Generación aumentada de recuperación con Documento de inteligencia de Azure AI
Este contenido se aplica a: ![]() v4.0 (GA)
v4.0 (GA)
Introducción
La generación aumentada de recuperación (RAG) es un modelo de diseño de documentos que combina un modelo de lenguaje grande (LLM) entrenado previamente, como ChatGPT, con un sistema de recuperación de datos externo para generar respuestas mejoradas que incorpora nuevos datos distintos de los datos de entrenamiento originales. Agregar un sistema de recuperación de información a las aplicaciones le permite chatear con los documentos, generar contenido cautivador y acceder a la eficacia de los modelos de Azure OpenAI para sus datos. También tiene más control sobre los datos usados por LLM a medida que formula una respuesta.
El modelo de diseño de Document Intelligence es una API avanzada de análisis de documentos basada en aprendizaje automático. El modelo de diseño ofrece una solución completa para funcionalidades avanzadas de extracción de contenido y análisis de estructura de documentos. Con el modelo de diseño, puede extraer fácilmente texto y elementos estructurales para dividir grandes cuerpos de texto en fragmentos más pequeños y significativos basados en contenido semántico en lugar de divisiones arbitrarias. La información extraída se puede representar convenientemente en formato Markdown, lo que le permite definir la estrategia de fragmentación semántica en función de los bloques de creación proporcionados.
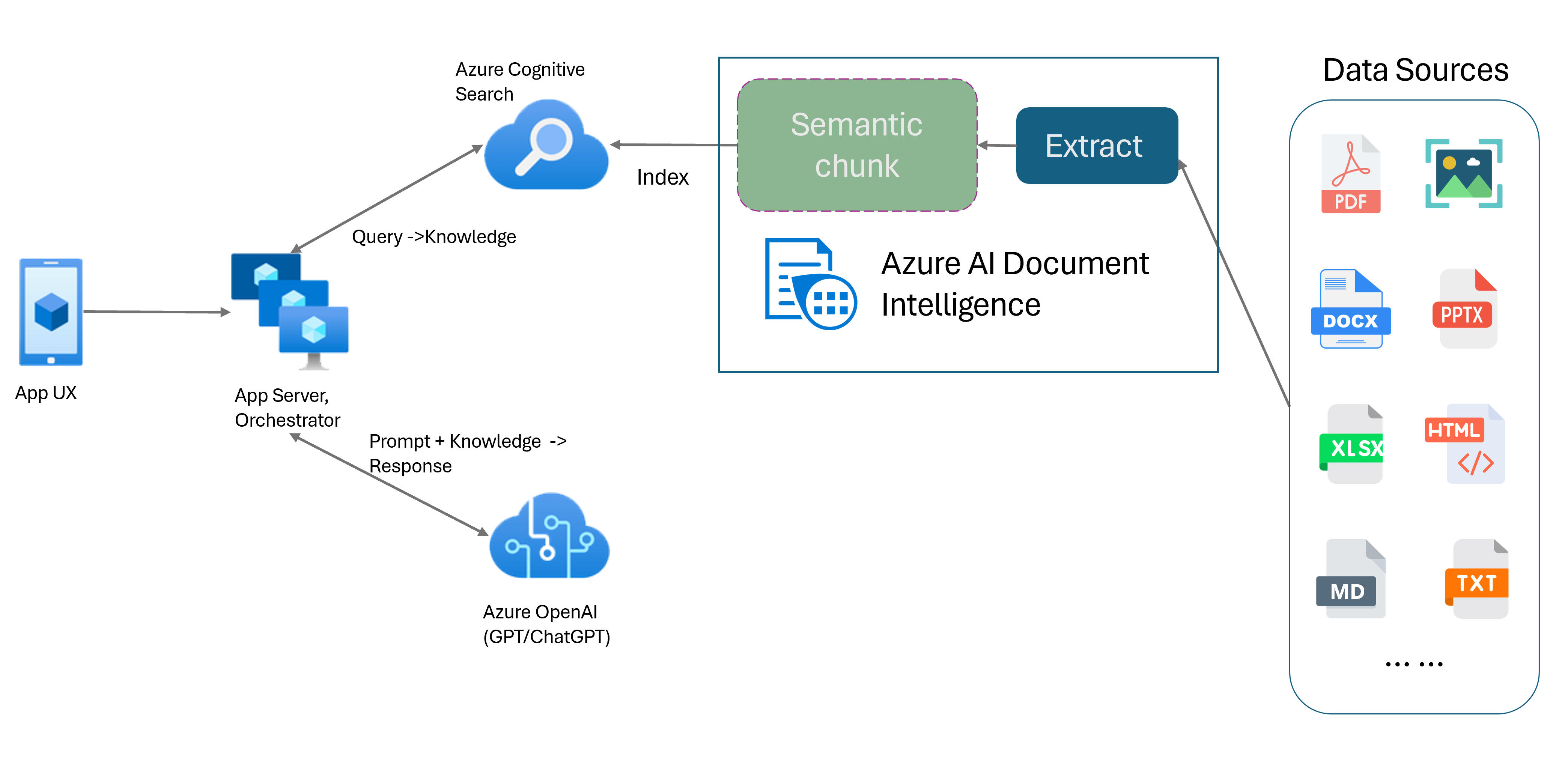
Fragmentación semántica
Las oraciones largas son difíciles para las aplicaciones de procesamiento de lenguaje natural (NLP). Especialmente cuando se componen de varias cláusulas, nombres complejos o frases verbales, oraciones relativas y agrupaciones con paréntesis. Al igual que el espectador humano, un sistema NLP también debe realizar un seguimiento correcto de todas las dependencias presentadas. El objetivo de la fragmentación semántica es buscar fragmentos semánticamente coherentes de una representación de oración. Estos fragmentos se pueden procesar de forma independiente y volver a asociarse como representaciones semánticas sin pérdida de información, interpretación o relevancia semántica. El significado inherente del texto se usa como guía para el proceso de fragmentación.
Las estrategias de fragmentación de datos de texto desempeñan un papel clave en la optimización de la respuesta y el rendimiento de RAG. El tamaño fijo y la semántica son dos métodos de fragmentación distintos:
Fragmentación de tamaño fijo. La mayoría de las estrategias de fragmentación que se usan actualmente en RAG se basan en segmentos de texto de tamaño fijo conocidos como fragmentos. La fragmentación de tamaño fijo es rápida, fácil y eficaz con texto que no tiene una estructura semántica sólida, como registros y datos. Sin embargo, no se recomienda para el texto que requiere una comprensión semántica y un contexto preciso. La naturaleza de tamaño fijo de la ventana puede dar lugar a que se interrumpan palabras, oraciones o párrafos que impidan la comprensión e interrumpan el flujo de información y comprensión.
Fragmentación semántica. Este método divide el texto en fragmentos en función de la comprensión semántica. Los límites de división se centran en el sujeto de la oración y usan recursos computacionales significativamente complejos. Sin embargo, tiene la gran ventaja de mantener la coherencia semántica dentro de cada fragmento. Resulta útil para las tareas de resumen de texto, análisis de sentimiento y clasificación de documentos.
Fragmentación semántica con el modelo de diseño de Document Intelligence
Markdown es un lenguaje de marcado estructurado y con formato y una entrada popular para habilitar la fragmentación semántica en RAG (generación aumentada de recuperación). Puede usar el contenido de Markdown del modelo de diseño para dividir documentos en función de los límites de párrafo, crear fragmentos específicos para tablas y ajustar la estrategia de fragmentación para mejorar la calidad de las respuestas generadas.
Ventajas de usar el modelo de diseño
Procesamiento simplificado. Puede analizar diferentes tipos de documentos, como archivos PDF digitales y escaneados, imágenes, archivos de office (docx, xlsx, pptx) y HTML, con una sola llamada API.
Escalabilidad y calidad de inteligencia artificial. El modelo de diseño es altamente escalable en el reconocimiento óptico de caracteres (OCR), extracción de tablas y análisis de estructura de documentos. Admite 309 idiomas impresos y 12 manuscritos, lo que garantiza resultados de alta calidad gracias a las funcionalidades de inteligencia artificial.
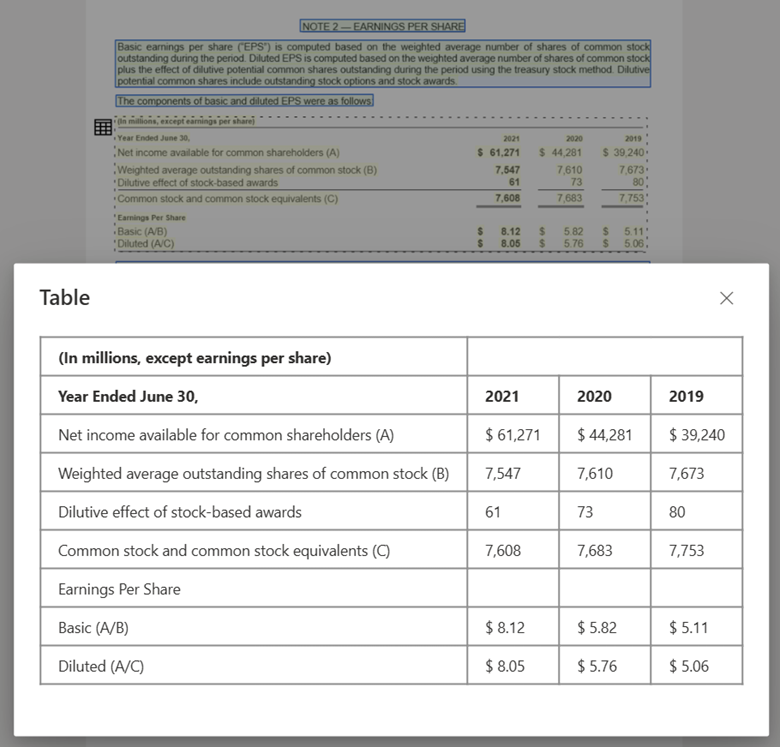
Compatibilidad con el modelo de lenguaje grande (LLM). La salida con formato Markdown del modelo de diseño es fácil de usar con LLM y facilita la integración sin problemas en los flujos de trabajo. Puede convertir cualquier tabla de un documento en formato Markdown y evitar tener que analizar los documentos para una mayor comprensión de LLM.
Imagen de texto procesada con Document Intelligence Studio y salida para MarkDown mediante el modelo de diseño

Imagen de tabla procesada con Document Intelligence Studio mediante el modelo de diseño
Introducción
El modelo de diseño de Document Intelligence 2024-11-30 (GA) admite las siguientes opciones de desarrollo:
¿Está listo para comenzar?
Estudio del documento de inteligencia
Puede seguir el inicio rápido de Document Intelligence Studio para empezar. A continuación, puede integrar características de Document Intelligence con su propia aplicación mediante el código de ejemplo proporcionado.
Comience con el modelo de diseño. Debe seleccionar las siguientes opciones de Análisis para usar RAG en Studio:
**Required**- Ejecutar intervalo de análisis → Documento actual
- Intervalo de páginas → Todas las páginas
- Estilo de formato de salida → Markdown
**Optional**- También puede seleccionar los parámetros de detección opcionales pertinentes.
Seleccione Guardar.
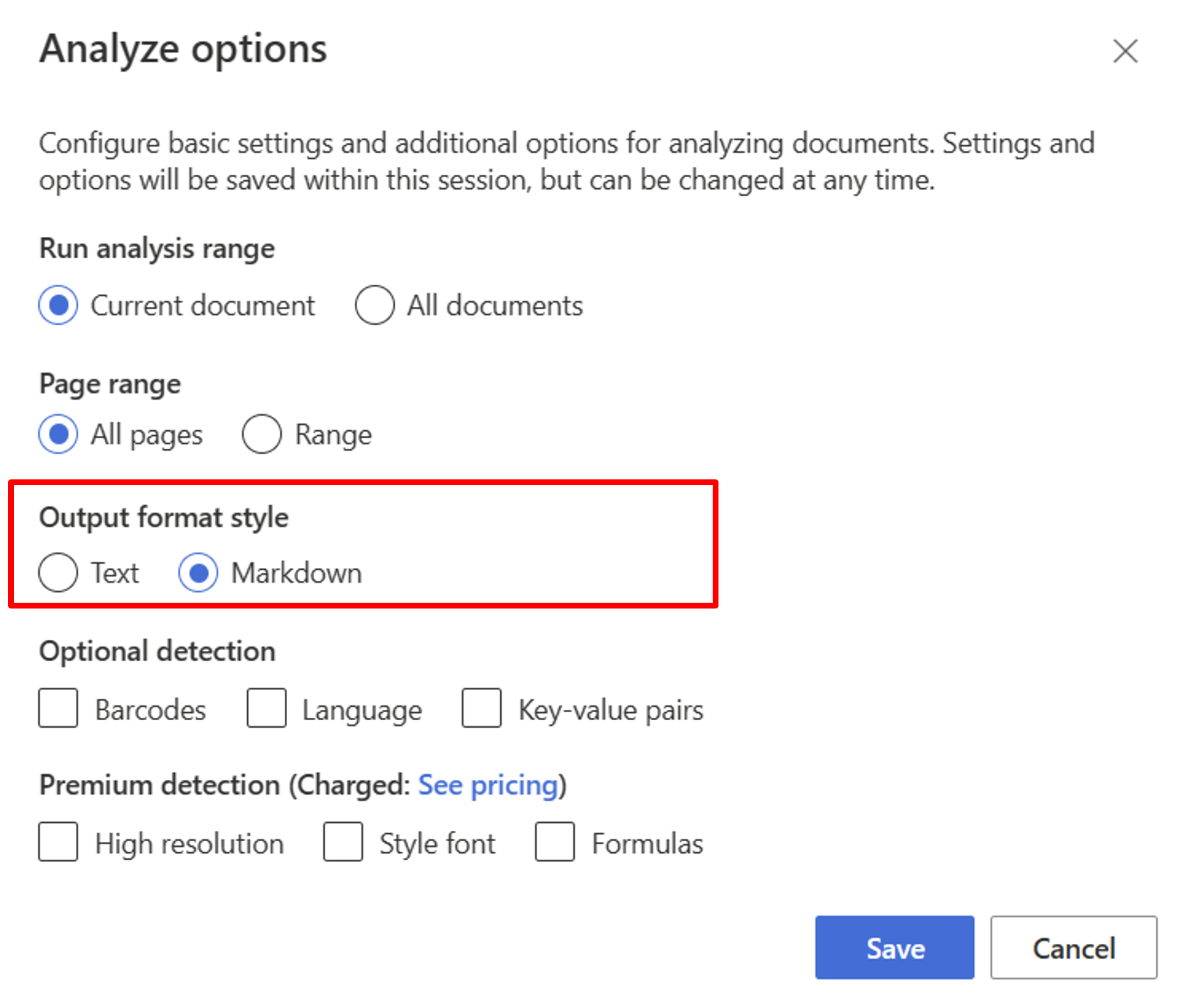
Seleccione el botón Ejecutar análisis para ver la salida.

SDK o API de REST
Puede seguir el inicio rápido de Document Intelligence para el SDK del lenguaje de programación o la API de REST que prefiera. Use el modelo de diseño para extraer el contenido y la estructura de los documentos.
También puede consultar repositorios de GitHub para obtener ejemplos de código y sugerencias para analizar un documento en formato de salida Markdown.
