Ideas de solución
En este artículo se describe una idea de solución. El arquitecto de la nube puede usar esta guía para ayudar a visualizar los componentes principales de una implementación típica de esta arquitectura. Use este artículo como punto de partida para diseñar una solución bien diseñada que se adapte a los requisitos específicos de la carga de trabajo.
Este ejemplo muestra cómo realizar una carga incremental en una canalización de extracción, carga y transformación (ELT). Usa Azure Data Factory para automatizar la canalización de ECT. La canalización mueve de forma incremental los datos OLTP más recientes de una base de datos de SQL Server local a Azure Synapse. Los datos transaccionales se transforman en un modelo tabular para su análisis.
Architecture

Descargue un archivo Visio de esta arquitectura.
Esta arquitectura se basa en la que se muestra en Enterprise BI con Azure Synapse Analytics, pero agrega algunas características que son importantes para escenarios de almacenamiento de datos empresariales.
- Automatización de la canalización mediante Data Factory.
- Carga incremental.
- Integración de varios orígenes de datos.
- Carga de datos binarios como datos geoespaciales e imágenes.
Flujo de trabajo
La arquitectura consta de los siguientes servicios y componentes.
Orígenes de datos
SQL Server local. Los datos de origen se encuentran en una base de datos de SQL Server de forma local. Para simular el entorno local. Se usa la base de datos OLTP de ejemplo de OLTP Wide World Importers como base de datos de origen.
Datos externos. Un escenario común para el almacenamiento de datos es integrar varios orígenes de datos. Esta arquitectura de referencia carga un conjunto de datos externo que contiene las poblaciones de las ciudades por año y lo integra con los datos de la base de datos de OLTP. Puede usar estos datos para obtener información como: "¿El crecimiento de las ventas en cada región iguala o supera el crecimiento de población?"
Ingesta y almacenamiento de datos
Blob Storage. Blob Storage se utiliza como área de almacenamiento provisional del origen de datos antes de la carga en Azure Synapse.
Azure Synapse. Azure Synapse es un sistema distribuido diseñado para realizar análisis con datos de gran tamaño. Admite el procesamiento paralelo masivo (MPP), lo que lo hace idóneo para ejecutar análisis de alto rendimiento.
Azure Data Factory. Data Factory es un servicio administrado que organiza y automatiza el movimiento y la transformación de datos. En esta arquitectura, coordina las distintas fases del proceso de ELT.
Análisis e informes
Azure Analysis Services. Analysis Services es un servicio completamente administrado que proporciona funcionalidades de modelado de datos. El modelo semántico se carga en Analysis Services.
Power BI. Power BI es un conjunto de herramientas de análisis de negocios que sirve para analizar datos con el fin de obtener perspectivas empresariales. En el caso de esta arquitectura consulta el modelo semántico almacenado en Analysis Services.
Autenticación
Microsoft Entra ID autentica a los usuarios que se conectan al servidor de Analysis Services mediante Power BI.
Data Factory puede usar también Microsoft Entra ID para autenticarse en Azure Synapse mediante el uso de una entidad de servicio o de Managed Service Identity (MSI).
Componentes
- Azure Blob Storage
- Azure Synapse Analytics
- Azure Data Factory
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
Detalles del escenario
Canalización de datos
En Azure Data Factory, una canalización es una agrupación lógica de actividades que se usa para coordinar una tarea: en este caso, la carga y transformación de los datos en Azure Synapse.
Esta arquitectura de referencia define una canalización primaria que ejecuta una secuencia de canalizaciones secundarias. Cada canalización secundaria carga datos en una o varias tablas de un almacén de datos.
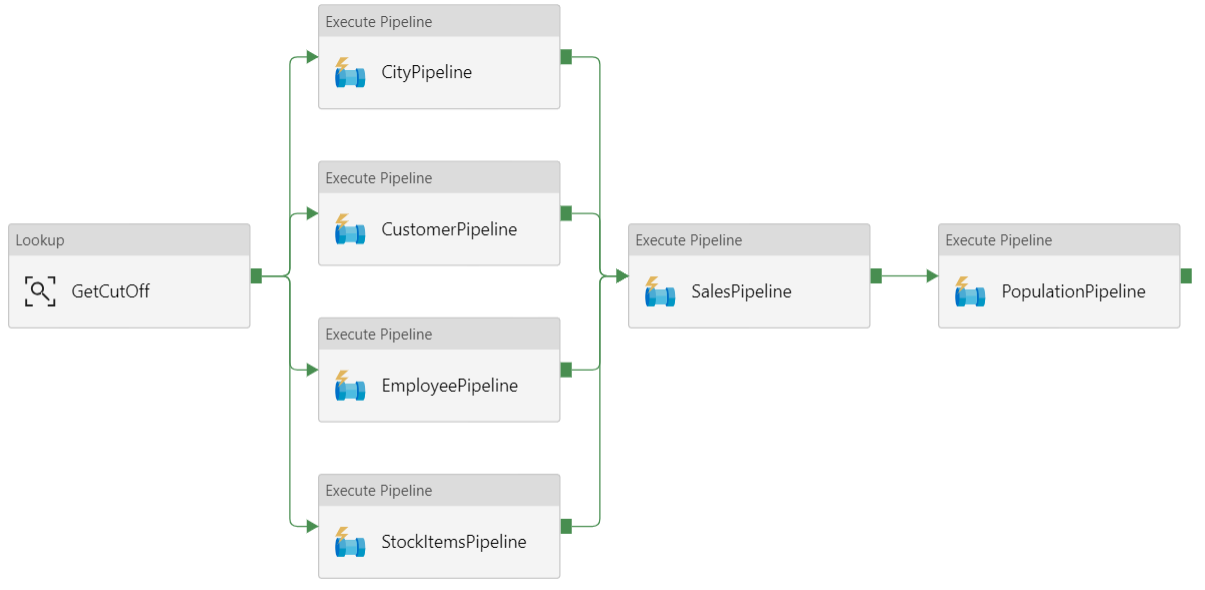
Recomendaciones
Carga incremental
Cuando se ejecuta un proceso automatizado de ETL o ELT, resulta más eficaz cargar solo los datos que han cambiado desde la última vez que se ejecutó. Esto se conoce como una carga incremental, frente a una carga completa, en la que se cargan todos los datos. Para realizar una carga incremental, se necesita alguna forma de identificar qué datos han cambiado. El método más común es usar un valor de marca de límite superior, lo que significa que se hace un seguimiento del valor más reciente de alguna de las columnas de la tabla de origen, una columna de fecha y hora o una columna de entero único.
A partir de SQL Server 2016, se pueden usar las tablas temporales, que son tablas con versiones de sistema que conservan el historial completo de los cambios de datos. El motor de base de datos registra automáticamente el historial de cada cambio en una tabla de historial independiente. Para consultar los datos históricos hay que agregar una cláusula FOR SYSTEM_TIME a una consulta. Internamente, el motor de base de datos consulta la tabla del historial, pero la aplicación no se percata de ello.
Nota
Para las versiones anteriores de SQL Server, puede usar captura de datos modificados (CDC). Este método es menos práctico que las tablas temporales, ya que hay que consultar una tabla de cambios independiente y el seguimiento de los cambios se realiza por un número de secuencia de registro, en lugar de una marca de tiempo.
Las tablas temporales son útiles para los datos de dimensión, que pueden cambiar con el tiempo. Las tablas de hechos suele representar una transacción inmutable, como por ejemplo una venta; en ese caso no tiene sentido mantener el historial de versiones del sistema. En su lugar, las transacciones suelen tener una columna que representa la fecha de la transacción, que se puede usar como valor de marca de agua. Por ejemplo, en la base de datos OLTP Wide World Importers, las tablas Sales.Invoices y Sales.InvoiceLines tienen un campo LastEditedWhen cuyo valor predeterminado es sysdatetime().
Este es el flujo general de la canalización de ELT:
En todas las tablas de la base de datos de origen, realice un seguimiento de la hora límite en que se ejecutó el último trabajo de ELT. Almacene esta información en la base de datos de almacenamiento de datos (en la instalación inicial, todas las horas se establecen en el "1-1-1900").
Durante el paso de exportación de datos, la hora límite se pasa como parámetro a un conjunto de procedimientos almacenados de la base de datos de origen. Dichos procedimientos consultan todos los registros que se cambiaron o crearon después de la hora límite. Para la tabla de hechos Sales, se usa la columna
LastEditedWhen. Para los datos de dimensiones, se usan tablas temporales con la versión del sistema.Una vez completada la migración de los datos, actualice la tabla que almacena las horas límite.
También es útil registrar un linaje para cada ejecución de ELT. En el caso de un registro concreto, el linaje asocia dicho registro con la ejecución de ELT que generó los datos. En cada ejecución de ETL, se crea un nuevo registro de linaje para todas las tablas, en el que se muestran la hora inicial y final de la carga. Las claves del linaje de los registros se almacenan en tablas de hechos y de dimensiones.
Después cargar un nuevo lote de datos en el almacén, actualice el modelo tabular de Analysis Services. Consulte Actualización asincrónica con la API REST.
Limpieza de datos
La limpieza de los datos debe formar parte del proceso de ELT. En esta arquitectura de referencia, un origen de datos incorrectos es la tabla de población de ciudades, donde algunas ciudades tienen una población cero, quizás porque no había datos disponibles. Durante el procesamiento, la canalización de ELT quita esas ciudades de la tabla de la población de ciudades. La limpieza de datos se debe realizar en las tablas de almacenamiento provisional, no en las tablas externas.
Orígenes de datos externos
Las bases de datos de almacenamiento de datos a menudo consolidan datos de varios orígenes. Por ejemplo, un origen de datos externo que contiene datos demográficos. Este conjunto de datos está disponible en Azure Blob Storage como parte del ejemplo WorldWideImportersDW.
Azure Data Factory puede realizar la copia directamente desde Blob Storage, mediante el conector de Blob Storage. Sin embargo, el conector requiere una cadena de conexión o una firma de acceso compartido, por lo que no se puede usar para copiar un blob con acceso de lectura público. Como alternativa, puede usar PolyBase para crear una tabla externa mediante Blob Storage y, después, copiar las tablas externas en Azure Synapse.
Control de datos binarios de gran tamaño
Por ejemplo, en la base de datos de origen, una tabla City tiene una columna Location que contiene un tipo de datos espaciales geography. Azure Synapse no admite el tipo geography de forma nativa, por lo que este campo se convierte al tipo varbinary durante la carga. (consulte Soluciones alternativas para los tipos de datos no admitidos).
Sin embargo, PolyBase admite un tamaño de columna máximo de varbinary(8000), lo que significa que algunos datos podrían aparecer truncados. Una solución alternativa a este problema es dividir los datos en fragmentos durante la exportación y, después, ensamblar dichos fragmentos como se indica a continuación:
Cree una tabla de almacenamiento provisional para la columna Location.
En cada ciudad, divida los datos de ubicación en fragmentos de 8000 bytes, lo que da como resultado 1 – N filas por cada ciudad.
Para ensamblar los fragmentos, use el operador PIVOT de T-SQL para convertir las filas en columnas y, después, concatene los valores de columna de cada ciudad.
El desafío es que cada ciudad se divida en un número diferente de filas, en función del tamaño de los datos geográficos. Para que el operador PIVOT funcione, todas las ciudades debe tener el mismo número de filas. Para que esto funcione, la consulta T-SQL realiza algunos trucos para rellenar las filas con valores en blanco, con el fin de que todas las ciudades tengan el mismo número de columnas después de la dinamización. La consulta resultante resulta ser mucho más rápida que crear bucles en las filas de una en una.
Pata los datos de imagen se usa el mismo método.
Cambio lento de dimensiones
Los datos de dimensiones son relativamente estáticos, pero se pueden cambiar. Por ejemplo, un producto se puede reasignar a otra categoría. Hay varios métodos para el control del cambio lento de dimensiones. Una técnica común, llamada de tipo 2, consiste en agregar un nuevo registro cada vez que cambia de una dimensión.
Para implementar este método, las tablas de dimensiones necesitan columnas adicionales que especifiquen el intervalo de fechas de vigencia de un registro determinado. Además, las claves principales de la base de datos de origen se duplicarán, por lo que la tabla de dimensiones debe tener una clave principal artificial.
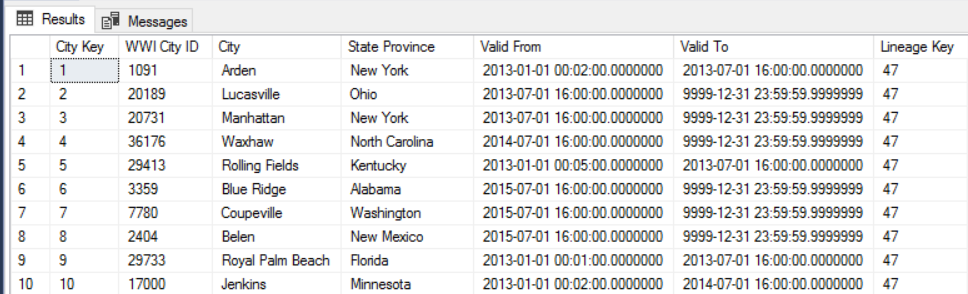
Por ejemplo, la siguiente imagen muestra la tabla Dimension.City. La columna WWI City ID es la clave principal de la base de datos de origen. La columna City Key es una clave artificial generada durante la canalización de ETL. Observe también que la tabla tiene las columnas Valid From y Valid To, que definen el intervalo de validez de cada fila. El valor de Valid To de los valores actuales es "9999-12-31".
