Un problema habitual al que se enfrentan las organizaciones es cómo recopilar datos de varios orígenes, en varios formatos. A continuación, tendrá que moverlos a uno o varios almacenes de datos. Es posible que el destino no sea el mismo tipo de almacén de datos que el origen. A menudo el formato es diferente, o bien es necesario dar forma a los datos o limpiarlos antes de cargarlos en el destino final.
Con los años se han desarrollado varias herramientas, servicios y procesos para ayudarle a afrontar estos desafíos. Independientemente del proceso que se utilice, hay una necesidad común de coordinar el trabajo y aplicar cierto nivel de transformación de datos en la canalización de datos. Las secciones siguientes resaltan los métodos más habituales utilizados para realizar estas tareas.
Proceso de extracción, transformación y carga (ETL)
Extracción, transformación y carga (ETL) es una canalización de datos que se usa para recopilar datos de varios orígenes. A continuación, transforma los datos según las reglas de negocio y los carga en un almacén de datos de destino. El trabajo de transformación en ETL tiene lugar en un motor especializado y, a menudo, implica el uso de tablas de almacenamiento provisional para conservar los datos temporalmente a medida que estos se transforman y, finalmente, se cargan en su destino.
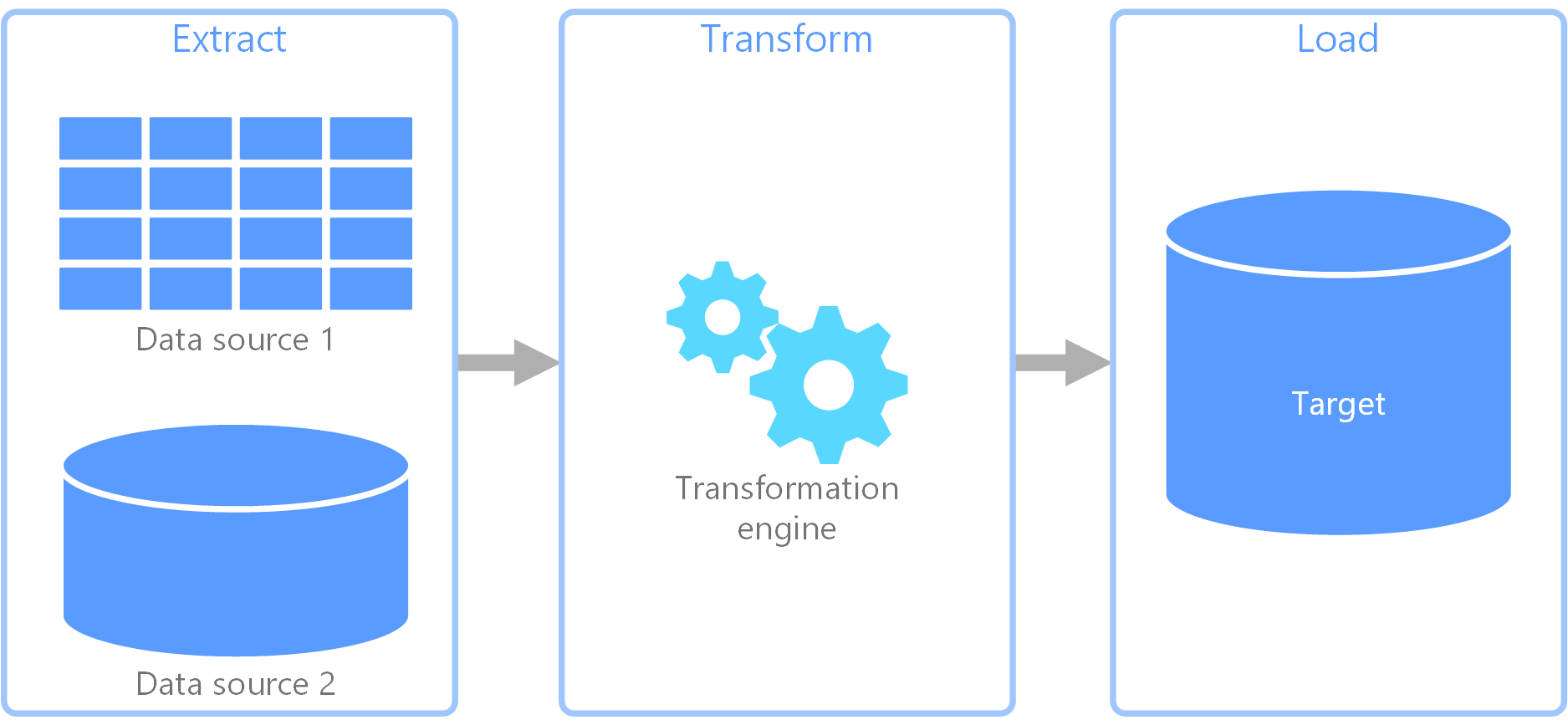
La transformación de datos que tiene lugar a menudo conlleva varias operaciones como filtrado, ordenación, agregación, combinación de datos, limpieza de datos, desduplicación y validación de datos.
