¿Cuál es la estructura de almacenamiento para flujos de datos analíticos?
Los flujos de datos analíticos almacenan datos y metadatos en Azure Data Lake Storage. Los flujos de datos aprovechan una estructura estándar para almacenar y describir los datos creados en el lago, que se conoce como las carpetas de Common Data Model. En este artículo, obtendrá más información sobre el estándar de almacenamiento que utilizan los flujos de datos internamente.
El almacenamiento necesita una estructura para un flujo de datos analítico
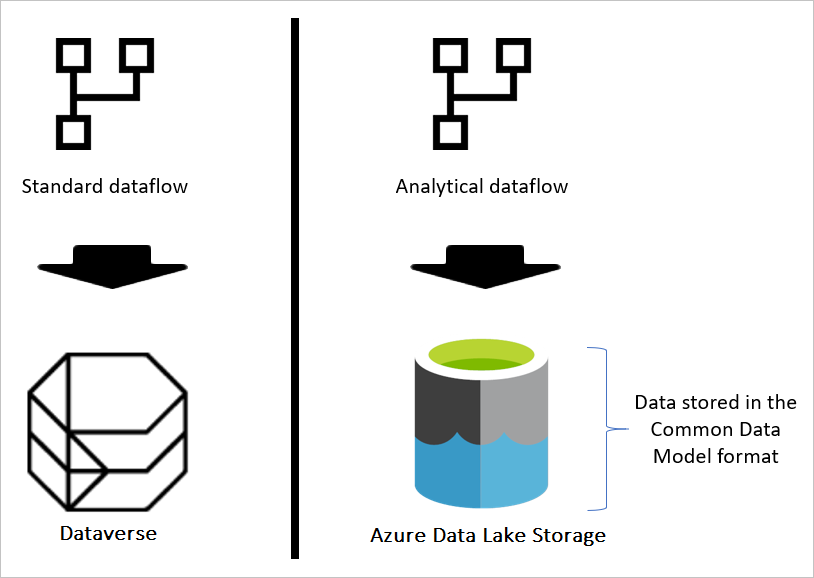
Si el flujo de datos es estándar, los datos se almacenan en Dataverse. Dataverse es como un sistema de base de datos; tiene el concepto de tablas, vistas, etc. Dataverse es una opción de almacenamiento de datos estructurada que utilizan los flujos de datos estándar.
Sin embargo, cuando el flujo de datos es analítico, los datos se almacenan en Azure Data Lake Storage. Los datos y metadatos de un flujo de datos se almacenan en una carpeta de Common Data Model. Dado que en una cuenta de almacenamiento puede haber varios flujos de datos almacenados, se ha introducido una jerarquía de carpetas y subcarpetas para ayudar a organizar los datos. En función del producto en el que se creó el flujo de datos, las carpetas y subcarpetas pueden representar áreas de trabajo (o entornos) y, a continuación, la carpeta de Common Data Model del flujo de datos. Dentro de la carpeta de Common Data Model, se almacenan tanto el esquema como los datos de las tablas de flujo de datos. Esta estructura sigue los estándares definidos para Common Data Model.
¿Qué es la estructura de almacenamiento de Common Data Model?
Common Data Model es una estructura de metadatos definida para aportar conformidad y coherencia para el uso de datos en varias plataformas. Common Data Model no es almacenamiento de datos, es la forma en que se almacenan y definen los datos.
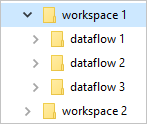
Las carpetas de Common Data Model definen cómo se debe almacenar el esquema de una tabla y sus datos. En Azure Data Lake Storage, los datos se organizan en carpetas. Las carpetas pueden representar un área de trabajo o un entorno. En esas carpetas, se crean subcarpetas para cada flujo de datos.
¿Qué hay en una carpeta de flujo de datos?
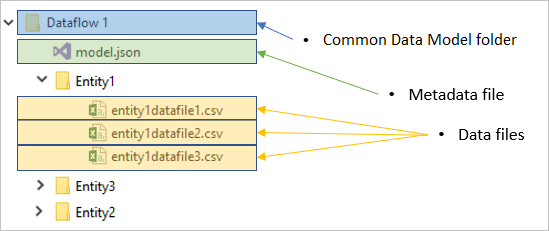
Cada carpeta de flujo de datos contiene una subcarpeta para cada tabla y un archivo de metadatos denominado model.json.
El archivo de metadatos: model.json
El archivo model.json es la definición de metadatos del flujo de datos. Este es el único archivo que contiene todos los metadatos del flujo de datos. Incluye una lista de tablas, columnas y sus tipos de datos en cada tabla, relación entre tablas, etc. Puede exportar con facilidad este archivo desde un flujo de datos, incluso si no tiene acceso a la estructura de carpetas de Common Data Model.
Puede utilizar este archivo JSON para migrar (o importar) el flujo de datos a otra área de trabajo o entorno.
Para obtener información exacta sobre lo que incluye el archivo de metadatos model.json, vaya a El archivo de metadatos (model.json) para Common Data Model.
Archivos de datos
Además del archivo de metadatos, la carpeta de flujo de datos incluye otras subcarpetas. Un flujo de datos almacena los datos de cada tabla de una subcarpeta con el nombre de la tabla. Los datos de una tabla pueden dividirse en varias particiones de datos, almacenadas en formato CSV.
Cómo ver o acceder a las carpetas de Common Data Model
Si usted utiliza flujos de datos que usan el almacenamiento proporcionado por el producto en el que se crearon, no tendrá acceso a esas carpetas directamente. En tales casos, para obtener datos de los flujos de datos hay que utiilzar el conector de flujo de datos de Microsoft Power Platform disponible en la experiencia Obtener datos del servicio Power BI, de Power Apps, de Power BI Desktop y productos de Dynamics 365 Customer Insights.
Para obtener información sobre cómo funcionan los flujos de datos y la integración interna de Data Lake Storage, vaya a Flujos de datos e integración de Azure Data Lake (versión preliminar)..
Si la organización habilitó flujos de datos para aprovechar su cuenta de Data Lake Storage y se seleccionó como destino de carga para flujos de datos, puede obtener datos del flujo de datos mediante el conector de flujo de datos de Power Platform como se mencionó anteriormente. Pero también puede acceder a la carpeta de Common Data Model del flujo de datos directamente a través del lago, incluso fuera de las herramientas y servicios de Power Platform. El acceso al lago es posible a través de Azure Portal, el Explorador de Microsoft Azure Storage o cualquier otro servicio o experiencia que admita Azure Data Lake Storage. Más información: Conexión a Azure Data Lake Storage Gen2 para el almacenamiento del flujo de datos
Pasos siguientes
Uso de Common Data Model para optimizar Azure Data Lake Storage Gen2
Agregar una carpeta de CDM a Power BI como flujo de datos (versión preliminar)
Conexión a Azure Data Lake Storage Gen2 para el almacenamiento del flujo de datos
Flujos de datos e integración de Azure Data Lake (versión preliminar)
Configuración de opciones de flujo de datos del área de trabajo (versión preliminar)