Actividades del cliente necesarias
Previas al incidente
Para los servicios de Azure
- Familiarizarse con Azure Service Health en Azure Portal. Esta página actuará como la "tienda única" durante un incidente.
- Considere el uso de alertas de Service Health, que se pueden configurar para generar automáticamente notificaciones cuando se produzcan incidentes de Azure.
Para Power BI
- Familiarizarse con Service Health en el Centro de administración de Microsoft 365. Esta página actuará como la "tienda única" durante un incidente.
- Considere el uso de Administración de Microsoft 365 aplicación móvil para obtener notificaciones automáticas de alertas de incidentes de servicio.
Durante el incidente
Para los servicios de Azure
- Azure Service Health dentro de su portal de administración de Azure proporcionará las actualizaciones más recientes.
- Si hay problemas para acceder a Service Health, consulte la página Estado de Azure.
- Si alguna vez hay problemas para acceder a la página Estado, vaya a @AzureSupport X (anteriormente Twitter).
- Si el impacto o los problemas no coinciden con el incidente (o persisten después de la mitigación), póngase en contacto con el soporte técnico para generar una incidencia de soporte técnico de servicio.
Para Power BI
- La página de Estado del servicio dentro del Centro de administración de Microsoft 365 proporcionará las actualizaciones más recientes.
- Si hay problemas para acceder a Service Health, consulte la página de estado de Microsoft 365.
- Si el impacto o los problemas no coinciden con el incidente (o si los problemas persisten después de la mitigación), debe generar una incidencia de soporte técnico de servicio.
Después de la recuperación de Microsoft
Consulte las siguientes secciones para más información.
Después del incidente
Para servicios de Azure
- Microsoft publicará un PIR en Azure Portal: Service Health para su revisión.
Para Power BI
- Microsoft publicará un PIR en el Administración de Microsoft 365- Service Health para su revisión.
Proceso de esperar a Microsoft
El proceso "Esperar a Microsoft" consiste en esperar a que Microsoft recupere todos los componentes y servicios de la región primaria afectada. Una vez recuperados, valide el enlace de la plataforma de datos a servicios compartidos empresariales o de otro tipo y la fecha del conjunto de datos y, luego, ejecute los procesos de puesta al día del sistema.
Una vez completado este proceso, se puede realizar la validación técnica y empresarial por parte del experto en la materia, lo que permite la aprobación por las partes interesadas para la recuperación del servicio.
Reimplementación en caso de desastre
Para una estrategia de "Reimplementación ante desastres", se puede describir el siguiente flujo de proceso de alto nivel.
Recuperación de los sistemas de origen y servicios compartidos empresariales de Contoso

- Este paso es un requisito previo para la recuperación de la plataforma de datos.
- Este paso se completaría mediante los distintos grupos de soporte técnico operativo de Contoso responsables de los servicios compartidos empresariales y los sistemas operativos de origen.
Recuperación de servicios de Azure Los servicios de Azure hacen referencia a las aplicaciones y servicios que constituyen la oferta de nube de Azure y que están disponibles en la región secundaria para su implementación.

Los servicios de Azure hacen referencia a las aplicaciones y servicios que constituyen la oferta de nube de Azure y que están disponibles en la región secundaria para su implementación.
- Este paso es un requisito previo para la recuperación de la plataforma de datos.
- Microsoft y otros asociados de plataforma como servicio (PaaS)/software como servicio (SaaS) completarían este paso.
Recuperación de la base de la plataforma de datos
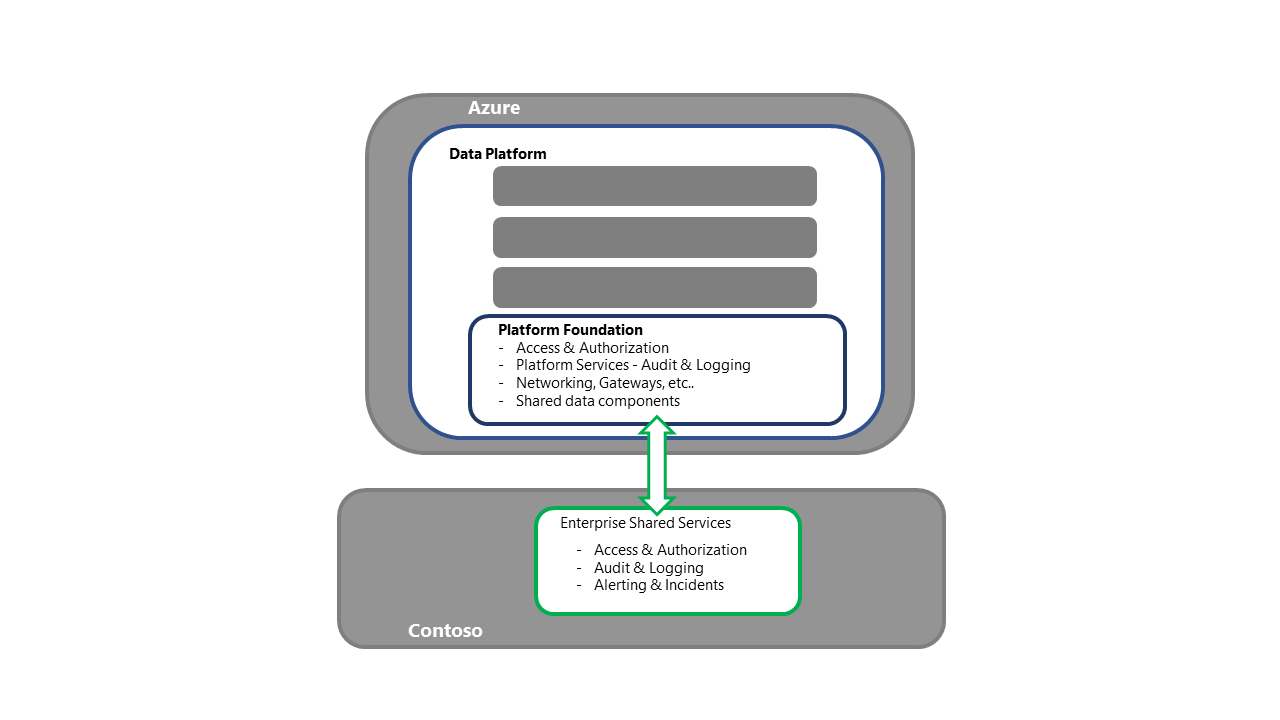
- Este paso es el punto de entrada para las actividades de recuperación de plataforma.
- Para la estrategia de reimplementación, cada componente o servicio necesarios se adquiriría e implementaría en la región secundaria.
- Consulte la sección Servicio y componente de Azure de esta serie para obtener un desglose detallado de los componentes y las estrategias de implementación.
- Este proceso también debe incluir actividades como el enlace a los servicios compartidos de empresa, garantizar la conectividad al acceso o la autenticación y validar que la descarga de registros funciona, al tiempo que garantiza la conectividad a procesos ascendentes y descendentes.
- Se deben confirmar los datos o el procesamiento. Por ejemplo, validación de la marca de tiempo de la plataforma recuperada.
- Si hay preguntas sobre la integridad de los datos, se podría tomar la decisión de revertirla más a tiempo antes de ejecutar el nuevo procesamiento para actualizar la plataforma.
- Tener un orden de prioridad para los procesos (en función del impacto empresarial) ayudará a organizar la recuperación.
- Este paso debe cerrarse con la validación técnica a menos que los usuarios empresariales interactúen directamente con los servicios. Si hay acceso directo, deberá haber un paso de validación empresarial.
- Una vez completada la validación, se produce una entrega a los equipos de soluciones individuales para iniciar su propio proceso de recuperación ante desastres (DR).
- Esta entrega debe incluir la confirmación de la marca de tiempo actual de los datos y los procesos.
- Si se van a ejecutar los procesos de datos empresariales principales, las soluciones individuales deben tener en cuenta esto: flujos entrantes o salientes, por ejemplo.
Recuperación de las soluciones individuales hospedadas por la plataforma
- Cada solución debe tener su propio runbook de recuperación ante desastres. Los runbooks deben contener al menos las partes interesadas empresariales designadas que probarán y confirmarán que se ha completado la recuperación del servicio.
- En función de la contención o prioridad de los recursos, las soluciones o cargas de trabajo clave se pueden priorizar por encima de otras: procesos empresariales principales sobre laboratorios ad hoc, por ejemplo.
- Una vez completados los pasos de validación, se produce una entrega a las soluciones de bajada para iniciar su proceso de recuperación ante desastres.
