Inicio rápido: Introducción al uso de la generación de audio de Azure OpenAI
Los modelos gpt-4o-audio-preview y /chat/completions introducen la modalidad de audio en la API de gpt-4o-mini-audio-preview existente. El modelo de audio amplía el potencial de las aplicaciones de inteligencia artificial en interacciones basadas en texto y voz y análisis de audio. Las modalidades admitidas en los modelos gpt-4o-audio-preview y gpt-4o-mini-audio-preview incluyen: texto, audio y texto + audio.
Esta es una tabla de las modalidades admitidas con casos de uso de ejemplo:
| Entrada de modalidad | Salida de modalidad | Ejemplo de caso de uso |
|---|---|---|
| Texto | Texto + audio | Texto a voz, generación de audiolibros |
| Audio | Texto + audio | Transcripción de audio, generación de audiolibros |
| Audio | Texto | Transcripción de audio: |
| Texto + audio | Texto + audio | Generación de audiolibros |
| Texto + audio | Texto | Transcripción de audio: |
Mediante el uso de funcionalidades de generación de audio, puede lograr aplicaciones de inteligencia artificial más dinámicas e interactivas. Los modelos que admiten entradas y salidas de audio permiten generar respuestas de audio habladas a indicaciones y usar entradas de audio para hacer solicitudes al modelo.
Modelos admitidos
Actualmente solo la versión gpt-4o-audio-preview y gpt-4o-mini-audio-preview: 2024-12-17 admite la generación de audio.
Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
Actualmente se admiten las siguientes voces para el audio: Alloy, Echo, and Shimmer.
El tamaño máximo de archivo de audio es de 20 MB.
Nota:
La API de tiempo real usa el mismo modelo de audio GPT-4o subyacente que la API de finalizaciones, pero está optimizada para interacciones de audio en tiempo real y de baja latencia.
Compatibilidad con API
La compatibilidad con finalizaciones de audio se agregó por primera vez en la versión de API 2025-01-01-preview.
Implementación de un modelo para la generación de audio
Para implementar el modelo de gpt-4o-mini-audio-preview en el portal de Azure AI Foundry:
- Vaya a la página Azure OpenAI Service en el portal de Azure AI Foundry. Asegúrese de que ha iniciado sesión con la suscripción de Azure que tiene el recurso de Azure OpenAI Service y el modelo
gpt-4o-mini-audio-previewimplementado. - Seleccione el área de juegos de Chat en Áreas de juegos en el panel izquierdo.
- Seleccione + Crear nueva implementación>Desde modelos base para abrir la ventana de implementación.
- Busque y seleccione el modelo de
gpt-4o-mini-audio-previewy, a continuación, seleccione Implementar en el recurso seleccionado. - En el asistente para la implementación, seleccione la versión del modelo
2024-12-17. - Siga el asistente para finalizar la implementación del modelo.
Ahora que tiene una implementación del modelo de gpt-4o-mini-audio-preview, puede interactuar con él en el Portal de la Fundición de IA de Azure, el área de juegos de Chat o la API de finalizaciones de chat.
Uso de la generación de audio de GPT-4o
Para chatear con el modelo de gpt-4o-mini-audio-preview implementado en el área de juegos de Chat de Portal de la Fundición de IA de Azure, siga estos pasos:
Vaya a la página Azure OpenAI Service en el portal de Azure AI Foundry. Asegúrese de que ha iniciado sesión con la suscripción de Azure que tiene el recurso de Azure OpenAI Service y el modelo
gpt-4o-mini-audio-previewimplementado.Seleccione el área de juegos de Chat en Área de juegos de recursos en el panel izquierdo.
Seleccione el modelo de
gpt-4o-mini-audio-previewimplementado en la lista desplegable Implementación.Comience a chatear con el modelo y escuche las respuestas de audio.
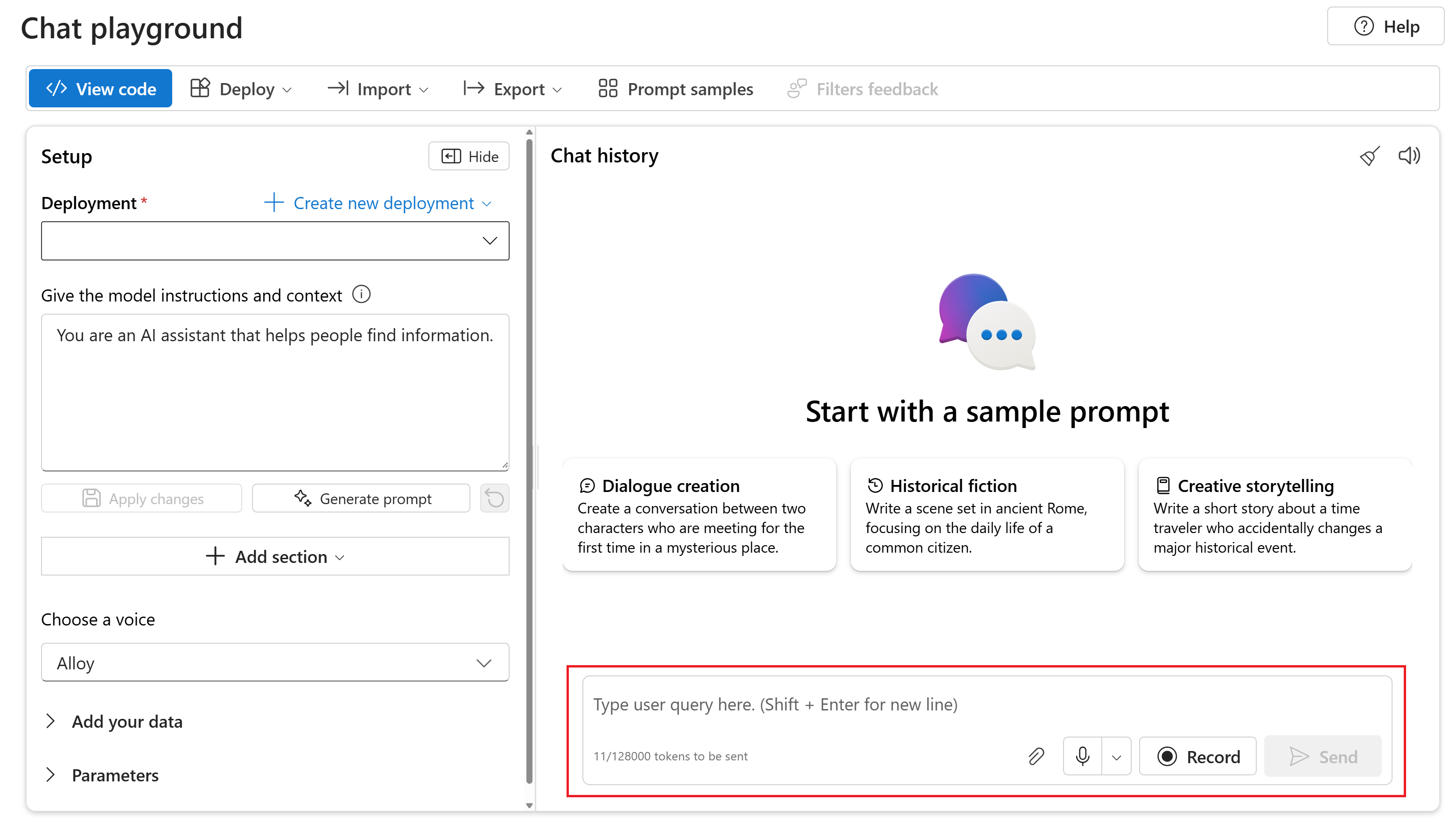
Puede:
- Grabe mensajes de audio.
- Adjunte archivos de audio al chat.
- Escriba indicaciones de texto.

Documentación de referencia | Código fuente de la biblioteca | Paquete (npm) | Ejemplos
Los modelos gpt-4o-audio-preview y /chat/completions introducen la modalidad de audio en la API de gpt-4o-mini-audio-preview existente. El modelo de audio amplía el potencial de las aplicaciones de inteligencia artificial en interacciones basadas en texto y voz y análisis de audio. Las modalidades admitidas en los modelos gpt-4o-audio-preview y gpt-4o-mini-audio-preview incluyen: texto, audio y texto + audio.
Esta es una tabla de las modalidades admitidas con casos de uso de ejemplo:
| Entrada de modalidad | Salida de modalidad | Ejemplo de caso de uso |
|---|---|---|
| Texto | Texto + audio | Texto a voz, generación de audiolibros |
| Audio | Texto + audio | Transcripción de audio, generación de audiolibros |
| Audio | Texto | Transcripción de audio: |
| Texto + audio | Texto + audio | Generación de audiolibros |
| Texto + audio | Texto | Transcripción de audio: |
Mediante el uso de funcionalidades de generación de audio, puede lograr aplicaciones de inteligencia artificial más dinámicas e interactivas. Los modelos que admiten entradas y salidas de audio permiten generar respuestas de audio habladas a indicaciones y usar entradas de audio para hacer solicitudes al modelo.
Modelos admitidos
Actualmente solo la versión gpt-4o-audio-preview y gpt-4o-mini-audio-preview: 2024-12-17 admite la generación de audio.
Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
Actualmente se admiten las siguientes voces para el audio: Alloy, Echo, and Shimmer.
El tamaño máximo de archivo de audio es de 20 MB.
Nota:
La API de tiempo real usa el mismo modelo de audio GPT-4o subyacente que la API de finalizaciones, pero está optimizada para interacciones de audio en tiempo real y de baja latencia.
Compatibilidad con API
La compatibilidad con finalizaciones de audio se agregó por primera vez en la versión de API 2025-01-01-preview.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
- Soporte para Node.js LTS o ESM.
- Un recurso de Azure OpenAI creado en una de las regiones admitidas. Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
- A continuación, debe implementar un modelo de
gpt-4o-mini-audio-previewcon el recurso de Azure OpenAI. Para obtener más información, consulte Creación de un recurso e implementación de un modelo con Azure OpenAI.
Requisitos previos de Microsoft Entra ID
Para la autenticación sin clave recomendada con Microsoft Entra ID, debe hacer lo siguiente:
- Instale la CLI de Azure utilizada para la autenticación sin clave con Microsoft Entra ID.
- Asignar el rol
Cognitive Services Usera su cuenta de usuario. Puede asignar roles en Azure Portal en Control de acceso (IAM)>Agregar asignación de roles.
Configurar
Cree una nueva carpeta
audio-completions-quickstartpara que contenga la aplicación y abra Visual Studio Code en esa carpeta con el siguiente comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCree el
package.jsoncon el comando siguiente:npm init -yActualice el
package.jsona ECMAScript con el siguiente comando:npm pkg set type=moduleInstale la biblioteca cliente de OpenAI para JavaScript con:
npm install openaiPara la autenticación sin clave recomendada con Microsoft Entra ID, instale el paquete
@azure/identitycon:npm install @azure/identity
Recuperación de información de recursos
Debe recuperar la siguiente información para autenticar la aplicación con el recurso de Azure OpenAI:
| Nombre de la variable | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Este valor se puede encontrar en la sección Claves y punto de conexión al examinar su recurso en Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Este valor corresponderá al nombre personalizado que eligió para la implementación al implementar un modelo. Este valor se puede encontrar en Administración de recursos>Implementaciones de modelos en Azure Portal. |
OPENAI_API_VERSION |
Obtenga más información sobre las versiones de API. |
Obtenga más información sobre la autenticación sin claves y la configuración de variables de entorno.
Precaución
Para usar la autenticación sin clave recomendada con el SDK, asegúrese de que la variable de entorno AZURE_OPENAI_API_KEY no esté establecida.
Generar audio a partir de la entrada de texto
Cree el archivo
to-audio.jscon el código siguiente:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Inicie sesión en Azure con el siguiente comando:
az loginEjecute el archivo JavaScript.
node to-audio.js
Espere unos instantes para obtener la respuesta.
Salida para generar audio a partir de la entrada de texto
El script genera un archivo de audio denominado dog.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta: "¿Un golden retriever es un buen perro familiar?"
Generar audio y texto a partir de la entrada de audio
Cree el archivo
from-audio.jscon el código siguiente:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Inicie sesión en Azure con el siguiente comando:
az loginEjecute el archivo JavaScript.
node from-audio.js
Espere unos instantes para obtener la respuesta.
Salida para generar audio y texto a partir de la entrada de audio
El script genera una transcripción del resumen de la entrada de audio hablado. También genera un archivo de audio denominado analysis.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta.
Generar audio y usar finalizaciones de chat de varios turnos
Cree el archivo
multi-turn.jscon el código siguiente:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Inicie sesión en Azure con el siguiente comando:
az loginEjecute el archivo JavaScript.
node multi-turn.js
Espere unos instantes para obtener la respuesta.
Salida para finalizaciones de chat de varios turnos
El script genera una transcripción del resumen de la entrada de audio hablado. A continuación, realiza una finalización de chat de varios turnos para resumir brevemente la entrada de audio hablada.
Código fuente de la biblioteca | Paquete | Ejemplos
Los modelos gpt-4o-audio-preview y /chat/completions introducen la modalidad de audio en la API de gpt-4o-mini-audio-preview existente. El modelo de audio amplía el potencial de las aplicaciones de inteligencia artificial en interacciones basadas en texto y voz y análisis de audio. Las modalidades admitidas en los modelos gpt-4o-audio-preview y gpt-4o-mini-audio-preview incluyen: texto, audio y texto + audio.
Esta es una tabla de las modalidades admitidas con casos de uso de ejemplo:
| Entrada de modalidad | Salida de modalidad | Ejemplo de caso de uso |
|---|---|---|
| Texto | Texto + audio | Texto a voz, generación de audiolibros |
| Audio | Texto + audio | Transcripción de audio, generación de audiolibros |
| Audio | Texto | Transcripción de audio: |
| Texto + audio | Texto + audio | Generación de audiolibros |
| Texto + audio | Texto | Transcripción de audio: |
Mediante el uso de funcionalidades de generación de audio, puede lograr aplicaciones de inteligencia artificial más dinámicas e interactivas. Los modelos que admiten entradas y salidas de audio permiten generar respuestas de audio habladas a indicaciones y usar entradas de audio para hacer solicitudes al modelo.
Modelos admitidos
Actualmente solo la versión gpt-4o-audio-preview y gpt-4o-mini-audio-preview: 2024-12-17 admite la generación de audio.
Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
Actualmente se admiten las siguientes voces para el audio: Alloy, Echo, and Shimmer.
El tamaño máximo de archivo de audio es de 20 MB.
Nota:
La API de tiempo real usa el mismo modelo de audio GPT-4o subyacente que la API de finalizaciones, pero está optimizada para interacciones de audio en tiempo real y de baja latencia.
Compatibilidad con API
La compatibilidad con finalizaciones de audio se agregó por primera vez en la versión de API 2025-01-01-preview.
Use esta guía para empezar a generar audio con el SDK de Azure OpenAI para Python.
Requisitos previos
- Suscripción a Azure. cree una de forma gratuita.
- Python 3.8 o una versión posterior. Se recomienda usar Python 3.10 o posterior, pero se requiere al menos Python 3.8. Si no tiene instalada una versión adecuada de Python, puede seguir las instrucciones del Tutorial de Python de VS Code para la manera más fácil de instalar Python en el sistema operativo.
- Un recurso de Azure OpenAI creado en una de las regiones admitidas. Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
- A continuación, debe implementar un modelo de
gpt-4o-mini-audio-previewcon el recurso de Azure OpenAI. Para obtener más información, consulte Creación de un recurso e implementación de un modelo con Azure OpenAI.
Requisitos previos de Microsoft Entra ID
Para la autenticación sin clave recomendada con Microsoft Entra ID, debe hacer lo siguiente:
- Instale la CLI de Azure utilizada para la autenticación sin clave con Microsoft Entra ID.
- Asignar el rol
Cognitive Services Usera su cuenta de usuario. Puede asignar roles en Azure Portal en Control de acceso (IAM)>Agregar asignación de roles.
Configurar
Cree una nueva carpeta
audio-completions-quickstartpara que contenga la aplicación y abra Visual Studio Code en esa carpeta con el siguiente comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCree un entorno virtual. Si ya tiene Instalado Python 3.10 o superior, puede crear un entorno virtual con los siguientes comandos:
La activación del entorno de Python significa que, al ejecutar
pythonopipdesde la línea de comandos, se usa el intérprete de Python incluido en la carpeta.venvde la aplicación. Puede usar el comandodeactivatepara salir del entorno virtual de Python y, posteriormente, volver a activarlo cuando sea necesario.Sugerencia
Se recomienda crear y activar un nuevo entorno de Python para instalar los paquetes que necesita para este tutorial. No instale paquetes en la instalación global de Python. Siempre debe usar un entorno virtual o conda al instalar paquetes de Python; de lo contrario, puede interrumpir la instalación global de Python.
Instale la biblioteca cliente de OpenAI para Python con:
pip install openaiPara la autenticación sin clave recomendada con Microsoft Entra ID, instale el paquete
azure-identitycon:pip install azure-identity
Recuperación de información de recursos
Debe recuperar la siguiente información para autenticar la aplicación con el recurso de Azure OpenAI:
| Nombre de la variable | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Este valor se puede encontrar en la sección Claves y punto de conexión al examinar su recurso en Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Este valor corresponderá al nombre personalizado que eligió para la implementación al implementar un modelo. Este valor se puede encontrar en Administración de recursos>Implementaciones de modelos en Azure Portal. |
OPENAI_API_VERSION |
Obtenga más información sobre las versiones de API. |
Obtenga más información sobre la autenticación sin claves y la configuración de variables de entorno.
Generar audio a partir de la entrada de texto
Cree el archivo
to-audio.pycon el código siguiente:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Ejecución del archivo de Python.
python to-audio.py
Espere unos instantes para obtener la respuesta.
Salida para generar audio a partir de la entrada de texto
El script genera un archivo de audio denominado dog.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta: "¿Un golden retriever es un buen perro familiar?"
Generar audio y texto a partir de la entrada de audio
Cree el archivo
from-audio.pycon el código siguiente:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Ejecución del archivo de Python.
python from-audio.py
Espere unos instantes para obtener la respuesta.
Salida para generar audio y texto a partir de la entrada de audio
El script genera una transcripción del resumen de la entrada de audio hablado. También genera un archivo de audio denominado analysis.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta.
Generar audio y usar finalizaciones de chat de varios turnos
Cree el archivo
multi-turn.pycon el código siguiente:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Ejecución del archivo de Python.
python multi-turn.py
Espere unos instantes para obtener la respuesta.
Salida para finalizaciones de chat de varios turnos
El script genera una transcripción del resumen de la entrada de audio hablado. A continuación, realiza una finalización de chat de varios turnos para resumir brevemente la entrada de audio hablada.
Especificación de la API de REST |
Los modelos gpt-4o-audio-preview y /chat/completions introducen la modalidad de audio en la API de gpt-4o-mini-audio-preview existente. El modelo de audio amplía el potencial de las aplicaciones de inteligencia artificial en interacciones basadas en texto y voz y análisis de audio. Las modalidades admitidas en los modelos gpt-4o-audio-preview y gpt-4o-mini-audio-preview incluyen: texto, audio y texto + audio.
