Transformación Agregar en Asignación de Data Flow
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Los flujos de datos están disponibles en las canalizaciones Azure Data Factory y Azure Synapse. Este artículo se aplica a los flujos de datos de asignación. Si carece de experiencia con las transformaciones, consulte el artículo de introducción Transformación de datos mediante flujos de datos de asignación.
En la transformación Agregar se definen las agregaciones de columnas de flujos de datos. Mediante el Generador de expresiones, puede definir diferentes tipos de agregaciones, tales como SUM, MIN, MAX y COUNT agrupados por columnas calculadas o existentes.
Agrupar por
Seleccione una columna existente o cree una nueva columna calculada para usarla como una cláusula Agrupar por para la agregación. Para usar una columna existente, selecciónela en la lista desplegable. Para crear una nueva columna calculada, mantenga el mouse sobre la cláusula y haga clic en Columna calculada. Se abrirá el generador de expresiones de flujo de datos. Una vez creada la columna calculada, escriba el nombre de la columna de salida en el campo Name as (Nombre como). Si desea agregar una cláusula Agrupar por adicional, mantenga el mouse sobre una cláusula existente y haga clic en el icono "más".
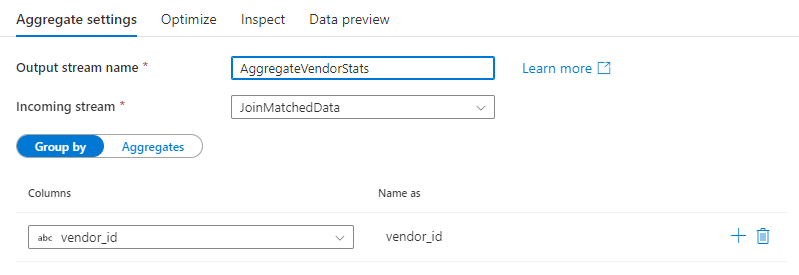
Una cláusula Agrupar por es opcional en una transformación Agregar.
Columnas agregadas
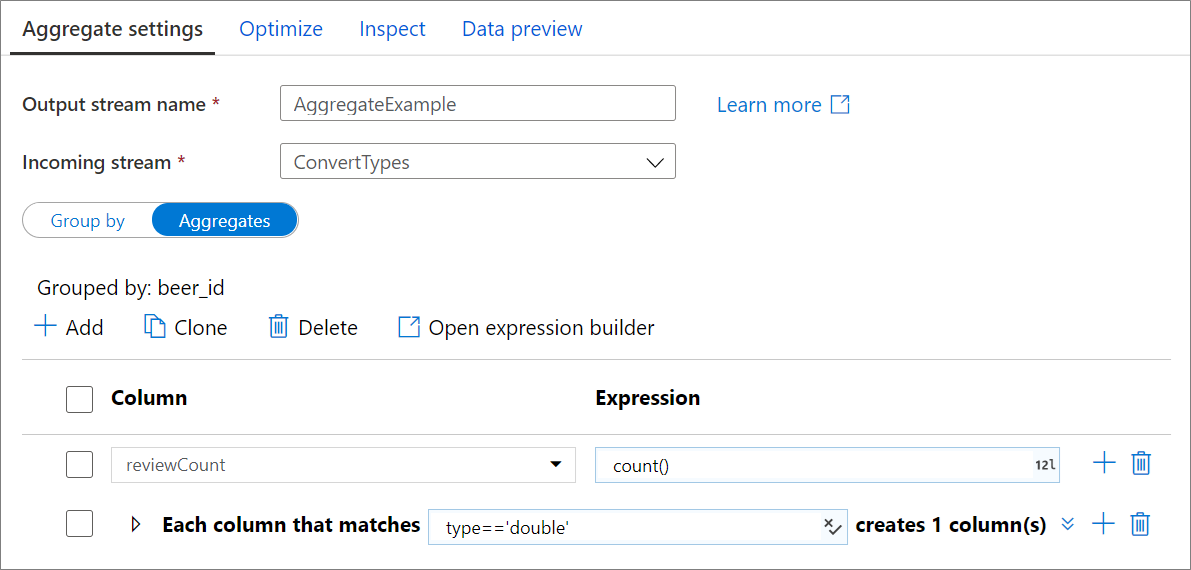
Vaya a la pestaña Agregados para generar las expresiones de agregación. Puede sobrescribir una columna existente con una agregación, o bien crear un campo nuevo con un nombre nuevo. La expresión de agregación se escribirá en el cuadro de la derecha, junto al selector de nombre de columna. Para editar la expresión, haga clic en el cuadro de texto y abra el generador de expresiones. Para agregar más columnas agregadas, haga clic en Agregar encima de la lista de columnas o en el icono de signo más junto a una columna agregada existente. Elija Agregar columna o Add column pattern (Agregar patrón de columna). Cada expresión de agregación debe contener al menos una función de agregado.
Nota
En el modo Depurar, el Generador de expresiones no puede generar vistas previas de los datos con las funciones de agregado. Para ver las vistas previas de los datos para las transformaciones Agregar, cierre el Generador de expresiones y vea los datos a través de la pestaña "Vista previa de los datos".
Patrones de columnas
Utilice patrones de columna para aplicar la misma agregación a un conjunto de columnas. Esto resulta útil si desea que persistan muchas columnas del esquema de entrada, ya que se anulan de manera predeterminada. Use una heurística como first() para que las columnas de entrada persistan en la agregación.
Reconexión de filas y columnas
Las transformaciones Agregar son similares a las consultas de selección de agregado de SQL. Las columnas que no estén incluidas en la cláusula Agrupar por o en las funciones de agregado no fluirán a través de la salida de la transformación Agregar. Si desea incluir otras columnas en la salida agregada, siga uno de estos métodos:
- Use una función de agregado como
last()ofirst()para incluir esa columna adicional. - Vuelva a unir las columnas al flujo de salida con el patrón self join.
Eliminación de filas duplicadas
Un uso común de la transformación de agregados es quitar o identificar entradas duplicadas en los datos de origen. Este proceso se conoce como desduplicación. En función de un conjunto de claves Group by, utilice una heurística de su elección para determinar qué fila duplicada desea conservar. Las heurísticas comunes son first(), last(), max() y min(). Use patrones de columna para aplicar la regla a todas las columnas excepto para las columnas Group by.
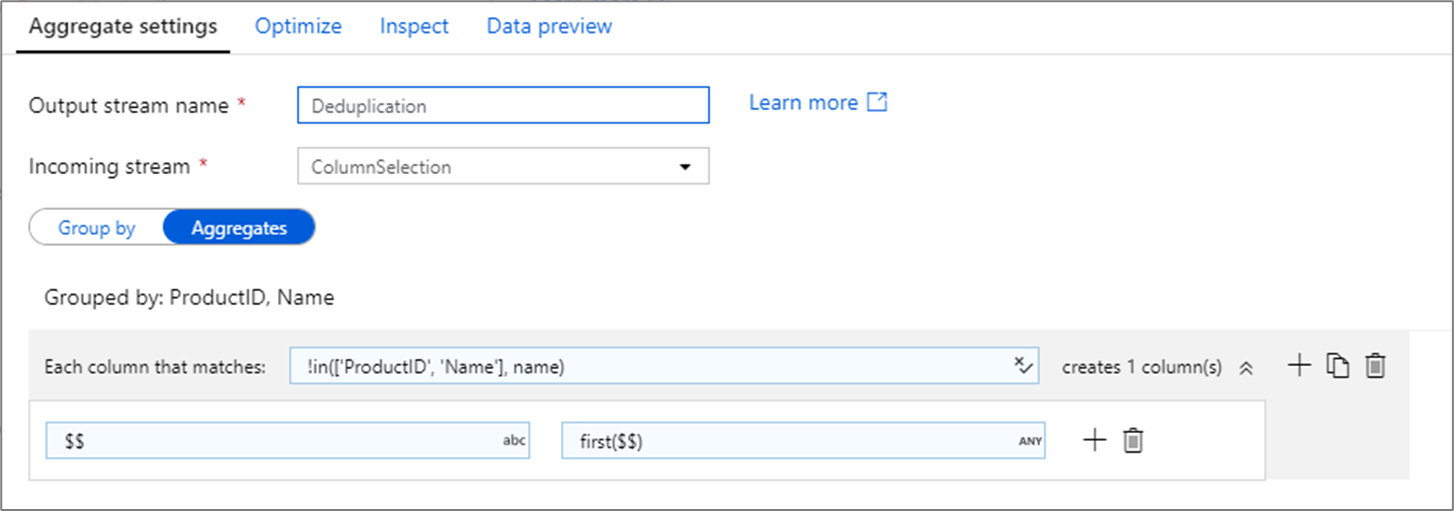
En el ejemplo anterior, las columnas ProductID y Name se usan para la agrupación. Si dos filas tienen los mismos valores para esas dos columnas, se consideran duplicadas. En esta transformación de agregados, se conservarán los valores de la primera fila coincidente y se quitarán todos los demás. Con la sintaxis de patrón de columnas, todas las columnas cuyos nombres no son ProductID y Name se asignan a su nombre de columna existente y se les proporciona el valor de las primeras filas coincidentes. El esquema de salida es el mismo que el esquema de entrada.