Traspaso a los sistemas dependientes de nivel inferior
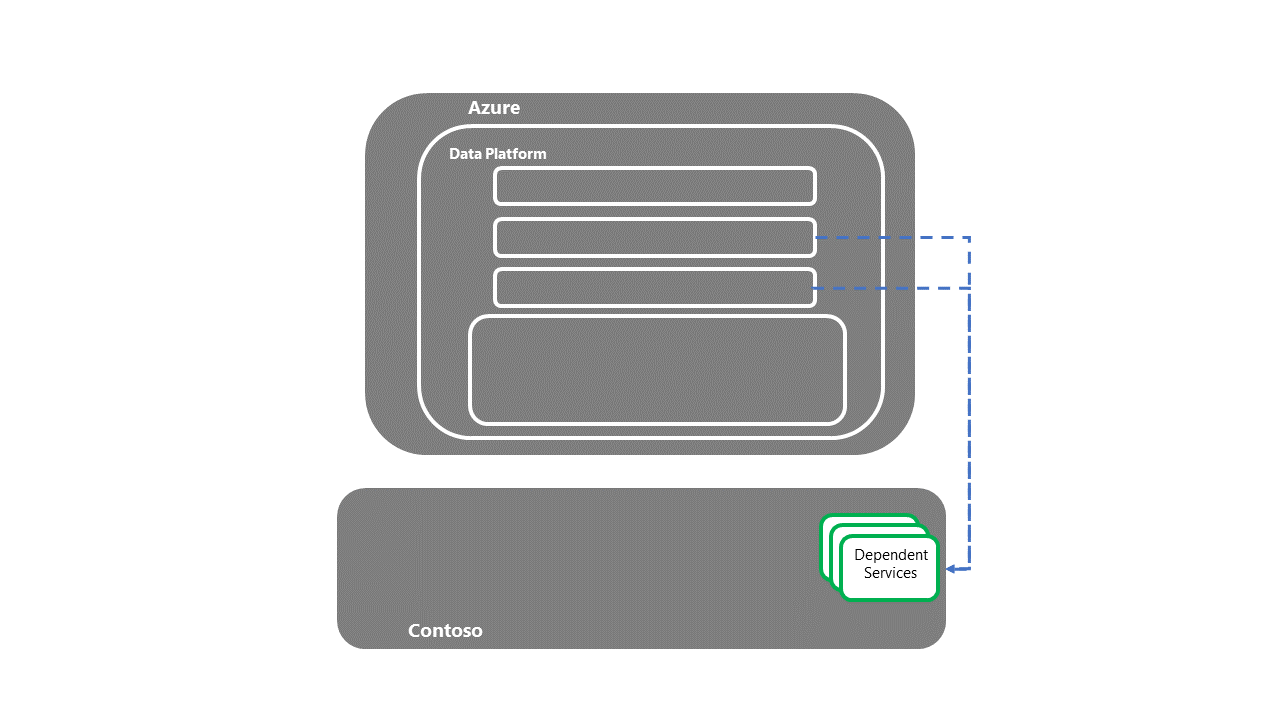
- Una vez recuperados los servicios dependientes, se completa el proceso de recuperación ante desastres de E2E.
Nota:
Aunque teóricamente es posible automatizar completamente un proceso de recuperación ante desastres E2E, es poco probable que se produzca el riesgo del evento frente al costo de las actividades sdLC necesarias para cubrir el proceso E2E.
Conmutación por recuperación a la región primaria La conmutación por recuperación es el proceso de mover el servicio de plataforma de datos y sus datos a la región primaria, una vez que está disponible para BAU.
Dependiendo de la naturaleza de los sistemas de origen y de varios procesos de datos, la conmutación por recuperación de la plataforma de datos podría realizarse independientemente de otras partes del ecosistema de datos.
Se recomienda a los clientes revisar las dependencias de su propia plataforma de datos (tanto de nivel superior como inferior) para tomar la decisión adecuada. En la sección siguiente se supone una recuperación independiente de la plataforma de datos.
- Una vez que todos los componentes o servicios necesarios estén disponibles en la región primaria, los clientes completarían una prueba de humo para validar la recuperación de Microsoft.
- Se validará la configuración del componente o servicio. Los deltas se abordarían a través de la reimplementación desde el control de código fuente.
- La fecha del sistema en la región primaria se establecerá en los componentes con estado. La diferencia entre la fecha establecida y la fecha y la marca de tiempo de la región secundaria deben abordarse reexecutando o reproduciendo los procesos de ingesta de datos desde ese momento.
- Con la aprobación de las partes interesadas empresariales y técnicas, se seleccionará una ventana de conmutación por recuperación. Lo ideal es que esto ocurra durante una pausa en la actividad y el procesamiento del sistema.
- Durante la reserva, la región primaria se incorporaría a la sincronización con la región secundaria, antes de que se cambiara el sistema.
- Después de un período de una ejecución en paralelo, la región secundaria se desconectaría del sistema.
- Los componentes de la región secundaria se quitarían o se quitarían, en función de la estrategia de recuperación ante desastres seleccionada.
Proceso de reserva en caliente
En el caso de una estrategia de "reserva semiactiva", el flujo de procesos de alto nivel está estrechamente alineado con el de "Reimplementación en caso de desastre"; la principal diferencia es que los componentes ya se han adquirido en la región secundaria. Esta estrategia elimina el riesgo de contención de recursos de otras organizaciones que buscan realizar su propia recuperación ante desastres en esa región.
Proceso de reserva activa
La estrategia de "reserva activa" significa que los servicios de plataforma, incluidos los sistemas PaaS y de infraestructura como servicio (IaaS), se conservarán a pesar del evento de desastre, ya que los sistemas secundarios funcionan en tándem con los sistemas principales. Al igual que con la estrategia "reserva semiactiva", esta estrategia elimina el riesgo de contención de recursos de otras organizaciones que buscan realizar su propia recuperación ante desastres en esa región.
Los clientes de reserva activa supervisarán la recuperación de Microsoft de componentes o servicios en la región primaria. Una vez completada, los clientes validarán los sistemas de la región primaria y realizarán la conmutación por recuperación a esta región. Este proceso sería similar al proceso de conmutación por error de la recuperación ante desastres, es decir, se comprueba el código base y los datos disponibles y se realiza una nueva implementación en caso necesario.
Nota
Se debe poner especial atención a que los metadatos del sistema sean coherentes entre las dos regiones.
- Una vez completada la conmutación por recuperación a la región primaria, los equilibradores de carga del sistema se pueden actualizar para devolver la región primaria a la topología del sistema. Si está disponible, se puede usar un enfoque de versión controlada para activar gradualmente la región primaria en el sistema.
Estructura del plan de recuperación ante desastres
Un plan de recuperación ante desastres eficaz presenta una guía paso a paso para la recuperación de servicios que se puede ejecutar mediante un recurso técnico de Azure. Por ello, a continuación se presenta una propuesta de estructura de MVP para un plan de recuperación ante desastres.
- Requisitos del proceso
- Cualquier detalle específico del proceso de recuperación ante desastres del cliente, como la autorización correcta necesaria para iniciar la recuperación ante desastres y tomar decisiones clave sobre la recuperación según sea necesario (incluida la "definición de hecho"), la referencia de vales de recuperación ante desastres de soporte técnico del servicio y los detalles de la sala de guerra.
- Confirmación de recursos, incluida la copia de seguridad del líder y del ejecutor de recuperación ante desastres. Todos los recursos deben estar documentados con contactos primarios y secundarios, vías de escalación y calendarios de permisos. En situaciones críticas de recuperación ante desastres, es posible que sea necesario tener en cuenta los sistemas de lista.
- Portátil, power packs o alimentación de copia de seguridad, conectividad de red y detalles de teléfono móvil para el ejecutor de recuperación ante desastres, copia de seguridad de recuperación ante desastres y cualquier punto de escalado.
- Proceso que se va a seguir si no se cumple alguno de los requisitos del proceso.
- Lista de contactos
- Liderazgo de recuperación ante desastres y grupos de apoyo.
- Pymes empresariales que completarán el ciclo de prueba y revisión para la recuperación técnica.
- Propietarios empresariales afectados, incluidos los aprobadores de recuperación del servicio.
- Propietarios técnicos afectados, incluidos los aprobadores de recuperación técnica.
- Compatibilidad con SME en todas las áreas afectadas, incluidas las soluciones clave hospedadas por la plataforma.
- Sistemas de bajada afectados: soporte operativo.
- Sistemas de origen ascendentes: soporte operativo.
- Contactos de servicios compartidos de empresa. Por ejemplo, compatibilidad con el acceso y la autenticación, la supervisión de seguridad y la compatibilidad con la puerta de enlace
- Cualquier proveedor externo o de terceros, incluidos los contactos de soporte técnico para proveedores en la nube.
- Diseño de arquitectura
- Describa los detalles del escenario de un extremo (E2E) y adjunte toda la documentación de soporte técnico asociada.
- Dependencias
- Enumere todas las relaciones y dependencias de los componentes.
- Requisitos previos de recuperación ante desastres
- Confirmación de que los sistemas de origen ascendentes están disponibles según sea necesario.
- Se ha concedido acceso elevado a través de la pila a los recursos del ejecutor de recuperación ante desastres.
- Los servicios de Azure están disponibles según sea necesario.
- Proceso que se va a seguir si no se ha cumplido alguno de los requisitos previos.
- Recuperación técnica: instrucciones paso a paso
- Orden de ejecución.
- Descripción del paso.
- Paso previo.
- Pasos detallados del proceso para cada acción discreta, incluidas las direcciones URL.
- Instrucciones de validación, incluida la evidencia necesaria.
- Tiempo esperado para completar cada paso, incluidas las contingencias.
- Proceso que se va a seguir si se produce un error en el paso.
- Puntos de escalación en caso de error o compatibilidad con SME.
- Recuperación técnica: requisitos posteriores
- Confirme la marca de tiempo de fecha actual del sistema en los componentes clave.
- Confirme las direcciones URL e ip del sistema de recuperación ante desastres.
- Prepárese para el proceso de revisión de las partes interesadas del negocio, incluida la confirmación del acceso a los sistemas y las PYME empresariales que completan la validación y la aprobación.
- Revisión y aprobación de partes interesadas empresariales
- Detalles de contacto del recurso empresarial.
- Los pasos de validación empresarial según la recuperación técnica anterior.
- La pista de evidencia necesaria del aprobador empresarial para cerrar la sesión de la recuperación.
- Requisitos posteriores de recuperación
- Entrega al soporte operativo para ejecutar los procesos de datos para actualizar el sistema.
- Entrega de los procesos y soluciones de bajada: confirmando los detalles de fecha y conexión del sistema de recuperación ante desastres.
- Confirme que el proceso de recuperación se completa con el cliente potencial de recuperación ante desastres: confirma la pista de evidencia y el runbook completado.
- Notifique a los equipos de seguridad que los privilegios de acceso elevados se pueden quitar del equipo de recuperación ante desastres.
Llamadas
- Se recomienda incluir capturas de pantalla del sistema de cada proceso. Estas capturas de pantalla ayudarán a abordar la dependencia de las PYME del sistema para completar las tareas.
- Para mantenerse al día de los servicios en la nube en constante evolución, el plan de recuperación ante desastres debe revisarse, probarse y ejecutarse periódicamente mediante recursos con conocimientos actuales de Azure y sus servicios.
- Los pasos de recuperación técnica deben reflejar la prioridad del componente y la solución para la organización. Por ejemplo, los flujos de datos empresariales principales se recuperan antes de los laboratorios de análisis de datos ad hoc.
- Los pasos de recuperación técnica deben seguir el orden de los flujos de trabajo (normalmente de izquierda a derecha), una vez recuperados los componentes básicos o el servicio como Key Vault. Esta estrategia garantizará que las dependencias ascendentes estén disponibles y los componentes se puedan probar correctamente.
- Una vez completado el plan paso a paso, se debe obtener un tiempo total para las actividades con contingencia. Si este total supera el objetivo de tiempo de recuperación (RTO) acordado, hay varias opciones disponibles:
- Automatice los procesos de recuperación seleccionados (siempre que sea posible).
- Buscar oportunidades para ejecutar los pasos de recuperación seleccionados en paralelo (siempre que sea posible). Teniendo en cuenta, sin embargo, que esta estrategia puede requerir recursos adicionales del ejecutor de la recuperación ante desastres.
- Eleva los componentes clave a niveles de servicio más altos, como PaaS, donde Microsoft asume una mayor responsabilidad para las actividades de recuperación de servicios.
- Amplíe el RTO con las partes interesadas.
Pruebas de recuperación ante desastres
La naturaleza de la oferta de servicio en la nube de Azure da como resultado restricciones en cualquier escenario de pruebas de recuperación ante desastres. Por lo tanto, se aconseja mantener una suscripción de recuperación ante desastres con los componentes de la plataforma de datos, ya que estarán disponibles en la región secundaria.
A partir de esta línea de base, el runbook del plan de recuperación ante desastres se puede ejecutar de forma selectiva, prestando atención específica a los servicios y componentes que se pueden implementar y validar. Este proceso requerirá un conjunto de datos de prueba mantenido, lo que permitirá la confirmación de las comprobaciones de validación técnica y empresarial según el plan.
Un plan de recuperación ante desastres debe probarse periódicamente para no solo asegurarse de que está actualizado, sino también para crear "memoria muscular" para los equipos que realizan actividades de conmutación por error y recuperación.
- Las copias de seguridad de los datos y de la configuración también deben probarse cada cierto tiempo para garantizar que son "aptas según los objetivos" para favorecer cualquier actividad de recuperación.
El área clave en la que centrarse durante una prueba de recuperación ante desastres es asegurarse de que los pasos prescriptivos siguen siendo correctos y los tiempos estimados siguen siendo pertinentes.
- Si las instrucciones reflejan las pantallas del portal en lugar de código, estas se deben validar al menos cada 12 meses debido a la cadencia del cambio en la nube.
Aunque la aspiración es tener un proceso de recuperación ante desastres totalmente automatizado, la automatización total puede ser improbable debido a la rareza del evento. Por lo tanto, se recomienda establecer la línea de base de la recuperación con la infraestructura como código (IaC) de la configuración de estado deseado (DSC) utilizada para entregar la plataforma y luego aumentar a medida que se crean nuevos proyectos sobre la línea de base.
- Con el tiempo, a medida que se amplían los componentes y servicios, se debe aplicar una NFR, que requiere que la canalización de la implementación de producción se refactorice para proporcionar cobertura para la recuperación ante desastres.
Si los tiempos del runbook superan el RTO, hay varias opciones:
- Amplíe el RTO con las partes interesadas.
- Reduzca el tiempo necesario para las actividades de recuperación, a través de la automatización, la ejecución de tareas en paralelo o la migración a niveles de servidor en la nube superiores.
Azure Chaos Studio
Azure Chaos Studio es un servicio administrado para mejorar la resistencia mediante la inserción de errores en las aplicaciones de Azure. Chaos Studio permite orquestar la inserción de errores en los recursos de Azure de forma segura y controlada, por medio de experimentos. Consulte la documentación del producto para ver una descripción de los tipos de errores admitidos actualmente.
La iteración actual de Chaos Studio solo cubre un subconjunto de componentes y servicios de Azure. Hasta que se agreguen más bibliotecas de errores, Chaos Studio es un enfoque recomendado para pruebas de resistencia aisladas en lugar de pruebas completas de recuperación ante desastres del sistema.
Puede consultar más información sobre Chaos Studio en la documentación sobre Azure Chaos Studio.
Azure Site Recovery
En el caso de los componentes de IaaS, Azure Site Recovery protegerá la mayoría de las cargas de trabajo que se ejecutan en una máquina virtual o un servidor físico compatibles.
Existen instrucciones detalladas para estas tareas:
- Ejecución de un simulacro de la recuperación ante desastres de máquinas virtuales de Azure
- Ejecución de una conmutación por error de recuperación ante desastres en una región secundaria
- Ejecución de una conmutación por recuperación a la región primaria
- Habilitación de la automatización de un plan de recuperación ante desastres
Recursos relacionados
- Diseño para lograr resistencia y disponibilidad
- Continuidad empresarial y recuperación ante desastres
- Copia de seguridad y recuperación ante desastres para aplicaciones de Azure
- Resistencia en Azure
- Resumen de acuerdos de nivel de servicio (SLA)
- Cinco procedimientos recomendados para anticipar errores
Pasos siguientes
Ahora que ha aprendido a implementar el escenario, puede leer un resumen de la serie de recuperación ante desastres para la plataforma de datos de Azure.
Recursos relacionados
- Recuperación ante desastres para la plataforma de datos de Azure: información general
- Recuperación ante desastres para una plataforma de datos de Azure: arquitectura
- Recuperación ante desastres en la plataforma de datos de Azure: detalles del escenario
- Recuperación ante desastres para una plataforma de datos de Azure: recomendaciones