Introducción a los grupos de proceso en Clústeres de macrodatos de SQL Server
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
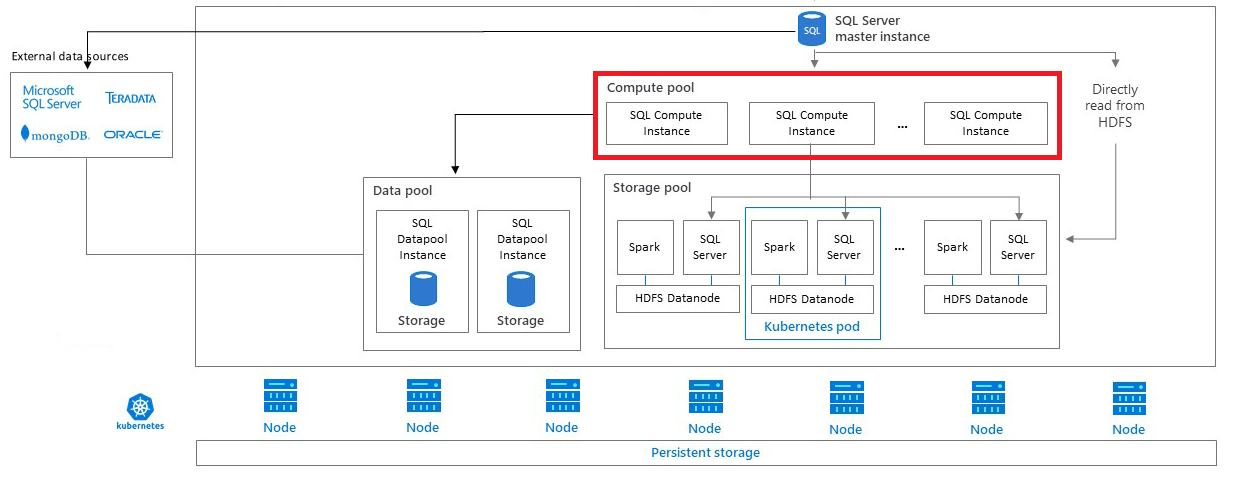
En este artículo se describe el rol de los grupos de proceso de SQL Server en un clúster de macrodatos de SQL Server. Los grupos de proceso proporcionan recursos computacionales de escalado horizontal para un clúster de macrodatos de SQL Server. Se usan para descargar el trabajo de cálculo o los conjuntos de resultados intermedios de la instancia maestra de SQL Server. En las secciones siguientes se describe la arquitectura, las funciones y los escenarios de uso de un grupo de proceso.
También puede ver este vídeo de 5 minutos para obtener una introducción a los grupos de proceso:
Arquitectura de grupo de proceso
Un grupo de proceso se compone de uno o varios pods de proceso que se ejecutan en Kubernetes. La creación y administración automatizadas de estos pods se coordinan mediante la instancia maestra de SQL Server. Cada pod contiene un conjunto de servicios base y una instancia del motor de base de datos de SQL Server.
Grupos de escalado horizontal
Un grupo de proceso puede actuar como grupo de escalado horizontal de PolyBase para las consultas distribuidas en diferentes orígenes de datos externos, como SQL Server, Oracle, MongoDB, Teradata y HDFS. Mediante el uso de pods de proceso en Kubernetes, un clúster de macrodatos de SQL Server puede automatizar la creación y configuración de los pods de proceso para los grupos de escalado horizontal de PolyBase.
Escenarios de grupos de proceso
Estos son algunos escenarios en los que se usan grupos de proceso:
Cuando las consultas enviadas a la instancia maestra usan una o más tablas ubicadas en el grupo de almacenamiento.
Cuando las consultas enviadas a la instancia maestra usan una o más tablas con distribución round robin ubicada en el grupo de datos.
Cuando las consultas enviadas a la instancia maestra usan tablas con particiones con orígenes de datos externos de SQL Server, Oracle, MongoDB y Teradata. En este escenario, la sugerencia de consulta OPTION (FORCE SCALEOUTEXECUTION) debe estar habilitada.
Cuando las consultas enviadas a la instancia maestra usan una o más tablas ubicadas en el almacenamiento por niveles de HDFS.
Estos son algunos escenarios en los que no se usan grupos de proceso:
Cuando las consultas enviadas a la instancia maestra usan una o más tablas en un clúster HDFS de Hadoop externo.
Cuando las consultas enviadas a la instancia maestra usan una o más tablas ubicadas en Azure Blob Storage.
Cuando las consultas enviadas a la instancia maestra usan tablas sin particiones con orígenes de datos externos de SQL Server, Oracle, MongoDB y Teradata.
Cuando está habilitada la sugerencia de consulta OPTION (DISABLE SCALEOUTEXECUTION).
Cuando las consultas enviadas a la instancia maestra se aplican a las bases de datos ubicadas en la instancia maestra.
Pasos siguientes
Para obtener más información sobre Clústeres de macrodatos de SQL Server, vea los recursos siguientes: