Optimización de receptores
Cuando los flujos de datos escriben en los receptores, la creación de particiones personalizada se produce inmediatamente antes de la escritura. Al igual que en el origen, en la mayoría de los casos se recomienda mantener seleccionada la opción Usar particiones actuales. Los datos particionados se escriben mucho más rápido que los datos no particionados, incluso si el destino no está particionado. A continuación se indican aspectos específicos de varios tipos de receptores.
Receptores de Azure SQL Database
En el caso de Azure SQL Database, la creación de particiones predeterminada debería funcionar en la mayoría de los casos. Existe la posibilidad de que el receptor pueda tener demasiadas particiones para que la base de datos SQL pueda administrarlas. Si ve que este puede ser el caso, reduzca el número de particiones que salen del receptor de SQL Database.
Procedimiento recomendado para eliminar filas en el receptor en función de las filas que faltan en el origen
Este es un tutorial en vídeo sobre cómo usar flujos de datos con las transformaciones Existe, Alteración de fila y Receptor para lograr este patrón común:
Efecto del control de filas de error sobre el rendimiento
Cuando se habilita el control de filas de error ("continuar en caso de error") en la transformación Receptor, el servicio realiza un paso adicional antes de escribir las filas compatibles en la tabla de destino. Este paso adicional tiene una pequeña penalización en el rendimiento, que puede estar en torno al 5 %, a lo que se suma una pequeña reducción adicional del rendimiento si establece la opción para que también se escriban las filas incompatibles en un archivo de registro.
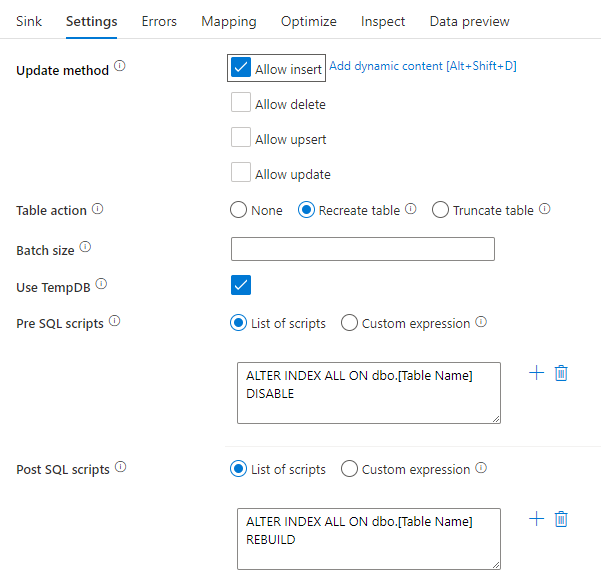
Deshabilitación de índices mediante un script SQL
Deshabilitar los índices antes de una carga en una base de datos SQL puede mejorar considerablemente el rendimiento de la escritura en la tabla. Ejecute el siguiente comando antes de escribir en el receptor de SQL.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Una vez finalizada la escritura, vuelva a generar los índices con el siguiente comando:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
En los flujos de datos de asignación, ambos se pueden ejecutar de forma nativa usando scripts anteriores y posteriores a SQL en una instancia de Azure SQL Database o un receptor de Synapse.
Advertencia
Cuando se deshabilitan los índices, el flujo de datos toma de hecho el control sobre una base de datos y es poco probable que las consultas se realicen correctamente en este caso. Como resultado, se desencadenan muchos trabajos ETL en medio de la noche para evitar este conflicto. Para obtener más información, vea las restricciones que conlleva deshabilitar índices SQL.
Escalado vertical de la base de datos
Programe un cambio de tamaño del origen y el receptor de Azure SQL DB y Azure SQL DataWarehouse antes de que la canalización se ejecute para aumentar el rendimiento y minimizar la limitación de Azure una vez que se alcancen los límites de DTU. Una vez completada la ejecución de la canalización, cambie el tamaño de las bases de datos a la velocidad de ejecución normal.
Receptores de Azure Synapse Analytics
Al escribir en Azure Synapse Analytics, asegúrese de que la opción Enable staging (Habilitar almacenamiento provisional) esté establecida en true. Esta permite que el servicio escriba usando el comando COPY de SQL, que carga los datos de forma eficaz y masiva. Tendrá que hacer referencia a una cuenta de Azure Data Lake Storage Gen2 o de Azure Blob Storage para el almacenamiento provisional de los datos cuando use almacenamiento provisional.
