Más información sobre y creación de reglas de calidad de datos
La calidad de los datos es la medición de la integridad de los datos de una organización y se evalúa mediante puntuaciones de calidad de datos. Puntuaciones generadas en función de la evaluación de los datos con respecto a las reglas definidas en Catálogo unificado de Microsoft Purview.
Las reglas de calidad de datos son directrices esenciales que las organizaciones establecen para garantizar la precisión, la coherencia y la integridad de sus datos. Estas reglas ayudan a mantener la integridad y confiabilidad de los datos.
Estos son algunos aspectos clave de las reglas de calidad de datos:
Precisión : los datos deben representar con precisión entidades del mundo real. ¡El contexto importa! Por ejemplo, si va a almacenar direcciones de cliente, asegúrese de que coincidan con las ubicaciones reales.
Integridad : el objetivo de esta regla es identificar los datos vacíos, null o que faltan. Esta regla valida que todos los valores están presentes (aunque no necesariamente correctos).
Conformidad : esta regla garantiza que los datos siguen los estándares de formato de datos, como la representación de fechas, direcciones y valores permitidos.
Coherencia : esta regla comprueba que los distintos valores del mismo registro están en conformidad con una regla determinada y no hay contradicciones. La coherencia de los datos garantiza que la misma información se represente uniformemente en distintos registros. Por ejemplo, si tiene un catálogo de productos, los nombres y descripciones de productos coherentes son fundamentales.
Escala de tiempo : esta regla tiene como objetivo garantizar que los datos sean accesibles en el menor tiempo posible. Garantiza que los datos están actualizados.
Unicidad : esta regla comprueba que los valores no están duplicados, por ejemplo, si se supone que solo hay un registro por cliente, no hay varios registros para el mismo cliente. Cada cliente, producto o transacción debe tener un identificador único.
Ciclo de vida de la calidad de datos
La creación de reglas de calidad de datos es el sexto paso del ciclo de vida de la calidad de los datos. Los pasos anteriores son:
- Asigne a los usuarios permisos de administrador de calidad de datos en Catálogo unificado para usar todas las características de calidad de datos.
- Registre y examine un origen de datos en el Mapa de datos de Microsoft Purview.
- Adición del recurso de datos a un producto de datos
- Configure una conexión de origen de datos para preparar el origen para la evaluación de la calidad de los datos.
- Configure y ejecute la generación de perfiles de datos para un recurso en el origen de datos.
Roles necesarios
- Para crear y administrar reglas de calidad de datos, los usuarios deben tener el rol administrador de calidad de datos.
- Para ver las reglas de calidad existentes, los usuarios deben estar en el rol lector de calidad de datos.
Visualización de reglas de calidad de datos existentes
En Catálogo unificado de Microsoft Purview, seleccione el menú Administración de estado y el submenú Calidad de datos.
En el submenú calidad de datos, seleccione un dominio de gobernanza.
Seleccione un producto de datos.
Seleccione un recurso de datos de la lista de recursos del producto de datos seleccionado.
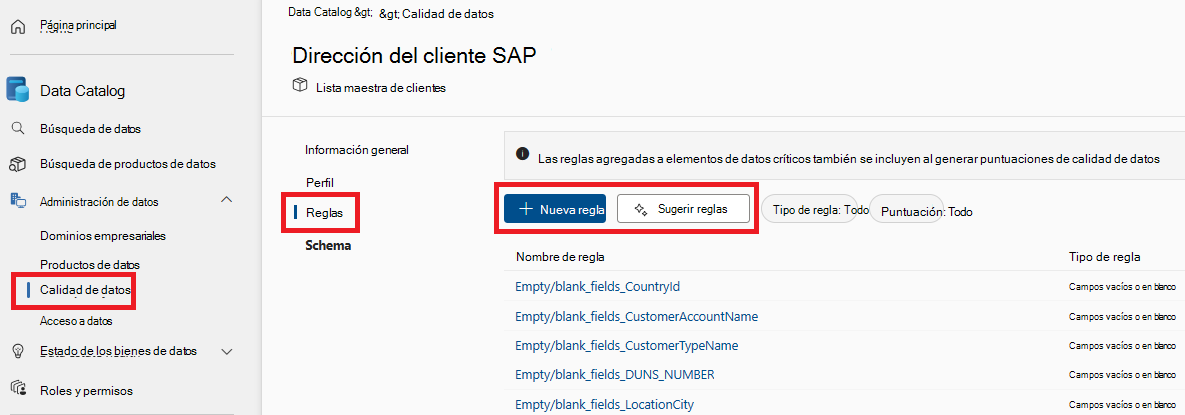
Seleccione la pestaña de menú Reglas para ver las reglas existentes aplicadas al recurso.
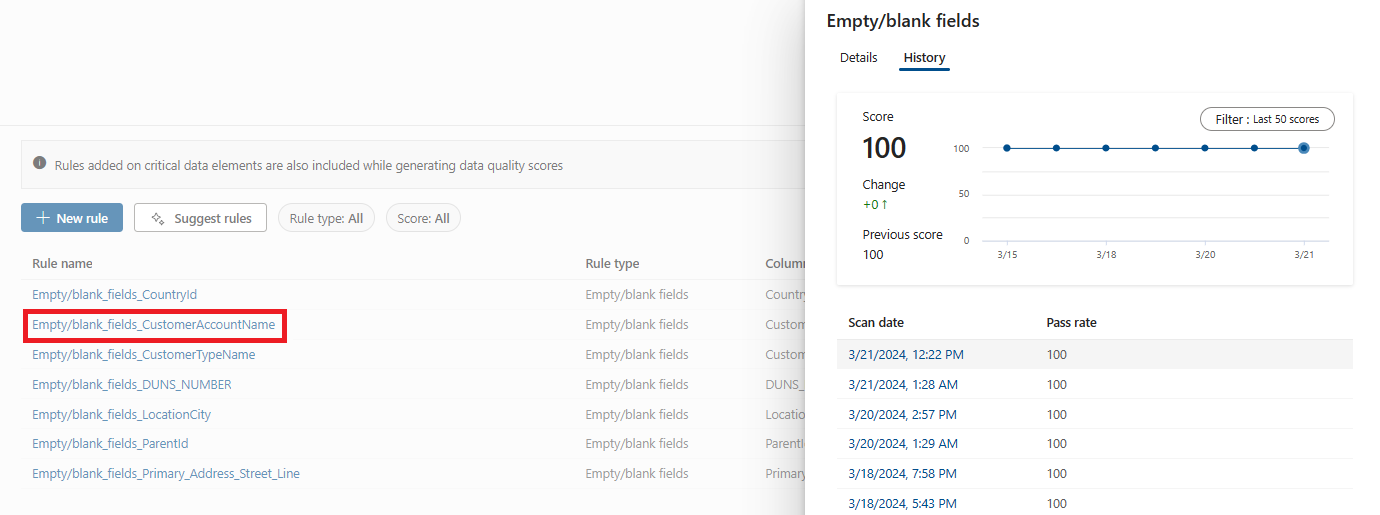
Seleccione una regla para examinar el historial de rendimiento de la regla aplicada al recurso de datos seleccionado.




Reglas de calidad de datos disponibles
Calidad de datos de Microsoft Purview permite la configuración de las reglas siguientes, estas son reglas integradas que ofrecen una forma de bajo código a sin código para medir la calidad de los datos.
| Rule | Definición |
|---|---|
| Actualización | Confirma que todos los valores están actualizados. |
| Valores únicos | Confirma que los valores de una columna son únicos. |
| Coincidencia de formato de cadena | Confirma que los valores de una columna coinciden con un formato específico u otros criterios. |
| Coincidencia del tipo de datos | Confirma que los valores de una columna coinciden con sus requisitos de tipo de datos. |
| Filas duplicadas | Comprueba si hay filas duplicadas con los mismos valores en dos o más columnas. |
| Campos vacíos o en blanco | Busca campos vacíos y en blanco en una columna donde debería haber valores. |
| Búsqueda de tablas | Confirma que un valor de una tabla se puede encontrar en la columna específica de otra tabla. |
| Personalizados | Cree una regla personalizada con el generador de expresiones visuales. |
Actualización
El propósito de la regla de actualización es determinar si el recurso se ha actualizado dentro del tiempo esperado. Microsoft Purview admite actualmente la comprobación de la actualización examinando las fechas de última modificación.
Nota:
La puntuación de la regla de actualización es 100 (se ha pasado) o 0 (error). No se admite la regla de actualización para Snowflake, Azure Databricks UC, Google BigQuery, Synapes y Azure SQL.
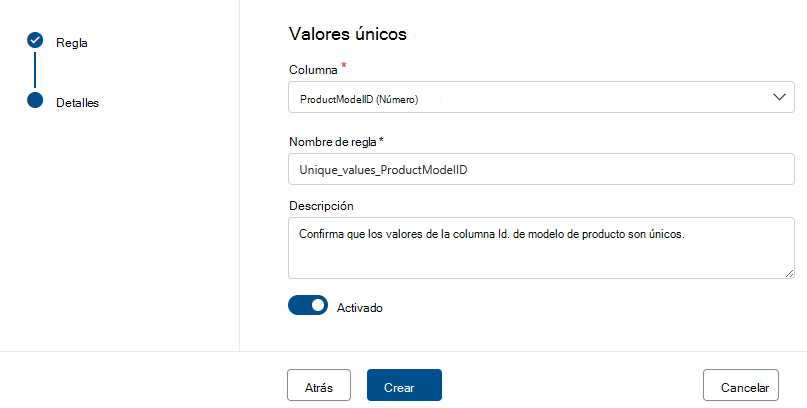
Valores únicos
La regla Valores únicos indica que todos los valores de la columna especificada deben ser únicos. Todos los valores que son "pass" únicos y los que no se tratan como un error. Si la regla De campos vacíos o en blanco no está definida en la columna, se omitirán los valores null/empty para los fines de esta regla.
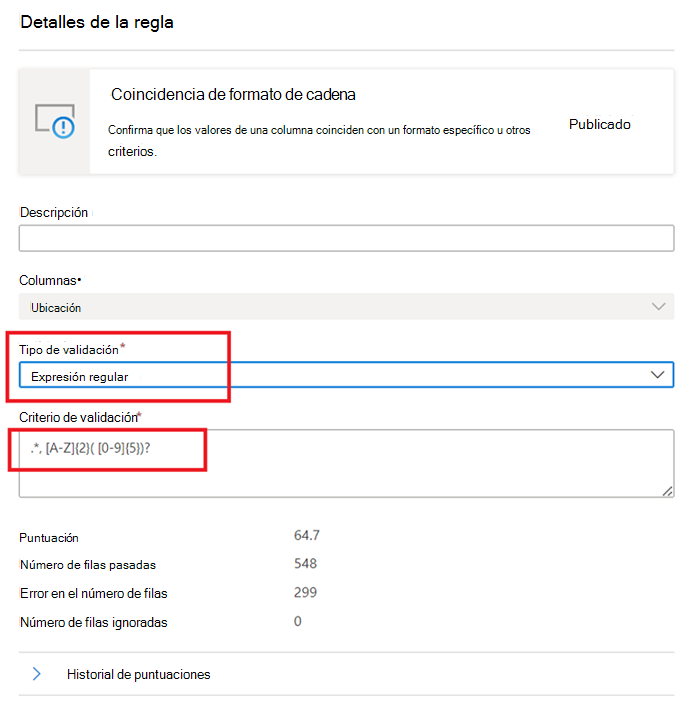
Coincidencia de formato de cadena
La regla de coincidencia de formato comprueba si todos los valores de la columna son válidos. Si la regla Campos vacíos o en blanco no está definida en una columna, los valores null/empty se omitirán a los efectos de esta regla.
Esta regla puede validar cada valor de la columna mediante tres enfoques diferentes:
Enumeración : se trata de una lista de valores separados por comas. Si el valor que se evalúa no se puede comparar con uno de los valores enumerados, se produce un error en la comprobación. Las comas y las barras diagonales inversas se pueden aplicar como escape mediante una barra diagonal inversa:
\. Por lo tantoa \, b, c, contiene dos valores: el primero esa , by el segundo esc.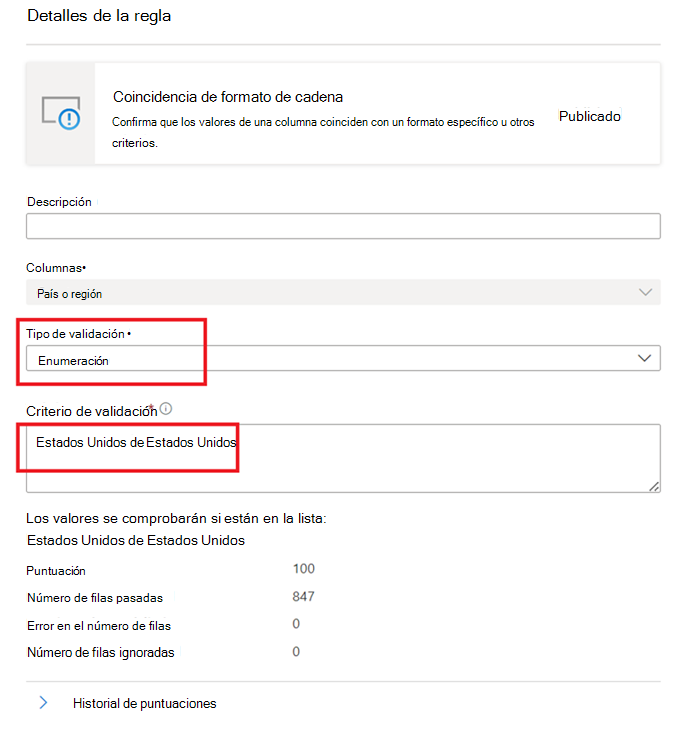
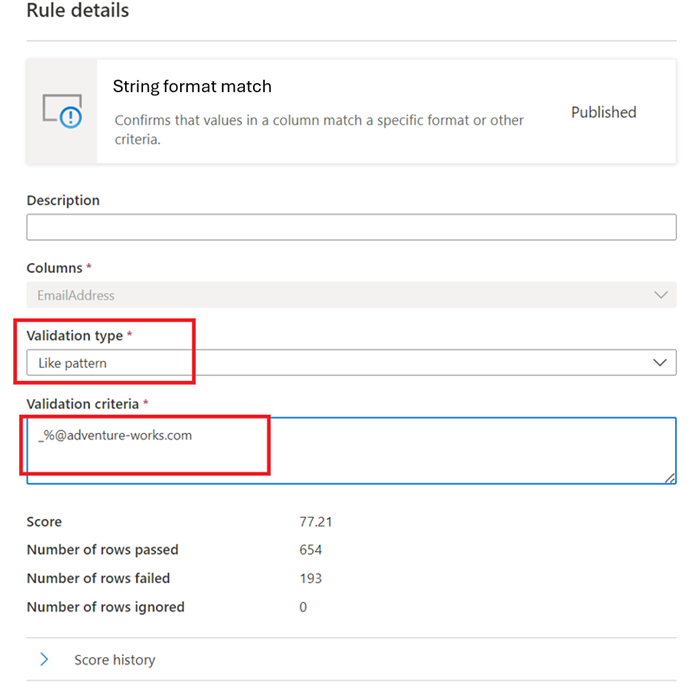
Patrón similar -
like(<string> : string, <pattern match> : string) => boolean
El patrón es una cadena que coincide literalmente. Las excepciones son los siguientes símbolos especiales: _ coincide con cualquier carácter de la entrada (similar a . enposixexpresiones regulares) % coincide con cero o más caracteres en la entrada (similar a .* enposixexpresiones regulares). El carácter de escape es ''. Si un carácter de escape precede a un símbolo especial u otro carácter de escape, el siguiente carácter coincide literalmente. No es válido escapar a cualquier otro carácter.like('icecream', 'ice%') -> true
Expresión regular :
regexMatch(<string> : string, <regex to match> : string) => boolean
Comprueba si la cadena coincide con el patrón regex especificado. Use<regex>(comilla inversa) para hacer coincidir una cadena sin escapar.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
Coincidencia del tipo de datos
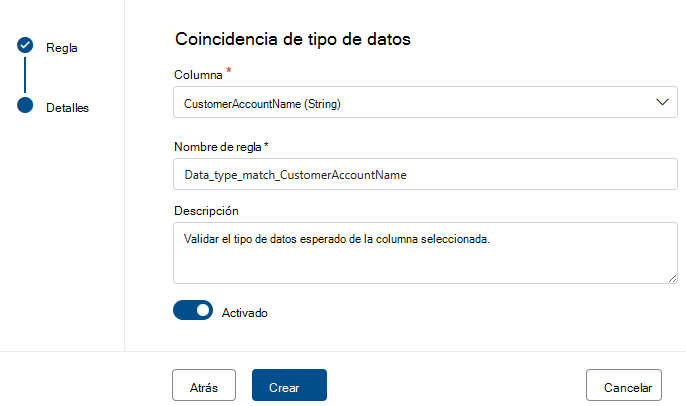
La regla de coincidencia de tipo de datos especifica qué tipo de datos se espera que contenga la columna asociada. Dado que el motor de reglas tiene que ejecutarse en muchos orígenes de datos diferentes, no puede usar tipos nativos como BIGINT o VARCHAR. En su lugar, tiene su propio sistema de tipos en el que traduce los tipos nativos. Esta regla indica al motor de examen de calidad a cuál de sus tipos integrados se debe traducir el tipo nativo. El sistema de tipos de datos se toma del sistema de tipos de Azure Data Flow que se usa en Azure Data Factory.
Durante un examen de calidad, todos los tipos nativos se probarán con el tipo de coincidencia de tipo de datos y, si no es posible traducir el tipo nativo al tipo de coincidencia de tipo de datos, esa fila se tratará como un error.
Filas duplicadas
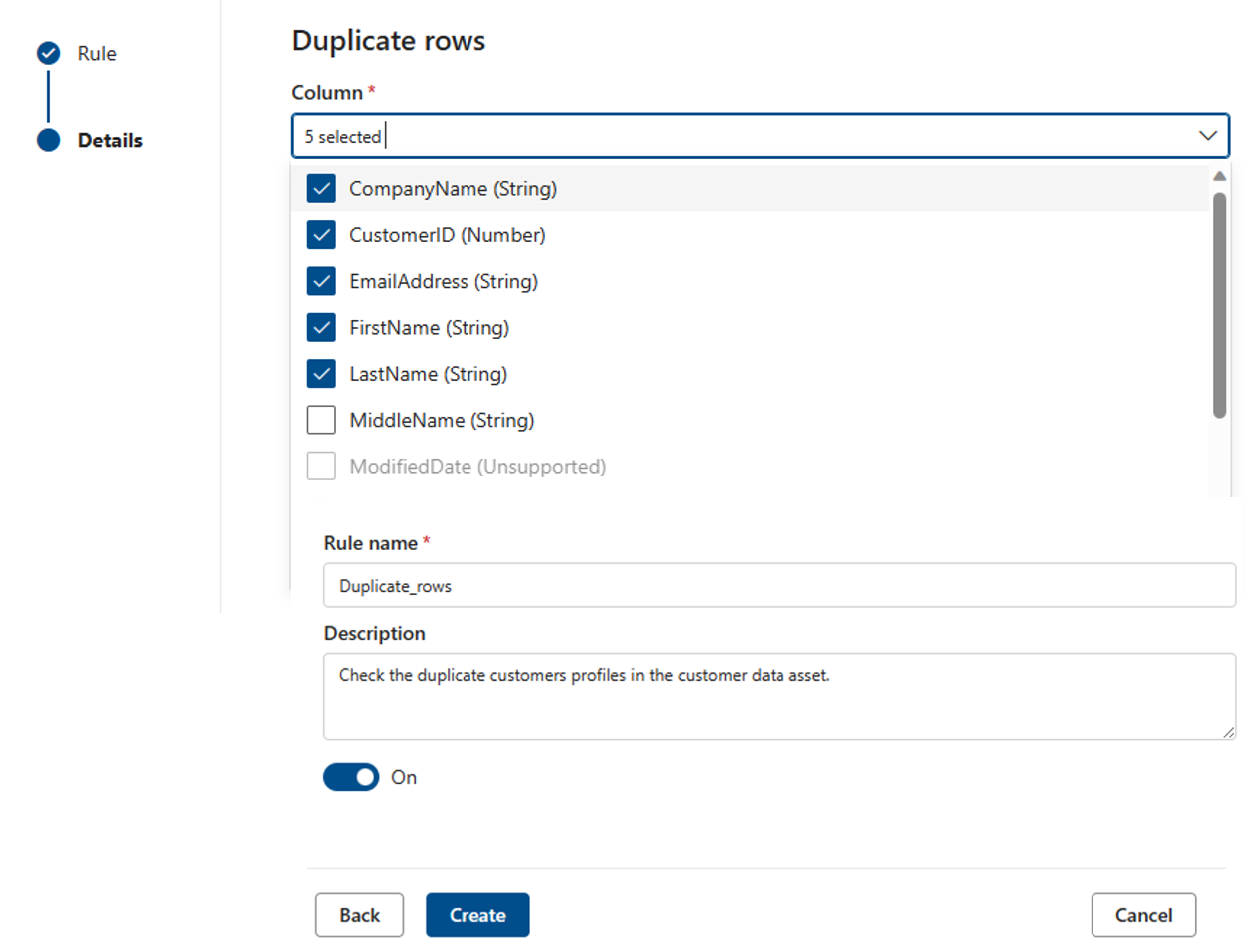
La regla Filas duplicadas comprueba si la combinación de los valores de la columna es única para cada fila de la tabla.
En el ejemplo siguiente, la expectativa es que la concatenación de _CompanyName, CustomerID, EmailAddress, FirstName y LastName genere un valor único para todas las filas de la tabla.
Cada recurso puede tener cero o una instancia de esta regla.
Campos vacíos o en blanco
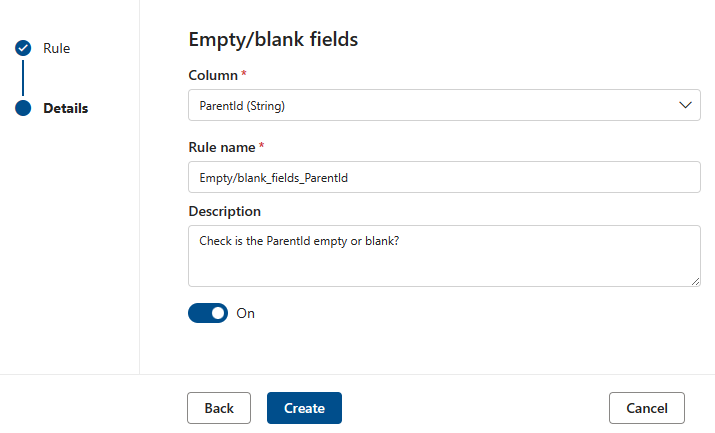
La regla De campos vacíos o en blanco afirma que las columnas identificadas no deben contener ningún valor NULL y, en el caso específico de las cadenas, tampoco hay valores vacíos ni espacios en blanco. Durante un examen de calidad, cualquier valor de esta columna que no sea NULL se tratará como correcto. Esta regla afectará a otras reglas, como valores únicos o reglas de coincidencia de formato . Si esta regla no se define en una columna, esas reglas cuando se ejecuten en esa columna omitirán automáticamente los valores NULL. Si esta regla se define en una columna, esas reglas examinarán los valores nulos o vacíos en esa columna y los considerarán con fines de puntuación.
Búsqueda de tablas
La regla Table Lookup examinará cada valor de la columna en la que se define la regla y lo comparará con una tabla de referencia. Por ejemplo, la tabla principal tiene una columna denominada "location" que contiene ciudades, estados y códigos postales con el formato "city, state zip". Hay una tabla de referencia, denominada citystate, que contiene todas las combinaciones legales de ciudades, estados y códigos postales admitidos en el Estados Unidos. El objetivo es comparar todas las ubicaciones de la columna actual con esa lista de referencia para asegurarse de que solo se usan combinaciones legales.
Para ello, primero escriba el "nombre de citystatezip en el cuadro de diálogo de recursos de búsqueda. A continuación, seleccionamos el recurso deseado y, a continuación, la columna con la que queremos comparar.
Nota:
La tabla de referencia o el recurso de datos deben pertenecer al mismo dominio de gobernanza. No se permite comparar un recurso de datos entre distintos dominios de gobernanza.
Reglas personalizadas
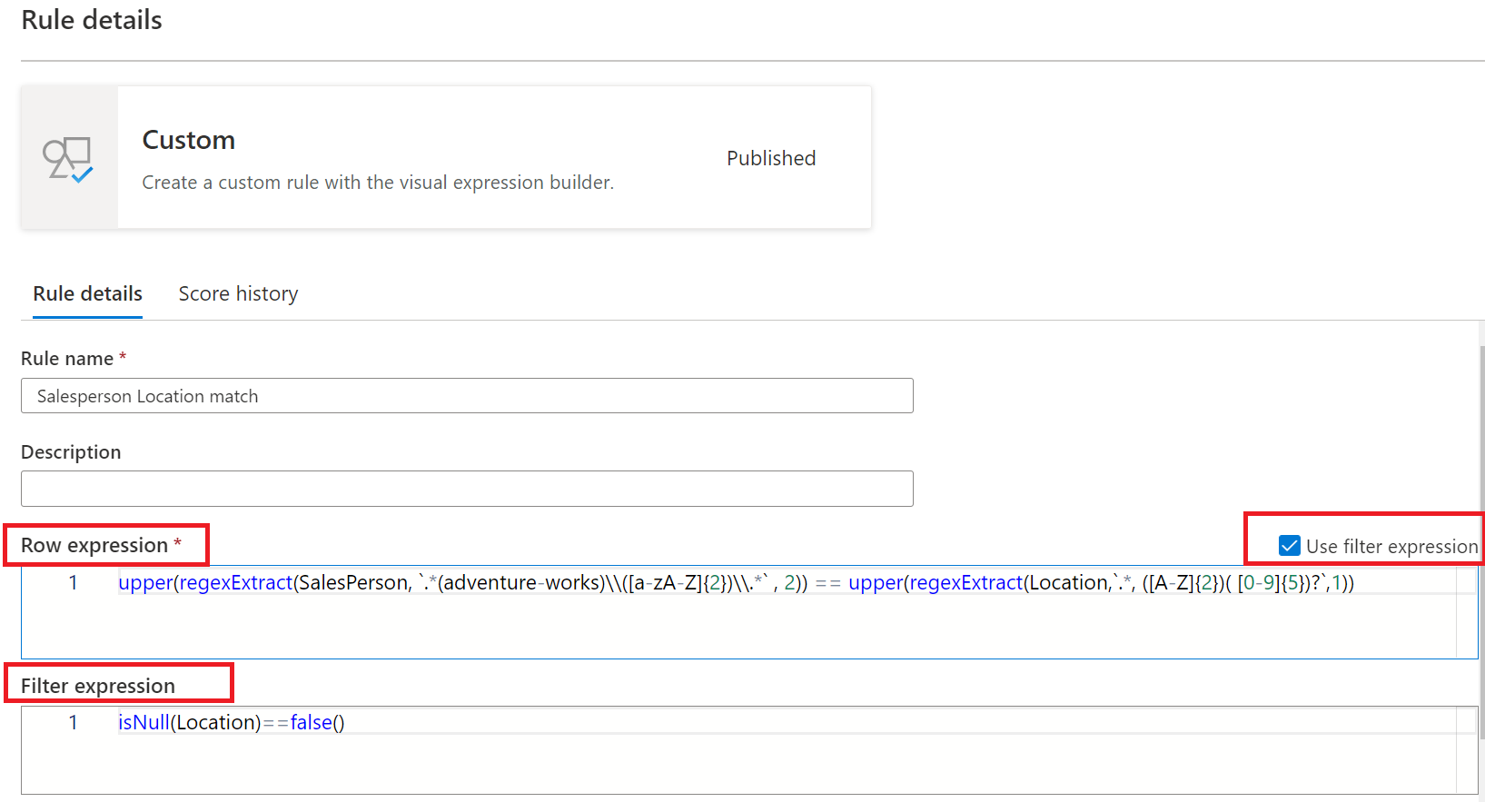
La regla Personalizada permite especificar reglas que intentan validar filas basadas en uno o varios valores de esa fila. La regla personalizada tiene dos partes:
- La primera parte es la expresión de filtro que es opcional y se activa seleccionando la casilla "Usar expresión de filtro". Se trata de una expresión que devuelve un valor booleano. La expresión de filtro se aplicará a una fila y, si devuelve true, esa fila se tendrá en cuenta para la regla. Si la expresión de filtro devuelve false para esa fila, significa que la fila se omitirá para los fines de esta regla. El comportamiento predeterminado de la expresión de filtro es pasar todas las filas, por lo que si no se especifica ninguna expresión de filtro y no se requiere una, se tendrán en cuenta todas las filas.
- La segunda parte es la expresión de fila. Se trata de una expresión booleana aplicada a cada fila que la expresión de filtro aprueba. Si esta expresión devuelve true, la fila pasa, si es false, se marca como un error.
Ejemplos de reglas personalizadas
| Escenario | Expresión de fila |
|---|---|
| Valide si state_id es igual a California y aba_Routing_Number coincide con un patrón regex determinado y la fecha de nacimiento cae en un intervalo determinado. | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Comprobar si VendorID es igual a 124 | {VendorID}=='124' |
| Compruebe si fare_amount es igual o mayor que 100 | {fare_amount} >= "100" |
| Validar si fare_amount es mayor que 100 y tolls_amount no es igual a 100 | {fare_amount} >= "100" || {tolls_amount} != "400" |
| Compruebe si la clasificación es menor que 5 | Rating < 5 |
| Comprobar si el número de dígitos en el año es 4 | length(toString(year)) == 4 |
| Compare dos columnas bbToLoanRatio y bankBalance para comprobar si sus valores son iguales | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Compruebe si el número de caracteres recortado y concatenado en firstName, lastName, LoanID, uuid es mayor que 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Compruebe si aba_Routing_Number coincide con cierto patrón regex y la fecha de transacción inicial es mayor que 2022-11-12, y Disallow-Listed es false, y el promedio de bankBalance es mayor que 50000 y state_id es igual a "Massachuse", "Tennessee", "Dakota del Norte" o "Albama". | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| Valide si aba_Routing_Number coincide con cierto patrón regex y dateOfBirth está entre 1968-12-13 y 2020-12-13 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Compruebe si el número de valores únicos en aba_Routing_Number es igual a 1000 000 y el número de valores únicos en EMAIL_ADDR es igual a 1000 000. | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
Tanto la expresión de filtro como la expresión de fila se definen mediante el lenguaje de expresiones Azure Data Factory, tal como se introduce aquí con el lenguaje definido aquí. Tenga en cuenta, sin embargo, que no todas las funciones definidas para el lenguaje de expresiones ADF genérico están disponibles. La lista completa de funciones disponibles se encuentra en la lista Funciones disponible en el cuadro de diálogo de expresión. No se admiten las siguientes funciones definidas en aquí : isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, cache lookup y Window.
Nota:
<regex> (backquote) se puede usar en expresiones regulares incluidas en reglas personalizadas para que coincidan con la cadena sin escape de caracteres especiales. El lenguaje de expresiones regulares se basa en Java y funciona como se indica aquí.
Esta página identifica los caracteres que deben tener escape.
Reglas generadas automáticamente asistidas por IA
La generación automatizada de reglas asistida por inteligencia artificial para la medición de la calidad de los datos implica el uso de técnicas de inteligencia artificial (IA) para crear automáticamente reglas para evaluar y mejorar la calidad de los datos. Las reglas generadas automáticamente son específicas del contenido. La mayoría de las reglas comunes se generarán automáticamente para que los usuarios no necesiten dedicar tanto esfuerzo a crear reglas personalizadas.
Para examinar y aplicar reglas generadas automáticamente:
- Seleccione Sugerir reglas en la página reglas.
- Examine las reglas sugeridas de la lista.

- Seleccione las reglas de la lista de reglas sugeridas para aplicarlas al recurso de datos.

Pasos siguientes
- Configure y ejecute un examen de calidad de datos en un producto de datos para evaluar la calidad de todos los recursos admitidos en el producto de datos.
- Revise los resultados del examen para evaluar la calidad de los datos actuales del producto de datos.