Compilar y entrenar un modelo de extracción personalizado
Este contenido se aplica a: ![]() v4.0 (GA) | Versiones anteriores:
v4.0 (GA) | Versiones anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1
v2.1
Los modelos personalizados de Documento de inteligencia requieren un pequeño grupo de documentos de entrenamiento para empezar. Si tiene al menos cinco documentos, puede empezar a entrenar un modelo personalizado. Puede entrenar un modelo de plantilla personalizado (formulario personalizado) o un modelo neuronal personalizado (documento personalizado). Este documento le guía por el proceso de entrenamiento de los modelos personalizados.
Requisitos de entrada del modelo personalizado
En primer lugar, asegúrese de que el conjunto de datos de aprendizaje cumpla con los requisitos de entrada de Documento de inteligencia.
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
Sugerencias sobre los datos de aprendizaje
Siga estas sugerencias para optimizar aún más el conjunto de datos para el entrenamiento:
- Use documentos PDF basados en texto en lugar de documentos basados en imágenes. Los PDF escaneados se tratan como imágenes.
- Use ejemplos que tienen todos los campos completados para formularios con campos de entrada.
- Use formularios con valores distintos en cada campo.
- Use un conjunto de datos mayor (imágenes de 10 a 15) si las imágenes de formulario son de menor calidad.
Carga de los datos de aprendizaje
Una vez que recopile un conjunto de formularios o documentos para el entrenamiento, debe cargarlo en un contenedor de Azure Blob Storage. Si no sabe cómo crear una cuenta de almacenamiento de Azure con un contenedor, siga el inicio rápido de Azure Storage para Azure Portal. Puede usar el plan de tarifa gratis (F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción.
Vídeo: Entrenamiento del modelo personalizado
- Una vez recopilado y cargado el conjunto de datos de entrenamiento, está listo para entrenar el modelo personalizado. En el vídeo siguiente, creamos un proyecto y exploramos algunos de los aspectos básicos para lograr un etiquetado y entrenamiento correctos de un modelo.
Creación de un proyecto en Documento de inteligencia Studio
Documento de inteligencia Studio proporciona y orquesta todas las llamadas API necesarias para completar el conjunto de datos y entrenar el modelo.
Para empezar, vaya a Documento de inteligencia Studio. La primera vez que use Studio, debe inicializar la suscripción, el grupo de recursos y el recurso. A continuación, siga los requisitos previos para proyectos personalizados para configurar Studio para acceder a su conjunto de datos de entrenamiento.
En Studio, seleccione el mosaico Modelo de extracción personalizado y seleccione el botón Crear un proyecto.
En el cuadro de diálogo
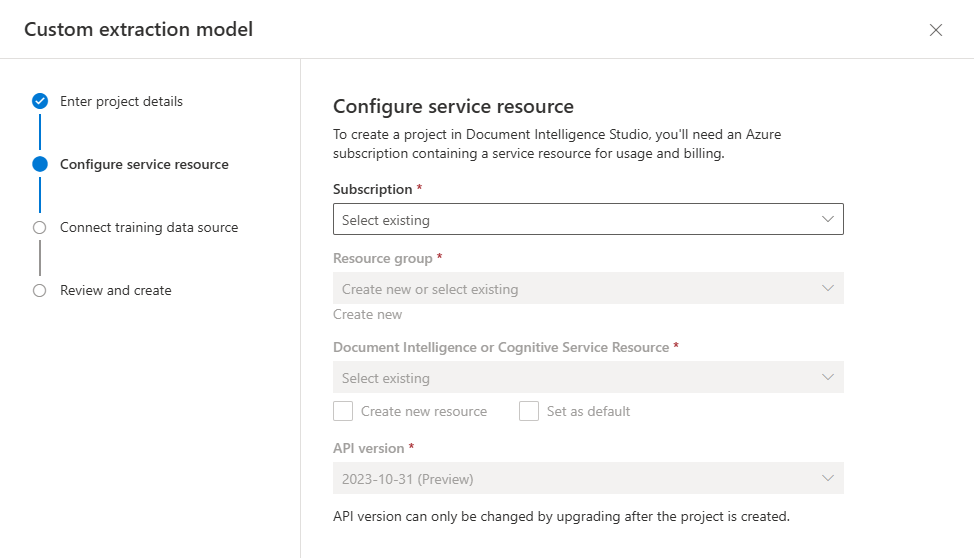
create project, proporcione un nombre para el proyecto, opcionalmente una descripción, y seleccione Continuar.En el paso siguiente del flujo de trabajo, elija o cree un recurso de Documento de inteligencia antes de seleccionar Continuar.
