Ciencia de datos Toolkit: servicio de modelo personalizado de regresión logística
El servicio de modelo personalizado de regresión logística permite crear modelos de regresión logística (a veces denominados "modelos logit") para predecir la probabilidad de clics o conversiones en función de una combinación de varias señales. A continuación, los modelos de regresión logística se pueden asociar a un elemento de línea mediante line item service - ALI (archivado).
Nota:
Esta oferta está actualmente en versión beta cerrada y está disponible para un conjunto limitado de clientes. Para obtener más información sobre el conjunto de herramientas de anuncios avanzados y los posibles casos de uso que pueden aplicarse a su empresa, póngase en contacto con el representante de su cuenta.
La fórmula para la regresión logística es:
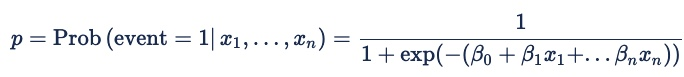
Para la publicidad en línea, el evento es un clic, un disparo de píxeles u otra acción en línea. La probabilidad está condicional tanto en los predictores x 1 a xn como en un conjunto implícito de variables que representan las características de una solicitud de puja. Los coeficientes beta son los pesos que el modelo asigna a diferentes predictores.
Convertimos esta probabilidad de que un evento se produzca en un valor esperado multiplicando la probabilidad por el valor del evento (el objetivo de eCPC para una predicción de clics), agregando un desplazamiento aditivo a la estimación y, a continuación, aplicando los límites de valor esperado mínimo/máximo para reducir el impacto de las interpretaciones erróneas.
La fórmula para derivar un valor esperado para una impresión a partir de la probabilidad de que se produzca un evento es:
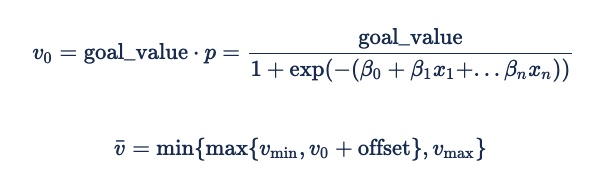
El desplazamiento suele ser 0. Sin embargo, un valor negativo puede ser útil como factor de seguridad para garantizar el rendimiento a costa de la entrega en el inventario de bajo rendimiento. Esto garantizará que el anunciante no puja, en lugar de pujar muy poco y potencialmente incurrir en cuotas fijas.
Para obtener más información sobre cómo funcionan los modelos personalizados de regresión logística, vea Modelos de regresión logística.
API de REST
Incorporación de un nuevo modelo de regresión logística
POST https://api.appnexus.com/custom-model-logit
(template JSON)
Modificación de un modelo de regresión logística
PUT https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
(template JSON)
Eliminación de un modelo de regresión logística
DELETE https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
Visualización de todos los modelos de regresión logística
GET https://api.appnexus.com/custom-model-logit
Visualización de un modelo de regresión logística específico
GET https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
Campos JSON
General
| Campo | Tipo | Description |
|---|---|---|
id |
Entero | Identificador del modelo personalizado de regresión logística. Valor predeterminado: número generado automáticamente Obligatorio en: PUT/ DELETE en la cadena de consulta |
name |
string | Nombre del modelo. |
beta0 |
float | β coeficiente 0 en la ecuación de regresión logística. |
max |
float | Máximo en la ecuación de valor esperado. |
min |
float | Mínimo en la ecuación de valor esperado. |
offset |
float | Desplazamiento en la ecuación de valor esperado. |
scale |
float | Escale en la ecuación de valor esperada. |
predictors |
matriz | Matriz de predictores. Consulte Predictores a continuación para obtener más detalles. |
Predictores
| Campo | Tipo | Description |
|---|---|---|
predictor_type |
scalar_descriptor, custom_model_descriptor, freq_rec_descriptor, segment_descriptor, categorical_descriptor |
|
keys |
||
hash_seed |
||
default_value |
||
hash_table_size_log |
||
coefficients |
Descriptor hash
Este punto de conexión es para enviar una tabla con hash previo. bucket_index0 y bucket_index1, cada 64 bits de largo, están ahí para admitir algoritmos hash que generan valores largos como claves. Actualmente, solo se admite un algoritmo hash: MurmurHash3_x64_128, que creará dos enteros de 64 bits, pero solo usamos los 64 bits inferiores del hash.
Los valores de bucket_index0 deben ser siempre más pequeños que (2 ^ hash_table_size_log) o se rechazarán.
Actualmente, los valores de bucket_index1 se omiten, ya que se usarán para la expansión futura. Si se envía un valor para bucket_index1, debe ser 0. El parámetro es opcional.
Claves de tabla hash
Para cada una de las claves de tabla hash, necesitará un valor uint32. Estos valores deben ser el identificador del objeto respectivo al que se hace referencia desde nuestro sistema: domain_id, por ejemplo, en lugar del valor de cadena de dominio. A continuación, estas claves uint32 se transforman en una matriz de bytes (little-endian) y se aplica un hash.
Ejemplo de Python
hash_bucket = (mmh3.hash64(bytes, seed)[ 0 ]) % table_size
| Campo | Tipo | Description |
|---|---|---|
type |
||
keys |
Matriz de uno a cinco descriptores en esta lista: | |
hashed_seeds |
Las semillas usadas cuando se pasan a Murmurhash3_x64_128 la función, solo se usa la primera por ahora, la matriz es para las funciones hash futuras planeadas que necesitan más de un valor de inicialización. |
|
hash_id |
Identificador de tabla hash existente | |
default_value |
Valor devuelto por el descriptor si no se encuentra ninguna coincidencia en la tabla hash | |
hash_table_size_log |
Registro del valor máximo de una clave de la tabla. Los valores mayores que 2^hash_table_size_log se rechazarán. El máximo para hash_table_size_log es 64 (sin cubo) |
Ejemplo de descriptor hash
{
"type": "hashed",
"keys": [
],
"hash_seeds": [42, 42, 42, 42, 42, 42],
"hash_id": ,
"default_value": 0,
"hash_table_size_log": 20
}
Descriptor de tabla de búsqueda (LUT)
| Campo | Tipo | Description |
|---|---|---|
type |
||
feature_keyword |
||
default_value |
||
initial_range_log |
||
bucket_count_log_per_range |
Ejemplo de descriptor de LUT
{
"type": "lookup",
"default_value": 0.1,
"features": [
{
"type": "categorical_descriptor",
"feature_keyword": "advertiser_id"
},
{
"type": "scalar_descriptor",
"feature_keyword": "user_age",
"default_value": 0
}
],
"coefficients": [
{'weight': 1.1, 'key': [1, 1]},
{'weight': 1.3, 'key': [2, 2]},
{'weight': 1.2, 'key': [3, 3]},
]
}
Descriptor categórico
Dado que se encuentra una coincidencia exacta, no se necesitan los default_valueparámetros y bucket_count_log_per_range . initial_range_log
Valores que faltan
El valor de clave de -1 se puede usar como marcador de posición para una característica que falta; Por ejemplo, cuando el vendedor no notifica un dominio. De lo contrario, se usará el valor predeterminado de LUT o el modelo hash, ya que no se encontrará ninguna coincidencia para ese valor de característica.
| Campo | Tipo | Description |
|---|---|---|
type |
||
feature_keyword |
- country- region- city- dma- postal_code- user_day- user_hour- os_family- os_extended- browser- language- user_gender- domain- ip_address- position- placement- placement_group- publisher- seller_member_id- supply_type- device_type- device_model- carrier- mobile_app- mobile_app_instance- mobile_app_bundle- appnexus_intended_audience- seller_intended_audience- spend_protection- user_group_id- advertiser_id- brand_category- creative- inventory_url_id- media_type |
|
default_value |
||
object_type |
Advertiser, li - ne_item, campaign (¿no dividido?) |
|
object_id |
Id. del anunciante al que se hace referencia, |
Ejemplo de descriptor categórico
{
"type": "categorical_descriptor",
"feature_keyword": "city"
}
Descriptor de frecuencia y recencia
| Campo | Tipo | Description |
|---|---|---|
type |
||
feature_keyword |
frequency_lifefrequency_dailyrecency |
|
default_value |
||
object_type |
Advertiser, line_item, campaign (¿no dividido?) |
|
object_id |
Id. del anunciante al que se hace referencia, | |
default_value |
Valor devuelto por el descriptor si no se encuentra ninguna coincidencia | |
initial_range_log |
Se usa para la creación de cubos de registros, intervalo inicial | |
bucket_count_log_per_range |
usado para el bucketing de registros, el número de cubos por intervalo |
Ejemplo de descriptor de frecuencia y recencia
{
"type": "frequency_recency_descriptor",
"feature_keyword": 'frequency_life',
"object_type": 'advertiser',
"object_id": 1,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
Descriptor escalar
| Campo | Tipo | Description |
|---|---|---|
type |
||
feature_keyword |
- appnexus_audited- cookie_age- estimated_average_price- estimated_clearing_price- predicted_iab_view_rate- predicted_video_completion_rate- self_audited- size- creative_size- spend_protection- uniform- user_ageNota: El descriptor de tamaño se representa como una cadena en los modelos ("300x250", por ejemplo), aunque se convierte en un escalar en el licitador. Cualquier tamaño es técnicamente válido en nuestro sistema, por lo que esta característica se trata como una característica escalar en lugar de una característica categórica. |
|
default_value |
Valor devuelto por el descriptor si no se encuentra ninguna coincidencia | |
initial_range_log |
Se usa para la creación de cubos de registros, intervalo inicial | |
bucket_count_log_per_range |
Se usa para el cubo de registros, el número de cubos por intervalo |
Ejemplo de descriptor escalar
{
"type": "scalar_descriptor",
"feature_keyword": "cookie_age",
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
Descriptor de segmento
| Campo | Tipo | Description |
|---|---|---|
type |
||
feature_keyword |
segment_valuesegment_agesegment_presence |
|
segment_id |
Identificador del segmento al que se hace referencia | |
default_value |
Valor devuelto por el descriptor si no se encuentra ninguna coincidencia | |
initial_range_log |
Se usa para la creación de cubos de registros, intervalo inicial | |
bucket_count_log_per_range |
Se usa para el cubo de registros, el número de cubos por intervalo |
Ejemplo de descriptor de segmento
{
"type": "segment_descriptor",
"feature_keyword": "segment_age",
"segment_id": 2,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}