Azure OpenAI en los datos
Use este artículo para obtener información sobre Azure OpenAI en los datos, lo que facilita a los desarrolladores conectarse a sus datos empresariales, ingerirlos y basarse en ellos para crear copilotos personalizados (versión preliminar) rápidamente. Mejora la comprensión del usuario, acelera la finalización de tareas, mejora la eficiencia operativa y ayuda a la toma de decisiones.
¿Qué es Azure OpenAI en los datos?
Azure OpenAI en los datos le permite ejecutar modelos de IA avanzados, como GPT-35-Turbo y GPT-4, en sus propios datos empresariales sin necesidad de entrenar o ajustar los modelos. Puede chatear sobre los datos y analizarlos con mayor precisión. Puede especificar orígenes para admitir las respuestas en función de la información más reciente disponible en los orígenes de datos designados. Puede acceder a Azure OpenAI en los datos mediante una API REST, mediante el SDK o la interfaz basada en web en Azure OpenAI Studio. También puede crear una aplicación web que se conecte a los datos para habilitar una solución de chat mejorada o implementarla directamente como copiloto en Copilot Studio (versión preliminar).
Desarrollando con Azure OpenAI en los datos
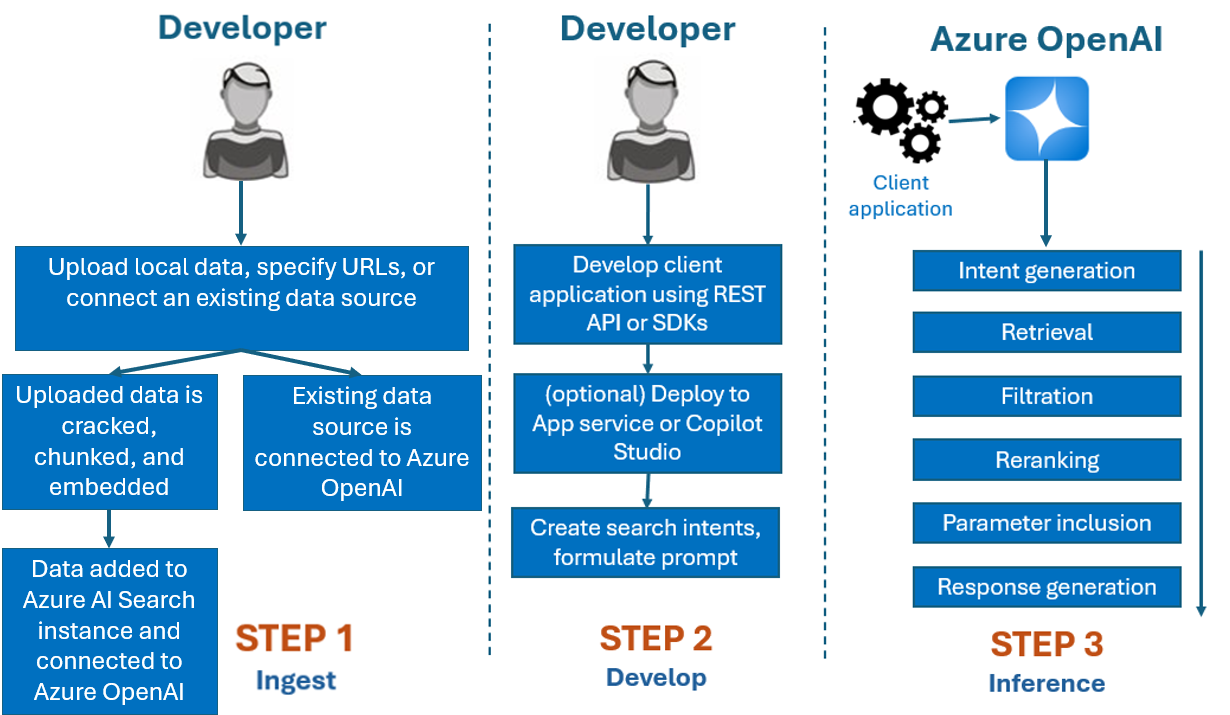
Normalmente, el proceso de desarrollo que usaría con Azure OpenAI en los datos es:
Ingesta: cargue archivos mediante Azure OpenAI Studio o la API de ingesta. Esto permite que los datos se descifren, se fragmentan y se inserten en una instancia de Búsqueda de Azure AI que se puede usar en los modelos de Azure OpenAI. Si tiene una origen de datos compatible, también puede conectarlo directamente.
Desarrollar: después de probar Azure OpenAI en los datos, empiece a desarrollar la aplicación mediante la API de REST y los SDK disponibles, que están disponibles en varios lenguajes. Creará mensajes y intenciones de búsqueda para pasar al servicio Azure OpenAI.
Inferencia: después de implementar la aplicación en su entorno preferido, enviará mensajes a Azure OpenAI, que realizará varios pasos antes de devolver una respuesta:
Generación de intenciones: el servicio determinará la intención del mensaje del usuario para determinar una respuesta adecuada.
Recuperación: el servicio recupera fragmentos relevantes de datos disponibles de la fuente de datos conectada mediante una consulta. Por ejemplo, mediante una búsqueda semántica o vectorial. Los parámetros, como la rigurosidad y el número de documentos que se van a recuperar se usan para influenciar la recuperación.
Filtrado y reclasificación: los resultados de búsqueda del paso de recuperación se mejoran clasificando y filtrando datos para refinar la relevancia.
Generación de respuesta: los datos resultantes se envían junto con otra información como el mensaje del sistema al modelo de lenguaje grande (LLM) y la respuesta se devuelve a la aplicación.
Para empezar, conecte su fuente de datos mediante Azure OpenAI Studio y empiece a hacer preguntas y a conversar sobre sus datos.
Controles de acceso basado en rol de Azure (Azure RBAC) para agregar orígenes de datos
Para usar Azure OpenAI en los datos en su totalidad, debe establecer uno o varios roles de RBAC de Azure. Vea Uso de Azure OpenAI en los datos de forma segura para obtener más información.
Formatos de datos y tipos de archivo
Azure OpenAI en los datos admite los siguientes tipos de archivo:
.txt.md.html.docx.pptx.pdf
Hay un límite de cargas y algunas advertencias sobre la estructura del documento y cómo podría afectar a la calidad de las respuestas del modelo:
Si va a convertir datos de un formato no admitido en un formato compatible, optimice la calidad de la respuesta del modelo asegurándose de la conversión:
- No conduce a una pérdida de datos significativa.
- No agrega ruido inesperado a los datos.
Si los archivos tienen un formato especial, como tablas y columnas, o puntos de viñetas, prepare los datos con el script de preparación de datos disponible en GitHub.
Para documentos y conjuntos de datos con texto largo, debe utilizar el script de preparación de datos disponible. El script fragmenta los datos para que las respuestas del modelo sean más precisas. Este script también admite imágenes y archivos PDF escaneados.
Orígenes de datos admitidos
Debe conectarse a un origen de datos para cargar los datos. Cuando quiera usar los datos a fin de chatear con un modelo de Azure OpenAI, estos se fragmentan en un índice de búsqueda para que se puedan encontrar los datos pertinentes en función de las consultas de usuario.
La base de datos vectorial integrada en Azure Cosmos DB for MongoDB basado en núcleo virtual admite de forma nativa la integración con Azure OpenAI en los datos.
En el caso de algunos orígenes de datos, como cargar archivos desde la máquina local (versión preliminar) o los datos contenidos en una cuenta de Blob Storage (versión preliminar), se usa Búsqueda de Azure AI. Al elegir los siguientes orígenes de datos, los datos se ingieren en un índice de Búsqueda de Azure AI.
| Datos ingeridos a través de Búsqueda de Azure AI | Descripción |
|---|---|
| Azure AI Search | Use un índice de Búsqueda de Azure AI existente con Azure OpenAI en los datos. |
| Carga de archivos (versión preliminar) | Cargue los archivos de la máquina local para almacenarlos en una base de datos de Azure Blob Storage e ingerirlos en Búsqueda de Azure AI. |
| Dirección web/URL (versión preliminar) | El contenido web de las direcciones URL se almacena en Azure Blob Storage. |
| Azure Blob Storage (versión preliminar) | Cargue archivos de Azure Blob Storage para que se ingieran en un índice de Búsqueda de Azure AI. |

- Azure AI Search
- Base de datos vectorial en Azure Cosmos DB for MongoDB
- Azure Blob Storage (versión preliminar)
- Carga de archivos (versión preliminar)
- Dirección web/URL (versión preliminar)
- Elasticsearch (versión preliminar)
- MongoDB Atlas (versión preliminar)
Es posible que quiera plantearse el uso de un índice de Búsqueda de Azure AI cuando quiera hacer lo siguiente:
- Personalizar el proceso de creación del índice.
- Volver a usar un índice creado antes ingiriendo datos de otros orígenes de datos.
Nota:
- Para usar un índice existente, debe tener al menos un campo que se pueda buscar.
- Establezca la opción CORS Permitir tipo de origen en
ally la opción Permitir orígenes en*.
Tipos de búsqueda
Azure OpenAI en los datos proporciona varias los tipos de búsqueda siguientes que puede usar al agregar el origen de datos.
Vector de búsqueda mediante modelos de inserción de Ada, disponibles en regiones seleccionadas.
Para habilitar el vector de búsqueda, necesita un modelo de inserción existente implementado en el recurso de Azure OpenAI. Seleccione la implementación de inserción al conectar los datos y, a continuación, seleccione uno de los tipos de vector de búsqueda en Administración de datos. Si usa Búsqueda de Azure AI como origen de datos, asegúrese de que tiene una columna vectorial en el índice.
Si usa su propio índice, puede personalizar la asignación de campos al agregar el origen de datos para definir los campos que se asignarán al responder preguntas. Para personalizar la asignación de campos, seleccione Usar la asignación de campos personalizada en la página Origen de datos al agregar el origen de datos.
Importante
- La búsqueda semántica está sujeta a precios adicionales. Debe elegir SKU Básico o superior para habilitar la búsqueda semántica o la búsqueda vectorial. Para más información, vea diferencias de planes de tarifa y límites de servicio.
- Para ayudar a mejorar la calidad de la recuperación de la información y la respuesta del modelo, se recomienda habilitar la búsqueda semántica para los siguientes idiomas de origen de los datos: inglés, francés, español, portugués, italiano, alemán, chino (Zh), japonés, coreano, ruso, y árabe.
| Opción de búsqueda | Tipo de recuperación | ¿Precios adicionales? | Ventajas |
|---|---|---|---|
| keyword | Búsqueda de palabra clave | No hay precios adicionales. | Realiza un análisis rápido y flexible de consultas y coincidencias en los campos que se pueden buscar, mediante términos o frases en cualquier lenguaje admitido, con o sin operadores. |
| semantic | Búsqueda semántica | Precios adicionales para el uso de búsqueda semántica. | Mejora la precisión y relevancia de los resultados de búsqueda mediante un reequilino (con modelos de IA) para comprender el significado semántico de los términos de consulta y los documentos devueltos por el clasificador de búsqueda inicial |
| vector | Búsqueda de vectores | Precios adicionales en la cuenta de Azure OpenAI desde la llamada al modelo de inserción. | Permite buscar documentos similares a una entrada de consulta determinada en función de las incrustaciones vectoriales del contenido. |
| híbrido (vector + palabra clave) | Un híbrido de vector de búsqueda y una búsqueda de palabra clave | Precios adicionales en la cuenta de Azure OpenAI desde la llamada al modelo de inserción. | Realiza una búsqueda de similitud sobre los campos vectoriales mediante incrustaciones vectoriales, al mismo tiempo que admite el análisis flexible de consultas y la búsqueda de texto completo sobre campos alfanuméricos mediante consultas de términos. |
| híbrido (vector + palabra clave) + semántico | Un híbrido de vector de búsqueda, búsqueda semántica y de búsqueda de palabras clave. | Precios adicionales en la cuenta de Azure OpenAI para llamar al modelo de inserción y precios adicionales para el uso de búsqueda semántica. | Usa las inserciones de vectores, la comprensión del lenguaje y el análisis flexible de consultas para crear experiencias de búsqueda enriquecidas y aplicaciones de IA generativas que pueden controlar escenarios complejos y diversos de recuperación de información. |
Búsqueda inteligente
Azure OpenAI en los datos tiene habilitada la búsqueda inteligente para los datos. La búsqueda semántica está habilitada de manera predeterminada si tiene búsqueda semántica y búsqueda de palabras clave. Si ha incrustado modelos, la búsqueda inteligente tiene como valor predeterminado la búsqueda híbrida y semántica.
Control de acceso de nivel de documento
Nota:
El control de acceso de nivel de documento se admite al seleccionar Búsqueda de Azure AI como origen de datos.
Azure OpenAI en los datos le permite restringir los documentos que se pueden usar en respuestas para distintos usuarios con filtros de seguridad de Búsqueda de Azure AI. Al habilitar el acceso a nivel de documento, los resultados de búsqueda devueltos por Búsqueda de Azure AI y utilizados para generar una respuesta se recortan en función de la pertenencia al grupo Microsoft Entra del usuario. Solo puede habilitar el acceso de nivel de documento en índices existentes de Búsqueda de Azure AI. Vea Uso de Azure OpenAI en los datos de forma segura para obtener más información.
Asignación de campos de índice
Si usa su propio índice, se le pedirá en Azure OpenAI Studio que defina qué campos desea asignar para responder preguntas al agregar el origen de datos. Puede proporcionar varios campos para los Datos de contenido y debe incluir todos los campos que tengan texto relacionado con el caso de uso.

En este ejemplo, los campos asignados a los Datos de contenido y Título proporcionan información al modelo para responder a preguntas. ElTítulo también se usa para el título del texto de cita. El campo asignado a Nombre de archivo genera los nombres de cita en la respuesta.
La asignación de estos campos ayuda a garantizar que el modelo tenga una mejor respuesta y calidad de cita. Además, puede configurarlo en la API mediante el parámetro fieldsMapping.
Filtro de búsqueda (API)
Si desea implementar criterios adicionales basados en valores para la ejecución de consultas, puede configurar un filtro de búsqueda mediante el parámetro filter en la API de REST.
Cómo se ingieren los datos en Búsqueda de Azure AI
A partir de septiembre de 2024, las API de ingesta cambiaron a la vectorización integrada. Esta actualización no modifica los contratos de API existentes. La vectorización integrada, una nueva oferta de Azure AI Search, usa aptitudes precompiladas para fragmentar e insertar los datos de entrada. Azure OpenAI en el servicio de ingesta de datos ya no emplea aptitudes personalizadas. Después de la migración a la vectorización integrada, el proceso de ingesta ha sufrido algunas modificaciones y, como resultado, solo se crean los siguientes recursos:
{job-id}-index{job-id}-indexer, si se especifica una programación diaria o por hora, de lo contrario, el indexador se limpia al final del proceso de ingesta.{job-id}-datasource
El contenedor de fragmentos ya no está disponible, ya que esta funcionalidad ahora está administrada inherentemente por Azure AI Search.
Conexión de datos
Debe seleccionar cómo desea autenticar la conexión desde Azure OpenAI, Azure AI Search y Azure Blob Storage. Puede elegir una Identidad administrada asignada por el sistema o una Clave de API. Al seleccionar la Clave de API como tipo de autenticación, el sistema rellenará automáticamente la clave de API para que se conecte con los recursos de Azure AI Search, Azure OpenAI y Azure Blob Storage. Al seleccionar identidad administrada asignada por el sistema, la autenticación se basará en la asignación de roles tiene. La identidad administrada asignada por el sistema está seleccionada de forma predeterminada para la seguridad.

Una vez que seleccione el botón siguiente, validará automáticamente la configuración para usar el método de autenticación seleccionado. Si se produce un error, consulte el artículo asignaciones de roles para actualizar la configuración.
Una vez que haya corregido la configuración, seleccione siguiente de nuevo para validar y continuar. Los usuarios de api también pueden configurar la autenticación con claves de API y identidad administrada asignadas.









Implementación en un copilot (versión preliminar), aplicación de Teams (versión preliminar) o aplicación web
Después de conectar Azure OpenAI a los datos, puede implementarlo mediante el botón Implementar en Azure OpenAI Studio.

Esto proporciona varias opciones para implementar la solución.
Puede implementar en un copilot en Copilot Studio (versión preliminar) directamente desde Azure OpenAI Studio, lo que le permite llevar experiencias conversacionales a varios canales, como Microsoft Teams, sitios web, Dynamics 365 y otros canales de Azure Bot Service. El inquilino que se usa en el servicio de Azure OpenAI y Copilot Studio (versión preliminar) debe ser el mismo. Para obtener más información, vea Uso de una conexión a Azure OpenAI en los datos.
Nota:
La implementación en un copiloto en Copilot Studio (versión preliminar) solo está disponible en regiones de EE. UU.
Uso de Azure OpenAI en los datos de forma segura
Puede usar Azure OpenAI en sus datos de forma segura mediante la protección de datos y recursos con el control de acceso basado en roles, redes virtuales y puntos de conexión privados de Microsoft Entra ID. También puede restringir los documentos que se pueden usar en respuestas para distintos usuarios con filtros de seguridad de Búsqueda de Azure AI. Vea Uso seguro de Azure OpenAI en los datos.
procedimientos recomendados
Use las secciones siguientes para obtener información sobre cómo mejorar la calidad de las respuestas que da el modelo.
Parámetro de ingesta
Cuando los datos se ingieren en la Búsqueda de Azure AI, puede modificar la siguiente configuración adicional en Studio o en la API de ingesta.
Tamaño del fragmento (versión preliminar)
Azure OpenAI en los datos procesa los documentos mediante su división en fragmentos antes de indexarlos. El tamaño del fragmento es el tamaño máximo en términos del número de tokens de cualquier fragmento del índice de búsqueda. El tamaño del fragmento y el número de documentos recuperados juntos controlan la cantidad de información (tokens) que se incluye en la solicitud enviada al modelo. En general, el tamaño del fragmento multiplicado por el número de documentos recuperados es el número total de tokens enviados al modelo.
Establecimiento del tamaño del fragmento para el caso de uso
El tamaño de fragmento predeterminado es de 1024 tokens. Sin embargo, dada la unicidad de los datos, es posible que encuentre un tamaño de fragmento diferente (por ejemplo, 256, 512 o 1536 tokens) más efectivo.
Ajustar el tamaño del fragmento puede mejorar el rendimiento del bot de chat. Aunque encontrar el tamaño óptimo del fragmento requiere algo de prueba y error, para empezar considere la naturaleza del conjunto de datos. Por lo general, un tamaño de fragmento más pequeño es mejor para conjuntos de datos con hechos directos y menos contexto, mientras que un tamaño de fragmento mayor podría ser beneficioso para obtener información más contextual, aunque podría afectar al rendimiento de la recuperación.
Un tamaño de fragmento pequeño, como 256, genera fragmentos más granulares. Este tamaño también significa que el modelo usará menos tokens para generar su salida (a menos que el número de documentos recuperados sea muy alto), lo que podría costar menos. Los fragmentos más pequeños también significan que el modelo no tiene que procesar e interpretar secciones largas de texto, lo que reduce el ruido y la distracción. Sin embargo, esta granularidad y enfoque suponen un posible problema. Es posible que la información importante no esté entre los fragmentos recuperados principales, especialmente si el número de documentos recuperados está establecido en un valor bajo como 3.
Sugerencia
Tenga en cuenta que modificar el tamaño del fragmento requiere que los documentos se vuelvan a ingerir, por lo que es útil ajustar primero los parámetros en runtime, como la rigurosidad y el número de documentos recuperados. Considere la posibilidad de cambiar el tamaño del fragmento si sigue sin obtener los resultados deseados:
- Si encuentra un gran número de respuestas como "No sé" para preguntas con respuestas que deben estar en los documentos, considere la posibilidad de reducir el tamaño del fragmento a 256 o 512 para mejorar la granularidad.
- Si el bot de chat proporciona algunos detalles correctos pero faltan otros, lo que se vuelve evidente en las citas, aumentar el tamaño del fragmento a 1536 podría ayudar a capturar más información contextual.
