Interpretación y mejora de las puntuaciones de confianza de los análisis y de precisión de los modelos
Una puntuación de confianza indica la probabilidad midiendo el grado de certeza estadística de que el resultado extraído se detecta correctamente. La precisión estimada se calcula mediante la ejecución de varias combinaciones diferentes de los datos de entrenamiento para predecir los valores etiquetados. En este artículo, descubrirá cómo interpretar las puntuaciones de precisión y confianza, así como los procedimientos recomendados para usar esas puntuaciones con el fin de mejorar los resultados de precisión y confianza.
Puntuación de confianza
Nota:
- La confianza de nivel de campo incluye puntuaciones de confianza de palabras con la versión de API 2024-11-30 (GA) para modelos personalizados.
- Las puntuaciones de confianza de las tablas, las filas de tabla y las celdas de tabla están disponibles a partir de la versión de API 30-11-2024-versión preliminar para los modelos personalizados.
Los resultados del análisis de Document Intelligence devuelven la confianza estimada para las palabras, los pares clave-valor, las marcas de selección, las regiones y las firmas predichas. Actualmente, no todos los campos de documento devuelven una puntuación de confianza.
La confianza de campo indica una probabilidad estimada entre 0 y 1 de que la predicción es correcta. Por ejemplo, un valor de confianza de 0,95 (95 %) indica que la predicción es probablemente correcta 19 de cada 20 veces. En escenarios en los que la precisión es crítica, se puede usar la confianza para determinar si se acepta automáticamente la predicción o se le asigna una marca para revisión humana.
Modelo analizado de factura prefabricada de
Document Intelligence Studio
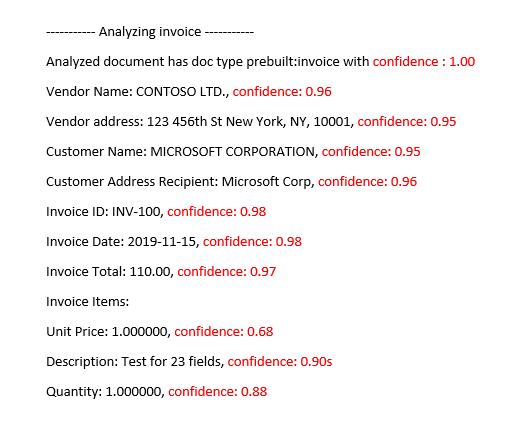
Mejorar las puntuaciones de confianza
Después de una operación de análisis, revise la salida JSON. Examine los valores de confidence de cada resultado de clave-valor en el nodo pageResults. También debe examinar las puntuaciones de confianza del nodo readResults, que se corresponden a la operación de lectura de texto. La confianza de los resultados de la lectura no afecta a la confianza de los resultados de la extracción de los pares clave-valor, por lo que debe comprobar ambos. Aquí encontrará algunas sugerencias:
Si la puntuación de confianza del objeto
readResultses baja, mejore la calidad de los documentos de entrada.Si la puntuación de confianza del objeto
pageResultses baja, asegúrese de que los documentos que está analizando sean del mismo tipo.Considere la posibilidad de incorporar la revisión humana a los flujos de trabajo.
Use formularios que tengan valores diferentes en cada campo.
Para los modelos personalizados, use un conjunto mayor de documentos de entrenamiento. Un conjunto de entrenamiento más grande enseña al modelo a reconocer campos con mayor precisión.
Puntuaciones de precisión para modelos personalizados
Nota:
- Los modelos neuronales y generativos personalizados no proporcionan puntuaciones de precisión durante el entrenamiento.
La salida de una operación de modelo personalizado (v3.0 y posterior) build o train (v2.1) incluye la puntuación de precisión estimada. Esta puntuación representa la capacidad del modelo para predecir con precisión el valor etiquetado en un documento visualmente similar. La precisión se mide dentro de un intervalo de valores porcentuales que va del 0 % (bajo) al 100 % (alto). Es mejor tener como destino una puntuación del 80 % o superior. Para casos más confidenciales, como los registros financieros o médicos, se recomienda una puntuación de cercana al 100 %. También puede agregar una fase de revisión humana para validar los flujos de trabajo de automatización más críticos.
Modelo personalizado entrenado (factura) de
Document Intelligence Studio
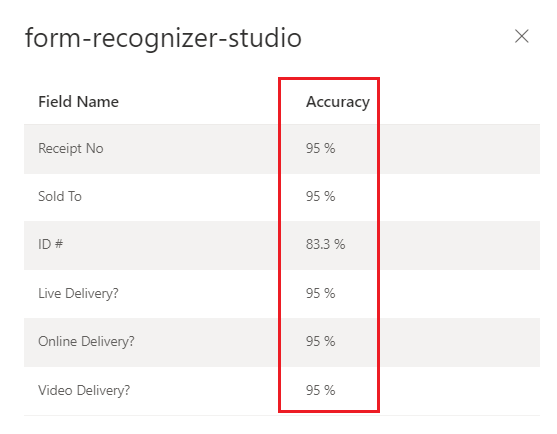
Interpretación de las puntuaciones de precisión y confianza para modelos personalizados
Los modelos de plantilla personalizados generan una puntuación de precisión estimada cuando se entrenan. Los documentos analizados con un modelo personalizado generan una puntuación de confianza para los campos extraídos. Al interpretar la puntuación de confianza de un modelo personalizado, debe tener en cuenta todas las puntuaciones de confianza devueltas del modelo. Comencemos con una lista de todas las puntuaciones de confianza.
- Puntuación de confianza del tipo de documento: la confianza del tipo de documento es un indicador de que el documento analizado se parece a los documentos del conjunto de datos de entrenamiento. Cuando la confianza del tipo de documento es baja, esto indica que hay variaciones estructurales o de plantilla en el documento analizado. Para mejorar la confianza del tipo de documento, etiquete un documento con esa variación específica y agréguelo al conjunto de datos de entrenamiento. Una vez que se vuelva a entrenar el modelo, debería estar mejor equipado para controlar esa clase de variaciones.
- Confianza de nivel de campo: cada campo etiquetado extraído tiene una puntuación de confianza asociada. Esta puntuación refleja la confianza del modelo en la posición del valor extraído. Al evaluar las puntuaciones de confianza, también debe examinar la confianza de extracción subyacente para generar una confianza completa para el resultado extraído. Evalúe los resultados de
OCRpara las marcas de extracción o selección de texto en función del tipo de campo para generar una puntuación de confianza compuesta para el campo. - Puntuación de confianza de palabra: cada palabra extraída dentro del documento tiene una puntuación de confianza asociada. La puntuación representa la confianza de la transcripción. La matriz de páginas contiene una matriz de palabras, y cada palabra tiene un intervalo y una confianza asociados. Los intervalos de los valores extraídos del campo personalizado coincidirán con los intervalos de las palabras extraídas.
- Puntuación de confianza de la marca de selección: la matriz de páginas también contiene una matriz de marcas de selección. Cada marca de selección tiene una puntuación de confianza que representa la confianza de la marca de selección y la detección de estado de selección. Cuando un campo etiquetado es una marca de selección, la confianza de selección del campo personalizado combinada con la confianza de la marca de selección es una representación precisa de la confianza general de que el campo se extrajo correctamente.
En la tabla siguiente se muestra cómo interpretar las puntuaciones de precisión y confianza para medir el rendimiento del modelo personalizado.
| Precisión | Confianza | Resultado |
|---|---|---|
| Alto | Alto | • El modelo funciona correctamente con las claves etiquetadas y los formatos de documento. • Tiene un conjunto de datos de entrenamiento equilibrado. |
| Alto | Bajo | • El documento analizado parece diferente del conjunto de datos de entrenamiento. • El modelo se beneficiaría del nuevo entrenamiento con al menos cinco documentos etiquetados más. • Estos resultados también podrían indicar una variación de formato entre el conjunto de datos de entrenamiento y el documento analizado. Considere la posibilidad de agregar un nuevo modelo. |
| Bajo | Alto | • Este resultado es más improbable. • Para obtener puntuaciones de precisión bajas, agregue más datos etiquetados o divida documentos visualmente distintos en varios modelos. |
| Bajo | Bajo | • Agregue más datos etiquetados. • Divida los documentos visualmente distintos en varios modelos. |
Garantizar una alta precisión del modelo para los modelos personalizados
Las variaciones de la estructura visual de los documentos afectan la precisión del modelo. Las puntuaciones de precisión notificadas pueden ser incoherentes cuando los documentos analizados difieren de los documentos usados en el entrenamiento. Tenga en cuenta que un conjunto de documentos puede tener un aspecto similar si lo ven personas y todo lo contrario en el caso de un modelo de IA. A continuación, se muestra una lista de los procedimientos recomendados para entrenar modelos con la máxima precisión. Seguir estas instrucciones debe generar un modelo con mayores puntuaciones de precisión y confianza durante el análisis y reducir el número de documentos marcados para revisión humana.
Asegúrese de que todas las variaciones de un documento se incluyen en el conjunto de datos de entrenamiento. Las variaciones incluyen formatos diferentes, por ejemplo, archivos PDF digitales frente a digitalizados.
Agregue al menos cinco muestras de cada tipo al conjunto de datos de entrenamiento si espera que el modelo analice ambos tipos de documentos PDF.
Separe los tipos de documento visualmente distintos para entrenar distintos modelos para modelos personalizados y modelos neuronales.
