Optimización de orígenes
En todos los orígenes, excepto Azure SQL Database, se recomienda mantener seleccionado el valor Usar particiones actuales. Cuando se leen los demás sistemas de origen, los flujos de datos crean automáticamente particiones de los datos de manera uniforme en función de su tamaño. Se crea una nueva partición aproximadamente por cada 128 MB de datos. A medida que aumenta el tamaño de los datos, aumenta el número de particiones.
Las particiones personalizadas tienen lugar después de que Spark ha leído los datos y afectan negativamente al rendimiento del flujo de datos. Dado que los datos se particionan uniformemente al leerlos, no se recomienda a menos que conozca primero la forma y la cardinalidad de los datos.
Nota:
Las velocidades de lectura pueden verse limitadas por la capacidad de proceso del sistema de origen.
Orígenes de Azure SQL Database
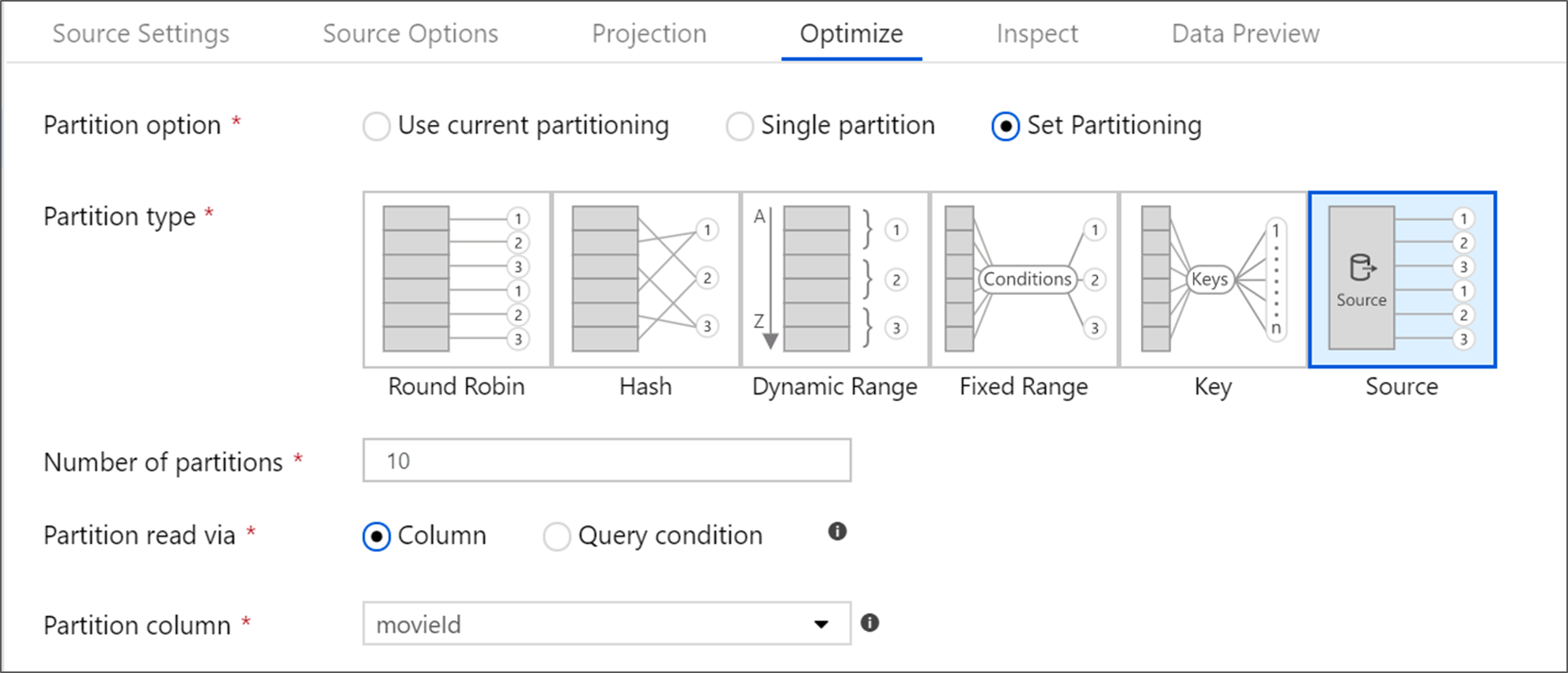
Azure SQL Database tiene una opción única de creación de particiones denominada creación de particiones "de origen". Si se habilita esta opción, pueden mejorar los tiempos de lectura de Azure SQL Database, ya que se habilitan conexiones paralelas en el sistema de origen. Se especifica el número de particiones y cómo se crean particiones de los datos. Se usa una columna de partición con alta cardinalidad. También se puede escribir una consulta que coincida con el esquema de partición de la tabla de origen.
Sugerencia
En la creación de particiones de origen, la E/S de SQL Server es el cuello de botella. Si se agregan demasiadas particiones, se puede saturar la base de datos de origen. Normalmente, cuando se usa esta opción el número ideal de particiones es de cuatro o cinco.
Nivel de aislamiento
El nivel de aislamiento de la lectura en un sistema de origen de Azure SQL afecta al rendimiento. La opción "Lectura no confirmada" proporciona el rendimiento más rápido y evita bloqueos en la base de datos. Para obtener más información sobre los niveles de aislamiento de SQL, vea Descripción de los niveles de aislamiento.
Lectura mediante consulta
Puede leer de Azure SQL Database mediante una tabla o una consulta SQL. Si ejecuta una consulta SQL, debe completarse para que se pueda iniciar la transformación. Las consultas SQL pueden resultar útiles para insertar operaciones que pueden ejecutarse más rápido y reducir la cantidad de datos que se leen de una instancia de SQL Server, como las instrucciones SELECT, WHERE y JOIN. Cuando se insertan las operaciones, se pierde la capacidad de realizar un seguimiento del linaje y el rendimiento de las transformaciones antes de que los datos lleguen al flujo de datos.
Orígenes de Azure Synapse Analytics
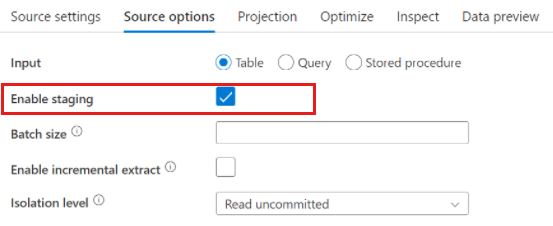
Cuando se usa Azure Synapse Analytics, las opciones de origen incluyen un valor denominado Enable staging (Habilitar almacenamiento provisional). Esto permite que el servicio lea información de Synapse con Staging, que mejora considerablemente el rendimiento de lectura al usar la funcionalidad de carga masiva con mayor rendimiento, como los comandos CETAS y COPY. La habilitación de Staging requiere que especifique una ubicación de almacenamiento provisional de Azure Blob Storage o Azure Data Lake Storage Gen2 en la configuración de la actividad del flujo de datos.
Orígenes basados en archivos
Texto delimitado frente a Parquet
Aunque los flujos de datos admiten varios tipos de archivo, se recomienda usar el formato Parquet nativo de Spark para conseguir tiempos de lectura y escritura óptimos.
Si está ejecutando el mismo flujo de datos en un conjunto de archivos, se recomienda leer de una carpeta, usar rutas de acceso con caracteres comodín o leer de una lista de archivos. Una sola ejecución de actividad de flujo de datos puede procesar todos los archivos por lotes. Puede encontrar más información sobre cómo establecer esta configuración en la sección Transformación de origen de la documentación sobre el conector de Azure Blob Storage.
Si es posible, evite usar la actividad For-Eeach para ejecutar flujos de datos en un conjunto de archivos. Esto hace que cada iteración de For-Each ponga en marcha su propio clúster de Spark, lo que a menudo no suele ser necesario y puede resultar caro.
Conjuntos de datos insertados frente a conjuntos de datos compartidos
Los conjuntos de datos de ADF y Synapse son recursos compartidos en las factorías y áreas de trabajo. Sin embargo, al leer un gran número de carpetas y archivos de origen con texto delimitado y orígenes JSON, puede mejorar el rendimiento de la detección de archivos de flujo de datos estableciendo la opción "Esquema proyectado por el usuario" en el cuadro de diálogo Proyección | Opciones de esquema. Esta opción desactiva la detección automática de esquemas predeterminada de ADF y mejora considerablemente el rendimiento de la detección de archivos. Antes de establecer esta opción, asegúrese de importar la proyección para que ADF tenga un esquema existente para la proyección. Esta opción no funciona con el desfase de esquema.
Contenido relacionado
- Introducción al rendimiento del flujo de datos
- Optimización de receptores
- Optimización de transformaciones
- Uso de flujos de datos en canalizaciones
Vea el resto de artículos sobre Data Flow relacionados con el rendimiento: