Modelo de diseño de Document Intelligence
Este contenido se aplica a: ![]() v4.0 (GA) | Versiones anteriores:
v4.0 (GA) | Versiones anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
El modelo de maquetación de Document Intelligence es una API avanzada de análisis de documentos basada en aprendizaje automático disponible en la nube de Document Intelligence. Permite tomar documentos en varios formatos y devolver sus representaciones de datos estructurados. Combina una versión mejorada de nuestras poderosas funcionalidades de reconocimiento óptico de caracteres (OCR) con modelos de aprendizaje profundo para extraer texto, tablas, marcas de selección y la estructura de los documentos.
Análisis de diseño de documentos (v4)
El análisis de la estructura y el diseño de documentos es el proceso de analizar un documento para extraer regiones de interés y sus interrelaciones. El objetivo es extraer texto y elementos estructurales de la página para crear modelos de mejor comprensión semántica. Hay dos tipos de roles en un diseño de documento:
- Roles geométricos: el texto, las tablas, las figuras y las marcas de selección son ejemplos de roles geométricos.
- Roles lógicos: los títulos, los encabezados y los pies de página son ejemplos de roles lógicos de textos.
En la ilustración siguiente se muestran los componentes típicos de una imagen de una página de ejemplo.

Opciones de desarrollo (v4)
Documento de inteligencia v4.0: 2024-11-30 (GA) es compatible con las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de diseño | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
diseño preelaborado |
Requisitos de entrada (v4)
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
Introducción al modelo de diseño
Vea cómo se extraen de los documentos los datos, incluidos el texto, las tablas, los encabezados de tabla, las marcas de selección y la información de estructura mediante Document Intelligence. Tendrá que supervisar los recursos siguientes:
Una suscripción a Azure: puede crear una cuenta gratuita.
Una instancia de Document Intelligence en el Azure Portal. Puede usar el plan de tarifa gratuito (
F0) para probar el servicio. Después de implementar el recurso, seleccione Ir al recurso para obtener la clave y el punto de conexión.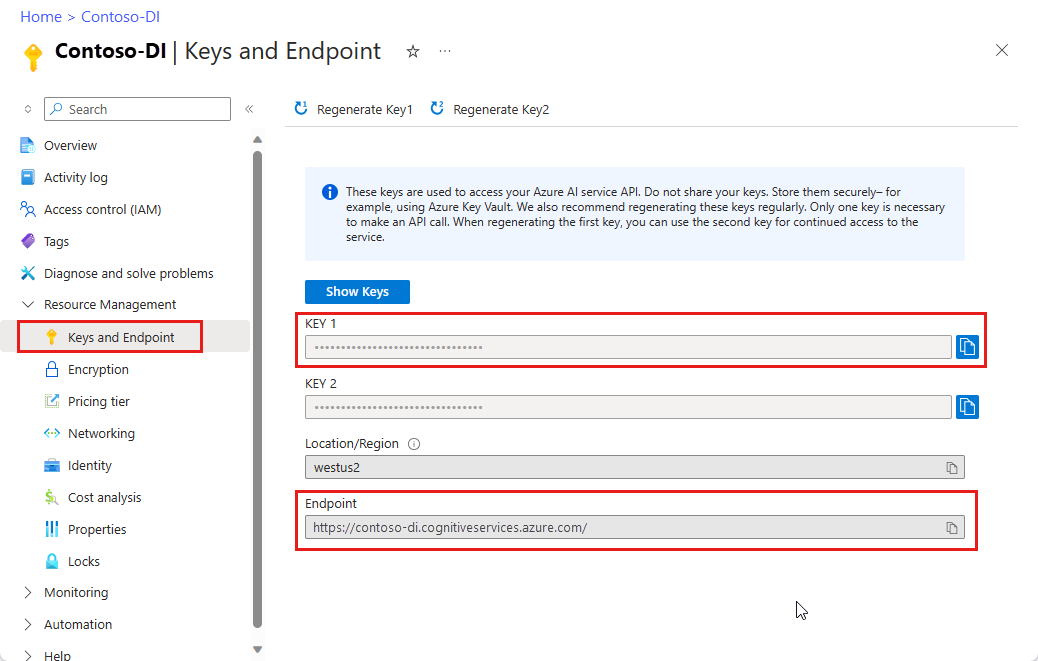
Nota:
Document Intelligence Studio está disponible con las API v3.0 y versiones posteriores.
Documento de ejemplo procesado con Inteligencia de documentos Studio
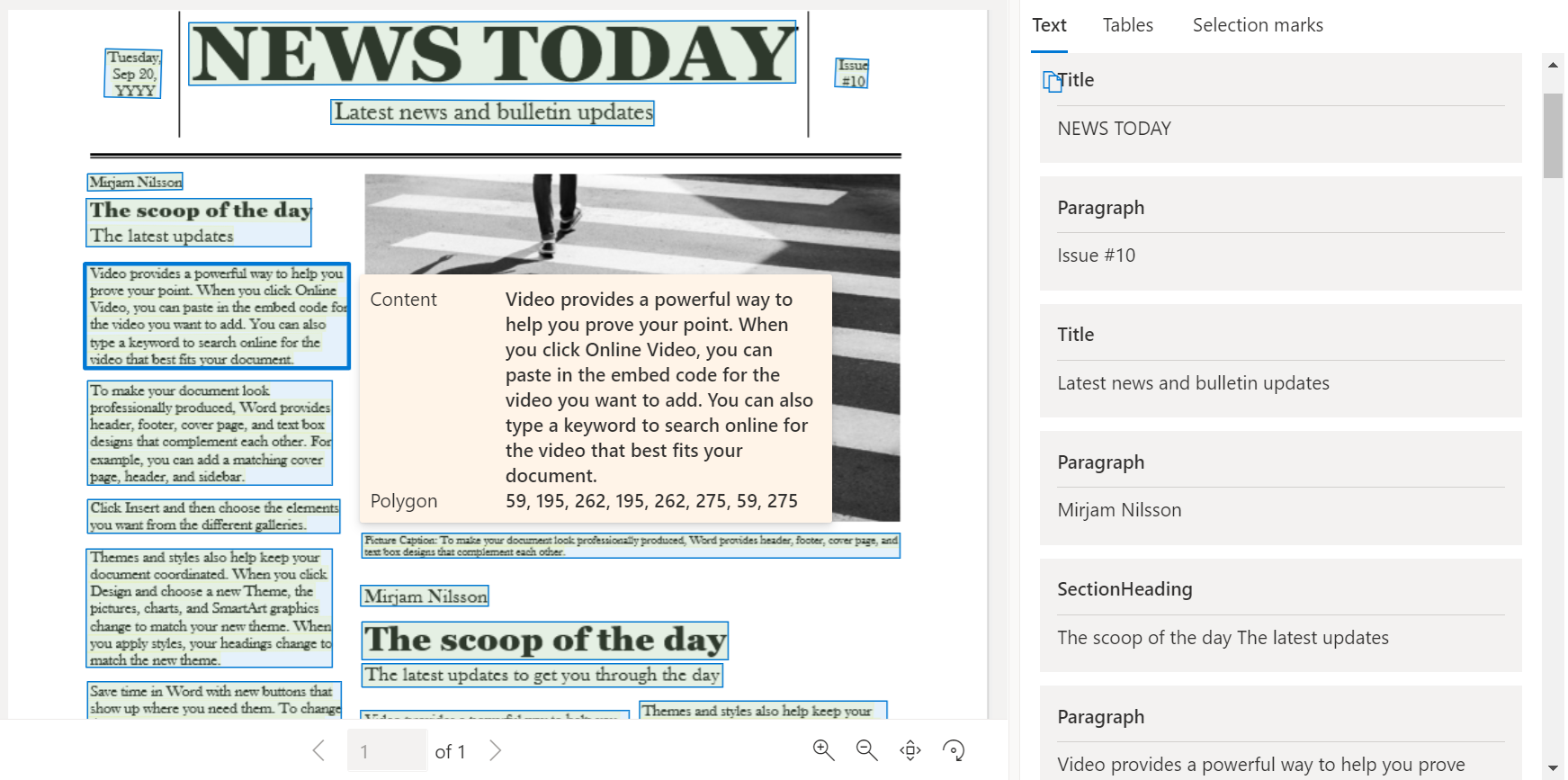
En la página principal de Document Intelligence Studio, seleccione Layout.
Puede analizar el documento de ejemplo o cargar archivos propios.
Seleccione el botón Ejecutar análisis y, si es necesario, configure las opciones de Análisis :

Idiomas compatibles
Vea nuestra página de Compatibilidad de idiomas: modelos de análisis de documentos para obtener una lista completa de los idiomas admitidos.
Extracción de datos (v4)
El modelo de diseño extrae texto, marcas de selección, tablas, párrafos y tipos de párrafo (roles) de los documentos.
Nota:
Document Intelligence v4.0 (2024-11-30 (GA)) y versiones posteriores admiten archivos de Microsoft Office (DOCX, XLSX, PPTX) y archivos HTML. No se admiten las siguientes características:
- No hay ángulo, ancho/alto ni unidad con cada objeto de página.
- En los objetos detectados no hay polígonos delimitadores ni regiones delimitadoras.
- El intervalo de páginas (
pages) no se admite como parámetro. - No hay objetos
lines.
Páginas
La colección de páginas es una lista de páginas del documento. Cada página se representa secuencialmente dentro del documento e incluye el ángulo de orientación, que indica si la página está girada, así como su ancho y alto (dimensiones en píxeles). Las unidades de página de la salida del modelo se calculan como se muestra:
| Formato de archivo | Unidad de página calculada | Páginas totales |
|---|---|---|
| Imágenes (JPEG/JPG, PNG, BMP y HEIF) | Cada imagen = 1 unidad de página | Total de imágenes |
| Cada página del PDF = 1 unidad de página | Total de páginas en el PDF | |
| TIFF | Cada imagen del TIFF = 1 unidad de página | Total de imágenes en el TIFF |
| Word (DOCX) | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
| Excel (XLSX) | Cada hoja de cálculo = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de hojas de cálculo |
| PowerPoint (PPTX) | Cada diapositiva = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de diapositivas |
| HTML | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Extracción de páginas seleccionadas de documentos
En el caso de documentos de varias páginas de gran tamaño, use el parámetro de consulta pagespara indicar números de página o intervalos de páginas específicos para la extracción de texto.
Párrafos
El modelo Layout extrae todos los bloques de texto identificados de la colección paragraphs como objeto de nivel superior en analyzeResults. Cada entrada de esta colección representa un bloque de texto e incluye el texto extraído como content y las coordenadas polygon de delimitador. La información de span apunta al fragmento de texto dentro de la propiedad content de nivel superior que contiene el texto completo del documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Roles de párrafo
La nueva detección de objetos de página basada en aprendizaje automático extrae roles lógicos como títulos, encabezados de sección, encabezados de página, pies de página, etc. El modelo de diseño de Document Intelligence asigna a determinados bloques de texto de la colección paragraphs su rol especializado o tipo predicho por el modelo. Es mejor usar roles de párrafo con documentos no estructurados para ayudar a comprender el diseño del contenido extraído para un análisis semántico más completo. Se admiten los siguientes roles de párrafo:
| Rol previsto | Descripción | Tipos de archivo admitidos |
|---|---|---|
title |
Encabezados principales de la página | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Uno o varios subtítulos de la página | pdf, image, docx, xlsx, html |
footnote |
Texto cerca del final de la página | pdf, image |
pageHeader |
Texto cerca del borde superior de la página | pdf, image, docx |
pageFooter |
Texto cerca del borde inferior de la página | pdf, image, docx, pptx, html |
pageNumber |
Número de página | pdf, image |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Texto, líneas y palabras
El modelo de maquetación de documentos de Document Intelligence extrae texto de estilo impreso y manuscrito como lines y words. La colección styles incluye cualquier estilo manuscrito para las líneas, si se detectan, junto con los intervalos que apuntan al texto asociado. Esta característica se aplica a los idiomas manuscritos admitidos.
Para el modelo de diseño de Microsoft Word, Excel, PowerPoint y HTML, Document Intelligence v4.0 2024-11-30 (GA) extraiga todo el texto insertado tal como está. Los textos se extraen en forma de palabras y párrafos. No se admiten las imágenes insertadas.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Estilo manuscrito para líneas de texto
La respuesta incluye la clasificación de si cada línea de texto es de estilo manuscrito o no, junto con una puntuación de confianza. Para obtener más información, Consulte Compatibilidad con idiomas manuscritos. En el ejemplo siguiente se muestra un ejemplo de fragmento JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Si habilita la funcionalidad de complemento de estilo o fuente, también obtendrá el resultado de fuente y estilo como parte del objeto styles.
Marcas de selección
El modelo Layout también extrae las marcas de selección de los documentos. Las marcas de selección extraídas aparecen dentro de la colección pages para cada página. Incluyen polygon delimitador, confidence y state de la selección (selected/unselected). La representación de texto (es decir, :selected: y :unselected) también se incluye como índice inicial (offset) y length que hace referencia a la propiedad de nivel superior content que contiene el texto completo del documento.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
Tablas
La extracción de tablas es un requisito clave para procesar documentos que contienen grandes volúmenes de datos que normalmente tienen formato de tablas. El modelo Layout extrae tablas de la sección pageResults de la salida JSON. La información extraída de las tablas incluye el número de columnas y filas, el intervalo de filas y el intervalo de columnas. Se representa cada celda con su polígono delimitador junto con información de si el área se reconoce como columnHeader o no. El modelo admite la extracción de tablas que se rotan. Cada celda de la tabla contiene las coordenadas de índice de fila y columna y polígono delimitador. Para el texto de la celda, el modelo genera la información span que contiene el índice inicial (offset). El modelo también produce el length en el contenido de nivel superior que contiene el texto completo del documento.
Estos son algunos factores que se deben tener en cuenta al usar la funcionalidad de extracción de viñetas de Inteligencia de documentos:
¿Se presentan los datos que desea extraer en forma de tabla y tiene sentido la estructura de la tabla?
¿Los datos caben en una cuadrícula bidimensional si no están en formato de tabla?
¿Las tablas se extienden por varias páginas? Si es así, para evitar tener que etiquetar todas las páginas, divida el PDF en páginas antes de enviarlo a Documento de inteligencia. Después del análisis, vuelva a procesar las páginas en una sola tabla.
Consulte Campos tabulares si va a crear modelos personalizados. Las tablas dinámicas tienen un número variable de filas para cada columna. Las tablas fijas tienen un número constante de filas para cada columna.
Nota:
- No se admite el análisis de tablas si el archivo de entrada es XLSX.
- Para 2024-11-30 (GA), las regiones delimitadoras de ilustraciones y tablas solo cubren el contenido principal y excluyen los títulos y notas al pie asociados.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Salida al formato markdown
Layout API puede generar el texto extraído en formato Markdown. Use outputContentFormat=markdown para especificar el formato de salida en Markdown. El contenido de Markdown se genera como parte de la sección content.
Nota:
Para v4.0 2024-11-30 (GA), la representación de tablas cambia a tablas HTML para permitir la representación de celdas combinadas, encabezados de varias filas, etc. Otro cambio relacionado consiste en usar caracteres de casilla Unicode ☒ y ☐ para marcas de selección en lugar de :selected: y :unselected:. Tenga en cuenta que esto significa que el contenido de los campos de marca de selección será :selected: aunque sus intervalos hagan referencia a caracteres Unicode en el intervalo de nivel superior.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Figuras
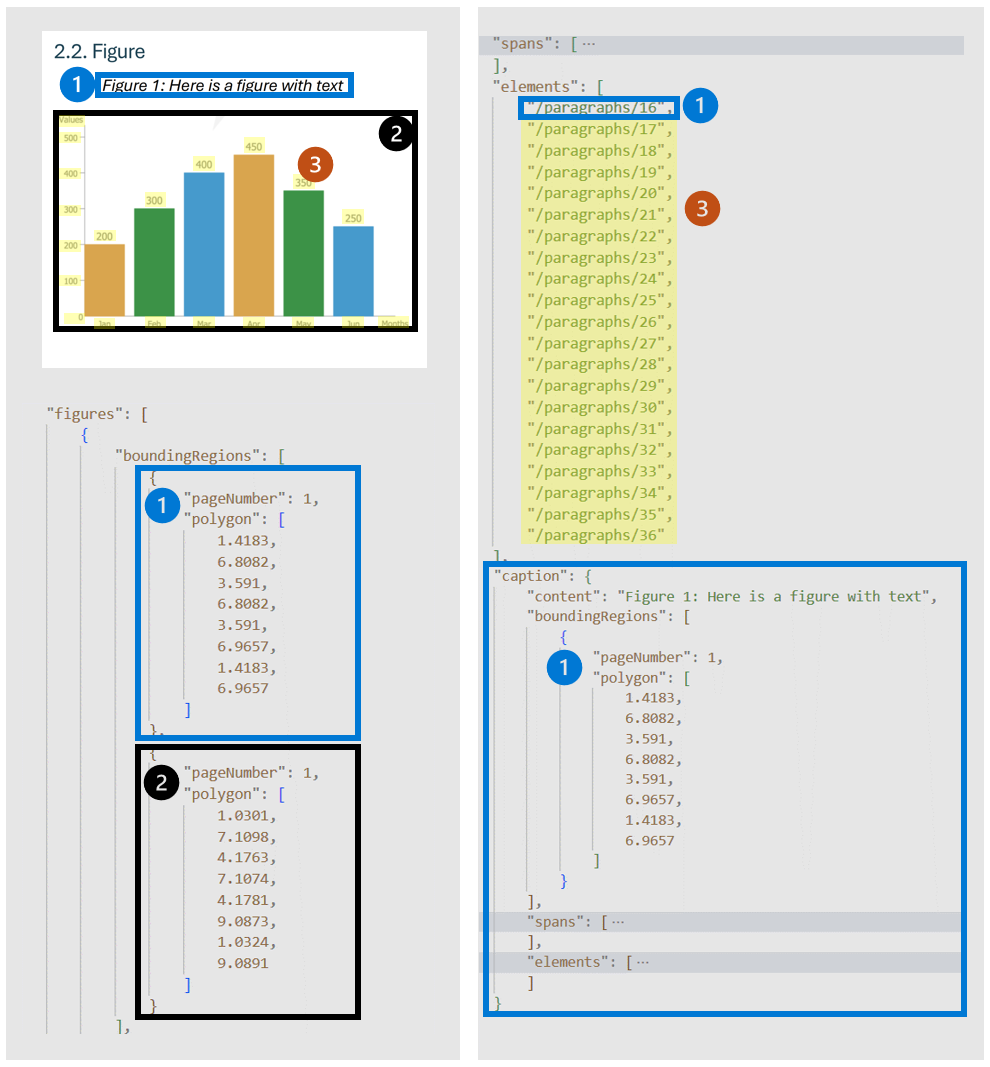
Las figuras (gráficos, imágenes) de los documentos desempeñan un papel fundamental en complementar y mejorar el contenido textual, proporcionando representaciones visuales que ayudan a comprender la información compleja. El objeto de ilustraciones detectado por el modelo de diseño tiene propiedades clave como boundingRegions (las ubicaciones espaciales de la figura en las páginas del documento, incluido el número de página y las coordenadas de polígono que describen el límite de la figura), spans (detalla los intervalos de texto relacionados con la figura, especificando sus desplazamientos y longitudes dentro del texto del documento. Esta conexión ayuda a asociar la figura con su contexto textual pertinente), elements (los identificadores de los elementos de texto o párrafos del documento que están relacionados con la figura o la describen) y caption si hay alguno.
Cuando se especifica output=figures durante la operación de análisis inicial, el servicio genera imágenes recortadas de todas las figuras detectadas a las que se puede acceder a través de /analyeResults/{resultId}/figures/{figureId}.
FigureId se incluye en cada objeto de figura, siguiendo una convención no documentada de {pageNumber}.{figureIndex} donde figureIndex se restablece a una por página.
Nota:
Para v4.0 0 2024-11-30-preview, las regiones delimitadoras de ilustraciones y tablas solo cubren el contenido principal y excluyen los títulos y notas al pie asociados.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
Secciones
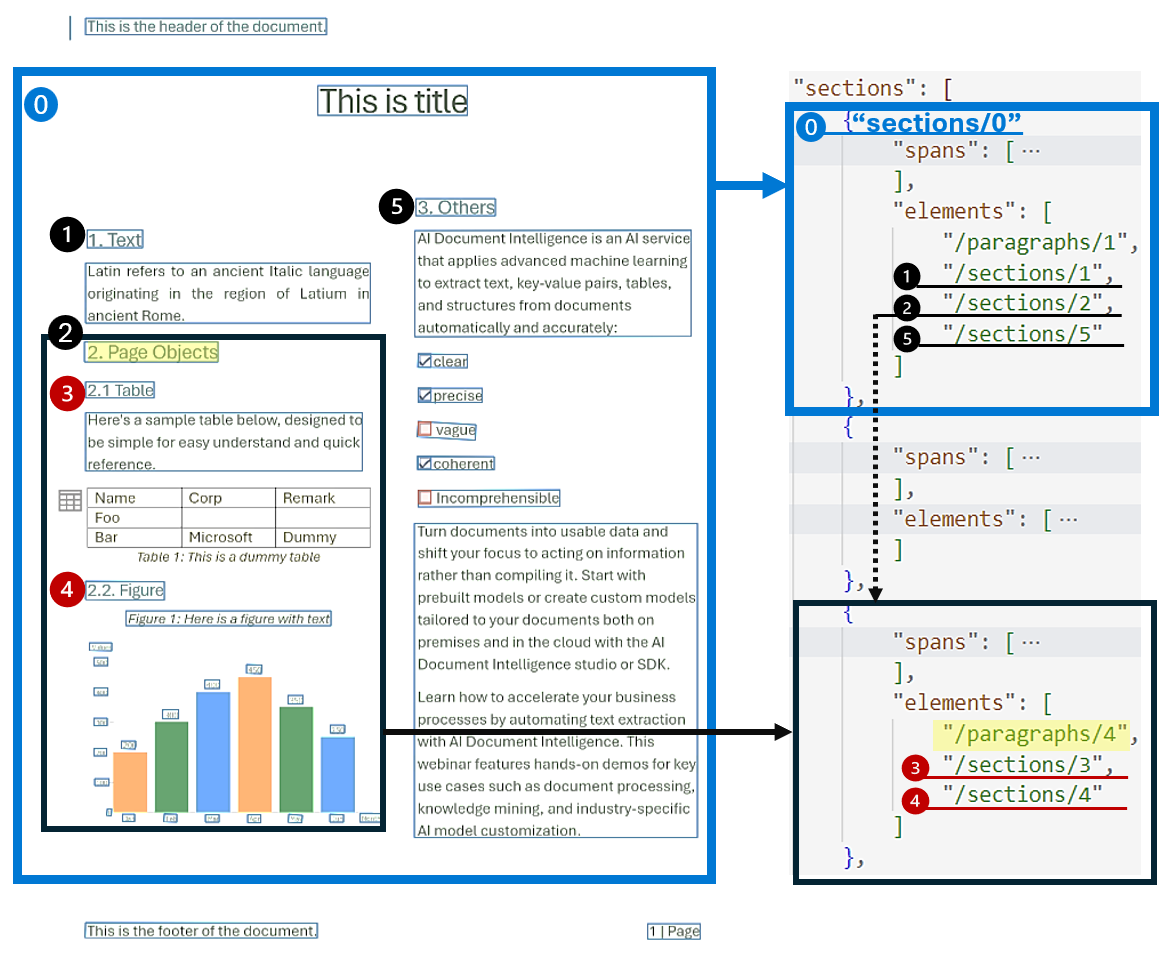
El análisis jerárquico de la estructura de documentos es fundamental para organizar, comprender y procesar documentos extensos. Este enfoque es esencial para segmentar semánticamente documentos largos para aumentar la comprensión, facilitar la navegación y mejorar la recuperación de información. La llegada de la recuperación de generación aumentada (RAG) en la inteligencia artificial generativa de documentos subraya la importancia del análisis jerárquico de la estructura de documentos. El modelo de diseño admite secciones y subsecciones en la salida, lo que identifica la relación de secciones y objetos dentro de cada sección. La estructura jerárquica se mantiene en elements de cada sección. Puede usar la salida al formato markdown para obtener fácilmente las secciones y subsecciones en markdown.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Este contenido se aplica a: ![]() v2.1 | Última versión:
v2.1 | Última versión: ![]() v4.0 (GA)
v4.0 (GA)
El modelo de maquetación de Document Intelligence es una API avanzada de análisis de documentos basada en aprendizaje automático disponible en la nube de Document Intelligence. Permite tomar documentos en varios formatos y devolver sus representaciones de datos estructurados. Combina una versión mejorada de nuestras poderosas funcionalidades de reconocimiento óptico de caracteres (OCR) con modelos de aprendizaje profundo para extraer texto, tablas, marcas de selección y la estructura de los documentos.
Análisis de diseño de documentos
El análisis de la estructura y el diseño de documentos es el proceso de analizar un documento para extraer regiones de interés y sus interrelaciones. El objetivo es extraer texto y elementos estructurales de la página para crear modelos de mejor comprensión semántica. Hay dos tipos de roles en un diseño de documento:
- Roles geométricos: el texto, las tablas, las figuras y las marcas de selección son ejemplos de roles geométricos.
- Roles lógicos: los títulos, los encabezados y los pies de página son ejemplos de roles lógicos de textos.
En la ilustración siguiente se muestran los componentes típicos de una imagen de una página de ejemplo.
Opciones de desarrollo
Documento de inteligencia v3.1 es compatible con las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de diseño | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
diseño preelaborado |
Documento de inteligencia v3.0 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos | Id. de modelo |
|---|---|---|
| Modelo de diseño | • Document Intelligence Studio • API REST • SDK de C# • SDK de Python • SDK de Java • SDK de JavaScript |
diseño preelaborado |
Documento de inteligencia v2.1 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos |
|---|---|
| Modelo de diseño | ● Herramienta de etiquetado de Documento de inteligencia ● API REST ● SDK de biblioteca cliente ● Contenedor Docker de Documento de inteligencia |
Requisitos de entrada
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
- Formatos de archivo admitidos: JPEG, PNG, PDF y TIFF.
- Número admitido de páginas: para PDF y TIFF, se procesan hasta 2000 páginas. En el caso de los suscriptores del nivel Gratis, solo se procesan las dos primeras páginas.
- Tamaño de archivo admitido: el tamaño del archivo debe ser inferior a 50 MB y dimensiones de al menos 50 x 50 píxeles y como máximo 10 000 x 10 000 píxeles.
Introducción al modelo de diseño
Vea cómo se extraen de los documentos los datos, incluidos el texto, las tablas, los encabezados de tabla, las marcas de selección y la información de estructura mediante Document Intelligence. Tendrá que supervisar los recursos siguientes:
Una suscripción a Azure: puede crear una cuenta gratuita.
Una instancia de Document Intelligence en el Azure Portal. Puede usar el plan de tarifa gratuito (
F0) para probar el servicio. Después de implementar el recurso, seleccione Ir al recurso para obtener la clave y el punto de conexión.
Nota:
Document Intelligence Studio está disponible con las API v3.0 y versiones posteriores.
Documento de ejemplo procesado con Inteligencia de documentos Studio
En la página principal de Document Intelligence Studio, seleccione Layout.
Puede analizar el documento de ejemplo o cargar archivos propios.
Seleccione el botón Ejecutar análisis y, si es necesario, configure las opciones de Análisis :
Herramienta de etiquetado de ejemplo de Documento de inteligencia
En la página principal de la herramienta de ejemplo, seleccione Use layout to get text, tables and selection marks (Usar el diseño para obtener texto, tablas y marcas de selección).
En el campo Punto de conexión de Documento de inteligencia, pegue el punto de conexión que obtuvo con la suscripción de Documento de inteligencia.
En el campo Clave, pegue la clave que obtuvo del recurso de Documento de inteligencia.
En el campo Origen, seleccione URL en el menú desplegable. Puede usar nuestro documento de ejemplo:
Seleccione el botón Recuperar cambios.
Seleccione Run Layout (Ejecutar la API Layout). La herramienta de etiquetado de muestras de Document Intelligence llama a la API
Analyze Layoutpara analizar el documento.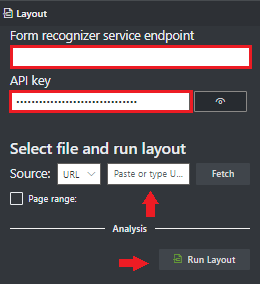
Ver los resultados: vea el texto extraído resaltado, las marcas de selección detectadas y las tablas detectadas.
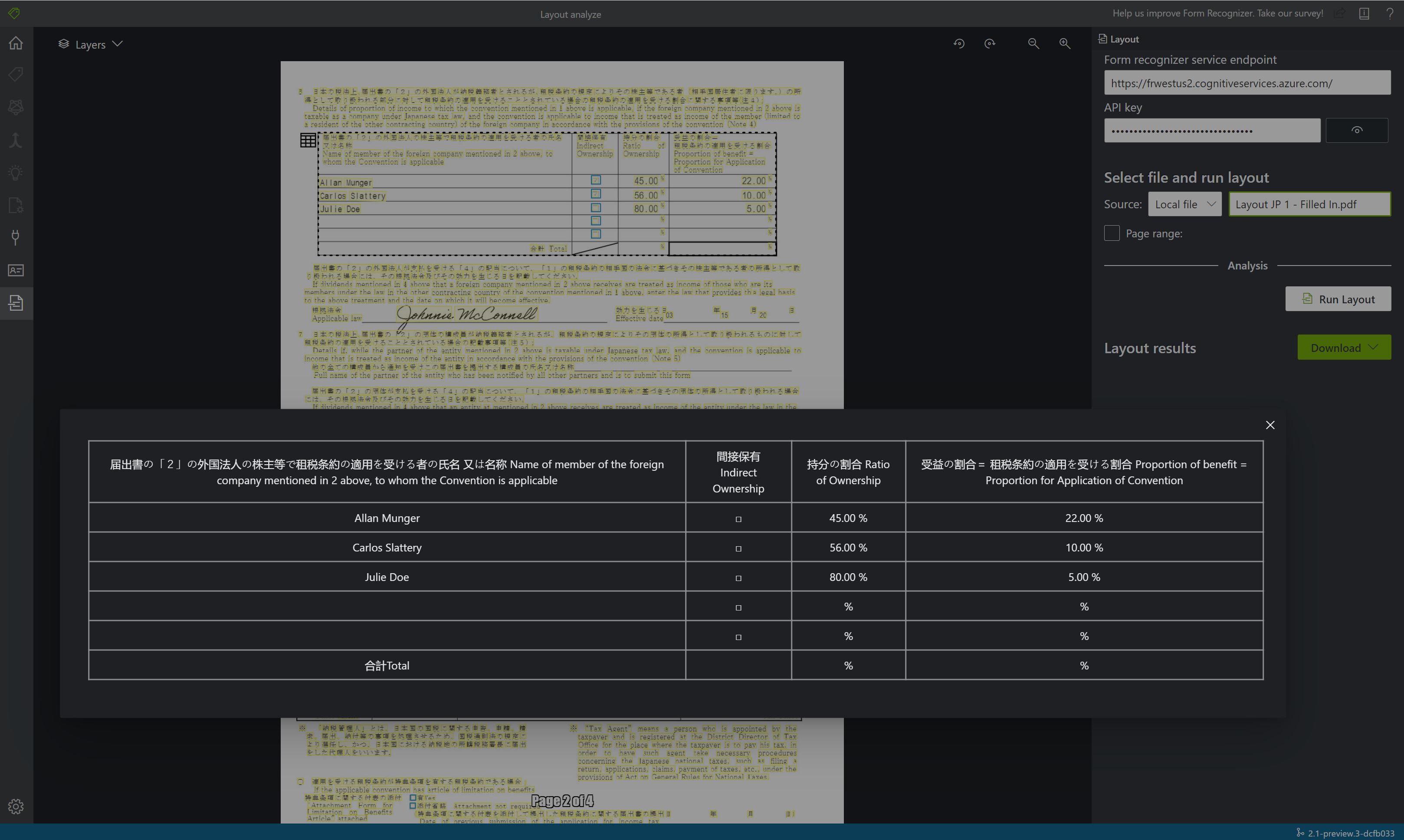
{kind=link}
Idiomas y configuraciones regionales compatibles
Vea nuestra página de Compatibilidad de idiomas: modelos de análisis de documentos para obtener una lista completa de los idiomas admitidos.
Documento de inteligencia v2.1 admite las siguientes herramientas, aplicaciones y bibliotecas:
| Característica | Recursos |
|---|---|
| API de diseño | ● Herramienta de etiquetado de Documento de inteligencia ● API REST ● SDK de biblioteca cliente ● Contenedor Docker de Documento de inteligencia |
Extracción de datos
El modelo de diseño extrae texto, marcas de selección, tablas, párrafos y tipos de párrafo (roles) de los documentos.
Nota:
Document Intelligence v4.0 2024-11-30 (GA) admite archivos de Microsoft Office (DOCX, XLSX, PPTX) y archivos HTML. No se admiten las siguientes características:
- No hay ángulo, ancho/alto ni unidad con cada objeto de página.
- En los objetos detectados no hay polígonos delimitadores ni regiones delimitadoras.
- El intervalo de páginas (
pages) no se admite como parámetro. - No hay objetos
lines.
Páginas
La colección de páginas es una lista de páginas del documento. Cada página se representa secuencialmente dentro del documento e incluye el ángulo de orientación, que indica si la página está girada, así como su ancho y alto (dimensiones en píxeles). Las unidades de página de la salida del modelo se calculan como se muestra:
| Formato de archivo | Unidad de página calculada | Páginas totales |
|---|---|---|
| Imágenes (JPEG/JPG, PNG, BMP y HEIF) | Cada imagen = 1 unidad de página | Total de imágenes |
| Cada página del PDF = 1 unidad de página | Total de páginas en el PDF | |
| TIFF | Cada imagen del TIFF = 1 unidad de página | Total de imágenes en el TIFF |
| Word (DOCX) | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
| Excel (XLSX) | Cada hoja de cálculo = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de hojas de cálculo |
| PowerPoint (PPTX) | Cada diapositiva = 1 unidad de página; no se admiten imágenes insertadas o vinculadas | Total de diapositivas |
| HTML | Hasta 3000 caracteres = 1 unidad de página; no se admiten imágenes incrustadas o vinculadas | Total de páginas de hasta 3000 caracteres cada una |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Extracción de páginas seleccionadas de documentos
En el caso de documentos de varias páginas de gran tamaño, use el parámetro de consulta pagespara indicar números de página o intervalos de páginas específicos para la extracción de texto.