La ventaja de este método es que conserva los datos históricos, lo que puede resultar muy útil de cara al análisis. Sin embargo, también significa que habrá varias filas para la misma entidad. Por ejemplo, estos son los registros que coinciden con WWI City ID = 28561:
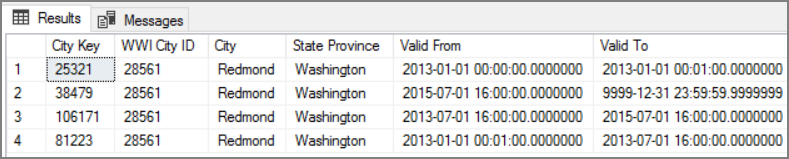
Para cada dato de Sales, desea asociar dicho hecho a una sola fila de la tabla de dimensiones City, correspondiente a la fecha de factura.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Seguridad
La seguridad proporciona garantías contra ataques deliberados y el abuso de datos y sistemas valiosos. Para obtener más información, vea Lista de comprobación de revisión de diseño para security.
Para mayor seguridad, puede usar los puntos de conexión de servicio de red virtual para proteger los recursos del servicio de Azure a solo la red virtual. Esto elimina por completo el acceso público a Internet de esos recursos, solo permite el tráfico solo desde la red virtual.
Con este método se crea una red virtual en Azure y, después, se crean puntos de conexión de servicio privados para los servicios de Azure. Luego se aplica una restricción a dichos servicios, por lo que solo le llega el tráfico de la red virtual. También se puede acceder ellos desde la red local a través de una puerta de enlace.
Tenga en cuenta las siguientes limitaciones:
Si se habilitan los puntos de conexión de servicio para Azure Storage, PolyBase no puede copiar datos de Azure Storage a Azure Synapse. Pero este problema se puede mitigar. Para más información, consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage.
Para mover datos desde el entorno local a Azure Storage, debe permitir las direcciones IP públicas desde el entorno local o desde ExpressRoute. Para más información, consulte Protección de servicios de Azure para las redes virtuales.
Para permitir que Analysis Services lea datos de Azure Synapse, implemente una máquina virtual Windows en la red virtual que contiene el punto de conexión de servicio de Azure Synapse. Instale la puerta de enlace de datos local de Azure en esta máquina virtual. Luego, conecte el servicio Azure Analysis a dicha puerta de enlace.
Optimización de costos
La optimización de costos consiste en examinar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para obtener más información, consulte Lista de comprobación de revisión de diseño para la optimización de costos.
Puede usar la calculadora de precios de Azure para calcular los costos. Estas son algunas consideraciones sobre los servicios que se usan en esta arquitectura de referencia.
Azure Data Factory
Azure Data Factory automatiza la canalización de ELT. La canalización mueve los datos de una base de datos de SQL Server local a Azure Synapse. A continuación, los datos se transforman en un modelo tabular para su análisis. En este escenario, los precios comienzan a partir de 0,001 USD por las ejecuciones de actividad al mes que incluye las ejecuciones de actividad, desencadenador y depuración. Dicho precio es el cargo base solo de la orquestación. También se le cobrarán las actividades de ejecución, como la copia de datos, las búsquedas y las actividades externas. Cada actividad tiene un precio individual. También se le cobrará por las canalizaciones sin desencadenadores ni ejecuciones asociadas en el mes. Todas las actividades se prorratean por minuto y se redondean.
Ejemplo de análisis de costos
Considere un caso de uso en el que hay dos actividades de búsqueda desde dos orígenes diferentes. Una toma 1 minuto y 2 segundos (se redondea a 2 minutos) y la otra toma 1 minuto, lo que da como resultado un tiempo total de 3 minutos. Una actividad de copia de datos tarda 10 minutos. Una actividad de procedimiento almacenado tarda 2 minutos. Total de ejecuciones de actividades de 4 minutos. El costo se calcula de la siguiente manera:
Ejecuciones de actividad: 4 * 0,001 USD = 0,004 USD
Búsquedas: 3 * (0,005 USD / 60) = 0,00025 USD
Procedimiento almacenado: 2 * (0,00025 USD / 60) = 0,000008 USD
Copia de datos: 10 * (0,25 USD / 60) * 4 unidades de integración de datos (DIU) = 0,167 USD
- Costo total por ejecución de canalización: 0,17 USD.
- Ejecutar una vez al día durante 30 días: 5,1 USD al mes.
- Ejecutar una vez al día por 100 tablas durante 30 días: 510 USD
Cada actividad tiene un costo asociado. Conozca el modelo de precios y use la calculadora de precios de ADF para obtener una solución optimizada no solo para el rendimiento, sino también para el costo. Administre los costos al iniciar, detener, poner en pausa y escalar los servicios.
Azure Synapse
Azure Synapse es ideal para cargas de trabajo intensivas con mayores necesidades de rendimiento de consultas y escalabilidad de proceso. Puede elegir el modelo de pago por uso o usar planes reservados de un año (ahorro del 37 %) o de 3 años (ahorro del 65 %).
El almacenamiento de datos se cobra por separado. Otros servicios, como la recuperación ante desastres y la detección de amenazas, también se cobran por separado.
Para más información, consulte Precios de Azure Synapse.
Analysis Services
Los precios de Azure Analysis Services dependen del nivel. La implementación de referencia de esta arquitectura usa el nivel Desarrollador, que se recomienda para escenarios de evaluación, desarrollo y prueba. Otros niveles incluyen, el nivel Básico, que se recomienda para un entorno de producción pequeño; el nivel Estándar para las aplicaciones de producción críticas. Para más información, consulte El nivel correcto cuando lo necesite.
No se aplica ningún cargo al pausar la instancia.
Para más información, vea Precios de Azure Analysis Services.
Blob Storage
Considere la posibilidad de usar la característica de capacidad reservada de Azure Storage para reducir el costo del almacenamiento. Con este modelo, obtiene un descuento si puede confirmar la reserva para la capacidad de almacenamiento fijo durante uno o tres años. Para más información Optimización de los costos de almacenamiento de blobs con capacidad reservada.
Para más información, consulte la sección Costos del artículo sobre el marco de buena arquitectura de Microsoft Azure.
Excelencia operativa
La excelencia operativa abarca los procesos de operaciones que implementan una aplicación y lo mantienen en ejecución en producción. Para obtener más información, vea Lista de comprobación de revisión de diseño para la excelencia operativa.
Cree grupos de recursos independientes para entornos de producción, desarrollo y pruebas. Los grupos de recursos independientes facilitan la administración de implementaciones, la eliminación de implementaciones de prueba y la asignación de derechos de acceso.
Coloque cada carga de trabajo en una plantilla de implementación independiente y almacene los recursos en los sistemas de control de código fuente. Puede implementar las plantillas en conjunto o por separado como parte de un proceso de CI/CD, lo que facilita el proceso de automatización.
En esta arquitectura, hay tres cargas de trabajo principales:
- El servidor de almacenamiento de datos, Analysis Services y los recursos relacionados.
- Azure Data Factory.
- Escenario simulado de local a la nube.
Cada carga de trabajo tiene su propia plantilla de implementación.
El servidor de almacenamiento de datos se instala y configura mediante el uso de comandos de la CLI de Azure que siguen el enfoque imperativo de la práctica IaC. Considere la posibilidad de usar scripts de implementación e integrarlos en el proceso de automatización.
Considere la posibilidad de almacenar provisionalmente las cargas de trabajo. Realice la implementación en varias fases y ejecute comprobaciones de validación en cada fase antes de pasar a la siguiente fase. De este modo, puede enviar actualizaciones a los entornos de producción de una manera muy controlada y minimizar los problemas de implementación imprevistos. Use las estrategias de implementación azul-verde y versiones de valores controlados para actualizar entornos de producción en directo.
Tenga una buena estrategia de reversión para administrar implementaciones con errores. Por ejemplo, puede volver a implementar automáticamente una implementación anterior que sea correcta desde el historial de implementación. Vea el parámetro de marca --rollback-on-error en la CLI de Azure.
Azure Monitor es la opción recomendada para analizar el rendimiento del almacenamiento de datos y toda la plataforma de análisis de Azure para una experiencia de supervisión integrada. Azure Synapse Analytics proporciona una experiencia de supervisión dentro de Azure Portal que muestra la información a la carga de trabajo del almacenamiento de datos. Azure Portal es la herramienta recomendada al supervisar el almacenamiento de datos, porque proporciona períodos de retención configurables, alertas, recomendaciones, y gráficos y paneles personalizables para métricas y registros.
Pasos siguientes
- Introducción a Azure Synapse Analytics
- Introducción a Azure Synapse Analytics
- Introducción al servicio Azure Data Factory
- ¿Qué es Azure Data Factory?
- Tutoriales de Azure Data Factory
Recursos relacionados
Puede examinar los siguientes escenarios de ejemplo de Azure que muestran soluciones específicas que usan algunas tecnologías similares: