Introducción a las implementaciones de lotes de Azure OpenAI
La API de Batch de Azure OpenAI está diseñada para controlar las tareas de procesamiento a gran escala y de alto volumen de forma eficaz. Procese grupos asincrónicos de solicitudes con cuota independiente, con una solución alternativa de destino de 24 horas, con un costo del 50 % menos que el estándar global. Con el procesamiento por lotes, en lugar de enviar una solicitud cada vez, se envía un gran número de solicitudes en un único archivo. Las solicitudes por lotes globales tienen una cuota de tokens en cola independiente, lo que evita cualquier interrupción de las cargas de trabajo en línea.
Los siguientes son algunos de los principales casos de uso:
Procesamiento de datos a gran escala: analice rápidamente conjuntos de datos extensos en paralelo.
Generación de contenido: cree grandes volúmenes de texto, como descripciones de productos o artículos.
Revisión y resumen de documentos: automatice la revisión y el resumen de documentos largos.
Automatización del soporte al cliente: controle numerosas consultas simultáneamente para respuestas más rápidas.
Extracción y análisis de datos: extraiga y analice información de grandes cantidades de datos no estructurados.
Tareas de procesamiento de lenguaje natural (NLP): realice tareas como análisis de sentimiento o traducción en grandes conjuntos de datos.
Marketing y personalización: genere contenido personalizado y recomendaciones a escala.
Importante
Nuestro objetivo es procesar solicitudes por lotes en un plazo de 24 horas; no expiran los trabajos que tardan más tiempo. Puede cancelar el trabajo en cualquier momento. Al cancelar el trabajo, se cancela cualquier trabajo restante y se devuelve cualquier trabajo ya completado. Se le cobrará por cualquier trabajo completado.
Los datos almacenados en reposo permanecen en la geografía de Azure designada, mientras que los datos se pueden procesar para la inferencia en cualquier ubicación de Azure OpenAI. Obtenga más información sobre la retención de datos.
Soporte técnico de lote
Disponibilidad global del modelo por lotes
| Región | o3-mini, 2025-01-31 | gpt-4o, 2024-05-13 | gpt-4o, 2024-08-06 | gpt-4o, 2024-11-20 | gpt-4o-mini, 2024-07-18 | gpt-4, 0613 | gpt-4, turbo-2024-04-09 | gpt-35-turbo, 0613 | gpt-35-turbo, 1106 | gpt-35-turbo, 0125 |
|---|---|---|---|---|---|---|---|---|---|---|
| australiaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| brazilsouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| canadaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| estado | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| francecentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| germanywestcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| japaneast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| koreacentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| northcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norwayeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| polandcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southafricanorth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southindia | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| suecia central | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norte de suiza | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| uksouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westeurope | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
El registro es necesario para el acceso a o3-mini. Para obtener más información, consulte la guía de modelos de razonamiento.
Los modelos siguientes admiten lotes globales:
| Modelo | Versión | Formato de entrada |
|---|---|---|
o3-mini |
31-01-2025 | text |
gpt-4o |
2024-08-06 | Texto e imagen |
gpt-4o-mini |
2024-07-18 | Texto e imagen |
gpt-4o |
2024-05-13 | Texto e imagen |
gpt-4 |
turbo-2024-04-09 | text |
gpt-4 |
0613 | text |
gpt-35-turbo |
0125 | text |
gpt-35-turbo |
1106 | text |
gpt-35-turbo |
0613 | text |
Consulte la página de modelos para obtener la información más actualizada sobre regiones o modelos en los que se admite actualmente el lote global.
Compatibilidad con API
| Versión de la API | |
|---|---|
| Versión más reciente de la API de disponibilidad general: | 2024-10-21 |
| Versión preliminar más reciente de la API: | 2025-01-01-preview |
Compatibilidad agregada por primera vez en: 2024-07-01-preview
Compatibilidad de características
Actualmente, no se admiten lo siguiente:
- Integración con la API de asistentes.
- Integración con la característica Azure OpenAI en los datos.
Nota:
Ahora se admiten salidas estructuradas con Global Batch.
Implementación de lote
Nota:
En el Portal de la Fundición de IA de Azure, los tipos de implementación de lote aparecerán como Global-Batch y Data Zone Batch. Para más información sobre los tipos de implementación de Azure OpenAI, consulte nuestra guía de tipos de implementación .

Sugerencia
Se recomienda habilitar cuota dinámica para todas las implementaciones de modelos por lotes globales para ayudar a evitar errores de trabajo debido a una cuota de tokens en cola insuficiente. La cuota dinámica permite que la implementación aproveche de forma oportunista más cuota cuando haya capacidad adicional disponible. Cuando la cuota dinámica se establece en desactivada, la implementación solo podrá procesar solicitudes hasta el límite de tokens en cola que se definió al crear la implementación.
Requisitos previos
- Una suscripción a Azure (cree una cuenta gratuita).
- Un recurso de Azure OpenAI con un modelo del tipo de implementación
Global-Batchimplementado. Puede consultar la guía de creación de recursos e implementación de modelo para obtener ayuda con este proceso.
Preparación del archivo por lotes
Al igual que el ajuste, el lote global usa archivos en formato de líneas JSON (.jsonl). A continuación se muestran algunos archivos de ejemplo con diferentes tipos de contenido admitido:
Formato de entrada
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id es necesario para permitir identificar qué solicitud por lotes individual corresponde a una respuesta determinada. Las respuestas no se devolverán en orden idéntico al orden definido en el archivo por lotes .jsonl.
Debe establecerse el atributo model para que coincida con el nombre de la implementación del lote global que desea establecer como destino para las respuestas de inferencia.
Importante
El atributo model debe establecerse para que coincida con el nombre de la implementación de Batch global que desea establecer como destino para las respuestas de inferencia. El mismo nombre de implementación del modelo de Batch global debe estar presente en cada línea del archivo por lotes. Si desea tener como destino una implementación diferente, debe hacerlo en un archivo o trabajo por lotes independiente.
Para obtener el mejor rendimiento, se recomienda enviar archivos grandes para el procesamiento por lotes, en lugar de un gran número de archivos pequeños con solo unas pocas líneas en cada archivo.
Crear un archivo de entrada
En este artículo, crearemos un archivo denominado test.jsonl y copiaremos el contenido del bloque de código de entrada estándar anterior al archivo. Deberá modificar y agregar el nombre de implementación del lote global a cada línea del archivo.
Carga del archivo por lotes
Una vez preparado el archivo de entrada, primero debe cargar el archivo para poder iniciar un trabajo por lotes. La carga de archivos se puede realizar mediante programación o a través de Studio.
Inicie sesión en el portal de Azure AI Foundry.
Seleccione el recurso de Azure OpenAI donde hay disponible una implementación de modelo por lotes global.
Seleccione Trabajos de Batch>+Crear trabajos por lotes.
En la lista desplegable en Datos por lote>Cargar archivos>, seleccione Cargar archivo y proporcione la ruta de acceso al archivo
test.jsonlcreado en el paso anterior >Siguiente.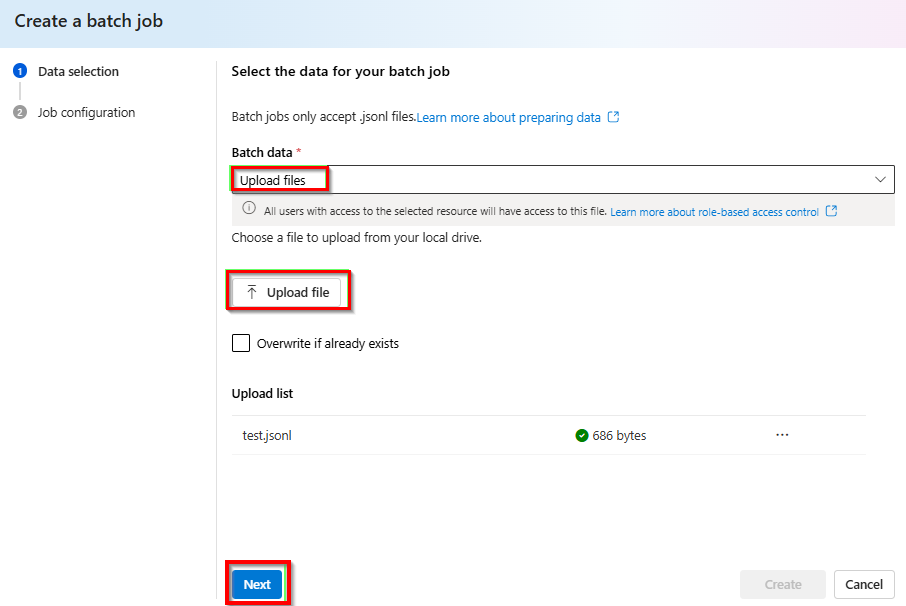


Creación de trabajo por lotes
Seleccione Crear para iniciar su trabajo por lotes.

Seguimiento del progreso del trabajo por lotes
Una vez creado el trabajo, puede supervisar el progreso seleccionando el identificador de trabajo para el trabajo creado más recientemente. De manera predeterminada, accederá a la página de estado de su trabajo por lotes creado más recientemente.

Puede realizar un seguimiento del estado del trabajo en el panel derecho:

Recuperación del archivo de salida del trabajo por lotes
Una vez que su trabajo haya finalizado o alcanzado un estado terminal, generará un archivo de error y un archivo de salida que podrá descargar para su revisión seleccionando el botón correspondiente con el icono de la flecha hacia abajo.

Cancelación del lote
Cancela un lote en curso. El lote estará en estado cancelling durante un máximo de 10 minutos, antes de cambiar a cancelled, donde tendrá resultados parciales (si los hay) disponibles en el archivo de salida.

Requisitos previos
- Una suscripción a Azure (cree una cuenta gratuita).
- Python 3.8 o una versión posterior
- La siguiente biblioteca de Python:
openai - Jupyter Notebooks
- Un recurso de Azure OpenAI con un modelo del tipo de implementación
Global-Batchimplementado. Puede consultar la guía de creación de recursos e implementación de modelo para obtener ayuda con este proceso.
Los pasos de este artículo están diseñados para ejecutarse secuencialmente en cuadernos de Jupyter Notebook. Por este motivo, solo crearemos instancias del cliente de Azure OpenAI una vez al principio de los ejemplos. Si desea ejecutar un paso fuera de servicio, a menudo tendrá que configurar un cliente de Azure OpenAI como parte de esa llamada.
Incluso si ya tiene instalada la biblioteca de Python de OpenAI, es posible que tenga que actualizar la instalación a la versión más reciente:
!pip install openai --upgrade
Preparación del archivo por lotes
Al igual que el ajuste, el lote global usa archivos en formato de líneas JSON (.jsonl). A continuación se muestran algunos archivos de ejemplo con diferentes tipos de contenido admitido:
Formato de entrada
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id es necesario para permitir identificar qué solicitud por lotes individual corresponde a una respuesta determinada. Las respuestas no se devolverán en orden idéntico al orden definido en el archivo por lotes .jsonl.
Debe establecerse el atributo model para que coincida con el nombre de la implementación del lote global que desea establecer como destino para las respuestas de inferencia.
Importante
El atributo model debe establecerse para que coincida con el nombre de la implementación de Batch global que desea establecer como destino para las respuestas de inferencia. El mismo nombre de implementación del modelo de Batch global debe estar presente en cada línea del archivo por lotes. Si desea tener como destino una implementación diferente, debe hacerlo en un archivo o trabajo por lotes independiente.
Para obtener el mejor rendimiento, se recomienda enviar archivos grandes para el procesamiento por lotes, en lugar de un gran número de archivos pequeños con solo unas pocas líneas en cada archivo.
Crear un archivo de entrada
En este artículo, crearemos un archivo denominado test.jsonl y copiaremos el contenido del bloque de código de entrada estándar anterior al archivo. Deberá modificar y agregar el nombre de la implementación por lotes global a cada línea del archivo. Guarde este archivo en el mismo directorio que se está ejecutando el cuaderno de Jupyter Notebook.
Carga del archivo por lotes
Una vez preparado el archivo de entrada, primero debe cargar el archivo para poder iniciar un trabajo por lotes. La carga de archivos se puede realizar mediante programación o a través de Studio. En este ejemplo se usan variables de entorno en lugar de los valores de clave y punto de conexión. Si no conoce el uso de variables de entorno con Python, consulte uno de nuestros inicios rápidos en los que se explica paso a paso el proceso de configuración de las variables de entorno.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
# Upload a file with a purpose of "batch"
file = client.files.create(
file=open("test.jsonl", "rb"),
purpose="batch"
)
print(file.model_dump_json(indent=2))
file_id = file.id
Salida:
{
"id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"bytes": 815,
"created_at": 1722476551,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": null,
"status_details": null
}
Creación de trabajo por lotes
Una vez que el archivo se haya cargado correctamente, puede enviar el archivo para el procesamiento por lotes.
# Submit a batch job with the file
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
)
# Save batch ID for later use
batch_id = batch_response.id
print(batch_response.model_dump_json(indent=2))
Nota:
Actualmente, la ventana de finalización debe establecerse en 24 h. Si establece algún otro valor distinto de 24 h, se producirá un error en el trabajo. Los trabajos que tardan más de 24 horas seguirán ejecutándose hasta que se cancelen.
Salida:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": null,
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
Seguimiento del progreso del trabajo por lotes
Cuando haya creado el trabajo por lotes correctamente, puede supervisar su progreso en Studio o mediante programación. Al comprobar el progreso del trabajo por lotes, se recomienda esperar al menos 60 segundos entre cada llamada de estado.
import time
import datetime
status = "validating"
while status not in ("completed", "failed", "canceled"):
time.sleep(60)
batch_response = client.batches.retrieve(batch_id)
status = batch_response.status
print(f"{datetime.datetime.now()} Batch Id: {batch_id}, Status: {status}")
if batch_response.status == "failed":
for error in batch_response.errors.data:
print(f"Error code {error.code} Message {error.message}")
Salida:
2024-07-31 21:48:32.556488 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: validating
2024-07-31 21:49:39.221560 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:50:53.383138 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:52:07.274570 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:53:21.149501 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:54:34.572508 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:55:35.304713 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:56:36.531816 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:57:37.414105 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: completed
Aparecen los siguientes valores de estado:
| Estado | Descripción |
|---|---|
validating |
El archivo de entrada se está validando antes de que pueda comenzar el procesamiento por lotes. |
failed |
El archivo de entrada ha producido un error en el proceso de validación. |
in_progress |
El archivo de entrada se validó correctamente y el lote se está ejecutando. |
finalizing |
El lote se ha completado y los resultados se están preparando. |
completed |
El lote se ha completado y los resultados están listos. |
expired |
El lote no pudo completarse en el período de tiempo de 24 horas. |
cancelling |
El lote está siendo cancelled (puede tardar hasta 10 minutos en entrar en vigor). |
cancelled |
el lote era cancelled. |
Para examinar los detalles del estado del trabajo, puede ejecutar:
print(batch_response.model_dump_json(indent=2))
Salida:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1722477429,
"error_file_id": "file-c795ae52-3ba7-417d-86ec-07eebca57d0b",
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": 1722477177,
"in_progress_at": null,
"metadata": null,
"output_file_id": "file-3304e310-3b39-4e34-9f1c-e1c1504b2b2a",
"request_counts": {
"completed": 3,
"failed": 0,
"total": 3
}
}
Observe que hay error_file_id y un elemento independiente output_file_id. Use error_file_id para ayudar a depurar los problemas que se producen con el trabajo por lotes.
Recuperación del archivo de salida del trabajo por lotes
import json
output_file_id = batch_response.output_file_id
if not output_file_id:
output_file_id = batch_response.error_file_id
if output_file_id:
file_response = client.files.content(output_file_id)
raw_responses = file_response.text.strip().split('\n')
for raw_response in raw_responses:
json_response = json.loads(raw_response)
formatted_json = json.dumps(json_response, indent=2)
print(formatted_json)
Salida:
Por motivos de brevedad, solo se incluye una respuesta de finalización de chat única de salida. Si sigue los pasos descritos en este artículo, debe tener tres respuestas similares a las siguientes:
{
"custom_id": "task-0",
"response": {
"body": {
"choices": [
{
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
},
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Microsoft was founded on April 4, 1975, by Bill Gates and Paul Allen in Albuquerque, New Mexico.",
"role": "assistant"
}
}
],
"created": 1722477079,
"id": "chatcmpl-9rFGJ9dh08Tw9WRKqaEHwrkqRa4DJ",
"model": "gpt-4o-2024-05-13",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": "fp_a9bfe9d51d",
"usage": {
"completion_tokens": 24,
"prompt_tokens": 27,
"total_tokens": 51
}
},
"request_id": "660b7424-b648-4b67-addc-862ba067d442",
"status_code": 200
},
"error": null
}
Comandos por lotes adicionales
Cancelación del lote
Cancela un lote en curso. El lote estará en estado cancelling durante un máximo de 10 minutos, antes de cambiar a cancelled, donde tendrá resultados parciales (si los hay) disponibles en el archivo de salida.
client.batches.cancel("batch_abc123") # set to your batch_id for the job you want to cancel
Enumeración de lotes
Enumeración de trabajos por lotes para un recurso de Azure OpenAI determinado.
client.batches.list()
Los métodos de lista de la biblioteca de Python están paginados.
Para enumerar todos los trabajos:
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.batches.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
Lote de lista (versión preliminar)
Use la API de REST para enumerar todos los trabajos por lotes con opciones adicionales de ordenación y filtrado.
En los ejemplos siguientes se proporciona la función generate_time_filter para facilitar la construcción del filtro. Si no desea usar esta función, el formato de la cadena de filtro tendría el aspecto created_at gt 1728860560 and status eq 'Completed'.
import requests
import json
from datetime import datetime, timedelta
from azure.identity import DefaultAzureCredential
token_credential = DefaultAzureCredential()
token = token_credential.get_token('https://cognitiveservices.azure.com/.default')
endpoint = "https://{YOUR_RESOURCE_NAME}.openai.azure.com/"
api_version = "2024-10-01-preview"
url = f"{endpoint}openai/batches"
order = "created_at asc"
time_filter = lambda: generate_time_filter("past 8 hours")
# Additional filter examples:
#time_filter = lambda: generate_time_filter("past 1 day")
#time_filter = lambda: generate_time_filter("past 3 days", status="Completed")
def generate_time_filter(time_range, status=None):
now = datetime.now()
if 'day' in time_range:
days = int(time_range.split()[1])
start_time = now - timedelta(days=days)
elif 'hour' in time_range:
hours = int(time_range.split()[1])
start_time = now - timedelta(hours=hours)
else:
raise ValueError("Invalid time range format. Use 'past X day(s)' or 'past X hour(s)'")
start_timestamp = int(start_time.timestamp())
filter_string = f"created_at gt {start_timestamp}"
if status:
filter_string += f" and status eq '{status}'"
return filter_string
filter = time_filter()
headers = {'Authorization': 'Bearer ' + token.token}
params = {
"api-version": api_version,
"$filter": filter,
"$orderby": order
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
if response.status_code == 200:
print(json.dumps(json_data, indent=2))
else:
print(f"Request failed with status code: {response.status_code}")
print(response.text)
Salida:
{
"data": [
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729011896,
"completion_window": "24h",
"created_at": 1729011128,
"error_file_id": "file-472c0626-4561-4327-9e4e-f41afbfb30e6",
"expired_at": null,
"expires_at": 1729097528,
"failed_at": null,
"finalizing_at": 1729011805,
"id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"in_progress_at": 1729011493,
"input_file_id": "file-f89384af0082485da43cb26b49dc25ce",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-62bebde8-e767-4cd3-a0a1-28b214dc8974",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
},
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729016366,
"completion_window": "24h",
"created_at": 1729015829,
"error_file_id": "file-85ae1971-9957-4511-9eb4-4cc9f708b904",
"expired_at": null,
"expires_at": 1729102229,
"failed_at": null,
"finalizing_at": 1729016272,
"id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43",
"in_progress_at": 1729016126,
"input_file_id": "file-686746fcb6bc47f495250191ffa8a28e",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-04399828-ae0b-4825-9b49-8976778918cb",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
}
],
"first_id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"has_more": false,
"last_id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43"
}
Requisitos previos
- Una suscripción a Azure (cree una cuenta gratuita).
- Un recurso de Azure OpenAI con un modelo del tipo de implementación
Global-Batchimplementado. Puede consultar la guía de creación de recursos e implementación de modelo para obtener ayuda con este proceso.
Preparación del archivo por lotes
Al igual que el ajuste, el lote global usa archivos en formato de líneas JSON (.jsonl). A continuación se muestran algunos archivos de ejemplo con diferentes tipos de contenido admitido:
Formato de entrada
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id es necesario para permitir identificar qué solicitud por lotes individual corresponde a una respuesta determinada. Las respuestas no se devolverán en orden idéntico al orden definido en el archivo por lotes .jsonl.
Debe establecerse el atributo model para que coincida con el nombre de la implementación del lote global que desea establecer como destino para las respuestas de inferencia.
Importante
El atributo model debe establecerse para que coincida con el nombre de la implementación de Batch global que desea establecer como destino para las respuestas de inferencia. El mismo nombre de implementación del modelo de Batch global debe estar presente en cada línea del archivo por lotes. Si desea tener como destino una implementación diferente, debe hacerlo en un archivo o trabajo por lotes independiente.
Para obtener el mejor rendimiento, se recomienda enviar archivos grandes para el procesamiento por lotes, en lugar de un gran número de archivos pequeños con solo unas pocas líneas en cada archivo.
Crear un archivo de entrada
En este artículo, crearemos un archivo denominado test.jsonl y copiaremos el contenido del bloque de código de entrada estándar anterior al archivo. Deberá modificar y agregar el nombre de la implementación por lotes global a cada línea del archivo.
Carga del archivo por lotes
Una vez preparado el archivo de entrada, primero debe cargar el archivo para poder iniciar un trabajo por lotes. La carga de archivos se puede realizar mediante programación o a través de Studio. En este ejemplo se usan variables de entorno en lugar de los valores de clave y punto de conexión. Si no conoce el uso de variables de entorno con Python, consulte uno de nuestros inicios rápidos en los que se explica paso a paso el proceso de configuración de las variables de entorno.
Importante
Use las claves de API con precaución. No incluya la clave de API directamente en el código ni la exponga nunca públicamente. Si está usando una clave de API, guárdela de forma segura en Azure Key Vault. Para más información sobre cómo utilizar las claves de API de forma segura en sus aplicaciones, consulte Claves de API con Azure Key Vault.
Para más información acerca de la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files?api-version=2024-10-21 \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=batch" \
-F "file=@C:\\batch\\test.jsonl;type=application/json"
El código anterior supone una ruta de acceso de archivo determinada para el archivo test.jsonl. Ajuste esta ruta de acceso de archivo según sea necesario para el sistema local.
Salida:
{
"status": "pending",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
Seguimiento del estado de la carga de archivo
Dependiendo del tamaño del archivo de carga, puede tardar algún tiempo antes de que se cargue y procese por completo. Para comprobar el estado de carga de archivos, ejecute:
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{file-id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Salida:
{
"status": "processed",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
Creación de trabajo por lotes
Una vez que el archivo se haya cargado correctamente, puede enviar el archivo para el procesamiento por lotes.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-abc123",
"endpoint": "/chat/completions",
"completion_window": "24h"
}'
Nota:
Actualmente, la ventana de finalización debe establecerse en 24 h. Si establece algún otro valor distinto de 24 h, se producirá un error en el trabajo. Los trabajos que tardan más de 24 horas seguirán ejecutándose hasta que se cancelen.
Salida:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:13:57.2491382+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:13:57.1918498+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_fe3f047a-de39-4068-9008-346795bfc1db",
"in_progress_at": null,
"input_file_id": "file-21006e70789246658b86a1fc205899a4",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
Seguimiento del progreso del trabajo por lotes
Cuando haya creado el trabajo por lotes correctamente, puede supervisar su progreso en Studio o mediante programación. Al comprobar el progreso del trabajo por lotes, se recomienda esperar al menos 60 segundos entre cada llamada de estado.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Salida:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:33:29.1619286+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:33:29.1578141+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_e0a7ee28-82c4-46a2-a3a0-c13b3c4e390b",
"in_progress_at": null,
"input_file_id": "file-c55ec4e859d54738a313d767718a2ac5",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
Aparecen los siguientes valores de estado:
| Estado | Descripción |
|---|---|
validating |
El archivo de entrada se está validando antes de que pueda comenzar el procesamiento por lotes. |
failed |
El archivo de entrada ha producido un error en el proceso de validación. |
in_progress |
El archivo de entrada se validó correctamente y el lote se está ejecutando. |
finalizing |
El lote se ha completado y los resultados se están preparando. |
completed |
El lote se ha completado y los resultados están listos. |
expired |
El lote no pudo completarse en el período de tiempo de 24 horas. |
cancelling |
El lote está siendo cancelled (puede tardar hasta 10 minutos en entrar en vigor). |
cancelled |
el lote era cancelled. |
Recuperación del archivo de salida del trabajo por lotes
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{output_file_id}/content?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" > batch_output.jsonl
Comandos por lotes adicionales
Cancelación del lote
Cancela un lote en curso. El lote estará en estado cancelling durante un máximo de 10 minutos, antes de cambiar a cancelled, donde tendrá resultados parciales (si los hay) disponibles en el archivo de salida.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}/cancel?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Enumeración de lotes
Enumere los trabajos por lotes existentes para un recurso de Azure OpenAI determinado.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
La llamada API de lista está paginada. La respuesta contiene un valor booleano has_more para indicar cuándo hay más resultados para recorrer en iteración.
Lote de lista (versión preliminar)
Use la API de REST para enumerar todos los trabajos por lotes con opciones adicionales de ordenación y filtrado.
curl "YOUR_RESOURCE_NAME.openai.azure.com/batches?api-version=2024-10-01-preview&$filter=created_at%20gt%201728773533%20and%20created_at%20lt%201729032733%20and%20status%20eq%20'Completed'&$orderby=created_at%20asc" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Para evitar el error, los espacios de URL rejected: Malformed input to a URL function se reemplazan por %20.
Límites de Batch
| Nombre del límite | Límite de valor |
|---|---|
| Número máximo de archivos por recurso | 500 |
| Tamaño máximo del archivo de entrada | 200 MB |
| Número máximo de solicitudes por archivo | 100 000 |
Cuota de lote
En la tabla se muestra el límite de cuota por lotes. Los valores de cuota para lote global se representan en términos de tokens en cola. Al enviar un archivo para procesar por lotes, se cuenta el número de tokens presentes en el archivo. Hasta que el trabajo por lotes alcance un estado de terminal, esos tokens contarán con el límite total de tokens en cola.
Lote global
| Modelo | Contrato Enterprise | Valor predeterminado | Suscripciones basadas en tarjetas de crédito mensuales | Suscripciones de MSDN | Azure for Students, pruebas gratuitas |
|---|---|---|---|---|---|
gpt-4o |
5 B | 200 M | 50 M | 90 K | N/D |
gpt-4o-mini |
15 B | 1 B | 50 M | 90 K | N/D |
gpt-4-turbo |
300 M | 80 M | 40 M | 90 K | N/D |
gpt-4 |
150 M | 30 M | 5 M | 100 000 | N/D |
gpt-35-turbo |
10 B | 1 B | 100 M | 2 M | 50 K |
o3-mini |
15 B | 1 B | 50 M | 90 K | N/D |
B = mil millones | M = millones | K = mil
Lote de zona de datos
| Modelo | Contrato Enterprise | Valor predeterminado | Suscripciones basadas en tarjetas de crédito mensuales | Suscripciones de MSDN | Azure for Students, pruebas gratuitas |
|---|---|---|---|---|---|
gpt-4o |
500 M | 30 M | 30 M | 90 K | N/D |
gpt-4o-mini |
1,5 B | 100 M | 50 M | 90 K | N/D |
Objeto Batch
| Propiedad | Tipo | Definición |
|---|---|---|
id |
string | |
object |
string | batch |
endpoint |
string | Punto de conexión de API usado por el lote |
errors |
objeto | |
input_file_id |
string | Identificador del archivo de entrada para el lote |
completion_window |
string | Período de tiempo en el que se debe procesar el lote |
status |
string | El estado actual del lote. Valores posibles: validating, failed, in_progress, finalizing, completed, expired, cancelling, cancelled. |
output_file_id |
string | Identificador del archivo que contiene las salidas de las solicitudes ejecutadas correctamente. |
error_file_id |
string | Identificador del archivo que contiene las salidas de las solicitudes con errores. |
created_at |
integer | Marca de tiempo cuando se creó este lote (en épocas Unix) |
in_progress_at |
integer | Marca de tiempo cuando este lote comenzó a avanzar (en épocas Unix) |
expires_at |
integer | Marca de tiempo cuando este lote va a expirar (en épocas Unix). |
finalizing_at |
integer | Marca de tiempo cuando este lote comenzó a finalizar (en épocas Unix). |
completed_at |
integer | Marca de tiempo cuando este lote comenzó a finalizar (en épocas Unix). |
failed_at |
integer | Marca de tiempo cuando se produce un error en este lote (en épocas Unix) |
expired_at |
integer | Marca de tiempo cuando este lote expiró (en épocas Unix). |
cancelling_at |
integer | Marca de tiempo cuando se inició este lote cancelling (en épocas Unix). |
cancelled_at |
integer | Marca de tiempo cuando este lote era cancelled (en épocas Unix). |
request_counts |
objeto | Estructura del objeto:total
entero Número total de solicitudes en el lote. completed
entero Número de solicitudes del lote que se han completado correctamente. failed
entero Número de solicitudes del lote con errores. |
metadata |
map | Conjunto de pares clave-valor que se pueden adjuntar a un objeto. Esta propiedad puede ser útil para almacenar información adicional sobre el objeto en un formato estructurado. |
Preguntas más frecuentes
¿Se pueden usar imágenes con la API por lotes?
Esta funcionalidad se limita a determinados modelos multi modales. Actualmente, solo GPT-4o admite imágenes como parte de las solicitudes por lotes. Las imágenes se pueden proporcionar como entrada a través de la dirección URL de la imagen o una representación codificada en base64 de la imagen. Actualmente no se admiten imágenes de lotes con GPT-4 Turbo.
¿Puedo usar la API por lotes con modelos ajustados?
Actualmente no se admite.
¿Puedo usar la API por lotes para insertar modelos?
Actualmente no se admite.
¿Funciona el filtrado de contenido con la implementación global por lotes?
Sí. De forma similar a otros tipos de implementación, puede crear filtros de contenido y asociarlos con el tipo de implementación global por lotes.
¿Puedo solicitar más cuota?
Sí, desde la página de cuota en el portal de AI Foundry. La asignación de cuota predeterminada se puede encontrar en el artículo sobre cuota y límites.
¿Qué ocurre si la API no completa mi solicitud dentro del período de tiempo de 24 horas?
Nuestro objetivo es procesar estas solicitudes en un plazo de 24 horas; no expiran los trabajos que tardan más tiempo. Puede cancelar el trabajo en cualquier momento. Al cancelar el trabajo, se cancela cualquier trabajo restante y se devuelve cualquier trabajo ya completado. Se le cobrará por cualquier trabajo completado.
¿Cuántas solicitudes puedo poner en cola mediante lotes?
Sin embargo, no hay ningún límite fijo en el número de solicitudes que se pueden procesar por lotes; sin embargo, dependerá de la cuota de tokens en cola. La cuota de tokens en cola incluye el número máximo de tokens de entrada que puede poner en cola cada vez.
Una vez completada la solicitud por lotes, se restablece el límite de velocidad por lotes, ya que se borran los tokens de entrada. El límite depende del número de solicitudes globales de la cola. Si la cola de la API por lotes procesa los lotes rápidamente, el límite de velocidad por lotes se restablece más rápidamente.
Solución de problemas
Un trabajo se realiza correctamente cuando status es Completed. Los trabajos correctos seguirán generando un error_file_id, pero se asociarán a un archivo vacío con cero bytes.
Cuando se produzca un error de trabajo, encontrará detalles sobre el error en la propiedad errors:
"value": [
{
"id": "batch_80f5ad38-e05b-49bf-b2d6-a799db8466da",
"completion_window": "24h",
"created_at": 1725419394,
"endpoint": "/chat/completions",
"input_file_id": "file-c2d9a7881c8a466285e6f76f6321a681",
"object": "batch",
"status": "failed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1725419955,
"error_file_id": "file-3b0f9beb-11ce-4796-bc31-d54e675f28fb",
"errors": {
"object": “list”,
"data": [
{
“code”: “empty_file”,
“message”: “The input file is empty. Please ensure that the batch contains at least one request.”
}
]
},
"expired_at": null,
"expires_at": 1725505794,
"failed_at": null,
"finalizing_at": 1725419710,
"in_progress_at": 1725419572,
"metadata": null,
"output_file_id": "file-ef12af98-dbbc-4d27-8309-2df57feed572",
"request_counts": {
"total": 10,
"completed": null,
"failed": null
},
}
Códigos de error
| Código de error | Definición |
|---|---|
invalid_json_line |
No se pudo analizar una línea (o varias) en el archivo de entrada como json válido. Asegúrese de que no haya errores tipográficos, que los corchetes de apertura y cierre sean correctos y las comillas sigan el estándar JSON y vuelva a enviar la solicitud. |
too_many_tasks |
El número de solicitudes del archivo de entrada supera el valor máximo permitido de 100 000. Asegúrese de que el total de solicitudes sea inferior a 100 000 y vuelva a enviar el trabajo. |
url_mismatch |
Una fila del archivo de entrada tiene una dirección URL que no coincide con el resto de las filas o la dirección URL especificada en el archivo de entrada no coincide con la del punto de conexión esperado. Asegúrese de que todas las direcciones URL de solicitud sean las mismas y que coincidan con la dirección URL del punto de conexión asociada a la implementación de Azure OpenAI. |
model_not_found |
No se encontró el nombre de implementación de modelo de Azure OpenAI especificado en la propiedad model del archivo de entrada.Asegúrese de que este nombre apunte a una implementación de modelo válida de Azure OpenAI. |
duplicate_custom_id |
El identificador personalizado de esta solicitud es un duplicado del identificador personalizado en otra solicitud. |
empty_batch |
Compruebe el archivo de entrada para asegurarse de que el parámetro del identificador personalizado sea único para cada solicitud del lote. |
model_mismatch |
El nombre de implementación de modelo de Azure OpenAI que se especificó en la propiedad model de esta solicitud en el archivo de entrada no coincide con el resto del archivo.Asegúrese de que todas las solicitudes del lote apunten a la misma implementación de modelo de Azure OpenAI Service en la propiedad model de la solicitud. |
invalid_request |
El esquema de la línea de entrada no es válido o la SKU de implementación no es válida. Asegúrese de que las propiedades de la solicitud en el archivo de entrada coinciden con las propiedades de entrada esperadas y que la SKU de implementación de Azure OpenAI sea globalbatch para las solicitudes de la API por lotes. |
Problemas conocidos
- Los recursos implementados con la CLI de Azure no funcionarán de forma predeterminada con el lote global de Azure OpenAI. Esto se debe a un problema por el que los recursos implementados mediante este método tienen subdominios de punto de conexión que no siguen el patrón
https://your-resource-name.openai.azure.com. Una solución alternativa para este problema es implementar un nuevo recurso de Azure OpenAI mediante uno de los otros métodos de implementación comunes que controlarán correctamente la configuración del subdominio como parte del proceso de implementación.
Consulte también
- Más información sobre los tipos de implementación de Azure OpenAI
- Más información sobre las cuotas y límites de Azure OpenAI