Comprender las diferencias entre los tipos de flujo de datos
Los flujos de datos se usan para extraer, transformar y cargar datos en un destino de almacenamiento donde se pueden aprovechar para diferentes escenarios. Dado que no todos los destinos de almacenamiento comparten las mismas características, algunas características y comportamientos de los flujos de datos difieren en función del destino de almacenamiento en el que los flujos de datos cargan los datos. Antes de crear un flujo de datos, es importante comprender cómo se van a usar los datos y elegir el destino de almacenamiento según los requisitos de la solución.
Al seleccionar un destino de almacenamiento de un flujo de datos, se determina el tipo del flujo de datos. Un flujo de datos que carga datos en tablas de Dataverse se clasifica como un flujo de datos estándar. Los flujos de datos que cargan datos en tablas analíticas se clasifican como un flujo de datos analítico.
Los flujos de datos creados en Power BI siempre son flujos de datos analíticos. Los flujos de datos creados en Power Apps pueden ser estándar o analíticos, en función de la selección al crear el flujo de datos.
Flujos de datos estándar
Un flujo de datos estándar carga datos en tablas de Dataverse. Los flujos de datos estándar solo se pueden crear en Power Apps. Una ventaja de crear este tipo de flujo de datos es que cualquier aplicación que dependa de los datos de Dataverse puede trabajar con los datos creados por flujos de datos estándar. Las aplicaciones típicas que utilizan las tablas de Dataverse son Power Apps, Power Automate, AI Builder y Power Virtual Agents.
Para crear flujos de datos en Power Apps:
En las pestañas Power Apps, seleccione Más.
Seleccione Flujos de datos.
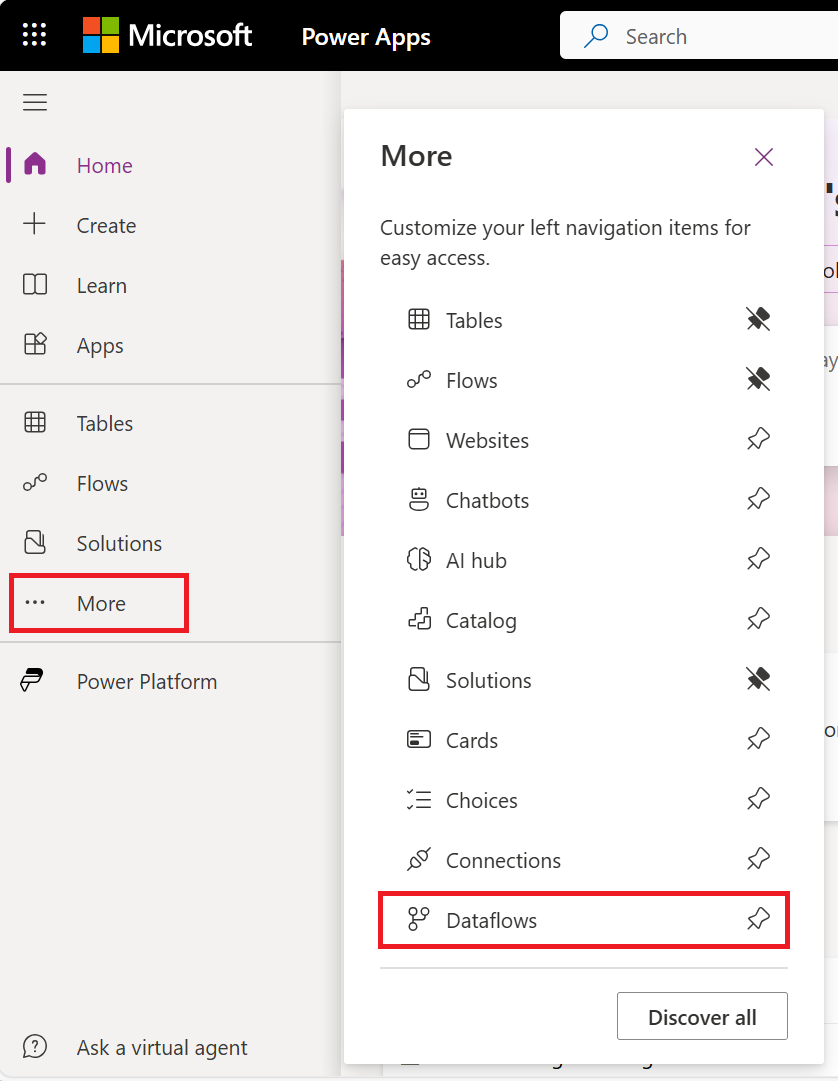
Seleccione Nuevo flujo de datos.
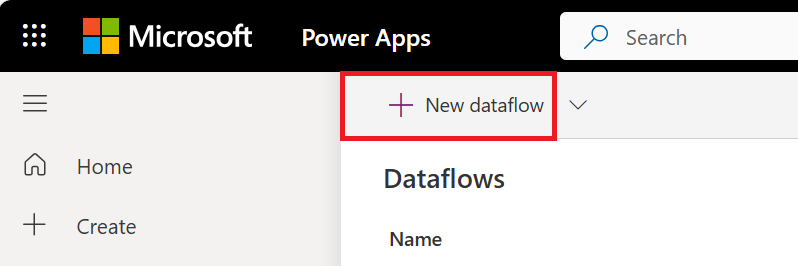
Si va a crear el primer flujo de datos, también puede seleccionar el botón Crear un flujo de datos.
Versiones de flujos de datos estándar
Nota:
Animamos a los usuarios del flujo de datos de Power Platform a migrar de flujos de datos V1 estándar a flujos de datos V2 estándar. Los flujos de datos V1 estándar se encuentran en una ruta de acceso a la compatibilidad discontinua en un futuro próximo. Para obtener más información sobre la migración a flujos de datos V2 estándar, vaya a Migración de un flujo de datos V1 estándar a un flujo de datos V2 estándar.
Hemos estado trabajando en actualizaciones significativas de flujos de datos estándar para mejorar su rendimiento y confiabilidad. Estas mejoras estarán disponibles finalmente para todos los flujos de datos estándar. No obstante, mientras tanto, diferenciaremos entre los flujos de datos estándar existentes (versión 1) y los nuevos flujos de datos estándar (versión 2) al agregar un indicador de versión en Power Apps.

Comparación de características de versiones de flujo de datos estándar
En la tabla siguiente se enumeran las principales diferencias de características entre los flujos de datos estándar V1 y V2, y se proporciona información sobre el comportamiento de cada característica en cada versión.
| Característica | V1 estándar | Standard V2 |
|---|---|---|
| Número máximo de flujos de datos que se pueden guardar con programación automática por inquilino de cliente | 50 | Ilimitado |
| Número máximo de registros ingeridos por consulta o tabla | 500.000 | Sin enlazar. El número máximo de registros que se pueden ingerir por consulta o tabla depende ahora de los límites de protección del servicio de Dataverse en el momento de la ingesta. |
| Velocidad de ingesta en Dataverse | Rendimiento de línea base | Rendimiento mejorado por algunos factores. Los resultados reales pueden variar y dependen de las características de los datos ingeridos y cargados en el servicio de Dataverse en el momento de la ingesta. |
| Directiva de actualización incremental | No compatible | Compatible |
| Resistencia | Cuando se encuentren límites de protección del servicio de Dataverse, se reintentará un registro hasta tres veces. | Cuando se encuentren límites de protección del servicio de Dataverse, se reintentará un registro hasta tres veces. |
| Integración con Power Automate | No compatible | Compatible |
Flujos de datos analíticos
Un flujo de datos analítico carga datos en tipos de almacenamiento optimizados para análisis: Azure Data Lake Storage. Los entornos de Microsoft Power Platform y las áreas de trabajo de Power BI proporcionan a los clientes una ubicación de almacenamiento analítico administrada que se incluye con esas licencias de productos. Además, los clientes pueden vincular la cuenta de almacenamiento de Azure Data Lake de su organización como destino para los flujos de datos.
Los flujos de datos analíticos son capaces de características analíticas adicionales. Por ejemplo, la integración con las características de IA de Power BI o el uso de tablas calculadas que se analizarán más adelante.
Puede crear flujos de datos analíticos en Power BI. De forma predeterminada, cargarán datos en el almacenamiento administrado de Power BI. Pero también puede configurar Power BI para almacenar los datos en el Azure Data Lake Storage de la organización.
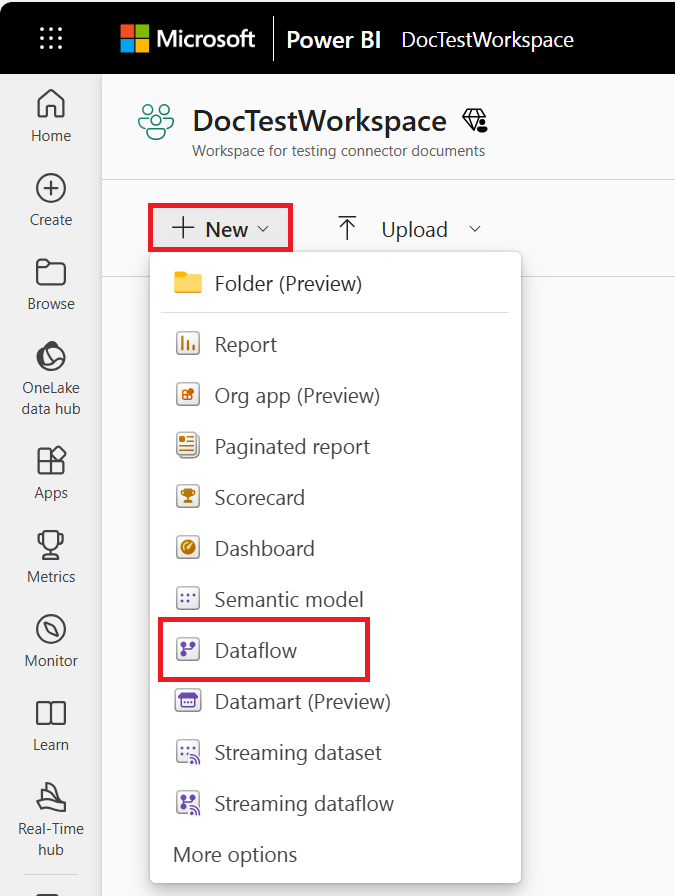
También puede crear flujos de datos analíticos en portales de Información de clientes de Power Apps y Dynamics 365. Al crear un flujo de datos en el portal de Power Apps, puede elegir entre el almacenamiento analítico administrado de Dataverse o la cuenta de Azure Data Lake Storage de su organización.
Integración con IA
A veces, según los requisitos, es posible que tenga que aplicar algunas funciones de inteligencia artificial y aprendizaje automático en los datos a través del flujo de datos. Estas funcionalidades están disponibles en flujos de datos de Power BI y requieren un área de trabajo Premium.

En los artículos siguientes se describe cómo utilizar funciones de inteligencia artificial en un flujo de datos:
- Integración de Azure Machine Learning en Power BI
- Cognitive Services en Power BI
- Aprendizaje automático automatizado en Power BI
Las funciones enumeradas en las dos secciones anteriores son específicas de Power BI y no están disponibles al crear un flujo de datos en los portales de información al cliente de Power Apps o Dynamics 365.
Tablas calculadas
Una de las razones para usar una tabla calculada es la capacidad de procesar grandes cantidades de datos. La tabla calculada ayuda en esos escenarios. Si tiene una tabla en un flujo de datos y otra tabla del mismo flujo de datos usa la salida de la primera tabla, esta acción crea una tabla calculada.
La tabla calculada ayuda con el rendimiento de las transformaciones de datos. En lugar de volver a realizar las transformaciones necesarias en la primera tabla varias veces, la transformación solo se realiza una vez en la tabla calculada. A continuación, el resultado se utiliza varias veces en otras tablas.
Para más información sobre las tablas calculadas, vaya a Creación de tablas calculadas en flujos de datos.
Las tablas calculadas solo están disponibles en un flujo de datos analítico.
Flujos de datos estándar frente a analíticos
En la tabla siguiente se enumeran algunas diferencias entre una tabla estándar y una tabla analítica.
| Operación | Estándar | Analíticos |
|---|---|---|
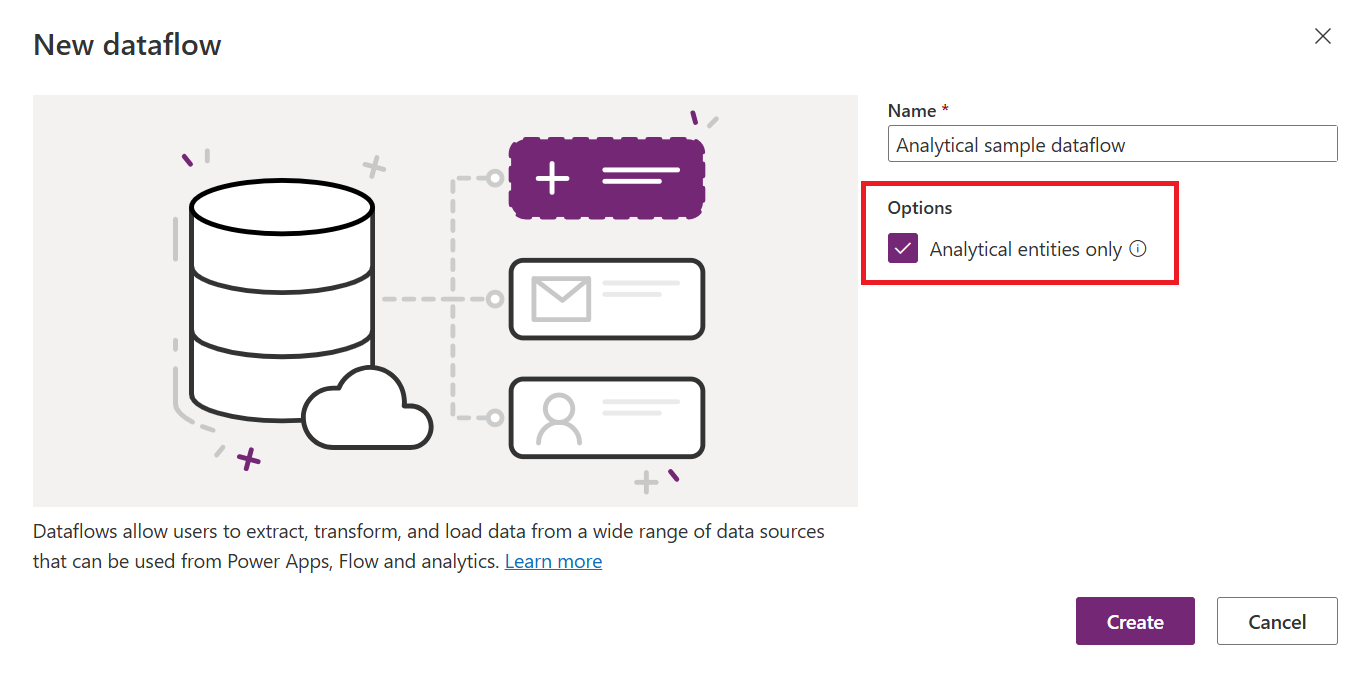
| Cómo crear | Flujos de datos de Power Platform | Flujos de datos de Power BI Flujos de datos de Power Platform activando la casilla Solo entidades analíticas al crear el flujo de datos |
| Opciones de almacenamiento | Dataverse | Power BI proporcionó Azure Data Lake Storage para flujos de datos de Power BI, Dataverse proporcionó Azure Data Lake Storage para flujos de datos de Power Platform o el cliente proporcionó Azure Data Lake Storage |
| Transformaciones de Power Query | Sí | Sí |
| Funciones de IA | No | Sí |
| Tabla calculada | No | Sí |
| Se puede utilizar en otras aplicaciones | Sí, a través de Dataverse | Flujos de datos de Power BI: solo en Power BI Flujos de datos de Power Platform o flujos de datos externos de Power BI: sí, a través de Azure Data Lake Storage |
| Asignación a tabla estándar | Sí | Sí |
| Carga incremental | Carga incremental predeterminada Es posible cambiarla mediante la casilla de verificación Eliminar filas que ya no existen en la salida de la consulta en la configuración de carga |
Carga completa predeterminada Es posible configurar la actualización incremental mediante la configuración de la actualización incremental en la configuración del flujo de datos |
| Actualización programada | Sí | Sí, la posibilidad de notificar el error a los propietarios del flujo de datos |
Escenarios para usar cada tipo de flujo de datos
Estos son algunos escenarios de ejemplo y recomendaciones de procedimientos recomendados para cada tipo de flujo de datos.
Uso multiplataforma: flujo de datos estándar
Si el plan para crear flujos de datos es usar datos almacenados en varias plataformas (no solo Power BI, sino también otros servicios de Microsoft Power Platform, Dynamics 365, etc.), un flujo de datos estándar es una gran opción. Los flujos de datos estándar almacenan los datos en Dataverse, a los que puede acceder a través de muchas otras plataformas y servicios.
Transformaciones de datos intensivas en tablas de datos grandes: flujo de datos analítico
Los flujos de datos analíticos son una excelente opción para procesar grandes cantidades de datos. Los flujos de datos analíticos también mejoran la capacidad de proceso detrás de la transformación. Tener los datos almacenados en Azure Data Lake Storage aumenta la velocidad de escritura en un destino. En comparación con Dataverse (que puede tener muchas reglas para comprobar en el momento del almacenamiento de datos), Azure Data Lake Storage es más rápido para las transacciones de lectura y escritura en una gran cantidad de datos.
Características de IA: flujo de datos analítico
Si planea usar cualquier funcionalidad de inteligencia artificial a través de la fase de transformación de datos, le resultará útil usar un flujo de datos analítico, ya que puede utilizar todas las características de inteligencia artificial compatibles con este tipo de flujo de datos.