Esta es una tabla de las modalidades admitidas con casos de uso de ejemplo:
| Entrada de modalidad | Salida de modalidad | Ejemplo de caso de uso |
|---|---|---|
| Texto | Texto + audio | Texto a voz, generación de audiolibros |
| Audio | Texto + audio | Transcripción de audio, generación de audiolibros |
| Audio | Texto | Transcripción de audio: |
| Texto + audio | Texto + audio | Generación de audiolibros |
| Texto + audio | Texto | Transcripción de audio: |
Mediante el uso de funcionalidades de generación de audio, puede lograr aplicaciones de inteligencia artificial más dinámicas e interactivas. Los modelos que admiten entradas y salidas de audio permiten generar respuestas de audio habladas a indicaciones y usar entradas de audio para hacer solicitudes al modelo.
Modelos admitidos
Actualmente solo la versión gpt-4o-audio-preview y gpt-4o-mini-audio-preview: 2024-12-17 admite la generación de audio.
Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
Actualmente se admiten las siguientes voces para el audio: Alloy, Echo, and Shimmer.
El tamaño máximo de archivo de audio es de 20 MB.
Nota:
La API de tiempo real usa el mismo modelo de audio GPT-4o subyacente que la API de finalizaciones, pero está optimizada para interacciones de audio en tiempo real y de baja latencia.
Compatibilidad con API
La compatibilidad con finalizaciones de audio se agregó por primera vez en la versión de API 2025-01-01-preview.
Requisitos previos
- Suscripción a Azure. cree una de forma gratuita.
- Python 3.8 o una versión posterior. Se recomienda usar Python 3.10 o posterior, pero se requiere al menos Python 3.8. Si no tiene instalada una versión adecuada de Python, puede seguir las instrucciones del Tutorial de Python de VS Code para la manera más fácil de instalar Python en el sistema operativo.
- Un recurso de Azure OpenAI creado en una de las regiones admitidas. Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
- A continuación, debe implementar un modelo de
gpt-4o-mini-audio-previewcon el recurso de Azure OpenAI. Para obtener más información, consulte Creación de un recurso e implementación de un modelo con Azure OpenAI.
Requisitos previos de Microsoft Entra ID
Para la autenticación sin clave recomendada con Microsoft Entra ID, debe hacer lo siguiente:
- Instale la CLI de Azure utilizada para la autenticación sin clave con Microsoft Entra ID.
- Asignar el rol
Cognitive Services Usera su cuenta de usuario. Puede asignar roles en Azure Portal en Control de acceso (IAM)>Agregar asignación de roles.
Configurar
Cree una nueva carpeta
audio-completions-quickstartpara que contenga la aplicación y abra Visual Studio Code en esa carpeta con el siguiente comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCree un entorno virtual. Si ya tiene Instalado Python 3.10 o superior, puede crear un entorno virtual con los siguientes comandos:
La activación del entorno de Python significa que, al ejecutar
pythonopipdesde la línea de comandos, se usa el intérprete de Python incluido en la carpeta.venvde la aplicación. Puede usar el comandodeactivatepara salir del entorno virtual de Python y, posteriormente, volver a activarlo cuando sea necesario.Sugerencia
Se recomienda crear y activar un nuevo entorno de Python para instalar los paquetes que necesita para este tutorial. No instale paquetes en la instalación global de Python. Siempre debe usar un entorno virtual o conda al instalar paquetes de Python; de lo contrario, puede interrumpir la instalación global de Python.
Instale la biblioteca cliente de OpenAI para Python con:
pip install openaiPara la autenticación sin clave recomendada con Microsoft Entra ID, instale el paquete
azure-identitycon:pip install azure-identity
Recuperación de información de recursos
Debe recuperar la siguiente información para autenticar la aplicación con el recurso de Azure OpenAI:
| Nombre de la variable | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Este valor se puede encontrar en la sección Claves y punto de conexión al examinar su recurso en Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Este valor corresponderá al nombre personalizado que eligió para la implementación al implementar un modelo. Este valor se puede encontrar en Administración de recursos>Implementaciones de modelos en Azure Portal. |
OPENAI_API_VERSION |
Obtenga más información sobre las versiones de API. |
Obtenga más información sobre la autenticación sin claves y la configuración de variables de entorno.