En escenarios de validación de datos, la función count() se puede usar para contar el número de duplicados que hay.
Script de flujo de datos
Sintaxis
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Ejemplo
En el ejemplo siguiente se toma un flujo entrante MoviesYear y las filas se agrupan por columna year. La transformación crea una columna de agregado avgrating que se evalúa como el promedio de la columna Rating. Esta transformación Agregar se denomina AvgComedyRatingsByYear.
En la interfaz de usuario, esta transformación es similar a la siguiente imagen:
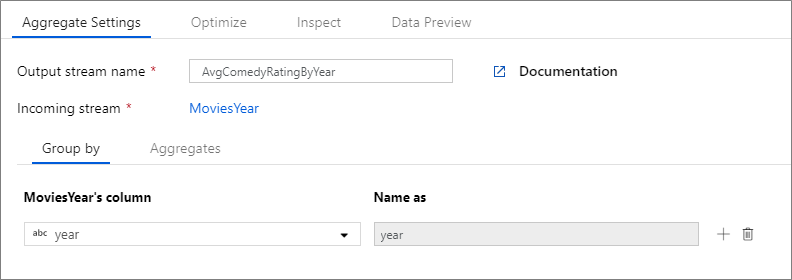
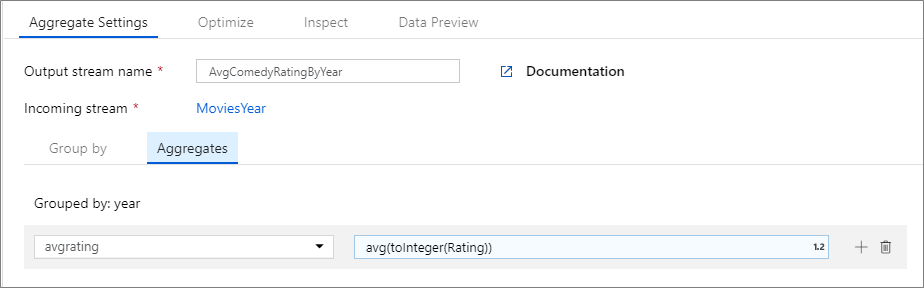
En el siguiente fragmento de código se muestra el script del flujo de datos para esta transformación.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
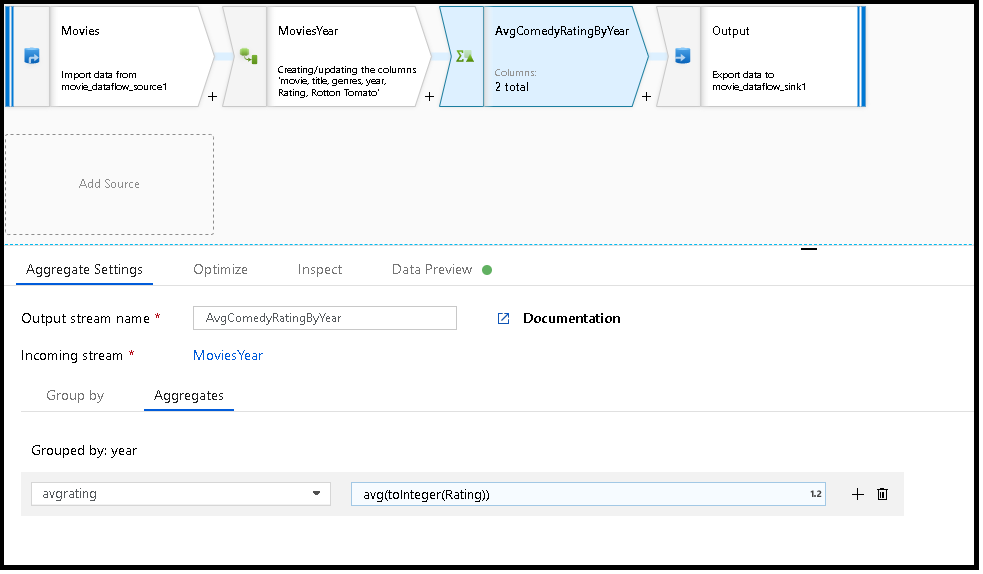
MoviesYear: columna derivada que define las columnas year y title AvgComedyRatingByYear: transformación de agregados para la clasificación media de comedias agrupadas por año avgrating: nombre de la nueva columna que se va a crear para contener el valor agregado
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Contenido relacionado
- Definir un agregación basada en ventanas mediante la transformación Ventana.