Operador make-series
Se aplica a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Cree una serie de valores agregados especificados a lo largo de un eje definido.
Sintaxis
T | make-series [MakeSeriesParameters] [Column =] Aggregation [default = DefaultValue] [, ...] on AxisColumn [from start] [to end] step step [by [Column =] GroupExpression [, ...]]
Obtenga más información sobre las convenciones de sintaxis.
Parámetros
| Nombre | Type | Obligatorio | Descripción |
|---|---|---|---|
| Column | string |
Nombre de la columna de resultado. El valor predeterminado es un nombre derivado de la expresión. | |
| DefaultValue | escalar | Valor predeterminado que se va a usar en lugar de valores ausentes. Si no hay ninguna fila con valores específicos de AxisColumn y GroupExpression, se asignará un valor DefaultValue al elemento correspondiente de la matriz. El valor predeterminado es 0. | |
| Agregación | string |
✔️ | Llamada a una función de agregación como count() o avg(), con nombres de columna como argumentos. Consulte la lista de funciones de agregación. Solo las funciones de agregación que devuelven resultados numéricos se pueden usar con el operador make-series. |
| AxisColumn | string |
✔️ | Columna por la que se ordenará la serie. Normalmente, los valores de columna serán de tipo datetime o timespan, pero se aceptan todos los tipos numéricos. |
| start | escalares | ✔️ | Valor de límite inferior de AxisColumn para cada una de las series que se van a compilar. Si no se especifica start, será el primer rango, o paso, que tiene datos en cada serie. |
| end | escalares | ✔️ | Valor no inclusivo de límite superior de AxisColumn. El último índice de la serie temporal es menor que este valor y será start más un número entero múltiplo de step que sea menor que end. Si end no se especifica, será el límite superior del último rango, o paso, que tiene datos por cada serie. |
| step | escalares | ✔️ | La diferencia, o tamaño de rango, entre dos elementos consecutivos de la matriz AxisColumn. Para una lista de los intervalos de tiempo posibles, consulte el tipo de datos timespan. |
| GroupExpression | expresión sobre las columnas que proporciona un conjunto de valores únicos. Habitualmente se trata de un nombre de columna que ya proporciona un conjunto restringido de valores. | ||
| MakeSeriesParameters | Cero o más parámetros separados por espacios en forma de Valor de nombre = que controlan el comportamiento. Consulte Parámetros make-serie admitidos. |
Nota:
Los parámetros start, end y step se usan para crear una matriz de valores AxisColumn. La matriz consta de valores entre start y end, con el valor step que representa la diferencia entre un elemento de matriz y el siguiente. Todos los valores de agregación se ordenan en función de esta matriz.
Parámetros make-serie admitidos
| Nombre | Descripción |
|---|---|
kind |
Genera el resultado predeterminado cuando la entrada del operador make-series está vacía. Valor: nonempty |
hint.shufflekey=<key> |
La consulta shufflekey comparte la carga de consultas en los nodos del clúster mediante una clave para crear particiones de datos. Consulte la consulta aleatoria. |
Nota:
Las matrices generadas por make-series tienen una limitación de 1048576 valores (2^20). Si se intenta generar una matriz mayor con make-series, se producirá un error, o se truncará la matriz.
Sintaxis alternativa
T | make-series [Column =] Aggregation [default = DefaultValue] [, ...] on AxisColumn in range(start, stop, step) [by [Column =] GroupExpression [, ...]]
La serie generada a partir de la sintaxis alternativa es distinta de la sintaxis principal en dos aspectos:
- El valor stop incluye los extremos.
- La discretización el eje de índice se genera con la función bin() y no con bin_at(), por lo que es posible que start no se incluya en la serie generada.
Se recomienda usar la sintaxis principal de make-series, en lugar de la sintaxis alternativa.
Devoluciones
Las filas de entrada están organizadas en grupos que tienen los mismos valores que las expresiones by y la expresión bin_at(AxisColumn,step,start). A continuación, las funciones de agregación especificadas se calculan sobre cada grupo, generando una fila para cada grupo. El resultado contiene las columnas by, la columna AxisColumn y también al menos una columna para cada agregación procesada (No se admiten las agregaciones en varias columnas ni resultados no numéricos).
Este resultado intermedio tiene tantas filas como combinaciones únicas de by y valores bin_at(AxisColumn,step,start).
Por último, las filas del resultado intermedio organizadas en grupos que tienen los mismos valores de las expresiones by y todos los valores agregados se organizan en matrices (valores de tipo dynamic). Para cada agregación, hay una columna que contiene la matriz con el mismo nombre. La última columna es una matriz que contiene los valores de AxisColumn agrupados según el paso especificado.
Nota:
Aunque puede proporcionar expresiones arbitrarias para las expresiones de agregación y las de agrupación, resulta más eficaz usar nombres de columna simples.
Lista de funciones de agregación
| Función | Descripción |
|---|---|
| avg() | Devuelve un valor promedio de todo el grupo. |
| avgif() | Devuelve un promedio con el predicado del grupo. |
| count() | Devuelve un recuento del grupo. |
| countif() | Devuelve un recuento con el predicado del grupo. |
| dcount() | Devuelve un recuento único aproximado de los elementos del grupo. |
| dcountif() | Devuelve un recuento único aproximado con el predicado del grupo. |
| max() | Devuelve el valor máximo de todo el grupo |
| maxif() | Devuelve el valor máximo con el predicado del grupo. |
| min() | Devuelve el valor mínimo de todo el grupo |
| minif() | Devuelve el valor mínimo con el predicado del grupo. |
| percentile() | Devuelve el valor de percentil en el grupo |
| take_any() | Devuelve un valor aleatorio no vacío para el grupo. |
| stdev() | Devuelve la desviación estándar del grupo. |
| sum() | Devuelve la suma de los elementos dentro del grupo. |
| sumif() | Devuelve la suma de los elementos con el predicado del grupo. |
| variance() | Devuelve la varianza del grupo. |
Lista de funciones para el análisis de series temporales
| Función | Descripción |
|---|---|
| series_fir() | Aplica un filtro de respuesta finita al impulso. |
| series_iir() | Aplica un filtro de respuesta infinita al impulso. |
| series_fit_line() | Busca una línea recta que sea la mejor aproximación de la entrada. |
| series_fit_line_dynamic() | Busca una línea que sea la mejor aproximación de la entrada y devuelve un objeto dinámico. |
| series_fit_2lines() | Busca dos líneas que sean la mejor aproximación de la entrada. |
| series_fit_2lines_dynamic() | Busca dos líneas que sean la mejor aproximación de la entrada y devuelve un objeto dinámico. |
| series_outliers() | Puntúa los puntos de anomalía de una serie. |
| series_periods_detect() | Encuentra los periodos más importantes en una serie temporal. |
| series_periods_validate() | Comprueba si una serie temporal contiene patrones periódicos de longitudes concretas. |
| series_stats_dynamic() | Devuelve varias columnas con estadísticas comunes (mín./máx./varianza/desviación estándar/promedio). |
| series_stats() | Genera un valor dinámico con estadísticas comunes (mín./máx./varianza/desviación estándar/promedio). |
Para obtener una lista completa de funciones para el análisis de series, consulte: Funciones de procesamiento de series
Lista de funciones de interpolación de series
| Función | Descripción |
|---|---|
| series_fill_backward() | Realiza una interpolación de relleno hacia atrás de los valores faltantes en una serie. |
| series_fill_const() | Reemplaza los valores faltantes de una serie con un valor constante especificado. |
| series_fill_forward() | Realiza una interpolación de relleno hacia delante de los valores faltantes en una serie. |
| series_fill_linear() | Realiza una interpolación lineal de los valores faltantes en una serie. |
- Nota: De manera predeterminada, las funciones de interpolación suponen que
nulles un valor faltante. Por lo tanto, especifiquedefault=double(null) enmake-seriessi tiene previsto usar funciones de interpolación en la serie.
Ejemplos
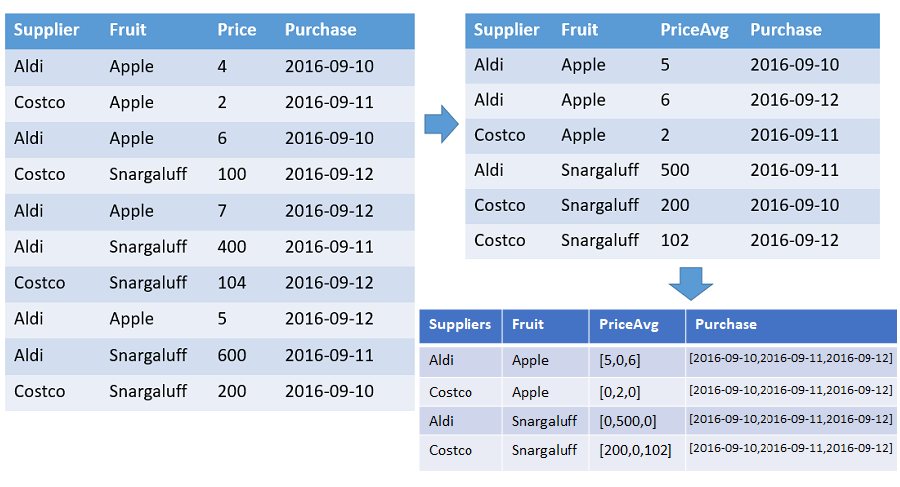
Una tabla que muestra matrices de los números y los precios promedio de cada fruta para cada uno de los proveedores ordenados por marca de tiempo con el intervalo especificado. Hay una fila en la salida para cada combinación única de frutas y proveedores. Las columnas de salida muestran las frutas, los proveedores y las matrices de: recuento, promedio y toda la escala de tiempo (de 2016-01-01 a 2016-01-10). Todas las matrices están ordenadas por la marca de tiempo correspondiente y todos los huecos se rellenan con los valores predeterminados (0 en este ejemplo). El resto de columnas de entrada se ignoran.
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | timestamp |
|---|---|
| [ 4,0, 3,0, 5,0, 0,0, 10,5, 4,0, 3,0, 8,0, 6,5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Cuando la entrada para make-series está vacía, el comportamiento predeterminado de make-series genera un resultado vacío.
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
Salida
| Count |
|---|
| 0 |
El uso de kind=nonempty en make-series generará un resultado no vacío de valores predeterminados:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
Salida
| avg_metric | timestamp |
|---|---|
| [ 1,0, 1,0, 1,0, 1,0, 1,0, 1,0, 1,0, 1,0, 1.0 ] |
[ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |