kit de herramientas de Ciencia de datos: modelos de regresión logística
Para admitir la capacidad de nuestro cliente de predecir la respuesta del usuario a su publicidad digital, Xandr proporciona modelos personalizados basados en árboles de decisión. Hemos desarrollado un lenguaje de programación fácil de usar llamado Bonsai que permite a los usuarios crear árboles de decisión para rellenar dinámicamente los parámetros de elementos de línea.
Los árboles de decisión funcionan bien para modelos discretos sencillos que se asignan a formas de predicción tradicionales basadas en la segmentación, pero tienen dificultades para modelar de forma eficaz lo que equivale a una matriz dispersa de muchas dimensiones y grandes características categóricas. Bonsai es fácil de entender y fácil de usar, pero no siempre es suficiente para máquinas y científicos de datos, ya que no permite la representación eficaz de las relaciones entre características. Para estas necesidades más complejas, Xandr usa modelos de regresión logística.
La regresión logística es el enfoque básico para predecir la probabilidad de una respuesta binaria (hacer clic o no hacer clic; comprar o no comprar) a partir de una combinación de varias señales. Mediante el uso de los científicos de datos de regresión logística, los científicos pueden ejecutar modelos más expresivos que generan predicciones más precisas y que se pueden entrenar rápidamente a gran escala. Mediante la creación de algoritmos personalizados, los clientes con herramientas de ciencia de datos sofisticadas pueden lograr un mejor rendimiento que la optimización integrada proporcionada por Xandr y pueden ejecutar modelos sin conexión complejos en tiempo real.
Fórmula para la regresión logística
La regresión logística es un algoritmo de clasificación. Se usa para predecir un resultado binario (por ejemplo, hará clic, no hará clic) en función de un conjunto de variables independientes.
La fórmula para la regresión logística es:
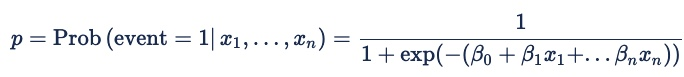
Donde la probabilidad (p) que se está modelando es la de un resultado binario: event = 1 o event = 0. Para la publicidad en línea, el evento es un clic, un disparo de píxeles u otra acción en línea. La probabilidad está condicional tanto en los predictores x1 a xn como en un conjunto implícito de variables que representan las características de una solicitud de puja. Los coeficientes beta son los pesos que el modelo asigna a los distintos predictores.
Convertimos esta probabilidad de que un evento se produzca en un valor esperado multiplicando la probabilidad por el valor del evento (por ejemplo, el objetivo de eCPC para una predicción de clics), agregando un desplazamiento aditivo a la estimación y, a continuación, aplicando límites de valor mínimo/máximo esperado para reducir el impacto de las predicciones erróneas.
La fórmula para derivar un valor esperado para una impresión a partir de la probabilidad de que se produzca un evento es:
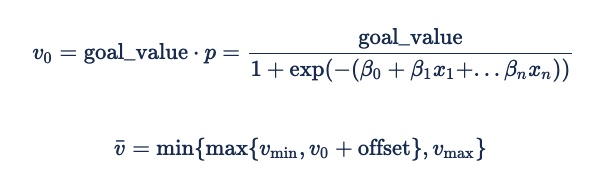
El desplazamiento suele ser 0. Sin embargo, un valor negativo puede ser útil como factor de seguridad para garantizar el rendimiento a costa de la entrega en el inventario de bajo rendimiento. Esto garantizará que el anunciante no puja en lugar de pujar muy poco y potencialmente incurrir en cuotas fijas.
Ejemplo de uso de características categóricas de la publicidad en línea
La publicidad en línea tiene muchas características categóricas, es decir, características que pueden tener muchos valores posibles. Algunos ejemplos incluyen explorador, dominio y día de la semana. Estas características suelen representarse con codificación "one-hot" (mediante "variables ficticias"), lo que significa que x1 sería 1 si "browser = safari" y 0 si no, x2 sería 1 si "browser = firefox", etc.
Si lo ponemos en la fórmula de regresión logística, obtenemos:

Dado que el explorador es una característica categórica, podemos expresar los coeficientes en una tabla:
| Explorador | Coeficiente |
|---|---|
| safari | 1.2 |
| firefox | 0.8 |
Cada fila de esta tabla se convierte en un término en la fórmula de regresión logística, por lo que x1 = 1 si "browser = safari" y β safari = 1,2 y x2 = 1 si "browser = firefox" y β firefox = 0,8. Esto hace que la ecuación general:
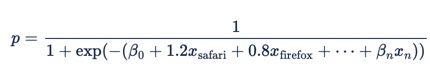
También se pueden expresar otras características categóricas de esta manera. Supongamos que asignamos los siguientes valores como coeficientes a los dominios siguientes:
| Dominio | Coeficiente |
|---|---|
| cnn.com | 2.1 |
| nytimes.com | 0.8 |
| yahoo.com | 0.3 |
A continuación, estos valores se convierten en términos incrementales en la fórmula (x3 es 1 si "dominio = cnn.com" y β 3 es 2,1), haciendo la ecuación general:

Cuando se envía la impresión del anuncio, Xandr identifica el explorador como Safari y el dominio como nytimes.com. Las variables correspondientes para browser = Safari y domain = nytimes.com se establecen en 1 y las demás variables se establecen en 0, lo que da como resultado la ecuación:
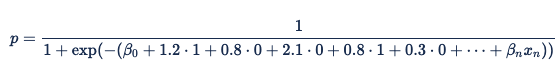
Predictores de orden superior
Xandr admite predictores de orden superior (combinaciones de características), lo que permite que los modelos personalizados controlen interacciones complejas entre los predictores. Comience con el ejemplo anterior calculando un valor en función de los valores categóricos de dominio y explorador. Ahora imagine que el dominio y el explorador no son independientes y que necesita modelar la relación entre ellos. Para ello, puede crear una característica categórica bidireccional con un coeficiente para cada par de características, utilizando los valores especificados en la tabla siguiente:
| Explorador | Dominio | Coeficiente |
|---|---|---|
| Safari | cnn.com | 1.1 |
| Safari | nytimes.com | 1.3 |
| Safari | yahoo.com | 1.2 |
| Firefox | cnn.com | 3.3 |
| Firefox | nytimes.com | 0.7 |
| Firefox | yahoo.com | 0,1 |
Cada uno de estos predictores emparejados se convierte en un término en la ecuación de regresión logística:
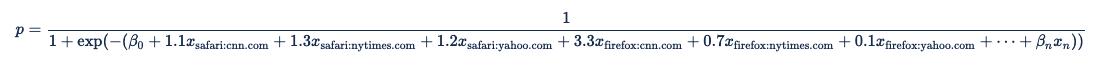
Predictores con hash
La combinación de varios predictores categóricos crea tablas extremadamente grandes que no se pueden asignar fácilmente a la memoria para un sistema en tiempo real. En lugar de intentar extraer valores de dichas tablas, puede aplicar hash a las combinaciones de características para crear colisiones, lo que reduce el número de combinaciones que deben asignarse a la memoria en tiempo real.
Ejemplo de predictores hash
Como ejemplo sencillo, puede aplicar hash a las combinaciones de explorador y dominio del ejemplo anterior mediante una función hash de 2 bits:
| Explorador | Dominio | Coeficiente |
|---|---|---|
| Safari | cnn.com | 0 |
| Safari | nytimes.com | 1 |
| Safari | yahoo.com | 3 |
| Firefox | cnn.com | 2 |
| Firefox | nytimes.com | 0 |
| Firefox | yahoo.com | 1 |
A continuación, calcule un coeficiente para cada valor hash. Tenga en cuenta que hay menos características que en el ejemplo anterior, lo que podría capturar parte de la interacción entre características sin requerir tanta memoria.
| hash de Browser-Domain | Coeficiente |
|---|---|
| 0 | 1.3 |
| 1 | 0.7 |
| 2 | 1,5 |
| 3 | 0.9 |
Una vez reemplazadas las variables por estos valores, la ecuación de regresión logística se convierte en:
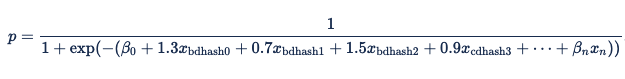
Para predecir la respuesta en una impresión determinada, Xandr aplica un hash a las características detectadas (con la misma función hash que se aplica durante la ingeniería de características para entrenar los modelos y la inferencia en línea). Para algunas características, usamos funciones hash para aplicar hash a los valores de características sin procesar en los que se usan en la fórmula anterior y ejecuta la predicción. Si el explorador es Safari y el dominio es nytimes.com (o cualquier otro par explorador-dominio que aplica hash al mismo valor), los aplicamos para buscar el valor 1 y sustituirlo en la ecuación de regresión logística:
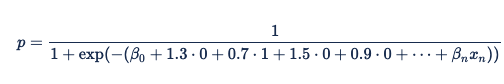
Conversión de vectores codificados y ponderados de un solo acceso a tablas
La codificación de las características categóricas garantiza que, para cada característica categórica, como máximo una variable recibirá el valor 1 y todo lo demás recibirá un valor de cero. El producto de punto del peso de las características del explorador y las variables del explorador es, por tanto, una manera de activar el peso predeterminado del explorador en la solicitud de puja. Digital Platform API usa la ecuación siguiente, que es una función sigmoid estándar:
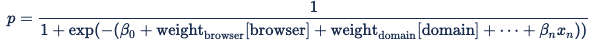
Si teníamos la siguiente solicitud de anuncio:
Si el tipo de explorador es Firefox, con la codificación de acceso único x_firefox se establecería en 1 y x_safari se establecería en 0. El peso activado para el tipo Firefox sería su peso predeterminado de 0,8 multiplicado por el valor codificado de 1. Por lo tanto , x_firefox sería igual a 0,8. El peso activado para el tipo Safari sería 0, es peso predeterminado, 1,2 multiplicado por el valor de x_safari de 0.
Obtendríamos una ecuación con la siguiente ponderación:
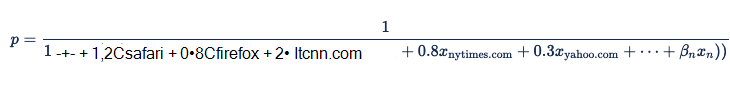
Para definir la asignación de una característica de categorías a una ponderación, Xandr usa llamadas API para crear y actualizar tablas de búsqueda. El propio modelo de regresión logística hará referencia a estas tablas y no a un vector de variables codificadas en un solo uso. El modelo también puede hacer referencia directamente a valores cardinales o reales, incluida la edad del segmento, el valor del segmento y la información de frecuencia o recencia de un anunciante, un creativo o un artículo de línea.
Introducción al proceso de ejemplo
Vamos a usar la información anterior para crear un flujo de trabajo de ejemplo.
Supongamos que ha configurado una campaña exploratoria para recopilar datos de entrenamiento con un presupuesto pequeño. Desea optimizar un elemento de línea de redestinación determinado para minimizar el costo por clic. Cada impresión ganada genera una fila en las fuentes de distribución de datos de nivel de registro con la is_click columna establecida en .false Cuando se genera finalmente un clic, se genera una fila idéntica en la fuente de distribución de datos con la is_click columna establecida en true. Los datos se particiona entre los conjuntos de entrenamiento, validación y pruebas examinando los últimos bits de user_id_64.
user_id_64 determina a qué parte se asignarán los datos. Finalmente, determina que las variables clave son:
- Explorador del usuario (categórico)
- País o región del usuario y día de la semana (categoría de orden superior)
- Combinación del publicador y el país o región del usuario (categoría de orden superior)
- La cantidad de tiempo transcurrido desde que se mostró por última vez un anuncio para ese anunciante a ese usuario (recencia del anunciante, un valor cardinal)
Dado que no hay muchos exploradores, es razonable tener un peso para cada explorador en el conjunto de entrenamiento. El producto cruzado y el país o región y el día de la semana también es razonablemente pequeño. Sin embargo, la combinación de publicador y país o región tiene una cardinalidad alta, por lo que decide entrenarla arbitrariamente con una tabla hash de 4096 entradas. Por último, la frecuencia diaria del elemento de línea es un valor cardinal.
Para cada fila de LLD, primero filtra las filas que no proceden de la campaña de entrenamiento. Ahora que ha definido los eventos que le interesan, puede extraer las variables:
- id. del explorador
- id. de país o región
- día de la semana del usuario (agregando el desplazamiento de la zona horaria a la marca de tiempo de la impresión y la asignación a una semana de 7 días)
- Id. del publicador
- anunciante, con un máximo de una hora (si este es el primer anuncio que se muestra a este usuario, la censura se establece de forma predeterminada en una hora)
Se reserva un identificador de característica para los identificadores de recency y 4096 para el hash (publisher:country/region) y se generan dinámicamente identificadores de características para cada explorador y par (país/región:día de la semana). La característica con hash necesita un paso más: tome los dos identificadores (publicador y país o región), escríbalos en un pequeño vector endian de 8 enteros de 32 bits y busque el cubo con MurmurHash3_x86_32(vector, 32, 0xC0FFEE) % 4096 (0xC0FFEE es una inicialización arbitraria). Esto le proporciona un vector (disperso) de valores de característica para cada fila, por lo que puede contar el número de impresiones y el número de clics para cada vector de este tipo.
Después de un día de impresiones de compra lenta, pruebe el modelo de regresión logística que entrenó en (un subconjunto de) LLD. El vector disperso de valores de característica es una codificación de un solo acceso al espacio de características. Debe volver a convertir de esta codificación a las funciones más lógicas de valor categórico a peso (tablas de búsqueda). Para ello, una la tabla de características al identificador de característica y el vector de ponderaciones para obtener lo siguiente:
| Característica | Índice | Peso |
|---|---|---|
| Censura del anunciante | 0 | -0.2 |
| publisher:country/region-bucket 0 | 1 | 1.4 |
| publisher:country/region-bucket 1 | 2 | -2.1 |
| ... | ... | ... |
| publisher:country/region-bucket 4095 | 4096 | -0.5 |
| browser=safari | 4097 | 5.2 |
| country/region:day-of-week=US:monday | 4098 | 0.7 |
| ... | ... | ... |
Determine los pesos de cada característica:
- Recencia del anunciante: lee el peso directamente desde el modelo entrenado.
- La tabla con hash: lee las ponderaciones de las características 4096 y las coloca en una matriz.
- Explorador: se recorre el mapa dinámico de la característica al identificador, las características son las claves y el identificador de los valores, y se crea una tabla de búsqueda desde el identificador del explorador hasta el peso distinto de cero (con cero como valor predeterminado) para crear una lista de asignaciones de explorador a ponderación.
- País o región:día de la semana: se recorre el mapa dinámico de la característica al identificador y se crea una tabla de búsqueda desde el identificador del explorador hasta el peso distinto de cero (con cero como valor predeterminado) para crear una lista de asignaciones de explorador a ponderación.
Estos son todos los datos que necesita para llamar a appnexus API.
Introducción al proceso de tiempo de la subasta
Una vez que el elemento de línea pasa la selección de destino, Xandr usa su modelo de regresión logística para determinar un precio de puja:
- Para cada tabla de búsqueda de su descripción, Xandr extrae los valores (o campos) del campo de la solicitud de puja y busca una entrada en la tabla. Si hay una entrada, ese valor se agrega al argumento lineal de la función logística. De lo contrario, se usa el valor predeterminado de la tabla, que suele ser 0.
- Lo mismo se hace para las tablas con hash, excepto que Xandr aplica un hash a los valores para buscar un cubo y, a continuación, busca ese cubo en la lista de cubos de la tabla hash:> asignaciones de valores. De nuevo, se usa el valor predeterminado si el valor especificado no aparece en la tabla.
- Por último, Xandr busca características de Bonsai. Realizamos la búsqueda de cada característica, multiplicamos por el peso y aplicamos límites mínimos/máximos.
- A continuación, Xandr suma los componentes y Beta0 y lo pasa a la función logística para calcular la probabilidad estimada de un clic. La probabilidad estimada se multiplica por el valor objetivo para obtener el valor esperado, que luego se fija entre 1 y 100 CPM para limitar cualquier valoración poco razonablemente alta.
- A continuación, Xandr usa el valor esperado y la cantidad de inventario disponible para calcular una oferta. Los cálculos exactos varían en función de la configuración del elemento de línea, pero el resultado es que Xandr reducirá automáticamente el valor esperado hasta que las pujas sean lo suficientemente altas como para que el elemento de línea gaste su presupuesto diario al final de cada día. Para obtener más información sobre este escalado, consulte Adaptive Pacing (inicio de sesión necesario) en la documentación.