de asignación tiene un lienzo de creación único diseñado para facilitar la creación de lógica de transformación. El lienzo de flujo de datos está dividido en tres partes: la barra superior, el gráfico y el panel de configuración.
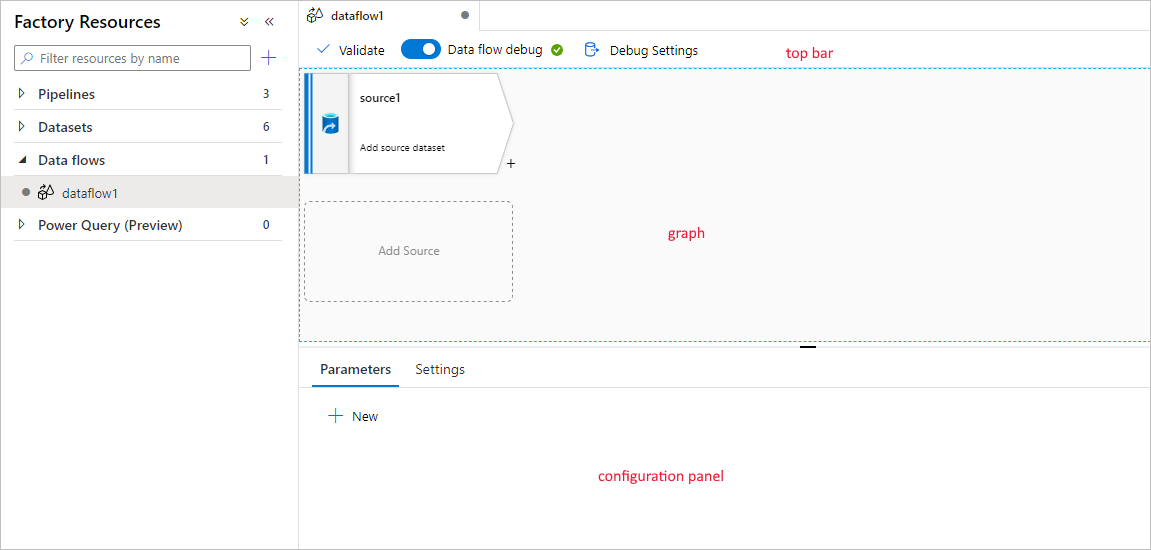
Grafo
En el gráfico se muestra el flujo de transformación. Muestra el linaje de los datos de origen a medida que fluyen hacia uno o varios receptores. Los receptores pueden ser cualquier destino para origen de datos donde desee mover los resultados de los datos transformados. Para agregar un nuevo origen, seleccione Agregar origen. Para agregar una nueva transformación, seleccione el signo más situado en la parte inferior derecha de una transformación existente. Obtenga más información sobre cómo administrar el gráfico de flujo de datos.
Panel de configuración
En el panel configuración se muestra la configuración específica de la transformación seleccionada actualmente. Si no se ha seleccionado ninguna transformación, se muestra el flujo de datos. En la configuración de flujo de datos general, puede agregar parámetros a través de la pestaña Parámetros. Para más información, consulte Parámetros de asignación de Data Flow.
Cada transformación contiene al menos cuatro pestañas de configuración.
Configuración de la transformación
La primera pestaña del panel de configuración de cada transformación contiene los valores específicos de esa transformación. Para más información, consulte la página de documentación de la transformación.
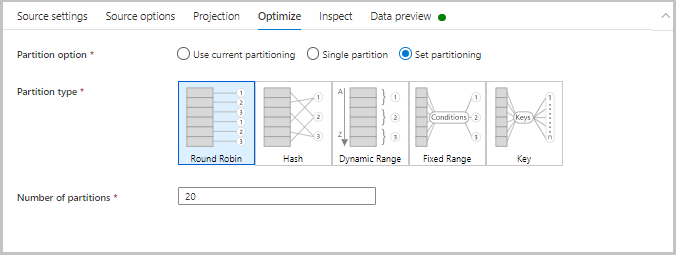
Optimización
La pestaña Optimizar contiene valores opcionales para configurar los esquemas de partición. Para obtener más información sobre cómo optimizar los flujos de datos, consulte la guía de rendimiento de flujos de datos de asignación.
Inspeccionar
La pestaña Inspeccionar proporciona una vista de los metadatos del flujo de datos que se está transformando. Puede ver el número de columnas, las columnas que han cambiado, las columnas que se han agregado, los tipos de datos, el orden de las columnas y las referencias de las columnas. Inspeccionar es una vista de solo lectura de los metadatos. Para ver los metadatos en el panel Inspeccionar, no es preciso que el modo de depuración esté habilitado.
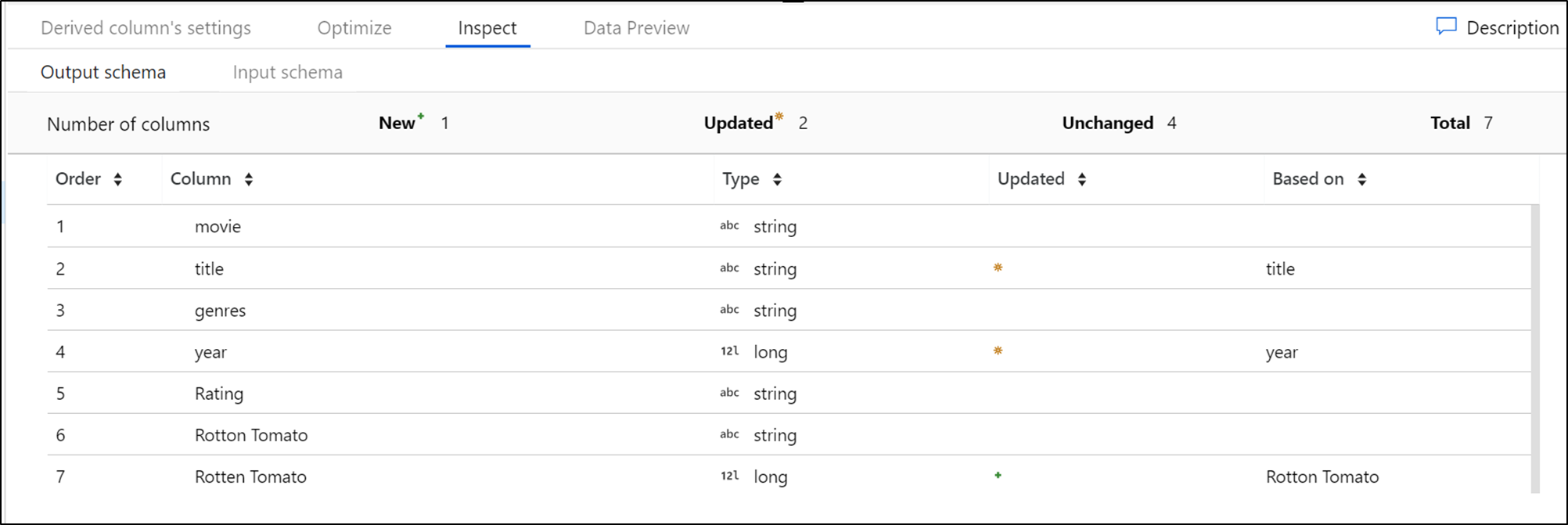
A medida que cambia la forma de sus datos mediante transformaciones, puede ver cómo fluyen los cambios de metadatos en el panel Inspeccionar. Si no hay un esquema definido en su transformación de origen, los metadatos no estarán visibles en el panel Inspeccionar. La falta de metadatos es habitual en escenarios de desviación en el esquema.
Vista previa de datos
Si el modo de depuración está activado, en la pestaña Vista previa de los datos, podrá ver una instantánea interactiva de los datos en cada transformación. Para más información, consulte Vista previa de los datos en modo de depuración.
Barra superior
La barra superior contiene acciones que afectan a todo el flujo de datos, como la operación de guardar y la validación. También puede ver el código JSON subyacente y el script de flujo de datos de la lógica de transformación. Para obtener más información, vea el script de flujo de datos.
Transformaciones disponibles
Vea Introducción a las transformaciones en el flujo de datos de asignación para obtener una lista de las transformaciones disponibles.
Tipos de datos de flujo de datos
- array
- binary
- boolean
- complejas
- decimal (incluye precisión)
- date
- FLOAT
- integer
- long
- mapa
- short
- string
- timestamp
Actividad de los flujos de datos
Los flujos de datos de asignación se ponen en marcha en canalizaciones de ADF mediante la actividad de flujo de datos. Todo lo que tiene que hacer el usuario es especificar qué entorno de ejecución de integración usar y pasar valores de parámetro. Para obtener más información, vea el entorno de ejecución de integración de Azure.
Modo de depuración
El modo de depuración permite ver de forma interactiva los resultados de cada paso de transformación mientras compila y depura flujos de datos. La sesión de depuración se puede usar al compilar la lógica del flujo de datos y al ejecutar ejecuciones de depuración de canalización con actividades de flujo de datos. Para obtener más información, vea la documentación del modo de depuración.
Supervisión de flujos de datos
El flujo de datos de asignación se integra con las capacidades de supervisión existentes de Azure Data Factory. Para obtener información para comprender la salida de la supervisión de flujos de datos, vea Supervisión de flujos de datos de asignación.
El equipo de Azure Data Factory ha creado una Guía para la optimización del rendimiento para ayudar a optimizar el tiempo de ejecución de los flujos de datos después de compilar la lógica de negocios.
Contenido relacionado
- Aprenda a crear una transformación de origen.
- Aprenda a crear flujos de datos en modo de depuración.