Uso de paneles para visualizar métricas de Azure Databricks
Nota:
Este artículo se basa en una biblioteca de código abierto hospedada en GitHub en: https://github.com/mspnp/spark-monitoring.
La biblioteca original admite Azure Databricks Runtimes 10.x (Spark 3.2.x) y versiones anteriores.
Databricks ha contribuido a una versión actualizada para admitir Azure Databricks Runtimes 11.0 (Spark 3.3.x) y versiones posteriores en la rama de l4jv2 en: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Tenga en cuenta que la versión 11.0 no es compatible con la versión anterior debido a los diferentes sistemas de registro usados en los runtimes de Databricks. Asegúrese de usar la compilación correcta para Databricks Runtime. La biblioteca y el repositorio de GitHub están en modo de mantenimiento. No hay planes para versiones adicionales y el soporte técnico es la mejor opción. Para cualquier pregunta adicional sobre la biblioteca o la hoja de ruta para supervisar y registrar los entornos de Azure Databricks, póngase en contacto con azure-spark-monitoring-help@databricks.com.
En este artículo se muestra cómo configurar un panel de Grafana para supervisar trabajo de Azure Databricks a fin de detectar problemas de rendimiento.
Azure Databricks es un servicio de análisis rápido, eficaz y colaborativo basado en Apache Spark, que permite desarrollar e implementar rápidamente soluciones de análisis de macrodatos y de inteligencia artificial (IA). La supervisión es un componente crítico de las cargas de trabajo de Azure Databricks operativas en producción. El primer paso consiste en recopilar métricas en un área de trabajo para su análisis. En Azure, la mejor solución para administrar los datos de registro es Azure Monitor. Azure Databricks no es compatible de forma nativa con el envío de datos de registro a Azure Monitor, pero existe una biblioteca para esta funcionalidad disponible en GitHub.
Esta biblioteca habilita el registro de métricas de servicio de Azure Databricks, así como métricas de eventos de consulta de streaming de estructura de Apache Spark. Una vez que haya implementado correctamente esta biblioteca en un clúster de Azure Databricks, puede implementar un conjunto de paneles de Grafana que puede implementar como parte del entorno de producción.
Requisitos previos
Configure el clúster de Azure Databricks para usar la biblioteca de supervisión, como se describe en el archivo Léame de GitHub.
Implementación del área de trabajo de Azure Log Analytics
Para implementar el área de trabajo de Azure Log Analytics, realice estos pasos:
Vaya al directorio
/perftools/deployment/loganalytics.Implemente la plantilla logAnalyticsDeploy.json de Azure Resource Manager. Para obtener más información sobre la implementación de plantillas de Azure Resource Manager, vea Implementación de recursos con plantillas de ARM y la CLI de Azure. La plantilla presenta los parámetros siguientes:
- location: región donde se implementan el área de trabajo de Log Analytics y los paneles.
- serviceTier: plan de tarifa del área de trabajo. Diríjase aquí para obtener una lista de los valores válidos.
- dataRetention (opcional): número de días que se conservan los datos del registro en el área de trabajo de Log Analytics. El valor predeterminado es 30 días. Si el plan de tarifa es
Free, la retención de datos debe ser de siete días. - workspaceName (opcional): nombre del área de trabajo. Si no se especifica, la plantilla genera un nombre.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Esta plantilla crea el área de trabajo y también crea un conjunto de consultas predefinidas que se usan en el panel.
Implementación de Grafana en una máquina virtual
Grafana es un proyecto de código abierto que se puede implementar para visualizar las métricas de las series temporales almacenadas en el área de trabajo de Azure Log Analytics mediante el complemento Grafana para Azure Monitor. Grafana se ejecuta en una máquina virtual (VM) y requiere una cuenta de almacenamiento, una red virtual y otros recursos. Para implementar una máquina virtual con la imagen de Grafana certificada por Bitnami y los recursos asociados, realice estos pasos:
Use la CLI de Azure para aceptar los términos de la imagen de Azure Marketplace para Grafana.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultVaya al directorio
/spark-monitoring/perftools/deployment/grafanaen su copia local del repositorio de GitHub.Implemente la plantilla grafanaDeploy.json de Resource Manager de la siguiente manera:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Una vez completada la implementación, la imagen de Bitnami de Grafana se instala en la máquina virtual.
Actualización de la contraseña de Grafana
Como parte del proceso de instalación, el script de instalación de Grafana genera una contraseña temporal para el usuario administrador. Necesita esta contraseña temporal para iniciar sesión. Para obtener la contraseña temporal, realice estos pasos:
- Inicie sesión en Azure Portal.
- Seleccione el grupo de recursos en el que se implementaron los recursos.
- Seleccione la VM en la que se instaló Grafana. Si usó el nombre de parámetro predeterminado en la plantilla de implementación, el nombre de la VM va precedido de sparkmonitoring-vm-grafana.
- En la sección Soporte técnico y solución de problemas, haga clic en Diagnósticos de arranque para abrir la página de diagnósticos de arranque.
- Haga clic en Registro serie en la página de diagnósticos de arranque.
- Busque la siguiente cadena: "Setting Bitnami application password to" (Estableciendo la contraseña de la aplicación Bitnami en).
- Copie la contraseña en una ubicación segura.
A continuación, cambie la contraseña de administrador de Grafana siguiendo estos pasos:
- En Azure Portal, seleccione la VM y haga clic en Información general.
- Copie la dirección IP pública.
- Abra un explorador web y vaya a la dirección URL siguiente:
http://<IP address>:3000. - En la pantalla de inicio de sesión de Grafana, escriba admin como nombre de usuario y use la contraseña de Grafana de los pasos anteriores.
- Una vez que haya iniciado sesión, seleccione Configuración (icono de engranaje).
- Seleccione Administrador del servidor.
- En la pestaña Usuarios, seleccione el inicio de sesión admin.
- Actualice la contraseña.
Creación de un origen de datos de Azure Monitor
Cree una entidad de servicio que permita a Grafana administrar el acceso al área de trabajo Log Analytics. Para más información, vea Creación de una entidad de servicio de Azure con la CLI de Azure.
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDTome nota de los valores de appId, password y tenant en la salida de este comando:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Inicie sesión en Grafana del modo descrito anteriormente. Seleccione Configuración (icono de engranaje) y, a continuación, Orígenes de datos.
En la pestaña Orígenes de datos, haga clic en Agregar origen de datos.
Seleccione Azure Monitor como el tipo de origen de datos.
En la sección Configuración, escriba un nombre para el origen de datos en el cuadro de texto Nombre.
En la sección Detalles de API de Azure Monitor, escriba la siguiente información:
- Id. de suscripción: el identificador de la suscripción a Azure.
- Id. de inquilino: identificador del inquilino anterior.
- Id. de cliente: valor de "appId" anterior.
- Secreto de cliente: valor de "password" anterior.
En la sección Detalles de API de Azure Log Analytics, seleccione la casilla Same Details as Azure Monitor API (Mismos detalles que la API de Azure Monitor).
Haga clic en Guardar y probar. Si el origen de datos de Log Analytics está configurado correctamente, se muestra un mensaje de operación correcta.
Creación del panel
Cree los paneles en Grafana siguiendo estos pasos:
Vaya al directorio
/perftools/dashboards/grafanaen su copia local del repositorio de GitHub.Ejecute el siguiente script:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shLa salida del script es un archivo denominado SparkMonitoringDash.json.
Vuelva al panel de Grafana y seleccione Crear (icono de signo más).
Seleccione Import (Importar).
Haga clic en Cargar archivo .json.
Seleccione el archivo SparkMonitoringDash.json creado en el paso 2.
En la sección Opciones, en ALA, seleccione el origen de datos de Azure Monitor creado anteriormente.
Haga clic en Import.
Visualizaciones en los paneles
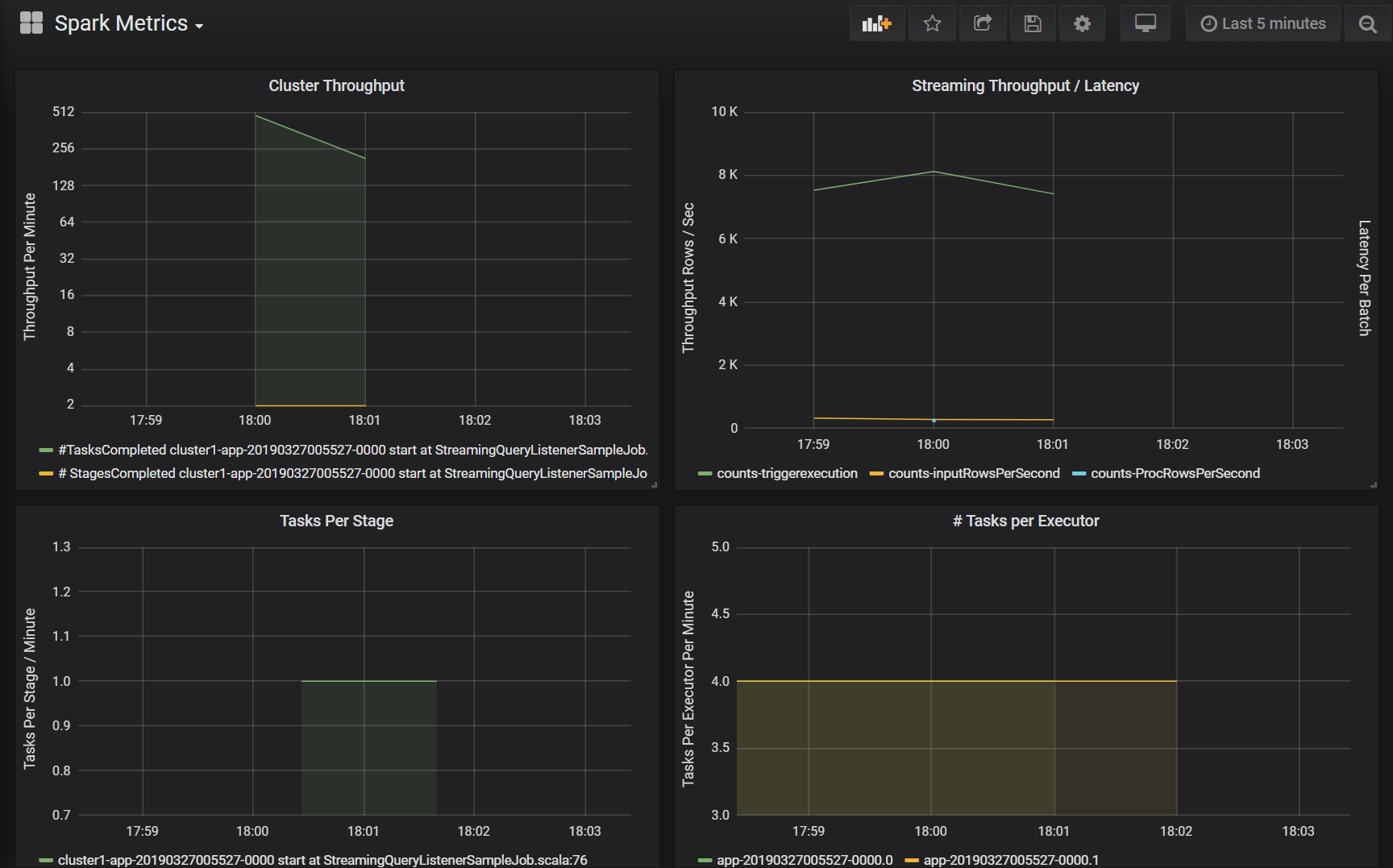
Los paneles de Azure Log Analytics y Grafana incluyen un conjunto de visualizaciones de serie temporal. Cada gráfico es el trazado de serie temporal de los datos de métricas relacionados con un trabajo de Apache Spark, las fases del trabajo y las tareas que componen cada fase.
Las visualizaciones son:
Latencia del trabajo
Esta visualización muestra la latencia de ejecución de un trabajo, que es una vista aproximada del rendimiento general de un trabajo. Muestra la duración de la ejecución del trabajo desde el principio hasta el final. Tenga en cuenta que la hora de inicio del trabajo no es la misma que la hora de envío del trabajo. La latencia se representa como percentiles (10 %, 30 %, 50 %, 90 %) de ejecución del trabajo indexados por el identificador de clúster y el identificador de la aplicación.
Latencia de la fase
La visualización muestra la latencia de cada fase por clúster, por aplicación y por fase individual. Esta visualización es útil para identificar una fase determinada que se ejecuta lentamente.
Latencia de la tarea
Esta visualización muestra la latencia de ejecución de tareas. La latencia se representa como un percentil de la ejecución de tareas por clúster, nombre de fase y aplicación.
Suma de ejecución de tareas por host
Esta visualización muestra la suma de la latencia de ejecución de tareas por host que se ejecuta en un clúster. La visualización de la latencia de ejecución de tareas por host identifica los hosts que tienen una latencia de tareas general mucho mayor que otros hosts. Esto puede significar que las tareas se han distribuido de manera ineficaz o desigual a los hosts.
Métricas de tareas
Esta visualización muestra un conjunto de las métricas de ejecución de una tarea determinada. Estas métricas incluyen el tamaño y la duración de un orden de datos aleatorio, la duración de las operaciones de serialización y deserialización, etc. Para ver el conjunto completo de métricas, vea la consulta de Log Analytics del panel. Esta visualización es útil para comprender las operaciones que componen una tarea e identificar el consumo de recursos de cada operación. Los picos del gráfico representan operaciones costosas que deben investigarse.
Rendimiento del clúster
Esta visualización es una vista de alto nivel de los elementos de trabajo indexados por clúster y aplicación para representar la cantidad de trabajo realizado por clúster y aplicación. Muestra el número de trabajos, tareas y fases completadas por clúster, aplicación y fase en incrementos de un minuto.
Rendimiento o latencia del streaming
Esta visualización está relacionada con las métricas asociadas a una consulta de streaming estructurado. El gráfico muestra el número de filas de entrada por segundo y el número de filas procesadas por segundo. Las métricas de streaming también se representan por aplicación. Estas métricas se envían cuando se genera el evento OnQueryProgress mientras se procesa la consulta de streaming estructurado y la visualización representa la latencia de streaming como la cantidad de tiempo, en milisegundos, que se tarda en ejecutar un lote de consultas.
Consumo de recursos por ejecutor
El siguiente es un conjunto de visualizaciones del panel que muestran el tipo de recurso determinado y cómo se consume por ejecutor en cada clúster. Estas visualizaciones ayudan a identificar los valores atípicos del consumo de recursos por ejecutor. Por ejemplo, si la asignación de trabajo de un ejecutor determinado está distorsionada, el consumo de recursos se elevará con respecto a otros ejecutores que se ejecutan en el clúster. Esto se puede identificar por los picos en el consumo de recursos de un ejecutor.
Métricas de tiempo de proceso del ejecutor
El siguiente es un conjunto de visualizaciones del panel que muestran la relación del tiempo de serialización del ejecutor, el tiempo de deserialización, el tiempo de CPU y el tiempo de la máquina virtual Java con el tiempo de proceso global del ejecutor. Esto muestra visualmente la cantidad de cada una de estas cuatro métricas que contribuye al procesamiento global del ejecutor.
Métricas aleatorias
El conjunto final de visualizaciones muestra las métricas de orden de datos aleatorio asociadas a una consulta de streaming estructurado en todos los ejecutores. Incluyen los bytes aleatorios leídos, los bytes aleatorios escritos, la memoria aleatoria y el uso de disco en las consultas en las que se usa el sistema de archivos.