Además de Staging, en Azure Synapse Analytics se aplican los mismos procedimientos recomendados que en Azure SQL Database.
Receptores basados en archivos
Aunque los flujos de datos admiten varios tipos de archivo, se recomienda usar el formato Parquet nativo de Spark para conseguir tiempos de lectura y escritura óptimos.
Si los datos se distribuyen uniformemente, Usar particiones actuales es la opción de creación de particiones más rápida para escribir archivos.
Opciones de nombre de archivo
Al escribir archivos, tiene una serie de opciones de nomenclatura que afectan de diferente forma al rendimiento.
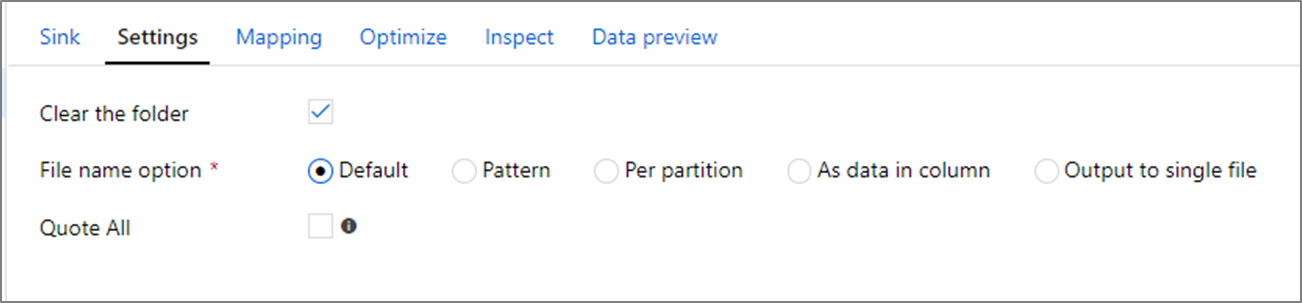
La opción Predeterminado ofrece la escritura más rápida. Cada partición equivale a un archivo con el nombre predeterminado de Spark. Esto resulta útil si solo está leyendo de la carpeta de datos.
La opción Patrón establece un patrón de nomenclatura que cambia el nombre de cada archivo de partición a un nombre más descriptivo. Esta operación se produce después de la escritura y es ligeramente más lenta que elegir la opción predeterminada.
Per partition (Por partición) permite asignar un nombre a cada partición individual manualmente.
Si una columna corresponde a la forma en la que desea generar los datos, puede seleccionar Asignar nombre al archivo como datos de columna. Esta opción reordena los datos y puede afectar al rendimiento si las columnas no están distribuidas uniformemente.
Si una columna corresponde a la forma en la que desea generar los nombres de carpeta, seleccione Asignar nombre a la carpeta como datos de columna.
Output to single file (Salida a un solo archivo) combina todos los datos en una sola partición. Esto supone tiempos de escritura largos, especialmente en grandes conjuntos de datos. No se recomienda usar esta opción a menos que haya una razón empresarial explícita para ello.
Receptores de Azure Cosmos DB
Cuando se escriben datos en Azure Cosmos DB, la modificación de la capacidad de procesamiento y el tamaño de lote durante la ejecución del flujo de datos puede mejorar el rendimiento. Estos cambios solo surten efecto durante la ejecución de la actividad de flujo de datos y volverán a la configuración original de la colección tras la conclusión.
Batch size (Tamaño de lote): Normalmente alcanza con comenzar con el tamaño de lote predeterminado. Para optimizar aún más este valor, calcule el tamaño de objeto aproximado de los datos y asegúrese de que el tamaño del objeto multiplicado por el tamaño de lote sea menor que 2 MB. Si lo es, puede aumentar el tamaño del lote para obtener un mejor rendimiento
Rendimiento: establezca aquí un valor de rendimiento mayor para que los documentos se escriban más rápidamente en Azure Cosmos DB. Tenga en cuenta que los costos de RU son mayores cuando aumenta el valor de capacidad de proceso.
Presupuesto de procesamiento de escritura: use un valor que sea menor que el total de RU por minuto. Si tiene un flujo de datos con un número elevado de particiones de Spark, al establecer un presupuesto de capacidad de procesamiento consigue un mayor equilibrio entre las particiones.
Contenido relacionado
- Introducción al rendimiento del flujo de datos
- Optimización de orígenes
- Optimización de transformaciones
- Uso de flujos de datos en canalizaciones
Vea el resto de artículos sobre Data Flow relacionados con el rendimiento: