El patrón Bulkhead es un tipo de diseño de aplicaciones que es tolerante a errores. En una arquitectura bulkhead, también conocida como arquitectura basada en celdas, los elementos de una aplicación se aíslan en grupos para que, si se produce un error en uno de ellos, los demás sigan funcionando. Su nombre proviene de las particiones en secciones (tabiques herméticos) del casco de un barco. Si el casco de un barco corre peligro, solo se llenará de agua la sección dañada, lo que evita que el barco se hunda.
Contexto y problema
Una aplicación basada en la nube puede incluir varios servicios, y cada servicio tiene uno o varios consumidores. Una carga excesiva o un error en un servicio afectarán a todos los consumidores del servicio.
Además, un consumidor puede enviar solicitudes a varios servicios al mismo tiempo y usar recursos para cada solicitud. Cuando el consumidor envía una solicitud a un servicio que no está configurada correctamente o que no responde, es posible que los recursos utilizados por la solicitud del cliente no se liberen en el momento oportuno. Como las solicitudes al servicio no se detienen, pueden agotarse. Por ejemplo, se puede agotar el grupo de conexiones del cliente. En ese momento, las solicitudes que el consumidor realiza a otros servicios resultan afectadas. En último término, el consumidor no puede volver a enviar solicitudes a otros servicios, no solo al servicio original que no responde.
El mismo problema de agotamiento de recursos afecta a los servicios con varios consumidores. Un gran número de solicitudes cuyo origen es un cliente puede agotar los recursos disponibles en el servicio. Otros consumidores no pueden consumir el servicio, lo que provoca un efecto de error en cascada.
Soluciones
Dividir las instancias del servicio en distintos grupos, en función de disponibilidad y carga de los consumidores. Este diseño ayuda a aislar los errores y le permite mantener la funcionalidad del servicio para algunos consumidores, incluso durante un error.
Los consumidores también pueden dividir los recursos, con el fin de asegurarse de que los recursos usados para llamar a un servicio no afectan a los usados para llamar a otro servicio. Por ejemplo, a un consumidor que llama a varios servicios se le puede asignar un grupo de conexiones por cada servicio. Si un servicio empieza a fallar, solo afecta al grupo de conexiones a dicho servicio, lo que permite al consumidor seguir usando los restantes.
Las ventajas de este patrón son:
- Aísla los consumidores y servicios de errores en cascada. Un problema que afecta a un servicio o a un consumidor se puede aislar en su propio mamparo, lo que evita que el error afecte a toda la solución.
- Le permite conservar cierta funcionalidad si se produce un error del servicio. Otros servicios y características de la aplicación continuarán funcionando.
- Permite implementar servicios que ofrecen una calidad de servicio diferente a las aplicaciones consumidoras. Se puede configurar que un grupo de consumidores de alta prioridad use los servicios de alta prioridad.
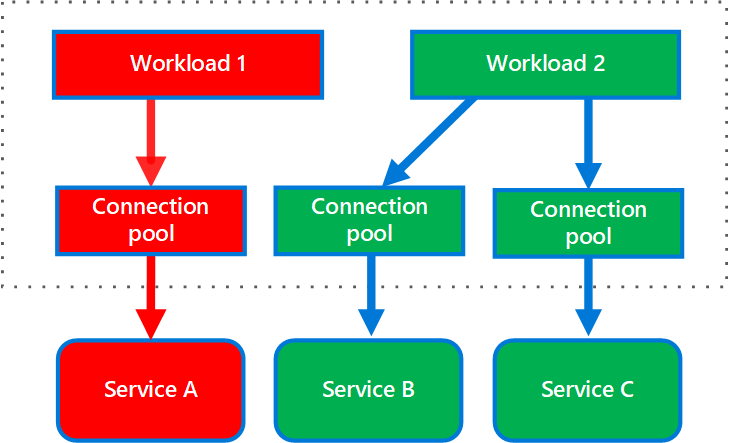
El siguiente diagrama muestra mamparos estructurados en torno a grupos de conexiones que llaman a los servicios individuales. Si en Service A se produce algún error o provoca algún otro problema, se aísla el grupo de conexiones, con lo que solo resultan afectadas las cargas de trabajo que usan el grupo de subprocesos asignado a Service A. Las cargas de trabajo que usan Service B y C no resultan afectadas y pueden seguir funcionando sin interrupción.
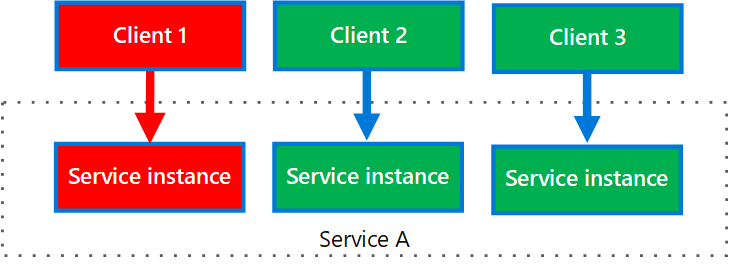
El diagrama siguiente muestra a varios clientes que llaman a un único servicio. A cada cliente se le asigna una instancia de servicio independiente. Client 1 ha realizado demasiadas solicitudes y desborda su instancia. Dado que cada instancia de servicio está aislada de las demás, los restantes clientes pueden seguir haciendo llamadas.
Problemas y consideraciones
- Defina particiones en torno a los requisitos técnicos y empresariales de la aplicación.
- Si usa DDD (diseño basado en dominios) táctico para diseñar microservicios los límites de partición deben alinearse con los contextos delimitados.
- Al dividir los servicios o los consumidores en mamparos, tenga en cuenta el nivel de aislamiento que ofrece la tecnología, así como la sobrecarga en términos de costo, rendimiento y capacidad de administración.
- Considere la posibilidad de combinar mamparos con los patrones Retry, Circuit Breaker y Throttling para proporcionar un control de errores más sofisticado.
- Al dividir los consumidores en mamparos, considere la posibilidad de usar procesos, grupos de subprocesos y semáforos. Algunos proyectos como resilience4j y Polly ofrecen un marco para crear compartimentos de consumidor.
- Al dividir los servicios en mamparos, considere la posibilidad de implementarlos en máquinas virtuales, contenedores o procesos independientes. Los contenedores ofrecen un buen equilibrio de aislamiento de recursos con poca sobrecarga.
- Los servicios que se comunican mediante mensajes asincrónicos se pueden aislar a través de distintos conjuntos de colas. Cada cola puede tener un conjunto dedicado de mensajes de procesamiento de instancias en la cola o un único grupo de instancias que usa un algoritmo para quitar de la cola y enviar el procesamiento.
- Determine el nivel de granularidad de los mamparos. Por ejemplo, si desea distribuir los inquilinos en particiones, puede colocar cada uno de ellos en una partición independiente o colocar varios inquilinos en una única partición.
- Supervise el rendimiento y el Acuerdo de Nivel de Servicio de cada partición.
Cuándo usar este patrón
Este patrón se usa para:
- Aislar los recursos que se usan para consumir un conjunto de servicios back-end, sobre todo si la aplicación puede proporcionar cierto nivel de funcionalidad, aunque no responda uno de los servicios.
- Aislar los consumidores críticos de los consumidores estándares.
- Proteger la aplicación de errores en cascada.
Este patrón puede no ser adecuado cuando:
- Puede que no se acepte un uso menos eficaz de los recursos en el proyecto.
- La complejidad agregada no es necesaria
Diseño de cargas de trabajo
El arquitecto debe evaluar cómo se puede usar el patrón Bulkhead en el diseño de su carga de trabajo para abordar los objetivos y principios tratados en los pilares del Marco de la Well-Architected de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | La estrategia de aislamiento de errores introducida mediante la segmentación intencionada y completa entre componentes intenta contener los errores únicamente en el mamparo que está experimentando el problema, evitando el impacto en otros mamparos. - RE:02 Flujos críticos - RE:07 Conservación automática |
| Las decisiones de diseño de seguridad ayudan a garantizar la confidencialidad, integridad y disponibilidad de los datos y sistemas de su carga de trabajo. | La segmentación entre componentes ayuda a limitar los incidentes de seguridad al mamparo comprometido. - SE:04 Segmentación |
| La eficiencia del rendimiento ayuda a que la carga de trabajo satisfaga eficazmente las demandas mediante optimizaciones en el escalado, los datos y el código. | Cada mamparo se puede escalar individualmente para satisfacer con eficacia las necesidades de la tarea que está encapsulada en el mamparo. - PE:02 Planeamiento de capacidad - PE:05 Escapado y particiones |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
El siguiente archivo de configuración de Kubernetes crea un contenedor aislado que ejecuta un servicio individual, con sus propios recursos y límites de CPU y memoria.
apiVersion: v1
kind: Pod
metadata:
name: drone-management
spec:
containers:
- name: drone-management-container
image: drone-service
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "1"
Pasos siguientes
Recursos relacionados
- Circuit Breaker pattern (Patrón Circuit Breaker)
- Retry pattern (Patrón Retry)
- Throttling pattern (Patrón Throttling)