"Ejercicio: Creación de un flujo de datos de asignación de Azure Data Factory"
Transformación de datos con el flujo de datos de asignación
Puede realizar transformaciones de datos de forma nativa con Azure Data Factory sin código mediante la tarea de flujo de datos de asignación. La asignación de flujos de datos proporciona una experiencia completamente visual que no requiere programación. Los flujos de datos se ejecutarán en su propio clúster de ejecución durante el procesamiento de datos de escalabilidad horizontal. Las actividades de flujo de datos pueden ponerse en marcha mediante las funcionalidades de programación, control, flujo y supervisión existentes en Data Factory.
Al compilar flujos de datos, puede habilitar el modo de depuración, que activa un pequeño clúster de Spark interactivo. Para activar el modo de depuración, alterne el control deslizante situado en la parte superior del módulo de creación. Los clústeres de depuración tardan unos minutos en prepararse, pero se pueden usar para obtener una vista previa interactiva de la salida de la lógica de transformación.

Una vez que se haya agregado el flujo de datos de asignación y se haya ejecutado el clúster de Spark, podrá realizar la transformación y ejecutar y obtener una vista previa de los datos. No se requiere ningún código, ya que Azure Data Factory controla toda la traducción de código, la optimización de rutas de acceso y la ejecución de los trabajos de flujo de datos.
Adición de los datos de origen al flujo de datos de asignación
Abra el lienzo del flujo de datos de asignación. Haga clic en el botón Agregar origen del lienzo del flujo de datos. En la lista desplegable de los conjuntos de datos de origen, seleccione el origen de datos. En este ejemplo, se usa el conjunto de datos de ADLS Gen2.
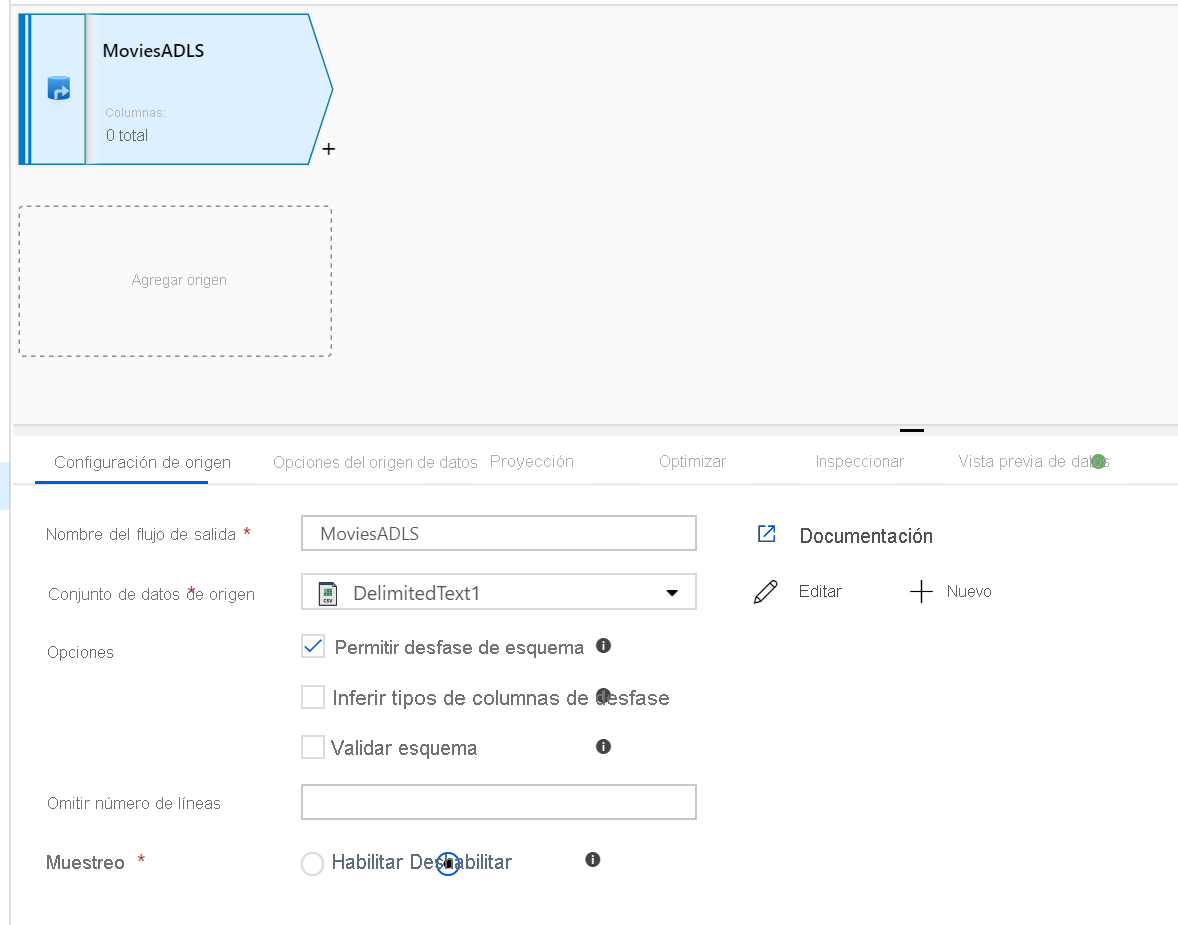
Hay un par de aspectos que deben tenerse en cuenta:
- Si el conjunto de datos apunta a una carpeta que contiene otros archivos y solo quiere utilizar un archivo, puede que deba crear otro conjunto de datos o usar la parametrización para asegurarse de que solo se lee un archivo en concreto.