Importante
Los modelos neuronales personalizados solo están disponibles en algunas regiones. Si planea entrenar un modelo neuronal, seleccione o cree un recurso en una de estas regiones admitidas.
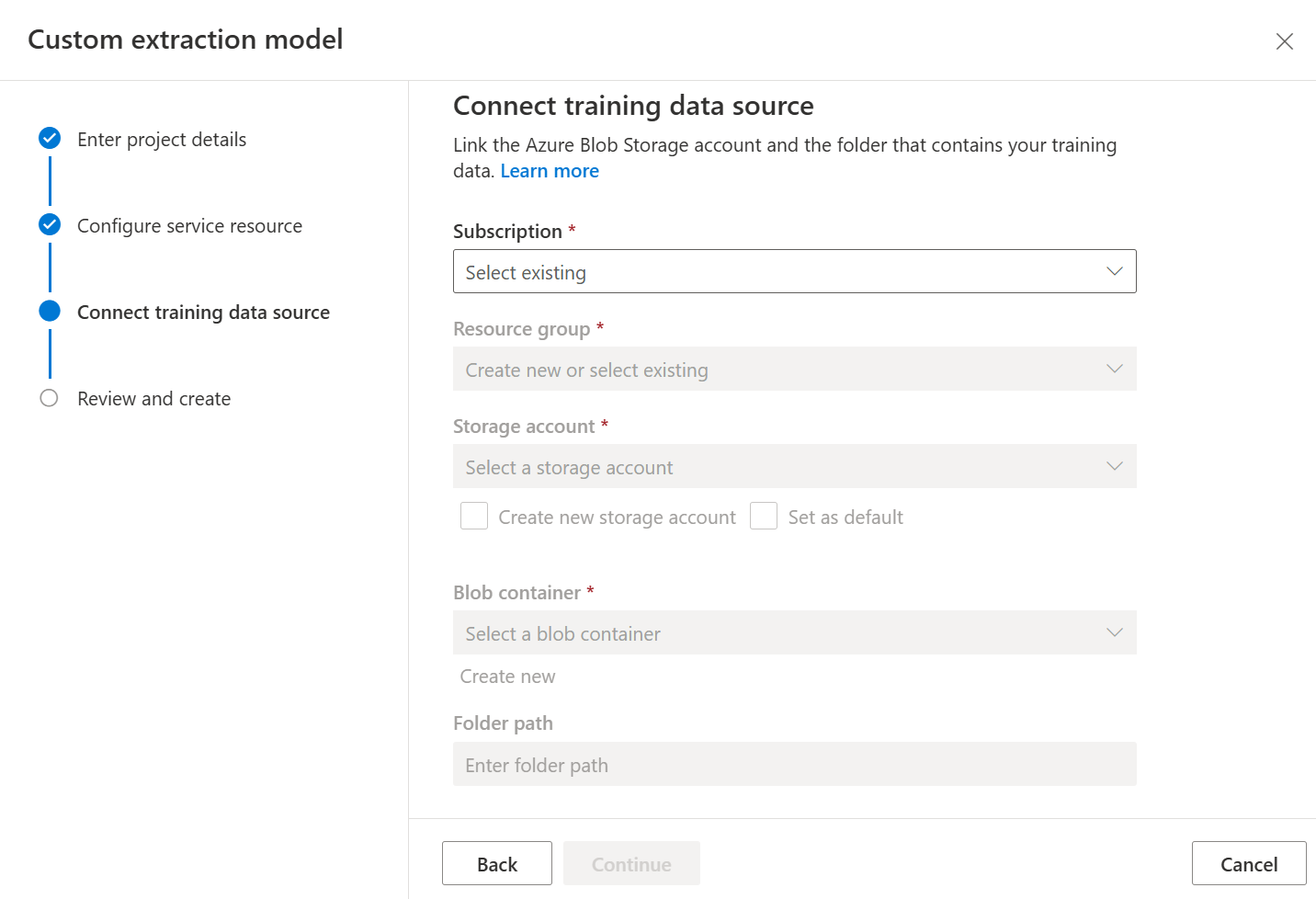
A continuación, seleccione la cuenta de almacenamiento que usó para cargar el conjunto de datos que desea utilizar para entrenar el modelo personalizado. La ruta de acceso a la carpeta debe estar vacía si los documentos de entrenamiento están en la raíz del contenedor. Si los documentos están en una subcarpeta, escriba la ruta de acceso relativa de la raíz del contenedor en el campo Ruta de acceso a la carpeta. Una vez configurada la cuenta de almacenamiento, seleccione Continuar.
