Implementación de clústeres de macrodatos de SQL Server con un cuaderno de Azure Data Studio
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
SQL Server proporciona una extensión para Azure Data Studio que incluye cuadernos de implementación. Un cuaderno de implementación incluye documentación y código que se puede usar en Azure Data Studio para crear un clúster de macrodatos de SQL Server.
Los cuadernos, que al principio se implementaban como un proyecto de código abierto, se han implementado en Azure Data Studio. Puede usar Markdown para el texto de las celdas de texto y uno de los kernels disponibles para escribir código en las celdas de código.
Puede usar cuadernos para implementar Clústeres de macrodatos de SQL Server.
Prerrequisitos
Los siguientes requisitos previos son indispensables para iniciar también el cuaderno:
- Versión más reciente de la compilación Azure Data Studio Insiders instalada
Además de lo anterior, para implementar un clúster de macrodatos también se requiere:
Inicio del cuaderno
Inicie Azure Data Studio.
En la pestaña Conexiones, seleccione los puntos suspensivos ( ... ) y, a continuación, seleccione Implementar SQL Server... .
En las opciones de implementación, seleccione Clúster de macrodatos de SQL Server.
En Deployment Target (Destino de implementación), en Opciones, seleccione New Azure Kubernetes Cluster (Nuevo clúster de Azure Kubernetes) o Existing Azure Kubernetes Service cluster (Clúster de Azure Kubernetes Service existente).
Acepte los términos de privacidad y de licencia.
En este cuadro de diálogo también se comprueba si en el host están las herramientas necesarias para el tipo seleccionado de implementación de SQL. El botón Seleccionar no se habilita hasta que se haya efectuado correctamente la comprobación de las herramientas.
Seleccione el botón Seleccionar. Esta acción inicia la experiencia de implementación.
Establecer una plantilla de configuración de implementación
Puede personalizar la configuración del perfil de implementación siguiendo las instrucciones que se indican a continuación.
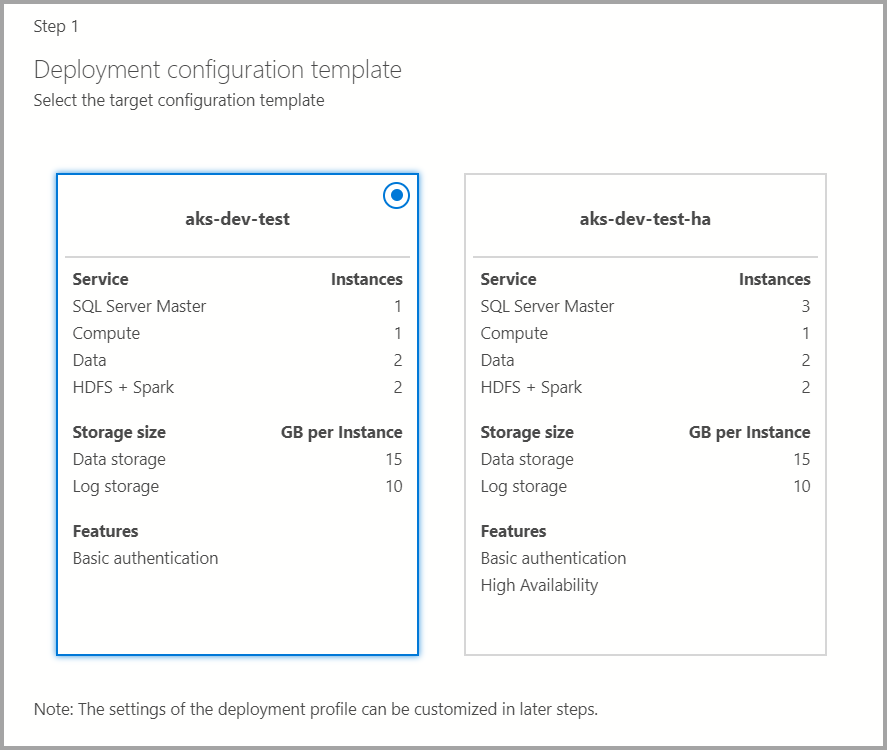
Plantilla de configuración de destino
Seleccione la plantilla de configuración de destino en las plantillas disponibles. Los perfiles disponibles se filtran según el tipo de destino de implementación que se elija en el cuadro de diálogo anterior.
Configuración de azure
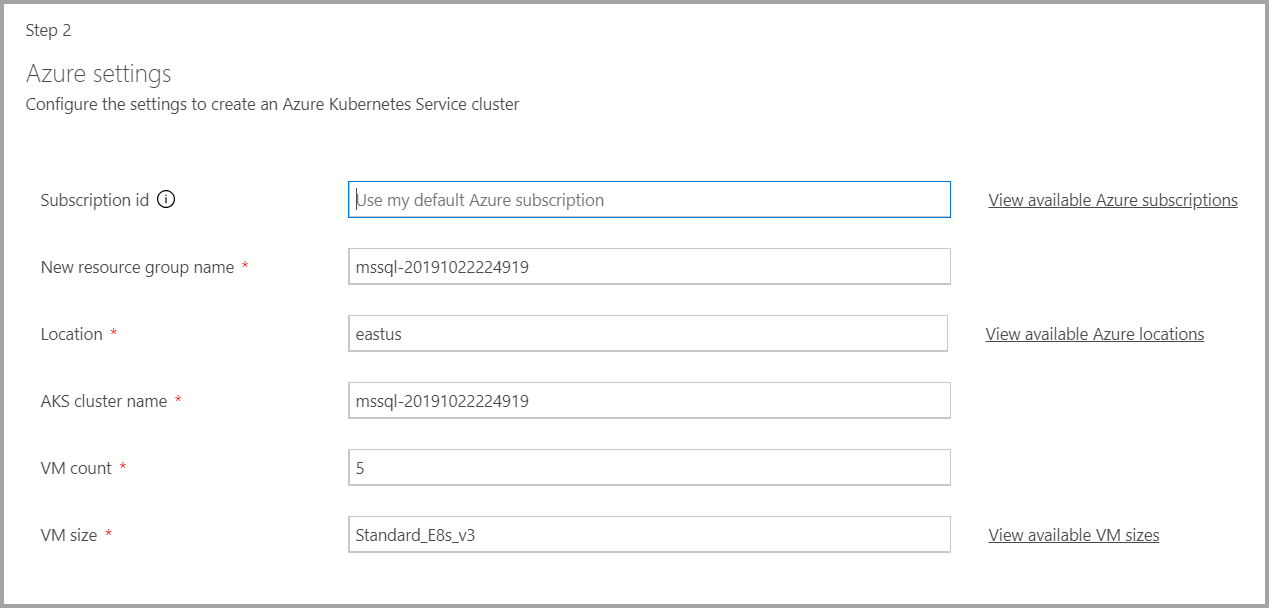
Si el destino de implementación es una instancia nueva de Azure Kubernetes Service (AKS), se necesitará información adicional, como el identificador de suscripción de Azure, el grupo de recursos, el nombre del clúster de AKS, el recuento de VM, el tamaño y demás información adicional para crear el clúster de AKS.
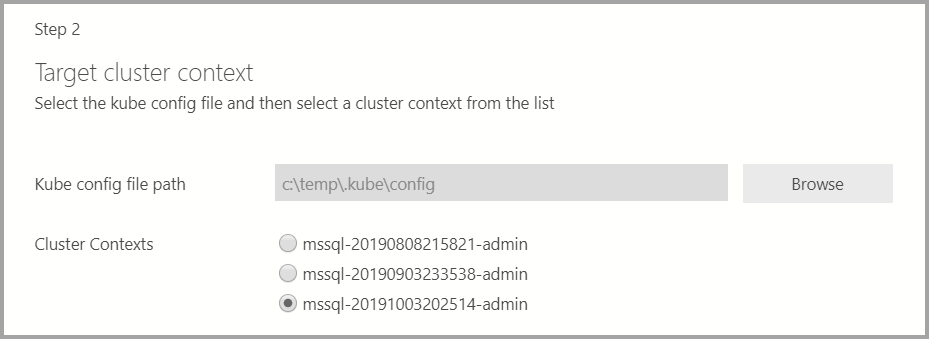
Si el destino de implementación es un clúster de Kubernetes existente, el asistente solicitará la ruta de acceso al archivo de configuración kube para importar las opciones de configuración de clúster de Kubernetes. Asegúrese de que esté seleccionado el contexto de clúster adecuado en el que se puede implementar el Clúster de macrodatos de SQL Server 2019.
Configuración de clúster, Docker y AD
Escriba el nombre para el clúster de macrodatos, un nombre de usuario administrador y una contraseña. Se usa la misma cuenta para el controlador y para SQL Server.
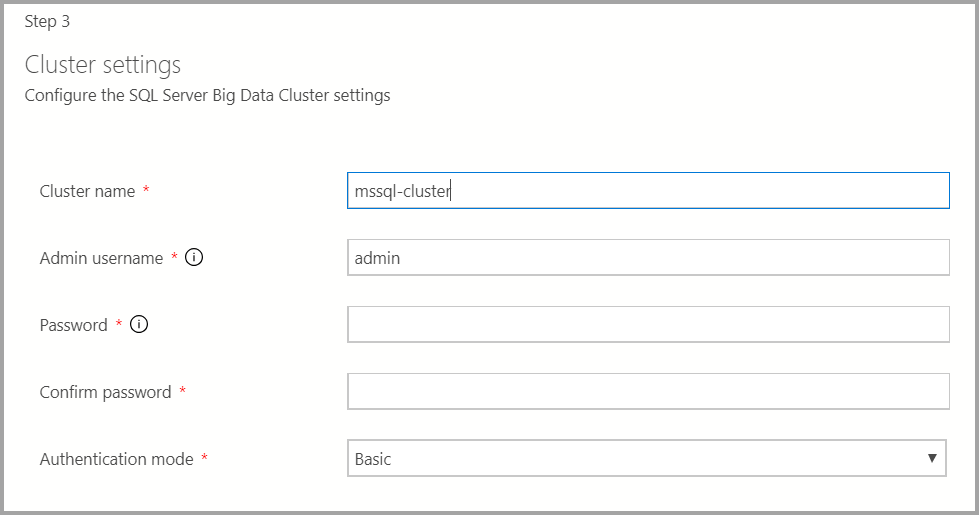
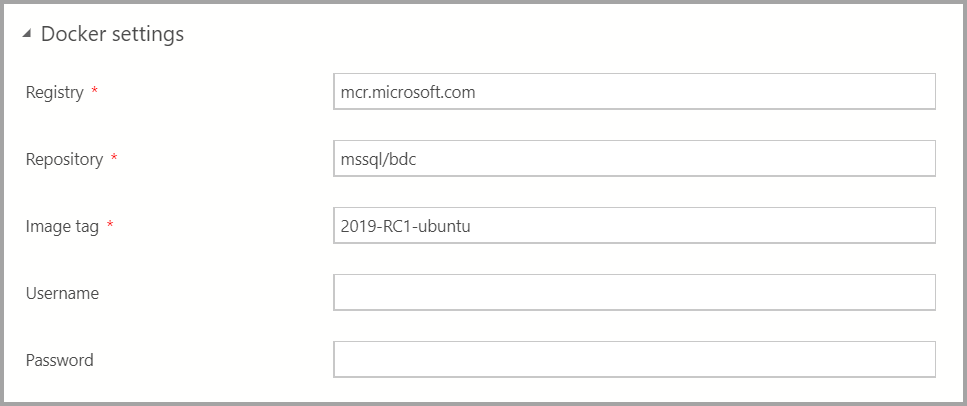
Escriba la configuración de Docker según corresponda.
Importante
Asegúrese de que el campo de etiqueta de imagen es el más reciente: 2019-CU13-ubuntu-20.04.
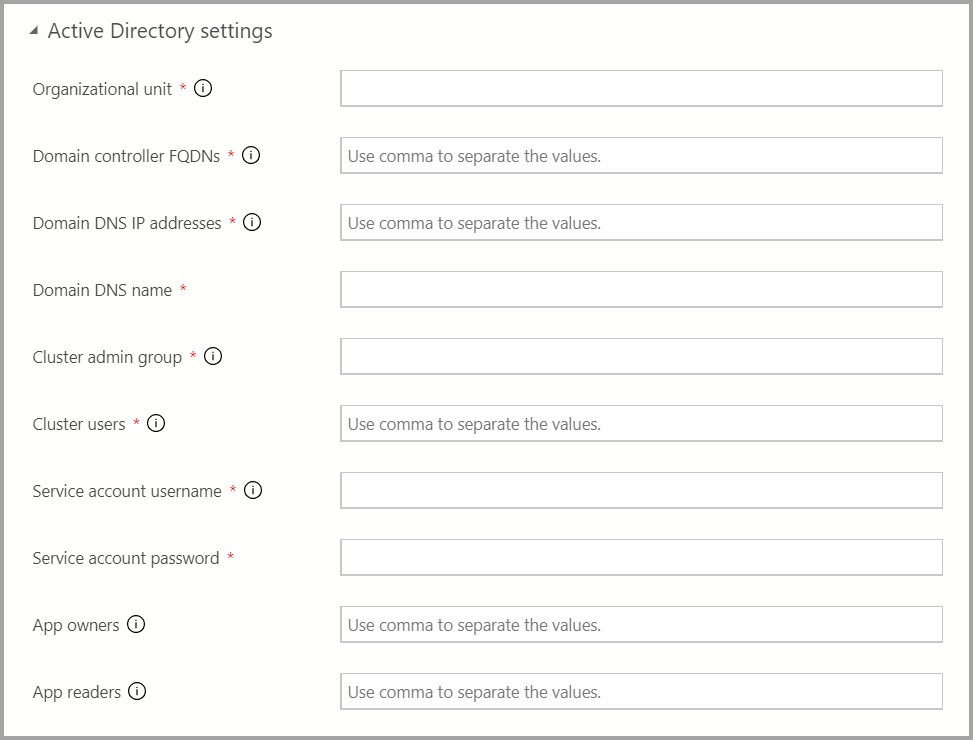
Si la autenticación de AD está disponible, escriba la configuración de AD.
Configuración del servicio
Esta pantalla contiene entradas para diversas opciones, como Escala, Puntos de conexión, Almacenamiento y otras opciones de almacenamiento avanzadas. Escriba los valores adecuados y seleccione Siguiente.
Configuración de escala
Escriba el número de instancias de cada uno de los componentes del clúster de macrodatos.
Se puede incluir una instancia de Spark junto con HDFS. Se incluye en el grupo de almacenamiento o por sí misma en el grupo de Spark.
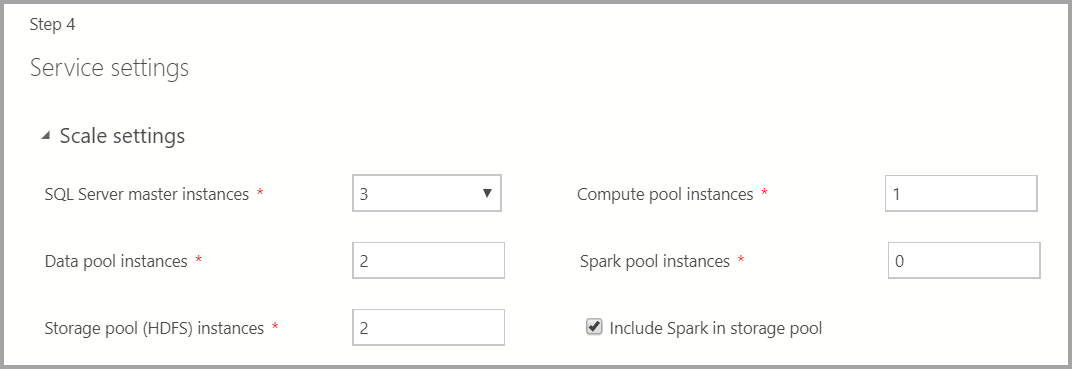
Para obtener más información sobre cada uno de estos componentes, puede consultar instancia maestra, grupo de datos, grupo de almacenamiento o grupo de proceso.
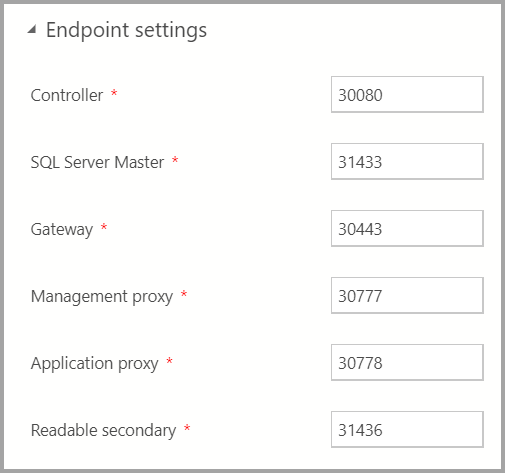
Configuración de punto de conexión
Los puntos de conexión predeterminados se han rellenado previamente. Sin embargo, se pueden cambiar según corresponda.
Configuración de almacenamiento
La configuración de almacenamiento incluye la clase de almacenamiento y el tamaño de las notificaciones para los datos y los registros. La configuración se puede aplicar en el grupo de almacenamiento, de datos y el maestro de SQL Server.

Configuración de almacenamiento avanzada
Puede agregar más opciones de configuración de almacenamiento en Configuración avanzada de almacenamiento.
Grupo de almacenamiento (HDFS)
Grupo de datos
Maestro de SQL Server

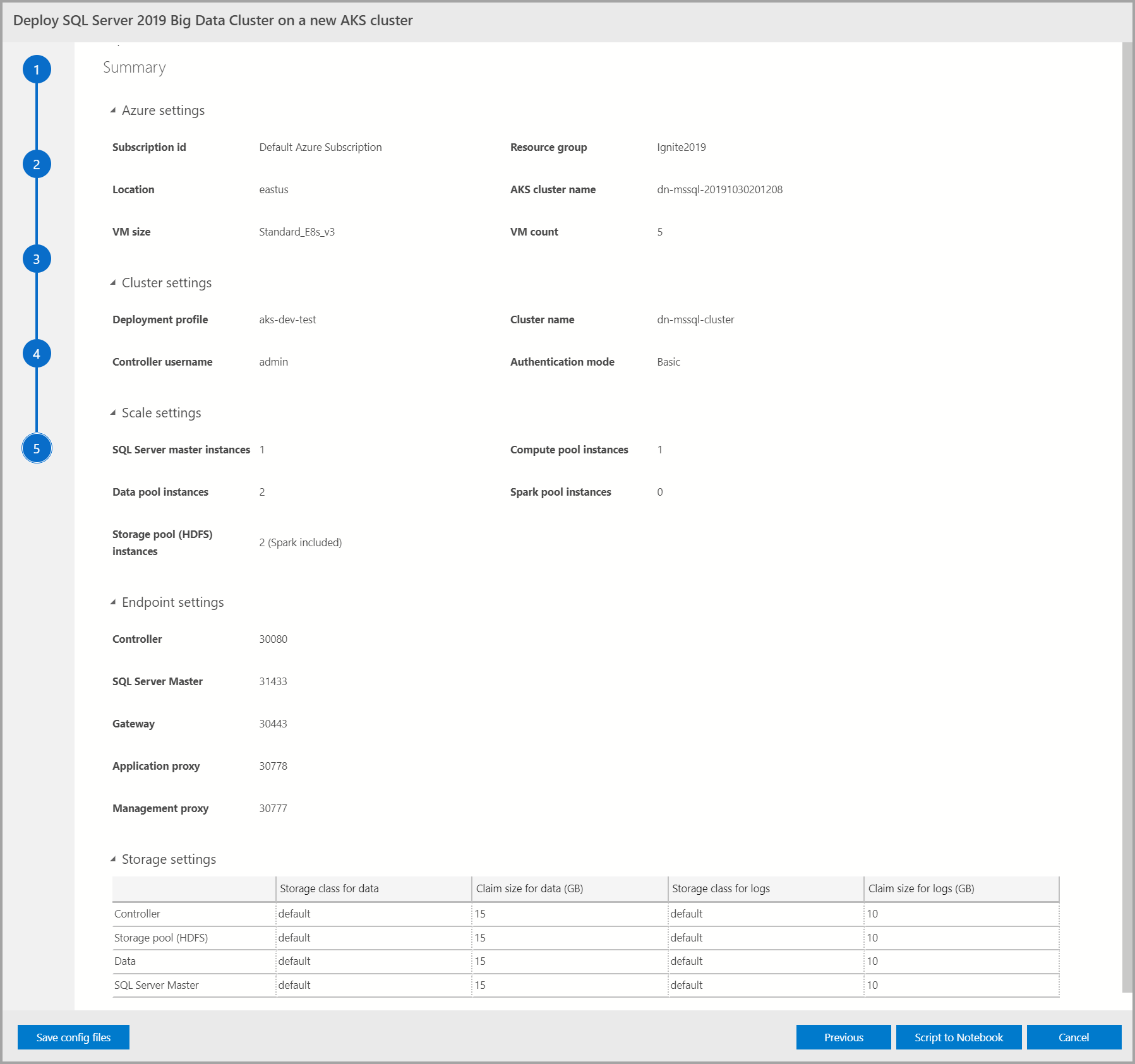
Resumen
En esta pantalla se resume toda la entrada proporcionada para implementar el clúster de macrodatos. Los archivos de configuración se pueden descargar con el botón Guardar archivos de configuración. Seleccione Script a Notebook para incluir toda la configuración de implementación en un script de un cuaderno. Una vez abierto el cuaderno, seleccione Ejecutar celdas para iniciar la implementación del clúster de macrodatos en el destino seleccionado.
Pasos siguientes
Para más información sobre la implementación, vea la guía de implementación para los clústeres de macrodatos de SQL Server.