Generar audio a partir de la entrada de texto
Cree el archivo
to-audio.pycon el código siguiente:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Ejecución del archivo de Python.
python to-audio.py
Espere unos instantes para obtener la respuesta.
Salida para generar audio a partir de la entrada de texto
El script genera un archivo de audio denominado dog.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta: "¿Un golden retriever es un buen perro familiar?"
Generar audio y texto a partir de la entrada de audio
Cree el archivo
from-audio.pycon el código siguiente:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Ejecución del archivo de Python.
python from-audio.py
Espere unos instantes para obtener la respuesta.
Salida para generar audio y texto a partir de la entrada de audio
El script genera una transcripción del resumen de la entrada de audio hablado. También genera un archivo de audio denominado analysis.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta.
Generar audio y usar finalizaciones de chat de varios turnos
Cree el archivo
multi-turn.pycon el código siguiente:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-mini-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Ejecución del archivo de Python.
python multi-turn.py
Espere unos instantes para obtener la respuesta.
Salida para finalizaciones de chat de varios turnos
El script genera una transcripción del resumen de la entrada de audio hablado. A continuación, realiza una finalización de chat de varios turnos para resumir brevemente la entrada de audio hablada.
Documentación de referencia | Código fuente de la biblioteca | Paquete (npm) | Ejemplos
Los modelos gpt-4o-audio-preview y /chat/completions introducen la modalidad de audio en la API de gpt-4o-mini-audio-preview existente. El modelo de audio amplía el potencial de las aplicaciones de inteligencia artificial en interacciones basadas en texto y voz y análisis de audio. Las modalidades admitidas en los modelos gpt-4o-audio-preview y gpt-4o-mini-audio-preview incluyen: texto, audio y texto + audio.
Esta es una tabla de las modalidades admitidas con casos de uso de ejemplo:
| Entrada de modalidad | Salida de modalidad | Ejemplo de caso de uso |
|---|---|---|
| Texto | Texto + audio | Texto a voz, generación de audiolibros |
| Audio | Texto + audio | Transcripción de audio, generación de audiolibros |
| Audio | Texto | Transcripción de audio: |
| Texto + audio | Texto + audio | Generación de audiolibros |
| Texto + audio | Texto | Transcripción de audio: |
Mediante el uso de funcionalidades de generación de audio, puede lograr aplicaciones de inteligencia artificial más dinámicas e interactivas. Los modelos que admiten entradas y salidas de audio permiten generar respuestas de audio habladas a indicaciones y usar entradas de audio para hacer solicitudes al modelo.
Modelos admitidos
Actualmente solo la versión gpt-4o-audio-preview y gpt-4o-mini-audio-preview: 2024-12-17 admite la generación de audio.
Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
Actualmente se admiten las siguientes voces para el audio: Alloy, Echo, and Shimmer.
El tamaño máximo de archivo de audio es de 20 MB.
Nota:
La API de tiempo real usa el mismo modelo de audio GPT-4o subyacente que la API de finalizaciones, pero está optimizada para interacciones de audio en tiempo real y de baja latencia.
Compatibilidad con API
La compatibilidad con finalizaciones de audio se agregó por primera vez en la versión de API 2025-01-01-preview.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
- Soporte para Node.js LTS o ESM.
- TypeScript instalado globalmente.
- Un recurso de Azure OpenAI creado en una de las regiones admitidas. Para obtener más información sobre la disponibilidad de la región, consulte la documentación de modelos y versiones.
- A continuación, debe implementar un modelo de
gpt-4o-mini-audio-previewcon el recurso de Azure OpenAI. Para obtener más información, consulte Creación de un recurso e implementación de un modelo con Azure OpenAI.