Frecuentemente, las tres fases del proceso ETL se ejecutan en paralelo para ahorrar tiempo. Por ejemplo, mientras se extraen datos, puede que esté funcionando un proceso de transformación sobre los datos ya recibidos y de preparación para la carga, y puede que empiece a funcionar un proceso de carga sobre los datos preparados, en lugar de tener que esperar a que termine todo el proceso de extracción.
Servicio de Azure correspondiente:
Otras herramientas:
Extracción, carga y transformación (ELT)
Extracción, carga y transformación (ELT) difiere de ETL solo por la ubicación en la que se realiza la transformación. En la canalización de ELT, la transformación se produce en el almacén de datos de destino. En lugar de usar un motor de transformación independiente, las funcionalidades de procesamiento del almacén de datos de destino se utilizan para transformar los datos. Esto simplifica la arquitectura ya que permite quitar el motor de transformación de la canalización. Otra ventaja de este enfoque es que al escalar el almacén de datos de destino también se escala el rendimiento de la canalización de ELT. No obstante, ELT solo funciona bien si el sistema de destino tiene la suficiente potencia para transformar los datos de forma eficaz.
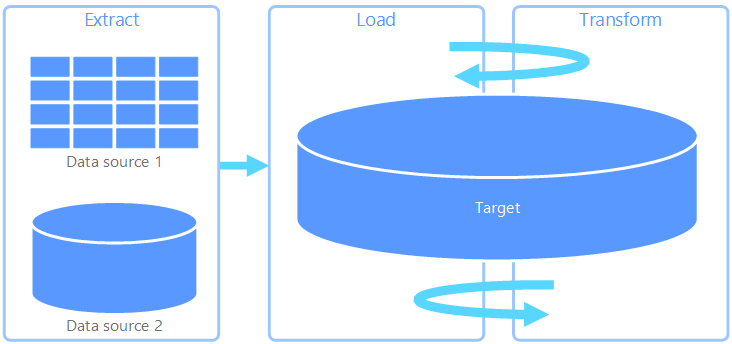
Los casos de uso habituales para ELT están dentro del dominio de los macrodatos. Por ejemplo, puede comenzar con la extracción de todos los datos de origen en archivos planos de un almacenamiento escalable, como el sistema de archivos distribuido de Hadoop, un almacén de blobs de Azure o Azure Data Lake Gen2 (o una combinación de estos). Se pueden utilizar tecnologías como Spark, Hive o PolyBase para consultar los datos de origen. El punto clave de ELT es que el almacén de datos que se usa para realizar la transformación es el mismo almacén de datos en el que se consumen en última instancia los datos. Este almacén de datos lee directamente desde el almacenamiento escalable, en lugar de cargar los datos en su propio almacenamiento propietario. Este enfoque omite el paso de copia de datos que se da en ETL. Esta es una operación que a menudo lleva mucho tiempo en el caso de conjuntos de datos grandes.
En la práctica, el almacén de datos de destino es un almacenamiento de datos que usa un clúster de Hadoop (con Hive o Spark) o grupos dedicados de SQL en una instancia de Azure Synapse Analytics. En general, un esquema se superpone sobre los datos del archivo plano en el momento de la consulta y se almacena como una tabla, lo cual permite que se puedan realizar consultas a los datos como en cualquier otra tabla del almacén de datos. Estas se conocen como tablas externas porque los datos no residen en el almacenamiento administrado por el propio almacén de datos, sino en alguna solución de almacenamiento escalable externo, como Azure Data Lake Store o Azure Blob Storage.