Creación de chat de documentos con fragmentación semántica
Azure OpenAI en los datos le permite ejecutar el chat admitido en los documentos. Azure OpenAI en los datos aplica el modelo de diseño de Document Intelligence para extraer y analizar los datos del documento fragmentando texto largo basado en tablas y párrafos. También puede personalizar la estrategia de fragmentación mediante scripts de ejemplo de Azure OpenAI ubicados en nuestro repositorio de GitHub.
Documento de inteligencia de Azure AI ahora se integra con LangChain como uno de sus cargadores de documentos. Puede usarlo para cargar fácilmente los datos y la salida en formato Markdown. Para obtener más información, consulte nuestro código de ejemplo donde se muestra una demostración sencilla para el patrón RAG con Documento de inteligencia de Azure AI como cargador de documentos y Azure Search como recuperador en LangChain.
El chat con el ejemplo de código del acelerador de soluciones de datos muestra un ejemplo de patrón RAG de línea base de un extremo a otro. Usa Búsqueda de Azure AI como recuperador y Documento de inteligencia de Azure AI para la carga de documentos y la fragmentación semántica.
Caso de uso
Si busca una sección específica en un documento, puede usar la fragmentación semántica para dividir el documento en fragmentos más pequeños en función de los encabezados de sección que le ayudarán a encontrar la sección que busca de forma rápida y sencilla:
# Using SDK targeting 2024-11-30 (GA), make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Pasos siguientes
Obtenga más información sobre Documento de inteligencia de Azure AI.
Aprenda a procesar sus propios formularios y documentos con Document Intelligence Studio.
Complete el inicio rápido de Documento de inteligencia y empiece a crear una aplicación de procesamiento de documentos en el lenguaje de desarrollo que prefiera.