Párrafos
El modelo Layout extrae todos los bloques de texto identificados de la colección paragraphs como objeto de nivel superior en analyzeResults. Cada entrada de esta colección representa un bloque de texto e incluye el texto extraído como content y las coordenadas polygon de delimitador. La información de span apunta al fragmento de texto dentro de la propiedad content de nivel superior que contiene el texto completo del documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Roles de párrafo
La nueva detección de objetos de página basada en aprendizaje automático extrae roles lógicos como títulos, encabezados de sección, encabezados de página, pies de página, etc. El modelo de diseño de Document Intelligence asigna a determinados bloques de texto de la colección paragraphs su rol especializado o tipo predicho por el modelo. Es mejor usar roles de párrafo con documentos no estructurados para ayudar a comprender el diseño del contenido extraído para un análisis semántico más completo. Se admiten los siguientes roles de párrafo:
| Rol previsto | Descripción | Tipos de archivo admitidos |
|---|---|---|
title |
Encabezados principales de la página | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Uno o varios subtítulos de la página | pdf, image, docx, xlsx, html |
footnote |
Texto cerca del final de la página | pdf, image |
pageHeader |
Texto cerca del borde superior de la página | pdf, image, docx |
pageFooter |
Texto cerca del borde inferior de la página | pdf, image, docx, pptx, html |
pageNumber |
Número de página | pdf, image |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Texto, líneas y palabras
El modelo de maquetación de documentos de Document Intelligence extrae texto de estilo impreso y manuscrito como lines y words. La colección styles incluye cualquier estilo manuscrito para las líneas, si se detectan, junto con los intervalos que apuntan al texto asociado. Esta característica se aplica a los idiomas manuscritos admitidos.
Para el modelo de diseño de Microsoft Word, Excel, PowerPoint y HTML, Document Intelligence v4.0 2024-11-30 (GA) extraiga todo el texto insertado tal como está. Los textos se extraen en forma de palabras y párrafos. No se admiten las imágenes insertadas.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Estilo manuscrito para líneas de texto
La respuesta incluye la clasificación de si cada línea de texto es de estilo manuscrito o no, junto con una puntuación de confianza. Para obtener más información, Consulte Compatibilidad con idiomas manuscritos. En el ejemplo siguiente se muestra un ejemplo de fragmento JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Si habilita la funcionalidad de complemento de estilo o fuente, también obtendrá el resultado de fuente y estilo como parte del objeto styles.
Marcas de selección
El modelo Layout también extrae las marcas de selección de los documentos. Las marcas de selección extraídas aparecen dentro de la colección pages para cada página. Incluyen polygon delimitador, confidence y state de la selección (selected/unselected). La representación de texto (es decir, :selected: y :unselected) también se incluye como índice inicial (offset) y length que hace referencia a la propiedad de nivel superior content que contiene el texto completo del documento.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Tablas
La extracción de tablas es un requisito clave para procesar documentos que contienen grandes volúmenes de datos que normalmente tienen formato de tablas. El modelo Layout extrae tablas de la sección pageResults de la salida JSON. La información extraída de las tablas incluye el número de columnas y filas, el intervalo de filas y el intervalo de columnas. Se representa cada celda con su polígono delimitador junto con información de si el área se reconoce como columnHeader o no. El modelo admite la extracción de tablas que se rotan. Cada celda de la tabla contiene las coordenadas de índice de fila y columna y polígono delimitador. Para el texto de la celda, el modelo genera la información span que contiene el índice inicial (offset). El modelo también produce el length en el contenido de nivel superior que contiene el texto completo del documento.
Estos son algunos factores que se deben tener en cuenta al usar la funcionalidad de extracción de viñetas de Inteligencia de documentos:
¿Se presentan los datos que desea extraer en forma de tabla y tiene sentido la estructura de la tabla?
¿Los datos caben en una cuadrícula bidimensional si no están en formato de tabla?
¿Las tablas se extienden por varias páginas? Si es así, para evitar tener que etiquetar todas las páginas, divida el PDF en páginas antes de enviarlo a Documento de inteligencia. Después del análisis, vuelva a procesar las páginas en una sola tabla.
Consulte Campos tabulares si va a crear modelos personalizados. Las tablas dinámicas tienen un número variable de filas para cada columna. Las tablas fijas tienen un número constante de filas para cada columna.
Nota:
- No se admite el análisis de tablas si el archivo de entrada es XLSX.
- Document Intelligence v4.0 2024-11-30 (GA) admite regiones delimitadoras para ilustraciones y tablas que cubren solo el contenido principal y excluyen los títulos y notas al pie asociados.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Anotaciones (disponibles solo en la API 2023-02-28-preview).
El modelo de diseño extrae anotaciones en documentos, como marcas de verificación y cruces. La respuesta incluye el tipo de anotación, junto con una puntuación de confianza y un polígono delimitador.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Salida de orden de lectura natural (solo idiomas procedentes del latín)
Puede especificar el orden en que se generan las líneas de texto con el parámetro de consulta readingOrder. Use natural si quiere obtener una salida de orden de lectura más natural, como se muestra en el ejemplo siguiente. Esta característica solo es compatible con los idiomas procedentes del latín.

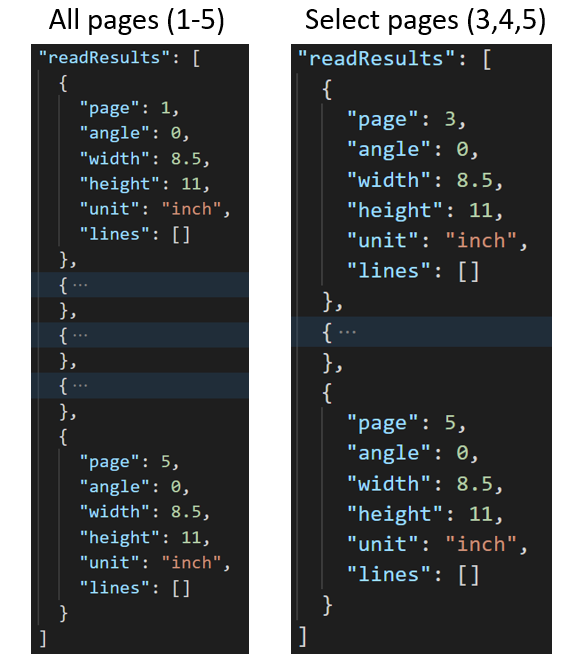
Seleccione los intervalos o los números de páginas para la extracción de texto
En el caso de documentos de varias páginas de gran tamaño, use el parámetro de consulta pagespara indicar números de página o intervalos de páginas específicos para la extracción de texto. En el ejemplo siguiente se muestra un documento con 10 páginas, con texto extraído para ambos casos: todas las páginas (1-10) y las páginas seleccionadas (3-6).
La operación Get Analyze Layout Result
El segundo paso consiste en llamar a la operación Get Analyze Layout Result. Esta operación toma como entrada el ID de resultado que ha creado la operación Analyze Layout. Devuelve una respuesta JSON que contiene un campo de estado con los siguientes valores posibles.
| Campo | Tipo | Valores posibles |
|---|---|---|
| status | cadena | notStarted: no se ha iniciado la operación de análisis.running: la operación de análisis está en curso.failed: error en la operación de análisis.succeeded: la operación de análisis se ha realizado correctamente. |
Llame esta operación de forma iterativa hasta que se devuelva con el valor succeeded. Para evitar superar la velocidad de solicitudes por segundo (RPS), use un intervalo de 3 a 5 segundos.
Cuando el campo de estado tiene el valor succeeded, la respuesta de JSON incluye el diseño, el texto, las tablas y las marcas de selección extraídos. Los datos extraídos incluyen las líneas de texto y palabras extraídas, los rectángulos delimitadores, el aspecto del texto con una indicación de texto manuscrito, las tablas y las marcas de selección que indican si se ha seleccionado o no.