- Si no ha importado el esquema en su instancia de ADLS pero ya ha ingerido los datos, vaya a la pestaña "Esquema" del conjunto de datos y haga clic en "Importar esquema" para que el flujo de datos conozca la proyección del esquema.
Mapping Data Flow sigue un enfoque de extracción, carga y transformación (ELT) y funciona con conjuntos de datos de un almacenamiento provisional que están todos en Azure. Actualmente, se pueden usar los siguientes conjuntos de datos en una transformación de origen:
- Azure Blob Storage (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Text, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Azure Data Factory tiene acceso a más de 80 conectores nativos. Para incluir datos de esos otros orígenes en el flujo de datos, use la herramienta de actividad de copia para cargar esos datos en una de las áreas de almacenamiento provisional compatibles.
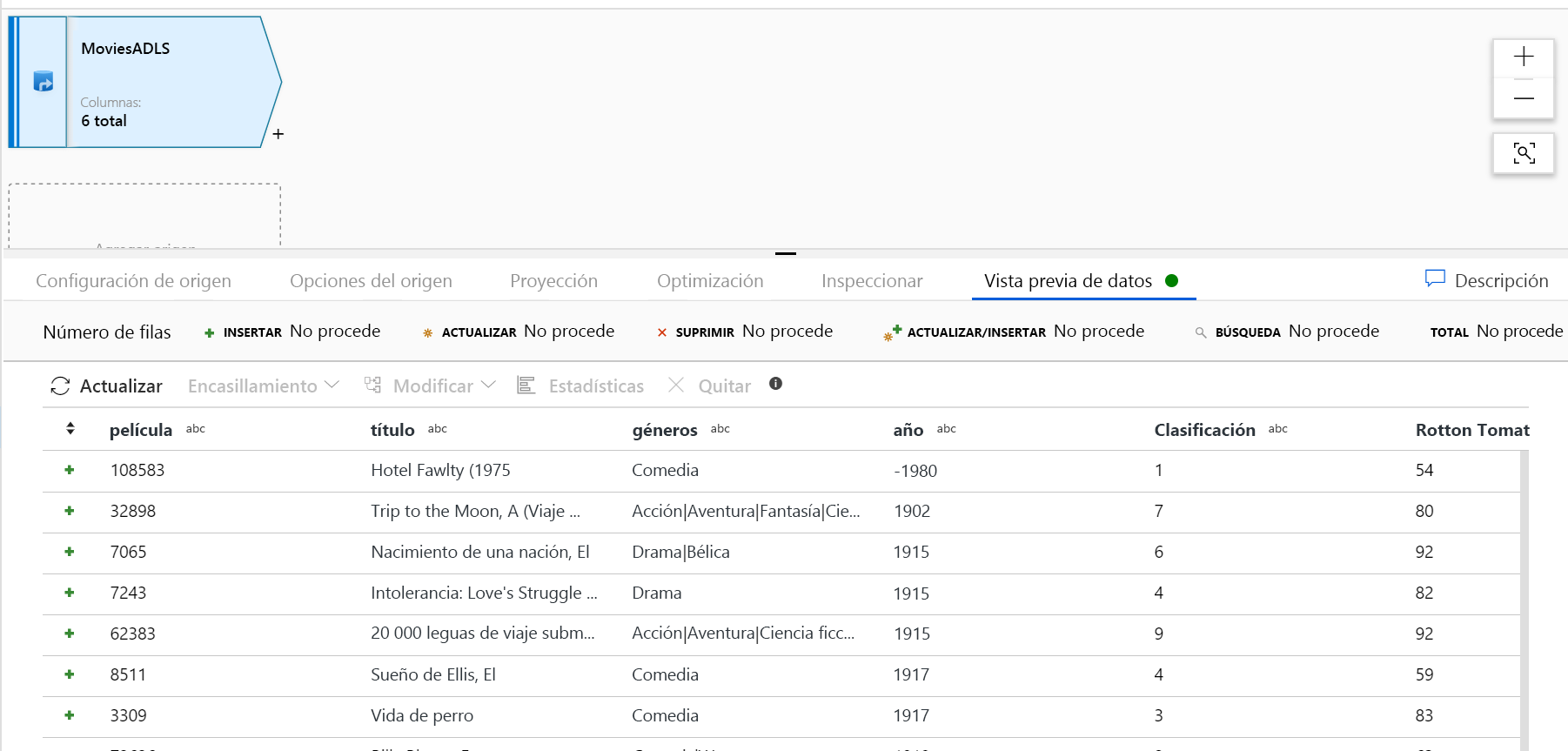
Una vez que se ha preparado el clúster de depuración, compruebe que los datos se hayan cargado correctamente mediante la pestaña Vista previa de datos. Al hacer clic en el botón Actualizar, el flujo de datos de asignación mostrará una instantánea del aspecto que tienen los datos en cada transformación.
Uso de las transformaciones en el flujo de datos de asignación
Ahora que ha movido los datos a Azure Data Lake Store Gen2, ya puede crear un flujo de datos de asignación que transformará los datos a escala mediante un clúster de Spark y, a continuación, los cargará en un almacenamiento de datos.
Las tareas principales de este proceso son las siguientes:
Preparación del entorno
Agregar un origen de datos
Uso de la transformación de flujo de datos de asignación
Escritura en un receptor de datos
Tarea 1: Preparación del entorno
Active la depuración del flujo de datos. Active el control deslizante Depurar el flujo de datos situado en la parte superior del módulo de creación.
Nota:
Los clústeres del flujo de datos tardan unos 5-7 minutos en prepararse.
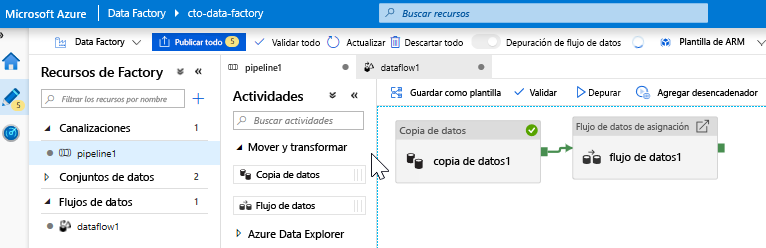
Adición de una actividad de flujo de datos. En el panel Actividades, abra el acordeón Mover y transformar y arrastre la actividad Flujo de datos al lienzo de la canalización. En la hoja que aparece, haga clic en Crear nuevo flujo de datos, seleccione Flujo de datos de asignación y, después, haga clic en Aceptar. Haga clic en la pestaña pipeline1 y arrastre el cuadro verde de la actividad de copia a la actividad de flujo de datos para crear una condición basada en el éxito. Verá lo siguiente en el lienzo:
Tarea 2: adición de un origen de datos
Agregue un origen de ADLS. Haga doble clic en el objeto Flujo de datos de asignación del lienzo. Haga clic en el botón Agregar origen del lienzo del flujo de datos. En la lista desplegable Conjunto de datos de origen, seleccione el conjunto de datos ADLSG2 usado en la actividad de copia.
- Si el conjunto de datos apunta a una carpeta que contiene otros archivos, puede que deba crear otro conjunto de datos o usar la parametrización para asegurarse de que solo se lee el archivo moviesDB.csv.
- Si no ha importado el esquema en su instancia de ADLS pero ya ha ingerido los datos, vaya a la pestaña "Esquema" del conjunto de datos y haga clic en "Importar esquema" para que el flujo de datos conozca la proyección del esquema.
Una vez que se ha preparado el clúster de depuración, compruebe que los datos se hayan cargado correctamente mediante la pestaña Vista previa de datos. Al hacer clic en el botón Actualizar, el flujo de datos de asignación mostrará una instantánea del aspecto que tienen los datos en cada transformación.
Tarea 3: Uso de la transformación de flujo de datos de asignación
Agregue una transformación de selección para cambiar el nombre de una columna y quitarla. En la vista previa de los datos, es posible que haya observado que la columna "Rotton Tomatoes" está mal escrita. Para asignarle el nombre correcto y quitar la columna de clasificación no usada, puede agregar una transformación de selección; para ello, haga clic en el icono + situado junto al nodo de origen de ADLS y elija Seleccionar en Modificador de esquema.
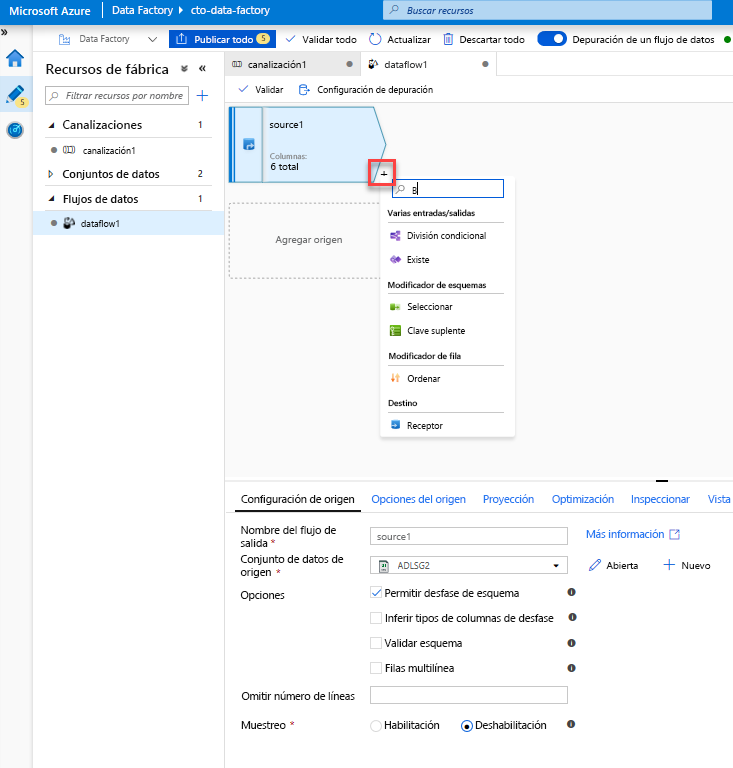
En el campo Nombrar como, cambie "Rotton" por "Rotten". Para quitar la columna de clasificación, mantenga el mouse sobre ella y haga clic en el icono de la papelera.
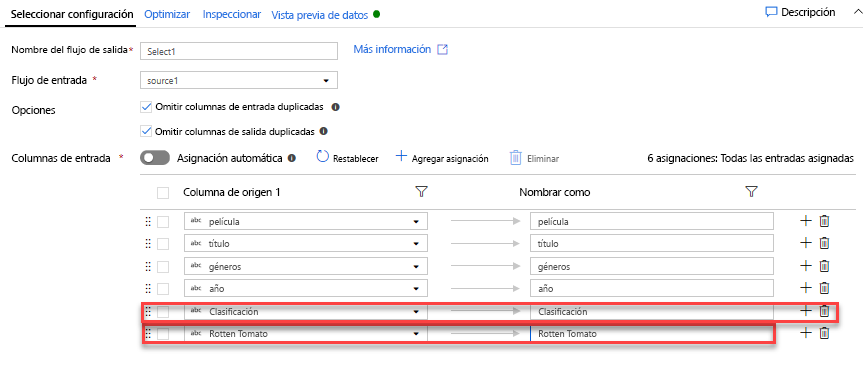
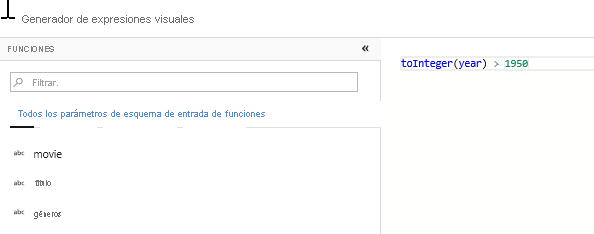
Agregue una transformación de filtro para filtrar los años no deseados. Supongamos que solo le interesan las películas realizadas después de 1951. Puede agregar una transformación de filtro para especificar una condición de filtro; para ello, haga clic en el icono + junto a la transformación de selección y elija Filtro en Modificador de fila. Haga clic en el cuadro de expresión para abrir el Generador de expresiones y escribir la condición de filtro. Con la sintaxis del lenguaje de expresiones de flujo de datos de asignación, toInteger(year) > 1950 convertirá el valor de año de la cadena en un entero y filtrará las filas si ese valor es superior a 1950.
Puede usar el panel de vista previa de datos incrustado del generador de expresiones para comprobar que la condición funciona correctamente.
Agregue una transformación de derivación para calcular el género principal. Como puede haber observado, la columna de géneros es una cadena delimitada por un carácter "|". Si solo le interesa el primer género de cada columna, puede derivar una nueva columna denominada PrimaryGenre mediante la transformación de columna derivada; para ello, haga clic en el icono + junto a la transformación de filtro y elija Derivado en Modificador de esquema. De forma similar a la transformación de filtro, la columna derivada usa el generador de expresiones de flujo de datos de asignación para especificar los valores de la nueva columna.

En este escenario, está intentando extraer el primer género de la columna de géneros, que tiene el formato "genre1 | genre2 |... | genreN". Utilice la función locate para obtener el primer índice de base 1 de "|" en la cadena de géneros. Mediante la función iif, si este índice es mayor que 1, el género principal se puede calcular mediante la función left, que devuelve todos los caracteres de una cadena a la izquierda de un índice. De lo contrario, el valor de PrimaryGenre es igual al campo de géneros. Puede comprobar la salida mediante el panel de vista previa de datos del generador de expresiones.
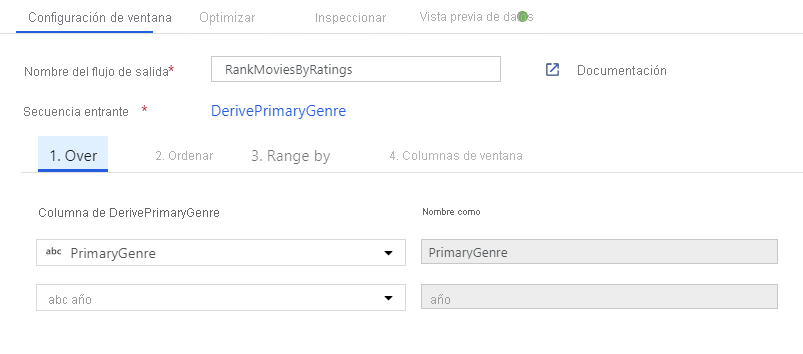
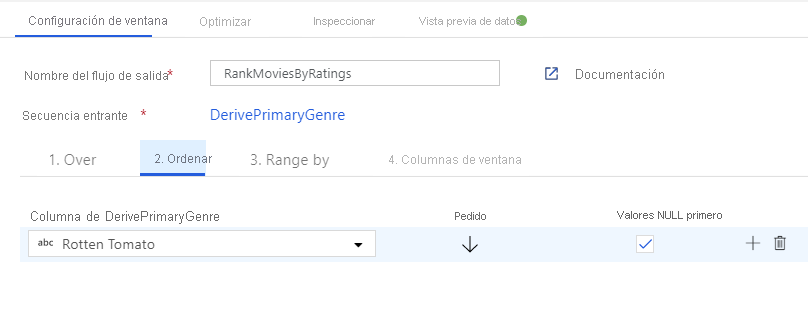
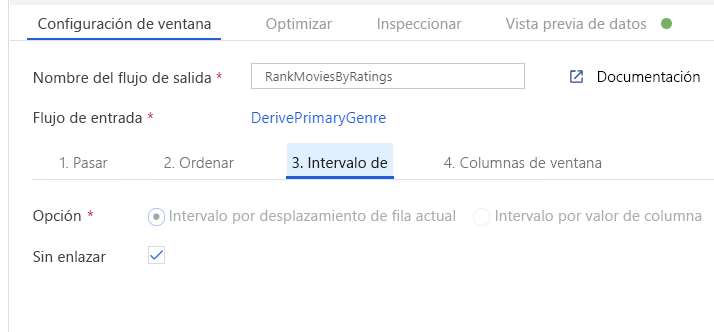
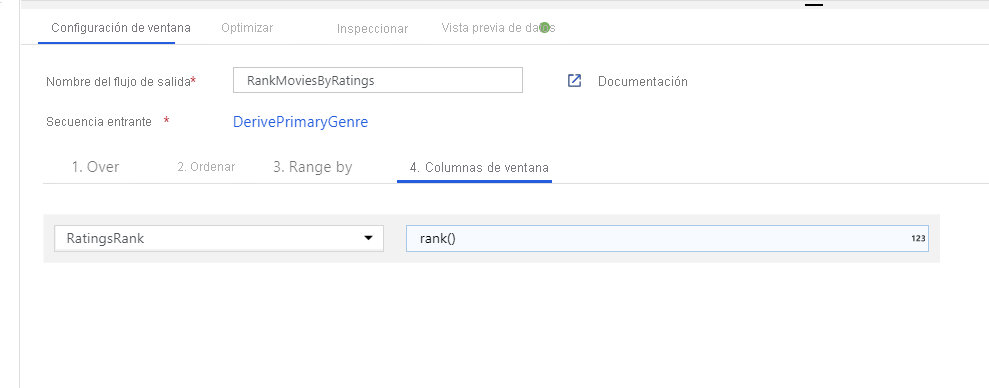
Clasifique las películas mediante una transformación de ventana. Imagine que le interesa la clasificación de una película dentro de su año y para su género específico. Puede agregar una transformación de ventana para definir agregaciones basadas en ventanas; para ello, haga clic en el icono + situado junto a la transformación de columna derivada y haga clic en Ventana en Modificador de esquema. Para ello, especifique de qué es lo que está realizando la ventana, qué determina el orden, cuál es el intervalo y cómo calcular las nuevas columnas de la ventana. En este ejemplo, se realizará la ventana de PrimaryGenre y año con un intervalo sin enlazar, ordenados por Rotten Tomato en orden descendente, y se calculará una nueva columna denominada RatingsRank que sea igual a la clasificación de cada película en su género y año específicos.
Agregue las clasificaciones con una transformación de agregado. Ahora que ha recopilado y derivado todos los datos necesarios, puede agregar una transformación de agregado para calcular las métricas en función de un grupo deseado; para ello, haga clic en el icono + situado junto a la transformación de ventana y haga clic en Agregar en Modificador de esquema. Como hizo en la transformación de ventana, agrupe las películas por PrimaryGenre y año.
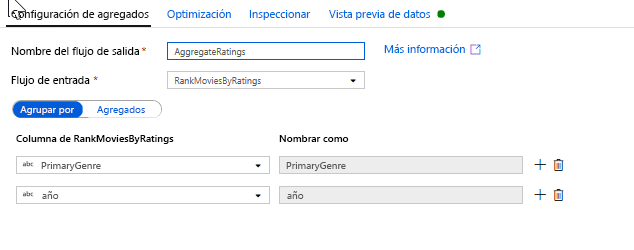
En la pestaña Agregados, puede crear las agregaciones calculadas en las columnas Agrupar por. Para cada género y año, obtenga la clasificación media de Rotten Tomatoes, la película mejor y peor clasificada (mediante la función de ventana) y el número de películas que hay en cada grupo. La agregación reduce significativamente el número de filas del flujo de transformación y solo propaga las columnas Agrupar por y Agregar especificadas en la transformación.
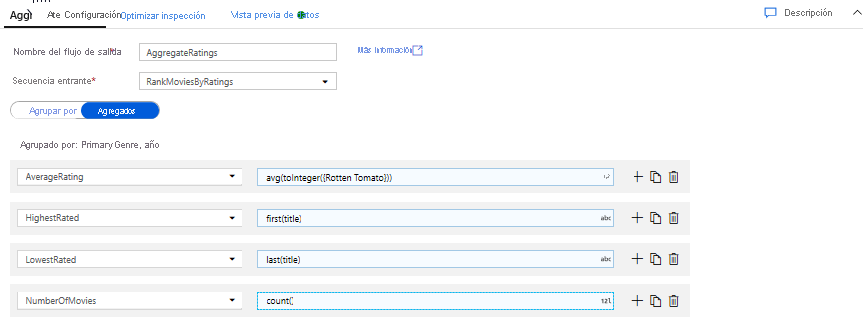
- Para ver cómo la transformación de agregado cambia los datos, use la pestaña Vista previa de datos.
Especifique una condición upsert mediante una transformación de modificación de fila. Si va a escribir en un receptor tabular, puede especificar directivas insert, delete, update y upsert en las filas mediante la transformación de modificación de fila; para ello, haga clic en el icono + situado junto a la transformación de agregado y haga clic en Modificar fila en Modificador de fila. Dado que siempre se insertan y actualizan, se puede especificar que todas las filas siempre sean upsert.

Tarea 4: escritura en un receptor de datos
- Escriba en un receptor de Azure Synapse Analytics. Ahora que ha finalizado toda la lógica de transformación, ya puede escribir en un receptor.
Agregue un Receptor; para ello, haga clic en el icono + situado junto a la transformación de upsert y haga clic en Receptor en Destino.
En la pestaña Receptor, cree un nuevo conjunto de datos de almacenamiento de datos mediante el botón + Nuevo.
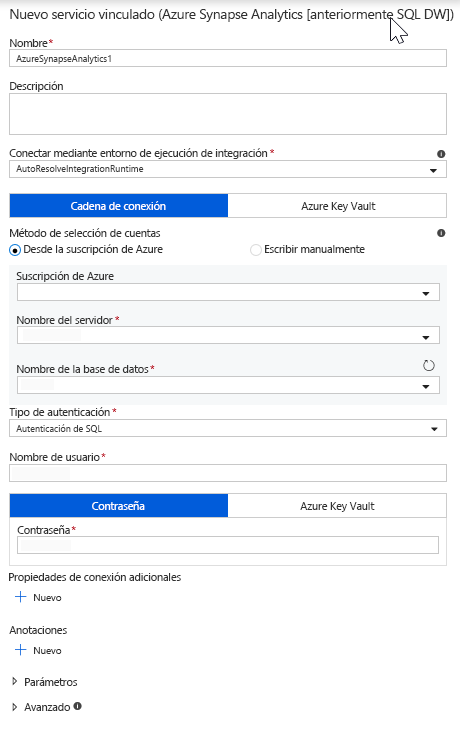
Seleccione Azure Synapse Analytics en la lista de mosaicos.
Seleccione un nuevo servicio vinculado y configure la conexión de Azure Synapse Analytics para conectarse a la base de datos de DWDB. Cuando haya terminado, haga clic en Create (Crear).
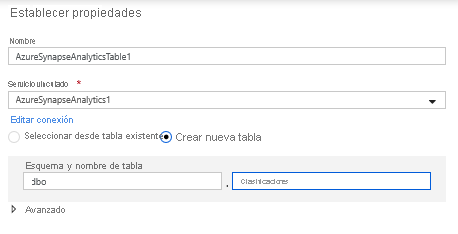
En la configuración del conjunto de datos, seleccione Crear nueva tabla y escriba el esquema de dbo y el nombre de tabla de Clasificaciones. Haga clic en Aceptar una vez haya finalizado.
Dado que se especificó una condición upsert, debe ir a la pestaña Configuración y seleccionar "Permitir upsert" en función de las columnas de clave PrimaryGenre y año.
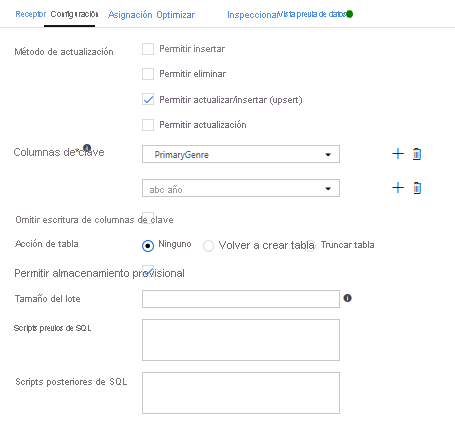
Llegados a este punto, ha terminado de crear el flujo de datos de asignación de 8 transformaciones. Es el momento de ejecutar la canalización y ver los resultados.

Tarea 5: ejecución de la canalización
Vaya a la pestaña pipeline1 del lienzo. Dado que Azure Synapse Analytics en el flujo de datos usa PolyBase, debe especificar un blob o una carpeta de almacenamiento provisional de ADLS. En la pestaña de configuración de Execute Data Flow activity (Ejecutar la actividad de flujo de datos), abra el acordeón de PolyBase, seleccione el servicio vinculado de ADLS y especifique una ruta de acceso de la carpeta de almacenamiento provisional.
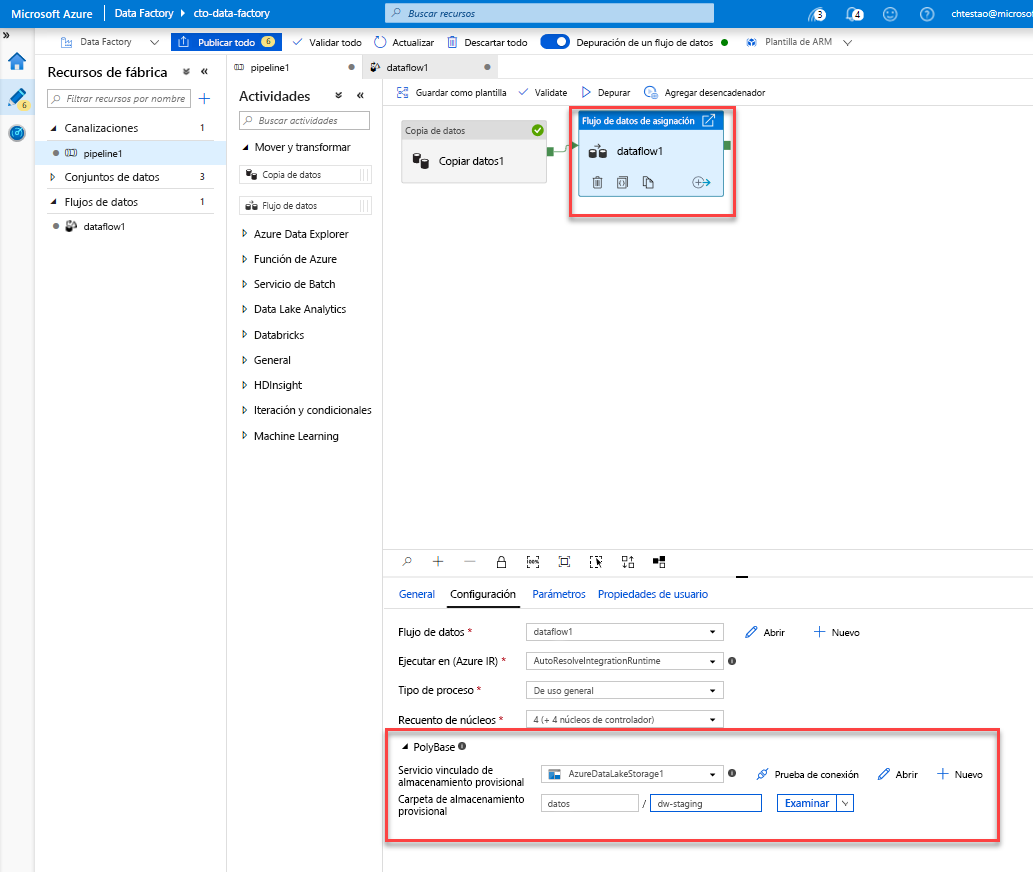
Antes de publicar la canalización, realice otra ejecución de depuración para confirmar que funciona según lo previsto. En la pestaña Salida, puede supervisar el estado de ambas actividades a medida que se ejecutan.
Cuando ambas actividades se hayan realizado correctamente, puede hacer clic en el icono de anteojos junto a la actividad de flujo de datos para obtener una visión más detallada de la ejecución del flujo de datos.
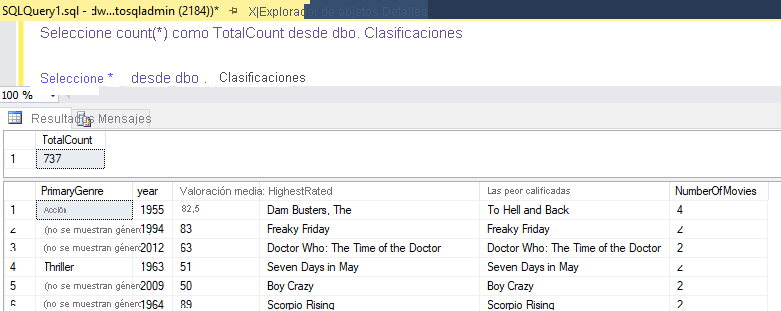
Si ha usado la misma lógica que se describe en este laboratorio, el flujo de datos escribirá 737 filas en el almacenamiento de datos SQL. Puede entrar en SQL Server Management Studio para comprobar que la canalización funcionó correctamente y ver lo que se escribió.