Por último, revise la configuración del proyecto y seleccione Crear proyecto para crear un nuevo proyecto. Ahora debería estar en la ventana de etiquetado y ver los archivos del conjunto de datos enumerados.
Etiquetado de los datos
En el proyecto, la primera tarea consiste en etiquetar el conjunto de datos con los campos que desea extraer.
Los archivos que cargó en el almacén se enumeran a la izquierda de su pantalla, con el primer archivo listo para ser etiquetado.
Empiece a etiquetar el conjunto de datos y cree el primer campo seleccionando el botón más (➕) situado en la parte superior derecha de la pantalla.
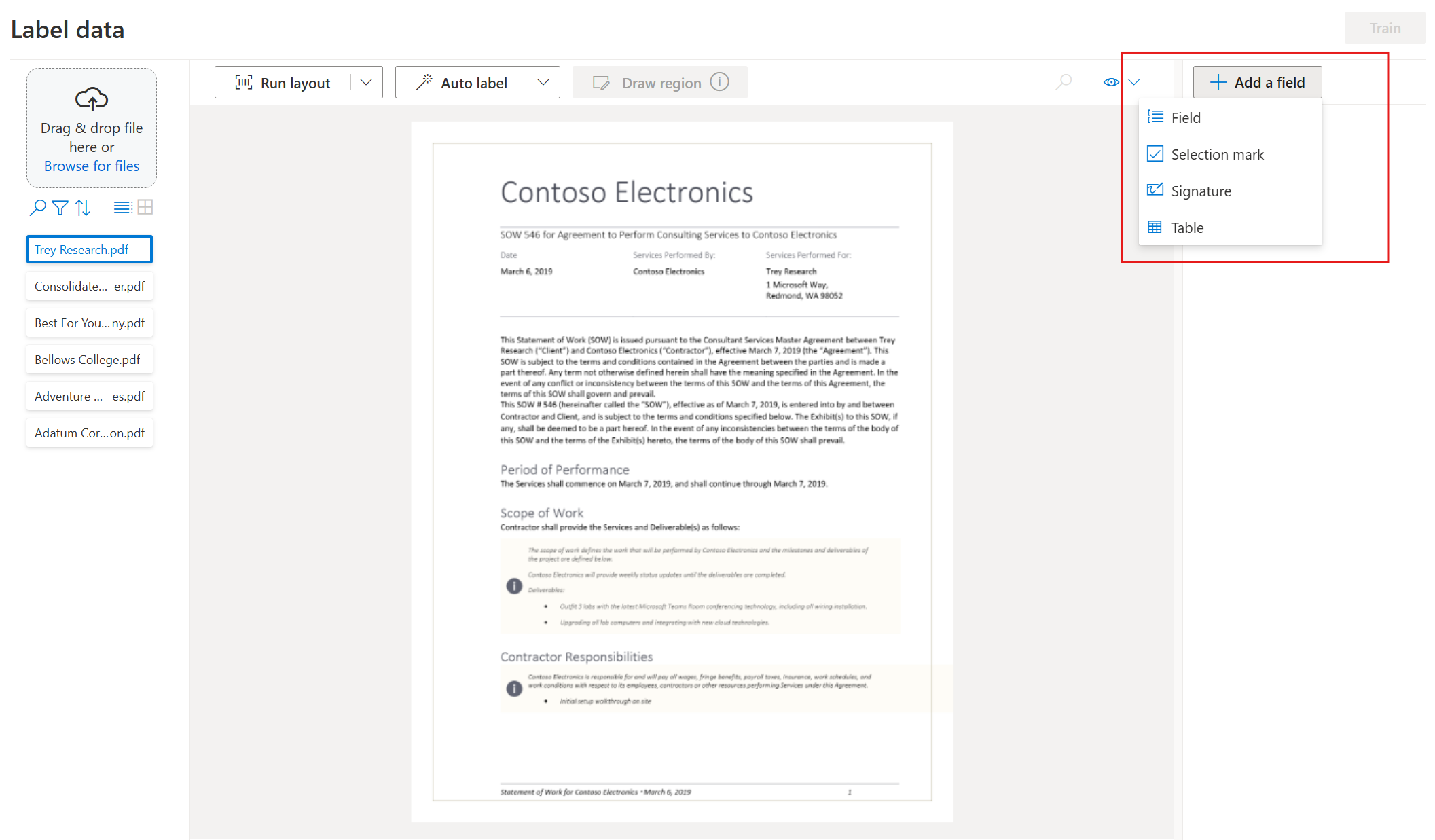
Escriba un nombre para el campo.
Asigne un valor al campo eligiendo una palabra o palabras en el documento. Seleccione el campo en la lista desplegable o en la lista de campos de la barra de navegación derecha. El valor etiquetado está debajo del nombre del campo en la lista de campos.
Repita el proceso para todos los campos que desea etiquetar para el conjunto de datos.
Etiquete los documentos restantes del conjunto de datos seleccionando cada documento y el texto que se va a etiquetar.
Ahora tiene todos los documentos del conjunto de datos etiquetados. Los archivos .labels.json y .ocr.json corresponden a cada documento del conjunto de datos de entrenamiento y un archivo fields.json nuevo. Este conjunto de datos de entrenamiento se envía para entrenar el modelo.
Entrenamiento de un modelo
Con el conjunto de datos etiquetado, ya está listo para entrenar el modelo. Seleccione el botón para entrenar en la esquina superior derecha.
En el cuadro de diálogo para entrenar el modelo, proporcione un identificador de modelo único y, opcionalmente, una descripción. El identificador del modelo acepta un tipo de datos de cadena.
Para el modo de compilación, seleccione el tipo de modelo que desea entrenar. Obtenga más información sobre los tipos de modelo y las funcionalidades.
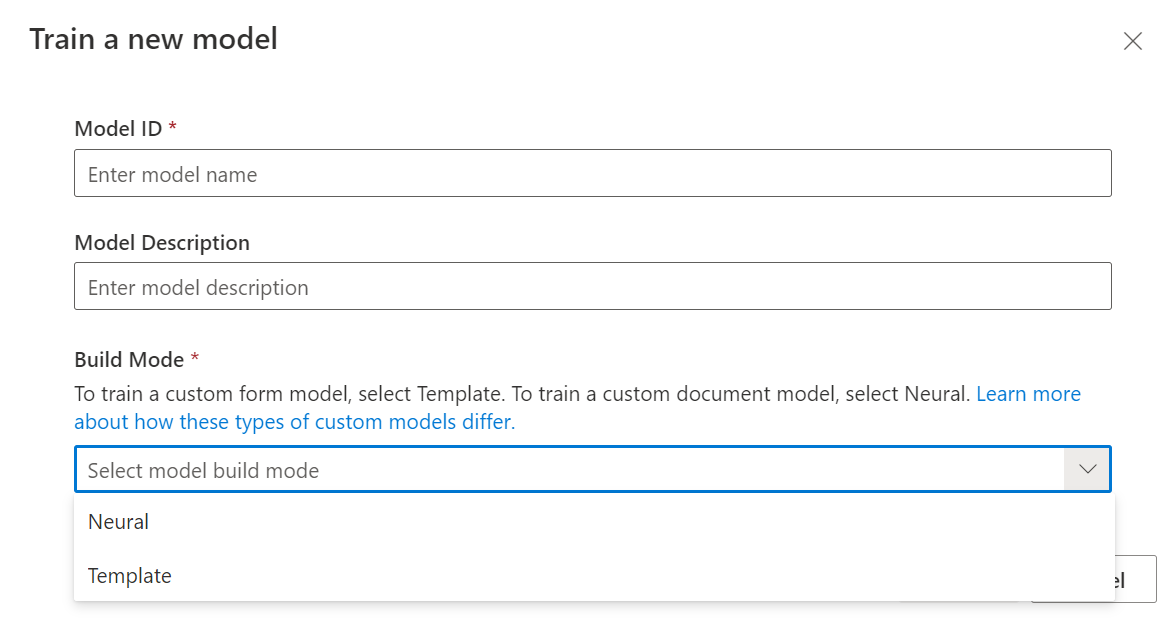
Seleccione Entrenar para iniciar el proceso de entrenamiento.
Los modelos de plantilla se entrenan en unos minutos. Los modelos neuronales pueden tardar hasta 30 minutos en entrenarse.
Vaya al menú Modelos para ver el estado de la operación de entrenamiento.
Prueba del modelo
Una vez completado el entrenamiento del modelo, puede probar el modelo seleccionándolo en la página de la lista de modelos.
Seleccione el modelo y haga clic en el botón Probar.
Seleccione el botón
+ Addpara seleccionar un archivo para probar el modelo.Con un archivo seleccionado, elija el botón Analizar para probar el modelo.
Los resultados del modelo se muestran en la ventana principal y los campos extraídos se muestran en la barra de navegación derecha.
Valide el modelo evaluando los resultados de cada campo.
La barra de navegación derecha también tiene el código de ejemplo para invocar el modelo y los resultados JSON de la API.
Enhorabuena, ha aprendido a entrenar un modelo personalizado en Document Intelligence Studio. El modelo está listo para usarse con la API REST o el SDK para analizar documentos.
Se aplica a: ![]() v2.1. Otras versiones: v3.0
v2.1. Otras versiones: v3.0
Cuando se usa el modelo personalizado de Documento de inteligencia, usted proporciona sus propios datos de entrenamiento a la operación Entrenar modelo personalizado, para que el modelo pueda entrenar según los formularios específicos del sector. Siga esta guía para obtener información sobre cómo recopilar y preparar los datos para entrenar el modelo de forma eficaz.
Necesita al menos cinco formas completadas del mismo tipo.
Si desea usar datos de entrenamiento etiquetados manualmente, debe empezar con al menos cinco formularios completados del mismo tipo. Podrá seguir usando formularios sin etiquetar además del conjunto de datos requerido.
Requisitos de entrada del modelo personalizado
En primer lugar, asegúrese de que el conjunto de datos de aprendizaje cumpla con los requisitos de entrada de Documento de inteligencia.
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-11-30 (GA), el tamaño total de los datos de entrenamiento es2GB con un máximo de 10 000 páginas.
Sugerencias sobre los datos de aprendizaje
Siga estas sugerencias para optimizar aún más el conjunto de datos para el entrenamiento.
- Use documentos PDF basados en texto en lugar de documentos basados en imágenes. Los PDF escaneados se tratan como imágenes.
- Use ejemplos que tengan todos sus campos rellenados para formularios completados.
- Use formularios con valores distintos en cada campo.
- Use un conjunto de datos mayor (imágenes de 10 a 15) para formularios completados.
Carga de los datos de aprendizaje
Una vez que recopile el conjunto de documentos para el entrenamiento, debe cargarlo en un contenedor de Azure Blob Storage. Si no sabe cómo crear una cuenta de almacenamiento de Azure con un contenedor, siga el inicio rápido de Azure Storage para Azure Portal. Use el nivel de rendimiento estándar.
Si desea usar datos etiquetados manualmente, cargue los archivos .labels.json y .ocr.json correspondientes a los documentos de entrenamiento. Puede usar la herramienta de etiquetado de ejemplo (o su propia interfaz de usuario) para generar estos archivos.
Organización de los datos en subcarpetas (opcional)
De manera predeterminada, la API Train Custom Model solo usa documentos de formularios que se encuentren en la raíz del contenedor de almacenamiento. Sin embargo, puede realizar el entrenamiento con los datos de las subcarpetas si lo especifica así en la llamada API. Por lo general, el cuerpo de la llamada Train Custom Model (Entrenar modelo personalizado) tiene el formato siguiente, donde <SAS URL> es la dirección URL de la firma de acceso compartido del contenedor:
{
"source":"<SAS URL>"
}
Si agrega el contenido siguiente al cuerpo de la solicitud, la API se entrena con los documentos ubicados en las subcarpetas. El campo "prefix" es opcional y limita el conjunto de datos de aprendizaje a los archivos cuyas rutas de acceso empiezan con la cadena determinada. Por lo tanto, un valor de "Test", por ejemplo, hace que la API examine solo los archivos o las carpetas que empiecen con la palabra Test (Prueba).
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Pasos siguientes
Ahora que ha aprendido a crear un conjunto de datos de entrenamiento, siga un inicio rápido para entrenar un modelo personalizado de Document Intelligence y empezar a usarlo en los formularios.