Clasificación manuscrita de líneas de texto (solo para idiomas derivados del latín)
La respuesta incluye la clasificación de si cada línea de texto es de estilo manuscrito o no, junto con una puntuación de confianza. Esta característica solo es compatible con los idiomas procedentes del latín. En el ejemplo siguiente se muestra la clasificación manuscrita del texto de la imagen.

Salida de JSON de ejemplo
La respuesta a la operación Get Analyze Layout Result es una representación estructurada del documento con toda la información extraída. Aquí encontrará un archivo con un documento de ejemplo y su salida estructurada, una salida de un diseño de ejemplo.
La salida JSON tiene dos partes:
- El nodo
readResultscontiene todo el texto reconocido y la marca de selección. La jerarquía de presentación de texto es página, línea y palabras individuales. - El nodo
pageResultscontiene las tablas y celdas extraídas con sus rectángulos delimitadores, su confianza y una referencia a las líneas y palabras del campo "readResults".
Ejemplo de salida
Texto
La API Layout extrae texto de documentos e imágenes con varios ángulos y colores de texto. Es compatible con fotografías de documentos, faxes, texto impreso o manuscrito (solo en inglés) y modos mixtos. El texto se extrae con información sobre las líneas, palabras, rectángulos delimitadores, puntuaciones de confianza y estilo (manuscrito u otro). Toda la información del texto se incluye en la sección readResults de la salida JSON.
Tablas con encabezados
La API Layout extrae tablas de la sección pageResults de la salida JSON. Los documentos se pueden digitalizar o fotografiar. Las tablas pueden ser complejas con celdas o columnas combinadas, con o sin bordes, y con ángulos impares. La información extraída de las tablas incluye el número de columnas y filas, el intervalo de filas y el intervalo de columnas. Se representa cada celda con su rectángulo de selección y se indica si el área se reconoce como parte de un encabezado o no. Las celdas de encabezado previstas por el modelo pueden abarcar varias filas y no son necesariamente las primeras filas de una tabla. También funcionan con tablas giradas. Cada celda de la tabla también incluye el texto completo con referencias a las palabras individuales de la sección readResults.
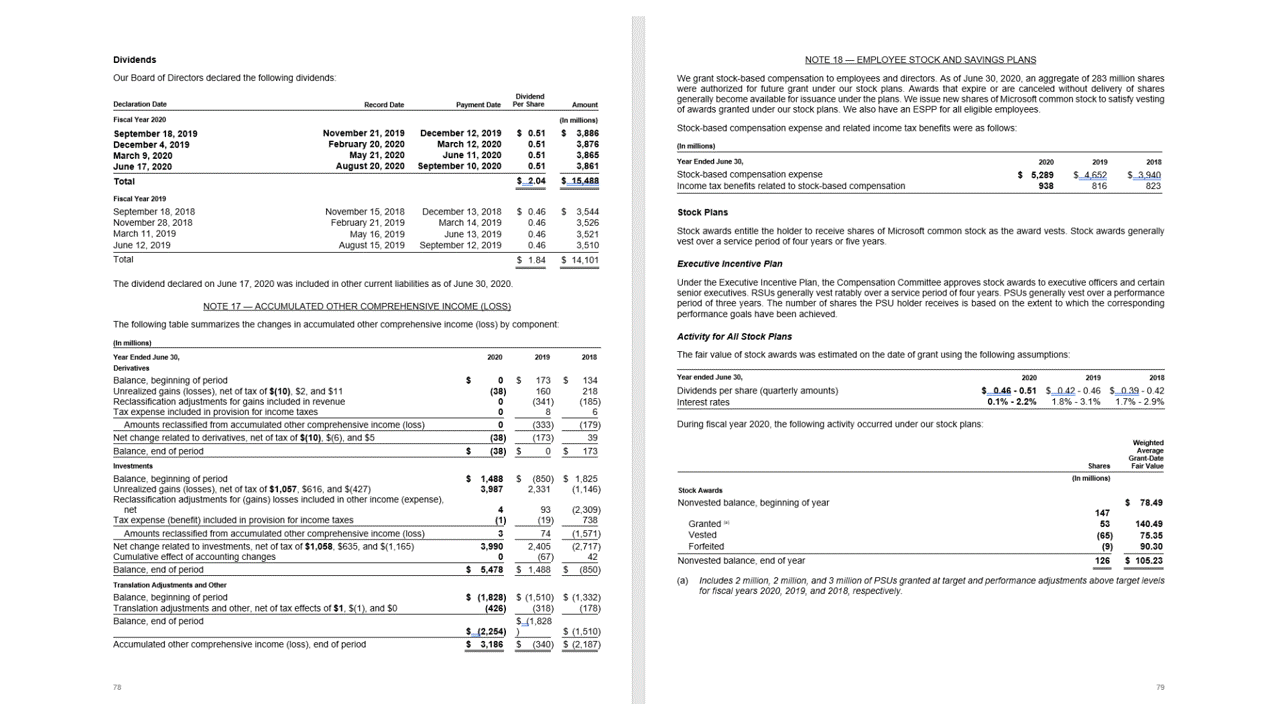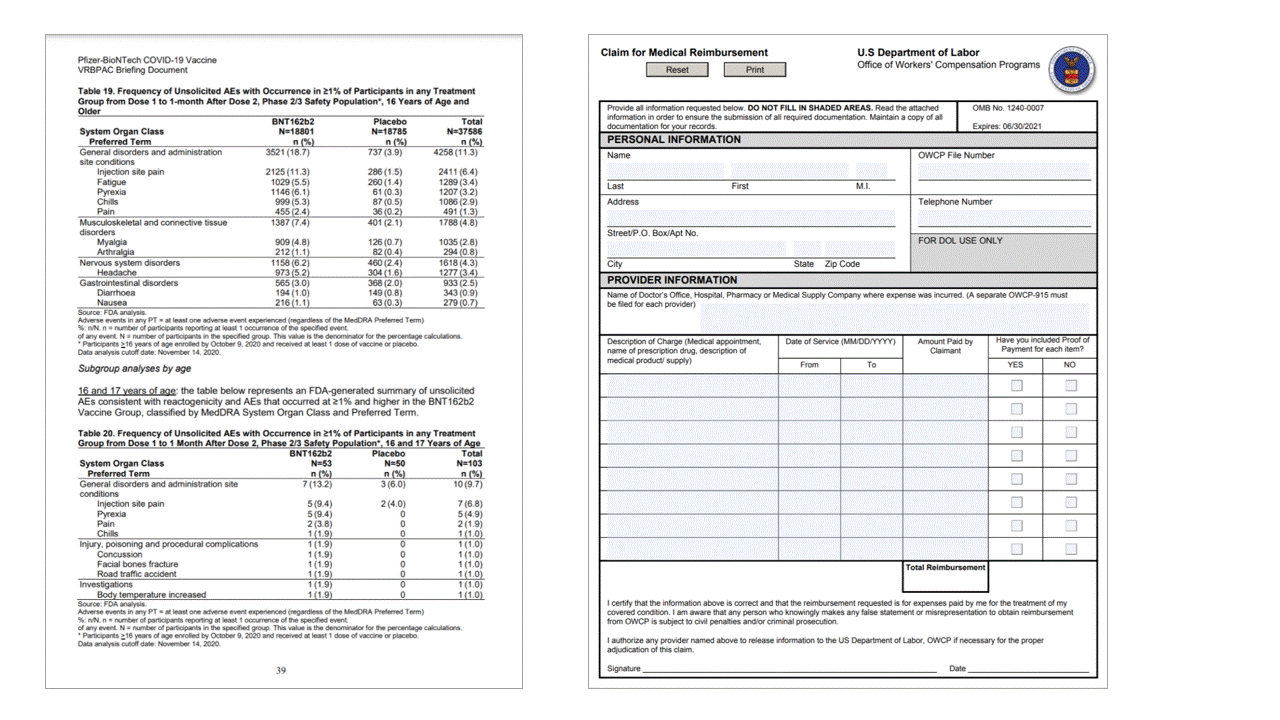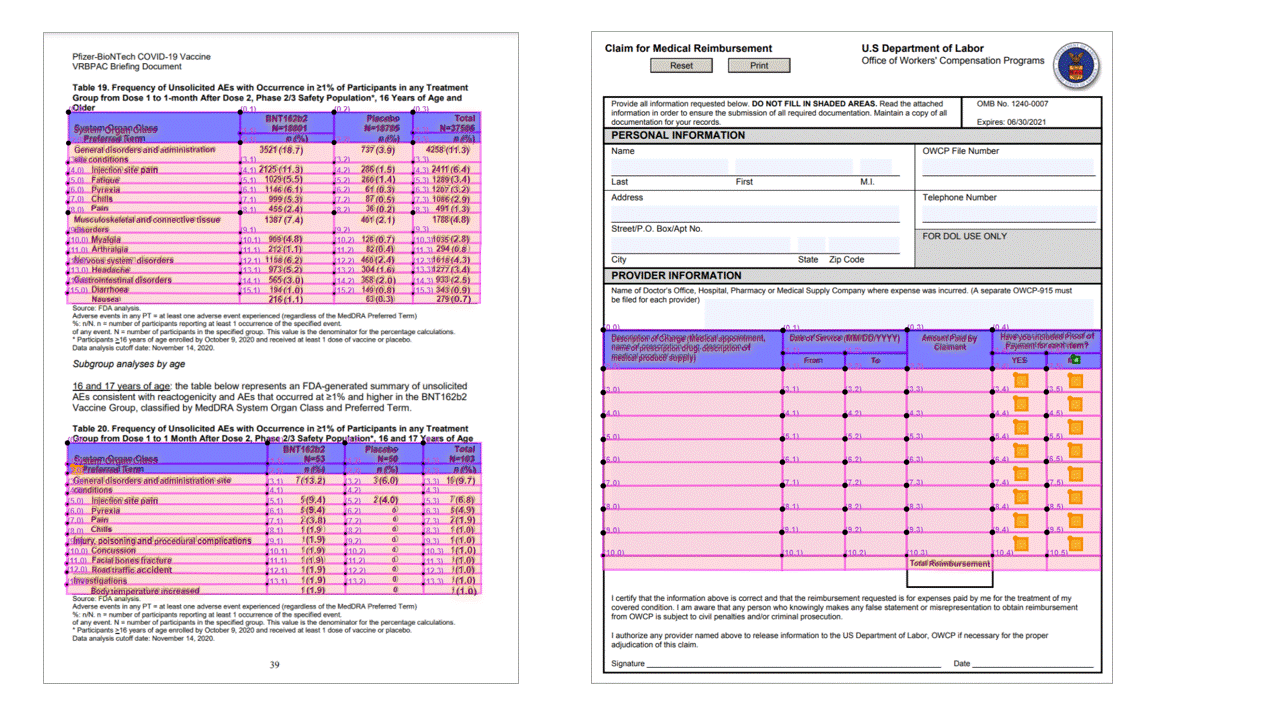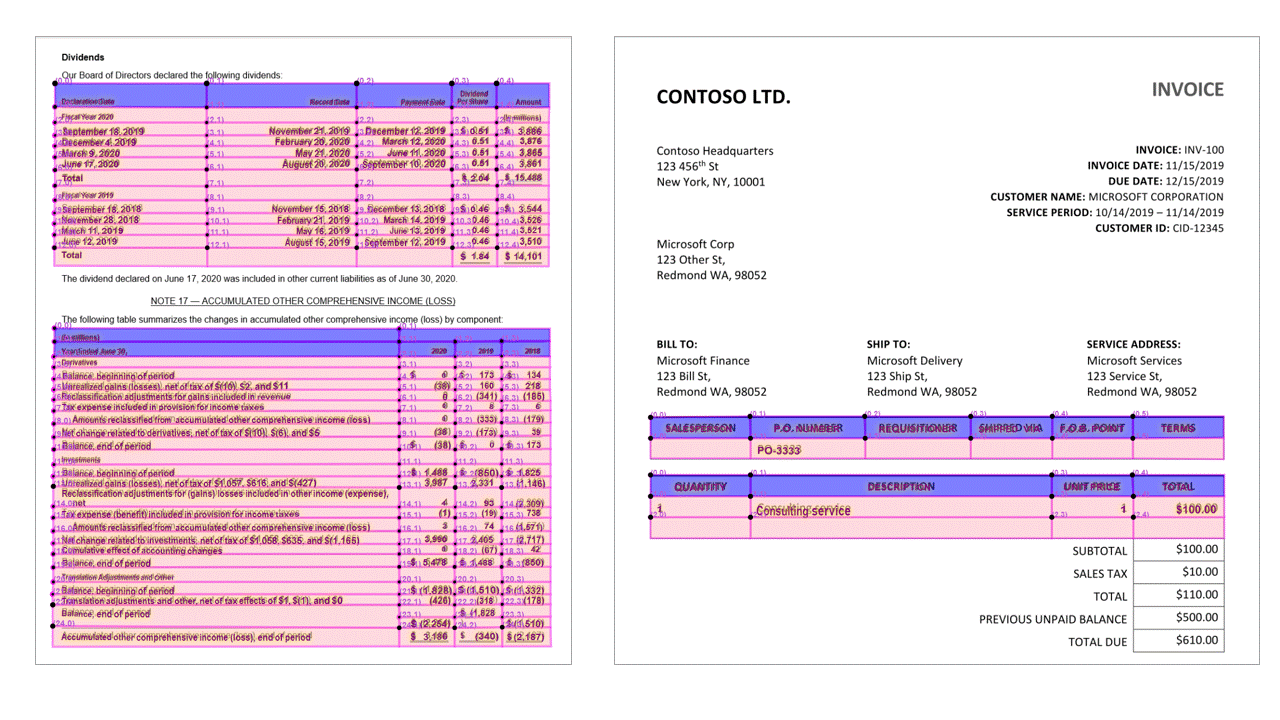
Marcas de selección
La API Layout también extrae marcas de selección de los documentos. Entre las marcas de selección extraídas se incluyen el rectángulo delimitador, la confianza y el estado (seleccionado o no seleccionado). La información de la marca de selección se extrae en la sección readResults de la salida JSON.
Guía de migración
- Siga la Guía de migración de Document Intelligence v3.1 para obtener información sobre cómo usar la versión v3.1 en las aplicaciones y flujos de trabajo.
Pasos siguientes
Aprenda a procesar sus propios formularios y documentos con Document Intelligence Studio.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.
Obtenga información sobre cómo procesar sus propios formularios y documentos con la Herramienta de etiquetado de muestras de Document Intelligence.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.