Requisitos previos de Microsoft Entra ID
Para la autenticación sin clave recomendada con Microsoft Entra ID, debe hacer lo siguiente:
- Instale la CLI de Azure utilizada para la autenticación sin clave con Microsoft Entra ID.
- Asignar el rol
Cognitive Services Usera su cuenta de usuario. Puede asignar roles en Azure Portal en Control de acceso (IAM)>Agregar asignación de roles.
Configurar
Cree una nueva carpeta
audio-completions-quickstartpara que contenga la aplicación y abra Visual Studio Code en esa carpeta con el siguiente comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCree el
package.jsoncon el comando siguiente:npm init -yActualice el
package.jsona ECMAScript con el siguiente comando:npm pkg set type=moduleInstale la biblioteca cliente de OpenAI para JavaScript con:
npm install openaiPara la autenticación sin clave recomendada con Microsoft Entra ID, instale el paquete
@azure/identitycon:npm install @azure/identity
Recuperación de información de recursos
Debe recuperar la siguiente información para autenticar la aplicación con el recurso de Azure OpenAI:
| Nombre de la variable | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Este valor se puede encontrar en la sección Claves y punto de conexión al examinar su recurso en Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Este valor corresponderá al nombre personalizado que eligió para la implementación al implementar un modelo. Este valor se puede encontrar en Administración de recursos>Implementaciones de modelos en Azure Portal. |
OPENAI_API_VERSION |
Obtenga más información sobre las versiones de API. |
Obtenga más información sobre la autenticación sin claves y la configuración de variables de entorno.
Precaución
Para usar la autenticación sin clave recomendada con el SDK, asegúrese de que la variable de entorno AZURE_OPENAI_API_KEY no esté establecida.
Generar audio a partir de la entrada de texto
Cree el archivo
to-audio.tscon el código siguiente:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Cree el archivo
tsconfig.jsonpara transpilar el código TypeScript y copie el código siguiente para ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile de TypeScript a JavaScript.
tscInicie sesión en Azure con el siguiente comando:
az loginEjecute el código con el siguiente comando:
node to-audio.js
Espere unos instantes para obtener la respuesta.
Salida para generar audio a partir de la entrada de texto
El script genera un archivo de audio denominado dog.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta: "¿Un golden retriever es un buen perro familiar?"
Generar audio y texto a partir de la entrada de audio
Cree el archivo
from-audio.tscon el código siguiente:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Cree el archivo
tsconfig.jsonpara transpilar el código TypeScript y copie el código siguiente para ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile de TypeScript a JavaScript.
tscInicie sesión en Azure con el siguiente comando:
az loginEjecute el código con el siguiente comando:
node from-audio.js
Espere unos instantes para obtener la respuesta.
Salida para generar audio y texto a partir de la entrada de audio
El script genera una transcripción del resumen de la entrada de audio hablado. También genera un archivo de audio denominado analysis.wav en el mismo directorio que el script. El archivo de audio contiene la respuesta hablada para la pregunta.
Generar audio y usar finalizaciones de chat de varios turnos
Cree el archivo
multi-turn.tscon el código siguiente:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Cree el archivo
tsconfig.jsonpara transpilar el código TypeScript y copie el código siguiente para ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile de TypeScript a JavaScript.
tscInicie sesión en Azure con el siguiente comando:
az loginEjecute el código con el siguiente comando:
node multi-turn.js
Espere unos instantes para obtener la respuesta.
Salida para finalizaciones de chat de varios turnos
El script genera una transcripción del resumen de la entrada de audio hablado. A continuación, realiza una finalización de chat de varios turnos para resumir brevemente la entrada de audio hablada.
Limpieza de recursos
Si quiere limpiar y quitar un recurso de Azure OpenAI, puede eliminar el recurso. Antes de eliminar el recurso, primero deberá eliminar los modelos implementados.
Contenido relacionado
- Más información sobre los tipos de implementación de Azure OpenAI.
- Más información sobre las cuotas y límites de Azure OpenAI.