Parámetros en tiempo de ejecución
Puede modificar la siguiente configuración adicional en la sección Parámetros de datos en Azure OpenAI Studio y la API. No es necesario volver a ingerir los datos al actualizar estos parámetros.
| Nombre de parámetro | Descripción |
|---|---|
| Limitar las respuestas a los datos | Esta marca configura el enfoque del bot de chat para controlar consultas no relacionadas con el origen de datos o cuando los documentos de búsqueda no son suficientes para obtener una respuesta completa. Cuando este valor está deshabilitado, el modelo complementa sus respuestas con su propio conocimiento además de los documentos. Cuando este valor está habilitado, el modelo intenta confiar solo en los documentos para obtener las respuestas. Este es el parámetro inScope de la API y se establece en true de forma predeterminada. |
| Documentos recuperados | Este parámetro es un entero que se puede establecer en 3, 5, 10 o 20 y controla el número de fragmentos del documento proporcionados al modelo de lenguaje grande para formular la respuesta final. De forma predeterminada, está establecida en 5. El proceso de búsqueda puede ser ruidoso y, a veces, debido a la fragmentación, la información relevante se puede distribuir entre varios fragmentos en el índice de búsqueda. Al seleccionar un número para los K principales (por ejemplo, 5), se garantiza que el modelo pueda extraer información relevante, a pesar de las limitaciones inherentes de la búsqueda y la fragmentación. Sin embargo, aumentar el número a uno demasiado alto puede distraer al modelo. Además, el número máximo de documentos que se pueden usar de forma eficaz depende de la versión del modelo, ya que cada uno tiene un tamaño de contexto y una capacidad diferentes para manejar documentos. Si observa que a las respuestas les falta contexto importante, pruebe a aumentar este parámetro. Este es el parámetro topNDocuments de la API y es 5 de forma predeterminada. |
| Rigurosidad | Determina la agresividad del sistema en el filtrado de los documentos de búsqueda en función de sus puntuaciones de similitud. El sistema consulta Azure Search u otros almacenes de documentos y, luego, decide qué documentos proporcionar a modelos de lenguaje grandes como ChatGPT. El filtrado de documentos irrelevantes puede mejorar significativamente el rendimiento del bot de chat de un extremo a otro. Algunos documentos se excluyen de los resultados de los K principales si tienen puntuaciones de similitud bajas antes de reenviarlos al modelo. Esto se controla mediante un valor entero comprendido entre 1 y 5. Establecer este valor en 1 significa que el sistema filtrará mínimamente los documentos en función de la similitud de búsqueda con la consulta del usuario. Por el contrario, un valor de 5 indica que el sistema filtrará los documentos de forma agresiva, aplicando un umbral de similitud muy alto. Si encuentra que el bot de chat omite información relevante, reduzca la rigidez del filtro (establezca el valor más cercano a 1) para incluir más documentos. Y a la inversa, si los documentos irrelevantes distraen las respuestas, aumente el umbral (establezca el valor más cerca de 5). Este es el parámetro strictness de la API y se establece en 3 de forma predeterminada. |
Referencias no citadas
Es posible que el modelo devuelva "TYPE":"UNCITED_REFERENCE" en lugar de "TYPE":CONTENT en la API para los documentos que se recuperan del origen de datos, pero que no se incluyen en la cita. Esto puede ser útil para la depuración y puede controlar este comportamiento modificando la rigurosidad y los parámetros en runtime de documentos recuperados descritos anteriormente.
Mensaje del sistema
Puede definir un mensaje del sistema para dirigir la respuesta del modelo al usar Azure OpenAI en los datos. Este mensaje le permite personalizar las respuestas sobre el patrón de Generación aumentada de recuperación (RAG) que usa Azure OpenAI en los datos. Para proporcionar la experiencia se usa el mensaje del sistema además de una solicitud base interna. Para admitir esto, truncamos el mensaje del sistema después de un número de tokens concreto para asegurarnos de que el modelo puede responder a preguntas mediante los datos. Si va a definir un comportamiento adicional sobre la experiencia predeterminada, asegúrese de que la solicitud del sistema se detalla y explica la personalización exacta esperada.
Una vez que seleccione la incorporación del conjunto de datos, puede usar la sección Mensaje del sistema de Azure OpenAI Studio o el role_informationparámetro de la API.

Patrones de uso potenciales
Definición de un rol
Puede definir un rol que quiera para el asistente. Por ejemplo, si va a crear un bot de soporte técnico, puede agregar "Eres un asistente de soporte técnico de incidentes experto que ayuda a los usuarios a resolver nuevos problemas".
Definición del tipo de datos que se recuperan
También puede agregar la naturaleza de los datos que proporciona al asistente.
- Defina el tema o el ámbito del conjunto de datos, como "informe financiero", "artículo académico" o "informe de incidentes". Por ejemplo, para el soporte técnico, puede agregar "Respondes consultas mediante información de incidentes similares en los documentos recuperados".
- Si los datos tienen determinadas características, puede agregar estos detalles al mensaje del sistema. Por ejemplo, si los documentos están en japonés, puede agregar "Recuperas documentos en japonés, y debes leerlos cuidadosamente en japonés y responder en japonés".
- Si los documentos incluyen datos estructurados como tablas de un informe financiero, también puede agregar este hecho al símbolo del sistema. Por ejemplo, si los datos tienen tablas, puede agregar "Se te proporcionan datos en forma de tablas relacionadas con los resultados financieros y debes leer la tabla línea por línea para realizar cálculos a fin de responder a preguntas del usuario".
Definición del estilo de salida
También puede cambiar la salida del modelo definiendo un mensaje del sistema. Por ejemplo, si quiere asegurarse de que las respuestas del asistente están en francés, puede agregar un mensaje como "Usted es un asistente de IA que ayuda a los usuarios que entienden la información de búsqueda en francés. Las preguntas del usuario pueden estar en inglés o francés. Lea cuidadosamente los documentos recuperados y respóndalos en francés. Traduce los conocimientos de documentos a francés para asegurarte de que todas las respuestas están en francés".
Reafirmación del comportamiento crítico
Azure OpenAI en los datos funciona enviando instrucciones a un modelo de lenguaje de gran tamaño en forma de avisos para responder a las consultas de usuario mediante los datos. Si hay un comportamiento determinado que es fundamental para la aplicación, puede repetir el comportamiento en el mensaje del sistema a fin de aumentar su precisión. Por ejemplo, para guiar el modelo para que solo responda desde documentos, puede agregar "Responda solo mediante documentos recuperados y sin usar sus conocimientos. Genere citas a fin de recuperar documentos para cada notificación de la respuesta. Si la pregunta del usuario no se puede responder mediante documentos recuperados, explique el argumento que explique que los documentos son relevantes para las consultas del usuario. En cualquier caso, no respondas con tus propio conocimientos".
Trucos de ingeniería de solicitudes
Hay muchos trucos en la ingeniería de solicitudes que puede probar para mejorar la salida. Un ejemplo es la cadena de pensamiento que indica dónde puede agregar "Vamos a pensar con detalle la información de los documentos recuperados para responder a las consultas del usuario. Extrae conocimientos relevantes para las consultas del usuario a partir documentos paso a paso y elabora una respuesta a partir de la información extraída de los documentos pertinentes".
Nota:
El mensaje del sistema se usa para modificar cómo el asistente de GPT responde a una pregunta del usuario en función de la documentación recuperada. No afecta al proceso de recuperación. Si quiere proporcionar instrucciones para el proceso de recuperación, es mejor incluirlas en las preguntas. El mensaje del sistema solo es una guía. Es posible que el modelo no se ajuste a todas las instrucciones especificadas porque se ha preparado con ciertos comportamientos, como objetividad, y para evitar instrucciones controvertidas. Puede producirse un comportamiento inesperado si el mensaje del sistema contradice estos comportamientos.
Respuesta máxima
Establezca un límite en el número de tokens por respuesta del modelo. El límite superior de Azure OpenAI en los datos es de 1500. Esto es equivalente a establecer el parámetro max_tokens en la API.
Limitar las respuestas a los datos
Esta opción anima al modelo a responder solo con los datos y está seleccionada de manera predeterminada. Si deselecciona esta opción, el modelo podría aplicar más fácilmente sus conocimientos internos para responder. Determine la selección correcta en función del caso de uso y el escenario.
Interacción con el modelo
Use los procedimientos siguientes para obtener los mejores resultados al chatear con el modelo.
Historial de conversaciones
- Antes de iniciar una nueva conversación (o formular una pregunta que no esté relacionada con las anteriores), borre el historial del chat.
- Se pueden esperar respuestas diferentes para la misma pregunta entre el primer turno conversacional y los turnos posteriores porque el historial de conversaciones cambia el estado actual del modelo. Si recibe respuestas incorrectas, notifíquelo como un error de calidad.
Respuesta del modelo
Si no está satisfecho con la respuesta del modelo para una pregunta específica, intente hacer la pregunta más específica o más genérica para ver cómo responde el modelo y vuelva a enmarcar la pregunta en consecuencia.
Se ha demostrado que la solicitud de cadena de pensamiento es eficaz para conseguir que el modelo genere salidas deseadas para preguntas o tareas complejas.
Longitud de la pregunta
Evite formular preguntas largas y divídalas en varias preguntas si es posible. Los modelos GPT tienen límites en el número de tokens que pueden aceptar. Los límites de token se cuentan hacia: la pregunta del usuario, el mensaje del sistema, los documentos de búsqueda recuperados (fragmentos), las solicitudes internas, el historial de conversaciones (si existe) y la respuesta. Si la pregunta supera el límite de tokens, se truncará.
Compatibilidad bilingüe
Actualmente, la búsqueda de palabras clave y la búsqueda semántica en Azure OpenAI en los datos que admiten consultas están en el mismo idioma que los datos del índice. Por ejemplo, si los datos están en japonés, las consultas también deben estar en japonés. Para la recuperación de documentos entre idiomas, se recomienda compilar el índice con el vector de búsqueda habilitado.
Para ayudar a mejorar la calidad de la recuperación de la información y la respuesta del modelo, se recomienda habilitar la búsqueda semántica para los siguientes idiomas: inglés, francés, español, portugués, italiano, alemán, chino (Zh), japonés, coreano, ruso, árabe
Se recomienda usar un mensaje del sistema para informar al modelo de que los datos están en otro idioma. Por ejemplo:
*"*Es un asistente de inteligencia artificial diseñado para ayudar a los usuarios a extraer información de documentos japoneses recuperados. Examine cuidadosamente los documentos japoneses antes de formular una respuesta. La consulta del usuario estará en japonés y también debe responder en japonés".
Si tiene documentos en varios idiomas, se recomienda crear un nuevo índice para cada idioma y conectarlos por separado a Azure OpenAI.
Streaming de datos
Puede enviar una solicitud de streaming mediante el parámetro stream, lo que permite que los datos se envíen y reciban de forma incremental, sin esperar toda la respuesta de la API. Esto puede mejorar el rendimiento y la experiencia del usuario, especialmente para datos grandes o dinámicos.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Historial de conversaciones para obtener mejores resultados
Al chatear con un modelo, proporcionarle un historial de chat ayudará al modelo a devolver resultados de mayor calidad. No es necesario incluir la propiedad context de los mensajes del asistente en las solicitudes de API para mejorar la calidad de la respuesta. Consulta la documentación de referencia de la API para obtener más ejemplos.
Llamada a funciones
Algunos modelos de Azure OpenAI permiten definir herramientas y parámetros tool_choice para habilitar la llamada a funciones. Puede configurar la llamada de función a través de API de REST /chat/completions. Si tools y los orígenes de datos están en la solicitud, se aplica la siguiente directiva.
- Si
tool_choiceesnone, las herramientas se omiten y solo se usan los orígenes de datos para generar la respuesta. - De lo contrario, si
tool_choiceno se especifica o se especifica comoautoo un objeto, se omiten los orígenes de datos y la respuesta contendrá el nombre de las funciones seleccionadas y los argumentos, si los hubiera. Incluso si el modelo decide que no hay ninguna función seleccionada, los orígenes de datos todavía se omiten.
Si la directiva anterior no satisface sus necesidades, tenga en cuenta otras opciones, por ejemplo: flujo de avisos o API de asistentes.
Estimación del uso de tokens para Azure OpenAI en los datos
Azure OpenAI en la generación aumentada de recuperación de datos (RAG) es un servicio que aprovecha un servicio de búsqueda (como Azure AI Search) y la generación (modelos de Azure OpenAI) para permitir a los usuarios obtener respuestas para sus preguntas en función de los datos proporcionados.
Como parte de esta canalización RAG, hay tres pasos en un nivel alto:
Reformule la consulta del usuario en una lista de intenciones de búsqueda. Para ello, se realiza una llamada al modelo con un mensaje que incluye instrucciones, la pregunta del usuario y el historial de conversaciones. Vamos a llamar a este mensaje solicitud de intención.
Para cada intención, se recuperan varios fragmentos de documento del servicio de búsqueda. Después de filtrar fragmentos irrelevantes en función del umbral especificado por el usuario de la estricteidad y volver a activar o agregar los fragmentos en función de la lógica interna, se elige el número especificado por el usuario de fragmentos de documento.
Estos fragmentos de documento, junto con la pregunta del usuario, el historial de conversaciones, la información del rol y las instrucciones se envían al modelo para generar la respuesta final del modelo. Vamos a llamar a este mensaje de generación.
En total, hay dos llamadas realizadas al modelo:
Para procesar la intención: La estimación del token para la solicitud de intención incluye las de la pregunta del usuario, el historial de conversaciones y las instrucciones enviadas al modelo para la generación de intenciones.
Para generar la respuesta: La estimación del token de la solicitud de generación incluye las de la pregunta del usuario, el historial de conversaciones, la lista recuperada de fragmentos de documento, información de roles y las instrucciones enviadas a ella para su generación.
Los tokens de salida generados por el modelo (tanto intenciones como respuesta) deben tenerse en cuenta para la estimación total de tokens. La suma de las cuatro columnas siguientes proporciona el promedio de tokens totales usados para generar una respuesta.
| Modelo | Recuento de tokens del símbolo del sistema de generación | Recuento de tokens de solicitud de intención | Recuento de tokens de respuesta | Recuento de tokens de intención |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-Turbo-1106 | 4854 | 1372 | 110 | 26 |
Los números anteriores se basan en pruebas en un conjunto de datos con:
- 191 conversaciones
- 250 preguntas
- 10 tokens promedio por pregunta
- 4 turnos de conversación por conversación en promedio
Y los siguientes parámetros.
| Configuración | Valor |
|---|---|
| Número total de documentos recuperados | 5 |
| Rigurosidad | 3 |
| Tamaño del fragmento | 1024 |
| ¿Limitar las respuestas a los datos ingeridos? | True |
Estas estimaciones variarán en función de los valores establecidos para los parámetros anteriores. Por ejemplo, si el número de documentos recuperados se establece en 10 y la estricta se establece en 1, el recuento de tokens aumentará. Si las respuestas devueltas no están limitadas a los datos ingeridos, hay menos instrucciones dadas al modelo y el número de tokens dejará de funcionar.
Las estimaciones también dependen de la naturaleza de los documentos y las preguntas que se formulan. Por ejemplo, si las preguntas están abiertas, es probable que las respuestas sean más largas. Del mismo modo, un mensaje del sistema más largo contribuiría a un aviso más largo que consume más tokens y, si el historial de conversaciones es largo, el mensaje será más largo.
| Modelo | Número máximo de tokens para el mensaje del sistema |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
También determina el número máximo de tokens que se pueden usar para el mensaje del sistema. Para ver el número máximo de tokens para la respuesta del modelo, consulte el artículo de modelos. Además, los siguientes elementos también consumen tokens:
El meta aviso: Si limita las respuestas del modelo al contenido de los datos de base (
inScope=Trueen la API), el número máximo de tokens será mayor. De lo contrario (por ejemplo, siinScope=False) el máximo es menor. Este número varía en función de la longitud de los tokens del historial de preguntas y conversaciones del usuario. Esta estimación incluye el aviso base y los avisos de reescritura de consultas para la recuperación.Pregunta del usuario e historial: variable pero limitado a 2000 tokens.
Documentos recuperados (fragmentos): el número de tokens utilizados por los fragmentos de documento recuperados depende de varios factores. El límite superior es el número de fragmentos de documentos recuperados multiplicados por el tamaño del fragmento. Sin embargo, se truncará en función de los tokens disponibles para el modelo específico que se utilice tras contar el resto de campos.
El 20 % de los tokens disponibles están reservados para la respuesta del modelo. El 80 % restante de los tokens disponibles incluye el meta aviso, el historial de preguntas y conversaciones del usuario, y el mensaje del sistema. Los fragmentos de documentos recuperados usan el presupuesto del token restante.
Para calcular el número de tokens consumidos por la entrada (como la pregunta, la información del mensaje o rol del sistema), use el ejemplo de código siguiente.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Solución de problemas
Para solucionar problemas de operaciones con errores, busque siempre errores o advertencias especificados en la respuesta de la API o Azure OpenAI Studio. Estos son algunos de los errores y advertencias más comunes:
Error en los trabajos de ingesta
Problemas de limitación de cuotas
No se pudo crear un índice con el nombre X en el servicio Y. Se ha superado la cuota de índice para este servicio. Primero debe eliminar los índices no utilizados, agregar un retardo entre las solicitudes de creación de índices o actualizar el servicio para obtener límites superiores.
Se ha superado la cuota estándar del indexador de X para este servicio. Actualmente dispone de X indexadores estándar. Primero debe eliminar los indexadores no utilizados, cambiar el "executionMode" del indexador o actualizar el servicio para obtener límites superiores.
Resolución:
Actualice a un nivel de precios superior o elimine los activos sin usar.
Problemas con el tiempo de espera del preprocesamiento
No se pudo ejecutar la aptitud porque se produjo un error en la solicitud de API web
No se pudo ejecutar la aptitud porque la respuesta de aptitudes de API web no es válida
Resolución:
Divida los documentos de entrada en documentos más pequeños y vuelva a intentarlo.
Problemas de permisos
Esta solicitud no está autorizado para realizar esta operación
Resolución:
Esto significa que la cuenta de almacenamiento no es accesible con las credenciales dadas. En este caso, revise las credenciales de la cuenta de almacenamiento pasadas a la API y asegúrese de que la cuenta de almacenamiento no está oculta tras un punto de conexión privado (si no se ha configurado un punto de conexión privado para este recurso).
Errores 503 al enviar consultas con Búsqueda de Azure AI
Cada mensaje de usuario puede traducirse a varias consultas de búsqueda, y todas se envían al recurso de búsqueda en paralelo. Esto puede producir un comportamiento de limitación cuando el número de réplicas de búsqueda y particiones es bajo. Es posible que el número máximo de consultas por segundo que puede admitir una sola partición y una sola réplica no sea suficiente. En este caso, considere la posibilidad de aumentar las réplicas y las particiones o agregar lógica de suspensión o reintento en la aplicación. Consulte la Documentación de Búsqueda de Azure AI para obtener más información.
Disponibilidad regional y compatibilidad con el modelo
| Region | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Este de Australia | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Este de Canadá | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Este de EE. UU. | ✅ | ✅ | ✅ | |||||
| Este de EE. UU. 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Centro de Francia | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Japón Oriental | ✅ | |||||||
| Centro-Norte de EE. UU | ✅ | ✅ | ✅ | |||||
| Este de Noruega | ✅ | ✅ | ||||||
| Centro-sur de EE. UU. | ✅ | ✅ | ||||||
| Sur de la India | ✅ | ✅ | ||||||
| Centro de Suecia | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Norte de Suiza | ✅ | ✅ | ✅ | |||||
| Sur de Reino Unido | ✅ | ✅ | ✅ | ✅ | ||||
| Oeste de EE. UU. | ✅ | ✅ | ✅ |
**Se trata de una implementación de solo texto
Si el recurso Azure OpenAI se encuentra en otra región, no podrá usar Azure OpenAI en los datos.