El almacén de datos solo administra el esquema de los datos y aplica el esquema en la lectura. Por ejemplo, un clúster de Hadoop que use Hive describiría una tabla de Hive en la que el origen de datos es, efectivamente, una ruta de acceso a un conjunto de archivos en HDFS. En Azure Synapse, PolyBase puede lograr el mismo resultado creando una tabla con los datos almacenados de forma externa en la propia base de datos. Una vez cargados los datos de origen, los datos presentes en las tablas externas se pueden procesar mediante las funcionalidades del almacén de datos. En escenarios de macrodatos, esto significa que el almacén de datos debe ser capaz de realizar un procesamiento paralelo masivo (MPP), que divide los datos en fragmentos más pequeños y distribuye el procesamiento de los fragmentos en varios nodos en paralelo.
La fase final de la canalización de ELT suele transformar los datos de origen a un formato final que es más eficaz para los tipos de consultas que se deben admitir. Por ejemplo, se pueden realizar particiones en los datos. Además, ELT podría usar formatos de almacenamiento optimizado como Parquet, que almacena datos orientados a filas en forma de columnas y proporciona una indexación optimizada.
Servicio de Azure correspondiente:
- Grupos dedicados de SQL en Azure Synapse Analytics
- Grupos de SQL sin servidor en Azure Synapse Analytics
- HDInsight con Hive
- Azure Data Factory
- Datamarts en Power BI
Otras herramientas:
Flujo de datos y flujo de control
En el contexto de las canalizaciones de datos, el flujo de control garantiza el procesamiento ordenado de un conjunto de tareas. Para aplicar el orden de procesamiento correcto de estas tareas, se usan las restricciones de precedencia. Puede considerar estas restricciones como conectores en un diagrama de flujo de trabajo, como se indica en la siguiente imagen. Cada tarea tiene un resultado como, por ejemplo, correcto, error o conclusión. Cualquier tarea posterior no comenzará el procesamiento hasta que su predecesora se haya completado con uno de estos resultados.
Los flujos de control ejecutan flujos de datos como una tarea. En una tarea Flujo de datos, los datos se extraen de un origen, se transforman o se cargan en un almacén de datos. La salida de una tarea Flujo de datos puede ser la entrada de la siguiente tarea, y los flujos de datos se pueden ejecutar en paralelo. A diferencia de los flujos de control, no se pueden agregar restricciones entre las tareas de un flujo de datos. Sin embargo, puede agregar un visor de datos para observar los datos a medida que cada tarea los va procesando.
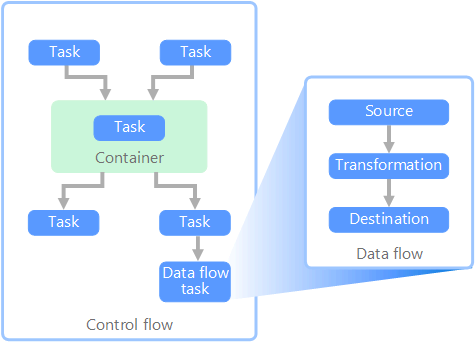
En el diagrama anterior, hay varias tareas en el flujo de control, una de las cuales es una tarea Flujo de datos. Una de las tareas se anida dentro de un contenedor. Los contenedores se pueden usar para proporcionar una estructura para las tareas, proporcionando una unidad de trabajo. Un ejemplo es la repetición de elementos en una colección, como los archivos de una carpeta o las instrucciones de una base de datos.
Servicio de Azure correspondiente:
Otras herramientas:
Opciones de tecnología
- Almacenes de datos de procesamiento de transacciones en línea (OLTP)
- Almacenes de datos de procesamiento analítico en línea (OLAP)
- Almacenamientos de datos
- Orquestación de canalizaciones
Pasos siguientes
- Integrar datos con Azure Data Factory o canalización de Azure Synapse
- Introducción a Azure Synapse Analytics
- Orqueste el movimiento y la transformación de datos en Azure Data Factory o en las canalizaciones de Azure Synapse
Recursos relacionados
Las arquitecturas de referencia siguientes muestran las canalizaciones ELT de un extremo a otro en Azure: