Solución de cuellos de botella de rendimiento en Azure Databricks
Nota
Este artículo se basa en una biblioteca de código abierto hospedada en GitHub en: https://github.com/mspnp/spark-monitoring.
La biblioteca original admite Azure Databricks Runtimes 10.x (Spark 3.2.x) y versiones anteriores.
Databricks ha contribuido a una versión actualizada para admitir Azure Databricks Runtimes 11.0 (Spark 3.3.x) y versiones posteriores en la rama de l4jv2 en: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Tenga en cuenta que la versión 11.0 no es compatible con la versión anterior debido a los diferentes sistemas de registro usados en los runtimes de Databricks. Asegúrese de usar la compilación correcta para Databricks Runtime. La biblioteca y el repositorio de GitHub están en modo de mantenimiento. No hay planes para versiones adicionales y el soporte técnico es la mejor opción. Para cualquier pregunta adicional sobre la biblioteca o la hoja de ruta para supervisar y registrar los entornos de Azure Databricks, póngase en contacto con azure-spark-monitoring-help@databricks.com.
En este artículo se describe cómo usar los paneles de supervisión para encontrar cuellos de botella de rendimiento en trabajos de Spark en Azure Databricks.
Azure Databricks es un servicio de análisis basado en Apache Spark, que facilita un rápido desarrollo e implementación de análisis de macrodatos. La supervisión y la solución de problemas de rendimiento son críticas cuando se trabaja con cargas de trabajo de Azure Databricks en producción. Para identificar problemas de rendimiento comunes, resulta útil usar visualizaciones de supervisión basadas en datos de telemetría.
Requisitos previos
Para configurar los paneles de Grafana que se muestran en este artículo:
Configure el clúster de Databricks para enviar telemetría a un área de trabajo de Log Analytics mediante la biblioteca de supervisión de Azure Databricks. Para obtener información, consulte el archivo Léame de GitHub.
Implemente Grafana en una máquina virtual. Para más información, consulte Uso de paneles para visualizar métricas de Azure Databricks.
El panel de Grafana que se implementa incluye un conjunto de visualizaciones de serie temporal. Cada gráfico es el trazado de serie temporal de las métricas relacionadas con un trabajo de Apache Spark, las fases del trabajo y las tareas que componen cada fase.
Información general del rendimiento de Azure Databricks
Azure Databricks se basa en Apache Spark, un sistema informático distribuido de uso general. El código de aplicación, conocido como trabajo, se ejecuta en un clúster de Apache Spark, coordinado por el administrador de clústeres. En general, un trabajo es la unidad de cálculo de nivel superior. Un trabajo representa la operación completa realizada por la aplicación Spark. Una operación típica incluye leer datos de un origen, aplicar transformaciones de datos y escribir los resultados en el almacenamiento o en otro destino.
Los trabajos se dividen en fases. El trabajo avanza por las fases en secuencial, lo que hace que las fases posteriores deban esperar a que se completen las fases anteriores. Las fases contienen grupos de tareas idénticas que se pueden ejecutar en paralelo en varios nodos del clúster de Spark. Las tareas son la unidad de ejecución más granular que tiene lugar en un subconjunto de los datos.
En las secciones siguientes se describen algunas visualizaciones de paneles, que son útiles para la solución de problemas de rendimiento.
Latencia del trabajo y de la fase
La latencia del trabajo es la duración de la ejecución de un trabajo desde el momento en que comienza hasta que se completa. Se muestra como percentiles de la ejecución de un trabajo por clúster e identificador de aplicación, para permitir la visualización de los valores atípicos. En el gráfico siguiente se muestra un historial de trabajos en el que el percentil 90 alcanzó los 50 segundos, aunque el percentil 50 se mantuvo constante en unos 10 segundos.
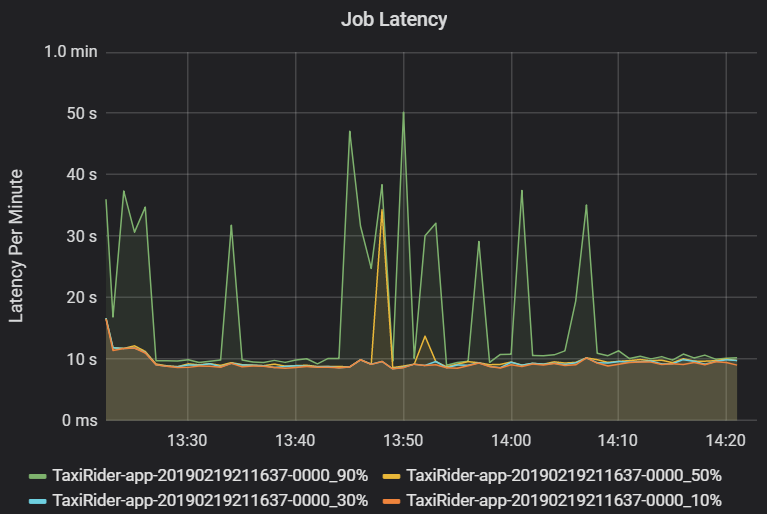
Investigue la ejecución del trabajo por clúster y aplicación, buscando picos de latencia. Una vez que identifique los clústeres y aplicaciones con latencia alta, pase a investigar la latencia de la fase.
La latencia de la fase también se muestra como percentiles para permitir la visualización de los valores atípicos. La latencia de la fase se divide por el nombre de clúster, de aplicación y de fase. Identifique los picos en la latencia de las tareas en el gráfico para determinar qué tareas están retrasando la finalización de la fase.
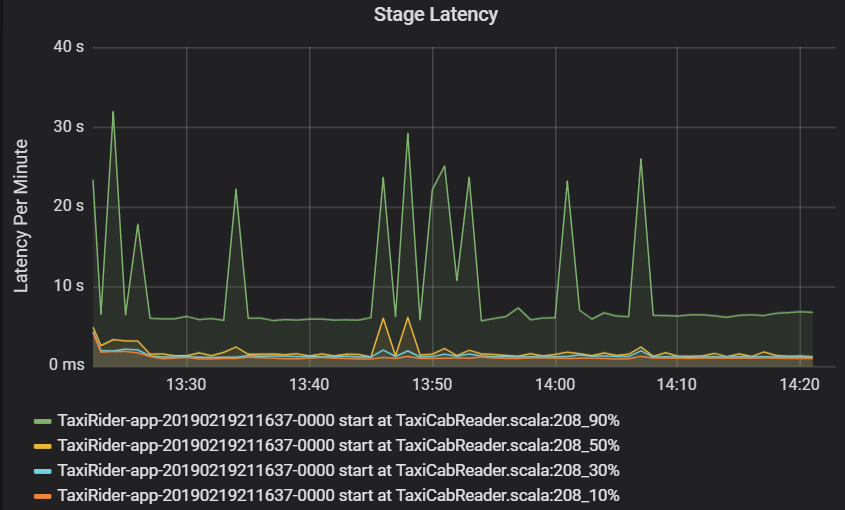
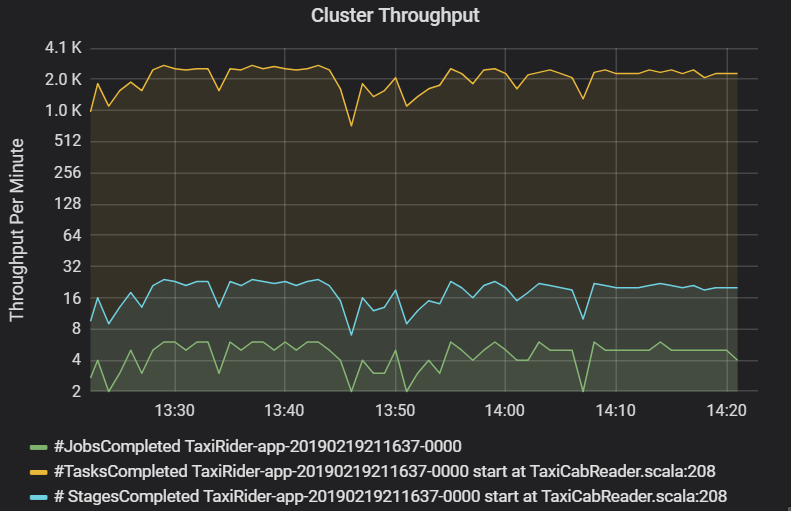
El gráfico de rendimiento del clúster muestra el número de trabajos, fases y tareas completadas por minuto. Esto le ayuda a comprender la carga de trabajo en cuanto al número relativo de fases y tareas por trabajo. Aquí puede ver que el número de trabajos por minuto oscila entre 2 y 6, mientras que el número de fases es de aproximadamente 12 a 24 por minuto.
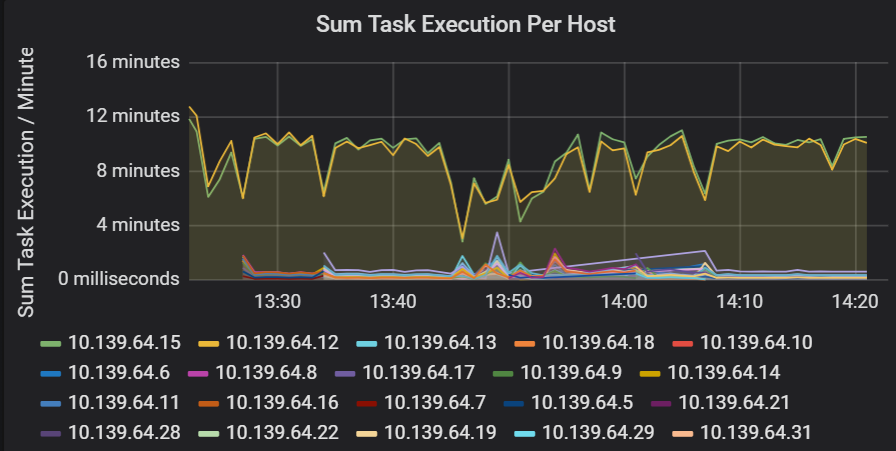
Suma de la latencia de ejecución de tareas
Esta visualización muestra la suma de la latencia de ejecución de tareas por host que se ejecuta en un clúster. Use este gráfico para detectar tareas que se ejecuten lentamente debido a que el host se ralentiza en un clúster o a una asignación incorrecta de tareas por ejecutor. En el siguiente gráfico, la mayoría de los hosts tienen una suma de aproximadamente 30 segundos. Sin embargo, dos de los hosts tienen sumas que se sitúan en torno a 10 minutos. Los hosts se ejecutan lentamente, o bien el número de tareas por ejecutor tiene una asignación inadecuada.
El número de tareas por ejecutor muestra que dos ejecutores tienen asignado un número desproporcionado de tareas, lo que provoca un cuello de botella.
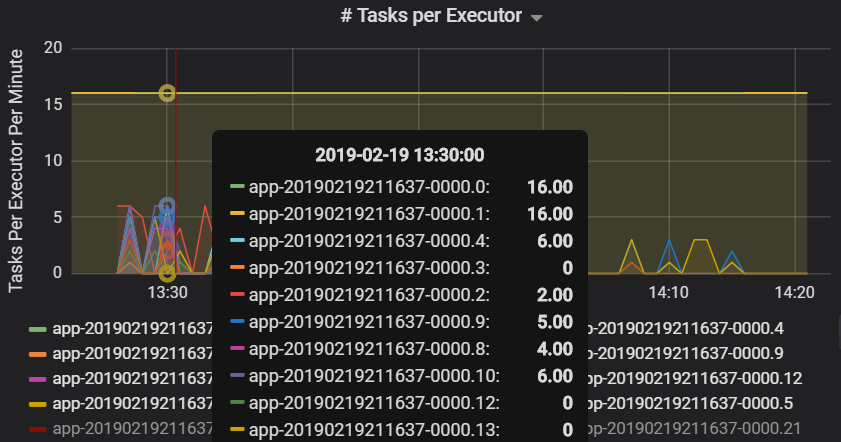
Métricas de tareas por fase
La visualización de las métricas de tareas proporciona el desglose de costos de la ejecución de una tarea. Puede usarla para ver el tiempo relativo empleado en tareas como la serialización y deserialización. Estos datos pueden mostrar oportunidades para optimizar por ejemplo, mediante el uso de variables de difusión para evitar el envío de datos. Las métricas de tareas también muestran el tamaño de los datos aleatorios de una tarea, así como los tiempos de lectura y escritura aleatorios. Si estos valores son altos, significa que hay muchos datos moviéndose a través de la red.
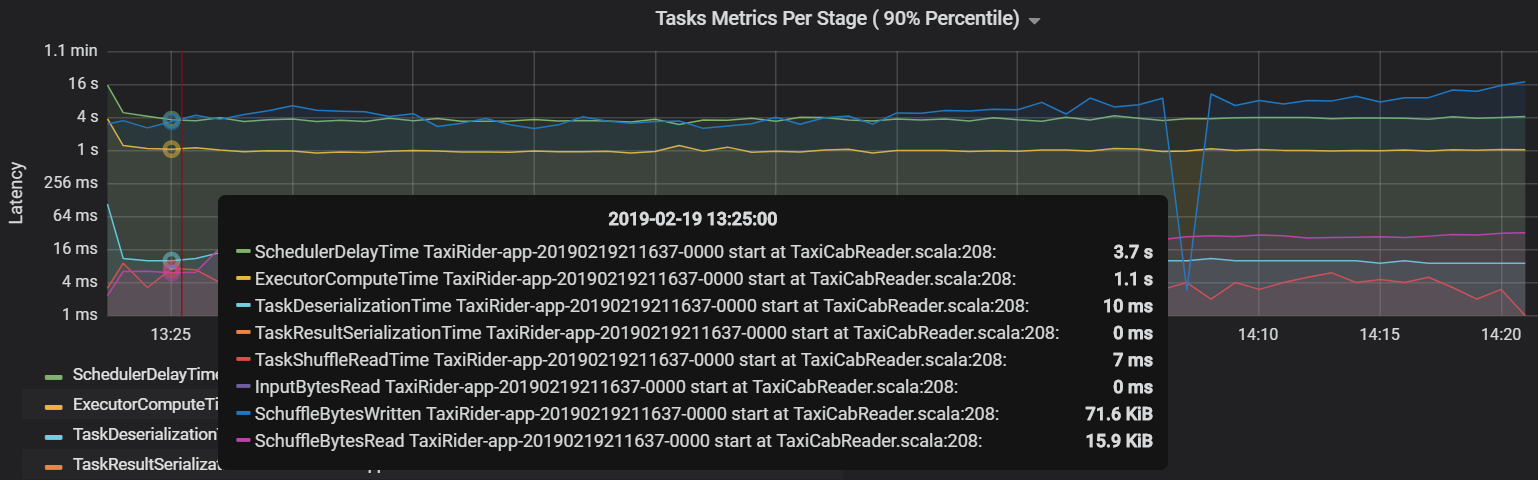
Otra métrica de tareas es el retraso del programador, que mide el tiempo que se tarda en programar una tarea. Idealmente, este valor debe ser bajo en comparación con el tiempo de proceso del ejecutor, que es el tiempo empleado en ejecutar realmente la tarea.
En el gráfico siguiente se muestra un tiempo de retraso del programador (3,7 s) que supera el tiempo de proceso del ejecutor (1,1 s). Esto significa que se pasa más tiempo esperando a que se programen las tareas que haciendo el trabajo real.
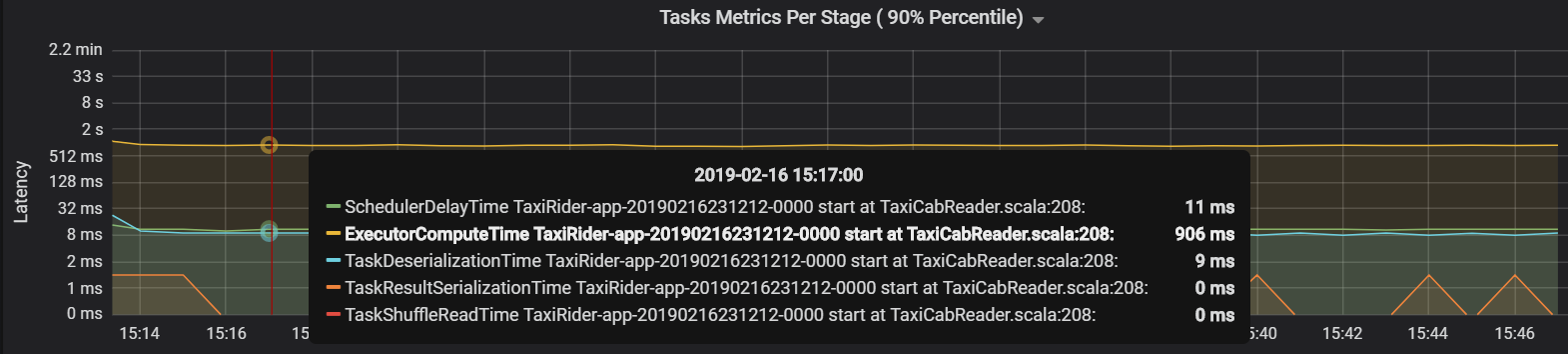
En este caso, el problema se debió a tener demasiadas particiones, lo que provocó una gran sobrecarga. La reducción del número de particiones disminuyó el tiempo de retraso del programador. En el gráfico siguiente se muestra que la mayor parte del tiempo se dedica a ejecutar la tarea.
Rendimiento y latencia de streaming
El rendimiento de streaming está directamente relacionado con el streaming estructurado. Hay dos métricas importantes asociadas al rendimiento de streaming: filas de entrada por segundo y filas procesadas por segundo. Si las filas de entrada por segundo superan las filas procesadas por segundo, el sistema de procesamiento de streaming tiene un retraso. Además, si los datos de entrada proceden de Event Hubs o Kafka, las filas de entrada por segundo deben mantenerse al ritmo de la tasa de ingesta de datos en el front-end.
Dos trabajos pueden tener un rendimiento de clúster similar, pero métricas de streaming muy diferentes. En la captura de pantalla siguiente se muestran dos cargas de trabajo diferentes. Son similares en cuanto al rendimiento del clúster (trabajos, fases y tareas por minuto). Pero la segunda ejecución procesa 12 000 filas/s frente a 4000 filas/s.
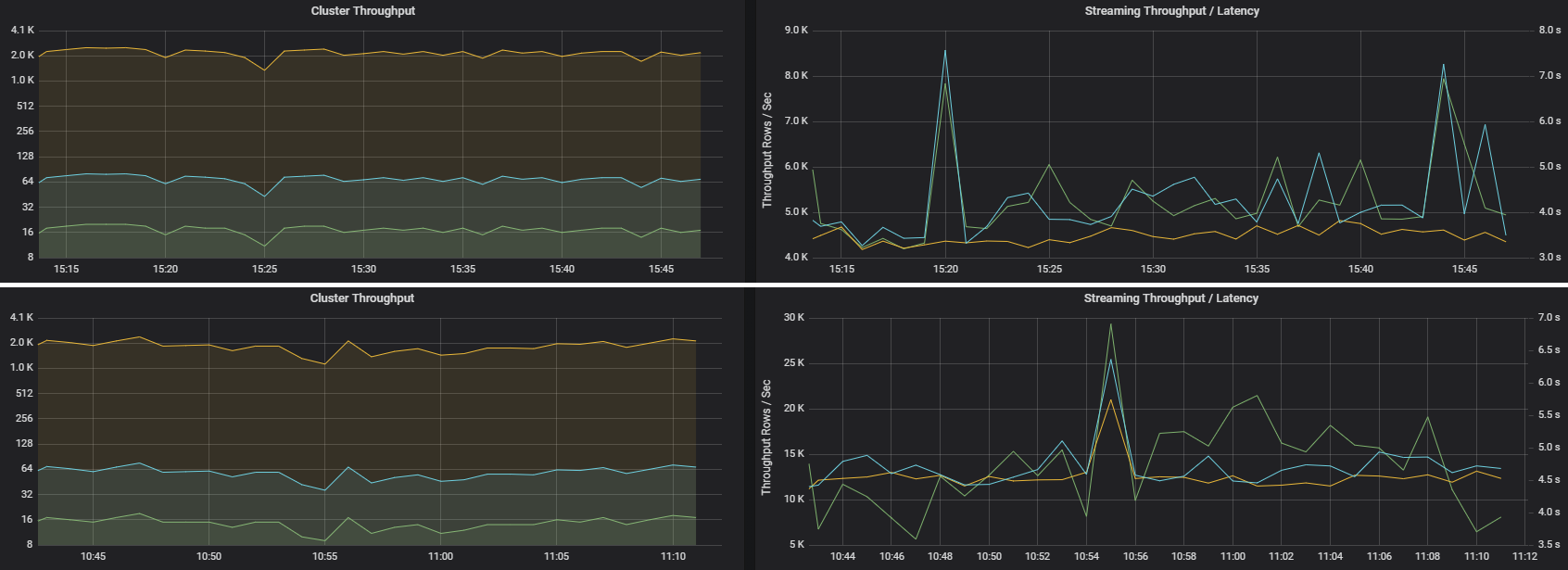
El rendimiento de streaming suele ser una mejor métrica empresarial que el rendimiento del clúster, ya que mide el número de registros de datos que se procesan.
Consumo de recursos por ejecutor
Estas métricas ayudan a comprender la labor que realiza cada ejecutor.
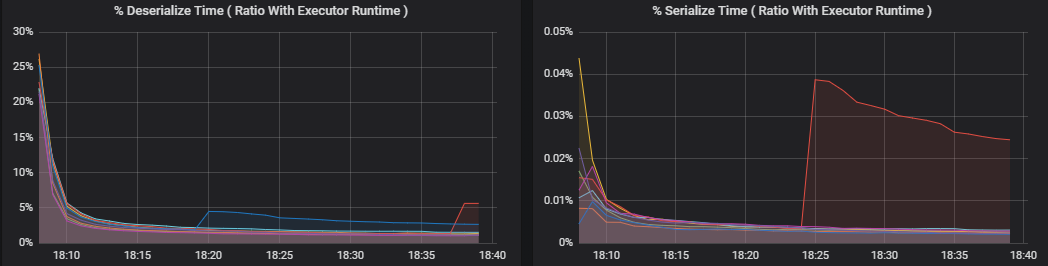
Las métricas de porcentaje miden cuánto tiempo invierte un ejecutor en varias cosas, expresado como una proporción del tiempo invertido frente al tiempo total de proceso del ejecutor. Son las siguientes:
- % de tiempo de serialización
- % de tiempo de deserialización
- % de tiempo del ejecutor de CPU
- % de tiempo de JVM
Estas visualizaciones muestran con cuánto contribuye cada una de estas métricas al procesamiento general del ejecutor.
Las métricas aleatorias son métricas relacionadas con los datos que se ordenan aleatoriamente entre los ejecutores.
- E/S aleatoria
- Memoria aleatoria
- Uso del sistema de archivos
- Uso del disco
Cuellos de botella de rendimiento comunes
Dos cuellos de botella de rendimiento comunes en Spark son las tareas rezagadas y un recuento de particiones aleatorias que no es el óptimo.
Tareas rezagadas
Las fases de un trabajo se ejecutan en secuencia, donde las fases anteriores bloquean las fases posteriores. Si una tarea ejecuta una partición aleatoria más lentamente que otras tareas, todas las tareas del clúster deben esperar a que la tarea lenta se ponga al día antes de que la fase pueda terminar. Esto puede deberse a los siguientes motivos:
Un host o un grupo de hosts se ejecutan lentamente. Síntomas: Alta latencia de tareas, fases o trabajos, y bajo rendimiento del clúster. El sumatorio de latencias de las tareas por host no se distribuirá de manera uniforme. Sin embargo, el consumo de recursos se distribuirá de manera uniforme entre los ejecutores.
Las tareas tienen una agregación costosa para ejecutarse (asimetría de datos). Síntomas: Alta latencia de tareas, de fases o de trabajos, o bajo rendimiento del clúster, pero el sumatorio de latencias por host se distribuye de manera uniforme. El consumo de recursos se distribuirá de manera uniforme entre los ejecutores.
Si las particiones tienen un tamaño distinto, una partición más grande puede producir una ejecución de tarea desequilibrada (asimetría de particiones). Síntomas: El consumo de recursos del ejecutor es alto en comparación con otros ejecutables que se ejecutan en el clúster. Todas las tareas que se ejecutan en ese ejecutor se ejecutarán lentamente y retendrán la ejecución de la fase en la canalización. Se dice que estas fases son barreras de la fase.
Recuento de particiones aleatorias que no es el óptimo
Durante una consulta de streaming estructurado, la asignación de una tarea a un ejecutor es una operación que consume muchos recursos en el clúster. Si los datos aleatorios no tienen el tamaño óptimo, la cantidad de retraso para una tarea afectará negativamente al rendimiento y la latencia. Si hay muy pocas particiones, los núcleos del clúster estarán infrautilizados, lo que puede provocar una ineficacia de procesamiento. Por el contrario, si hay demasiadas particiones, hay una gran cantidad de sobrecarga de administración para un número reducido de tareas.
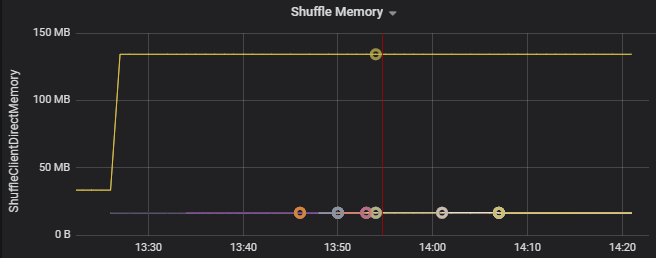
Use las métricas de consumo de recursos para solucionar problemas de asimetría de particiones y asignación indebida de los ejecutores en el clúster. Si una partición está sesgada, los recursos del ejecutor serán elevados en comparación con otros ejecutores que se ejecutan en el clúster.
Por ejemplo, en el gráfico siguiente se muestra que la memoria usada por el orden aleatorio en los dos primeros ejecutores es 90 veces mayor que en los otros ejecutores:
Pasos siguientes
- Supervisión de Azure Databricks en un área de trabajo de Azure Log Analytics
- Ruta de aprendizaje: Creación y funcionamiento de soluciones de aprendizaje automático con Azure Databricks
- Documentación de Azure Databricks
- Introducción a Azure Monitor
Recursos relacionados
- Supervisión de Azure Databricks
- Envío de registros de aplicaciones de Azure Databricks a Azure Monitor
- Uso de paneles para visualizar métricas de Azure Databricks
- Arquitectura de análisis moderno con Azure Databricks
- Canalizaciones de ingesta, ETL (extracción, transformación, carga) y procesamiento de flujos con Azure Databricks