- Como regla general, si quita todos los valores especificados por el usuario y los documentos tienen un aspecto similar, debe agregar más datos de entrenamiento al modelo existente.
- Si los documentos no son similares, divida los datos de entrenamiento en carpetas diferentes y entrene un modelo para cada variación. A continuación, puede componer las distintas variaciones en un único modelo.
Asegúrese de que no tiene ninguna etiqueta extraña.
Asegúrese de que el etiquetado de región y firma no incluya el texto circundante.
Confianza de tabla, fila y celda
Estas son algunas preguntas comunes que deben ayudar a interpretar las puntuaciones de tabla, fila y celda:
P: ¿Puede darse una puntuación de confianza alta para las celdas, pero baja para la fila?
R: Sí. Los distintos niveles de confianza de la tabla (celda, fila y tabla) están designados para capturar la corrección de una predicción en ese nivel específico. Una celda con predicción correcta que pertenece a una fila con otras posibles faltas tendría una confianza de celda alta, pero la confianza de la fila sería baja. Del mismo modo, una fila correcta en una tabla que tenga problemas con otras filas tendría una confianza alta de la fila, mientras que la confianza general de la tabla sería baja.
P: ¿Cuál es la puntuación de confianza que se espera cuando se combinan las celdas? Dado que una combinación da como resultado un cambio del número de columnas identificadas, ¿cómo se ven afectadas las puntuaciones?
R: Independientemente del tipo de tabla, la expectativa de las celdas combinadas es que deben tener valores de confianza más bajos. Además, la celda que falta (al haberse combinado con una celda adyacente) también debe tener un valor NULL con confianza más baja. La reducción de estos valores puede depender del conjunto de datos de entrenamiento, debe mantenerse la tendencia general de la celda combinada y aquella que falta con puntuaciones más bajas.
P: ¿Cuál es la puntuación de confianza cuando un valor es opcional? ¿Debería esperarse una celda con un valor NULL y una puntuación de confianza alta si falta el valor?
R: Si el conjunto de datos de entrenamiento es representativo de la opcionalidad de las celdas, esto ayuda al modelo a saber con qué frecuencia tiende a aparecer un valor en el conjunto de entrenamiento y, por tanto, qué esperar durante la inferencia. Esta característica se usa al calcular la confianza de una predicción o de no hacer ninguna predicción en absoluto (NULL). Debe esperar un campo vacío con confianza alta para los valores ausentes que están principalmente vacíos también en el conjunto de entrenamiento.
P: ¿Cómo se ven afectadas las puntuaciones de confianza si un campo es opcional y no está presente o ausente? ¿Se espera que la puntuación de confianza responda a esa pregunta?
R: Cuando falta un valor de una fila, la celda tiene un valor NULL y cierta confianza asignados. Una puntuación de confianza alta aquí debe significar que es más probable que la predicción del modelo (de que no hay un valor) sea correcta. Por el contrario, una puntuación baja debe indicar una mayor incertidumbre del modelo (y, por tanto, la posibilidad de un error, como que falte el valor).
P: ¿Cuál debe ser la expectativa de confianza de celda y de fila al extraer una tabla de varias páginas con una fila dividida entre páginas?
R: Cabe esperar que la confianza de celda sea alta y que la confianza de fila sea posiblemente inferior a la de las filas que no se dividen. La proporción de filas divididas del conjunto de datos de entrenamiento puede afectar a la puntuación de confianza. En general, una fila dividida tiene un aspecto distinto al del resto de filas de la tabla (por lo tanto, es menos seguro que el modelo sea correcto).
P: En el caso de tablas en varias páginas con filas que terminan y comienzan claramente en los límites de la página, ¿es correcto suponer que las puntuaciones de confianza son coherentes entre las páginas?
R: Sí. Dado que el aspecto y contenido de las filas es similar, independientemente de dónde se encuentren en el documento (o en qué página), sus puntuaciones de confianza respectivas deben ser coherentes.
P: ¿Cuál es la mejor forma de usar las nuevas puntuaciones de confianza?
R: Examine todos los niveles de confianza de la tabla mediante un enfoque de arriba abajo: comience por comprobar la confianza de una tabla en su conjunto y, a continuación, profundice en el nivel de fila y examine las filas individuales para, por último, examinar la confianza del nivel de celda. En función del tipo de tabla, deben tenerse en cuenta un par de cosas:
En el caso de las tablas fijas, la confianza de nivel de celda ya captura bastante información sobre la corrección de distintos aspectos. Esto significa que solo pasar por cada celda y ver la confianza correspondiente puede ser suficiente para ayudar a determinar la calidad de la predicción. En el caso de las tablas dinámicas, los niveles están diseñados de forma que se basan uno sobre otro, por lo que el enfoque de arriba abajo es más importante.