Usar la capacidad de enriquecimiento de notas clínicas sin estructura (versión preliminar) en soluciones de datos de atención sanitaria
[Este artículo es documentación preliminar y está sujeto a modificaciones].
Nota
Este contenido se está actualizando actualmente.
El enriquecimiento de notas clínicas sin estructura (versión preliminar) usa el servicio Text Analytics for Health del lenguaje de Azure AI para extraer entidades clave de Recursos Rápidos de Interoperabilidad en Salud (FHIR) de notas clínicas no estructuradas. Crea datos estructurados a partir de estas notas clínicas. A continuación, puede analizar estos datos estructurados para obtener información, predicciones y medidas de calidad destinadas a mejorar los resultados de salud de los pacientes.
Para obtener más información sobre la capacidad y comprender cómo implementarla y configurarla, consulte:
- Información general del enriquecimiento de notas clínicas sin estructura (versión preliminar)
- Implementar y configurar el enriquecimiento de notas clínicas sin estructura (versión preliminar)
El enriquecimiento de notas clínicas sin estructura (versión preliminar) tiene una dependencia directa de la funcionalidad Fundamentos de datos de Healthcare. Asegúrese de configurar y ejecutar correctamente primero las canalizaciones de Fundamentos de datos de Healthcare.
Requisitos previos
- Implementar soluciones de datos de atención sanitaria en Microsoft Fabric
- Instale los cuadernos básicos y las canalizaciones en Implementar fundamentos de datos de atención sanitaria.
- Configure el servicio de idioma de Azure como se explica en Configurar el servicio de idioma de Azure.
- Implementar y configurar el enriquecimiento de notas clínicas sin estructura (versión preliminar)
- Implementar y configurar las transformaciones de OMOP. Este paso es opcional.
Servicio de ingesta NLP
El cuaderno healthcare#_msft_ta4h_silver_ingestion ejecuta el módulo NLPIngestionService de la biblioteca de soluciones de datos de atención sanitaria para invocar el servicio Text Analytics for Health. Este servicio extrae notas clínicas no estructuradas del recurso de FHIR DocumentReference.Content para crear una salida plana. Para obtener más información, consulte Revisar la configuración del cuaderno.
Almacenamiento de datos en la capa plata
Después del análisis de la API de procesamiento del lenguaje natural (NLP), el resultado estructurado y aplanado se almacena en las siguientes tablas nativas dentro del almacén de lago healthcare#_msft_silver.
- nlpentity: contiene las entidades planas extraídas de las notas clínicas no estructuradas. Cada fila es un solo término extraído del texto no estructurado después de realizar el análisis de texto.
- nlprelationship: proporciona la relación entre las entidades extraídas.
- nlpfhir: contiene el paquete de salida FHIR como una cadena JSON.
Para realizar un seguimiento de la marca de tiempo de la última actualización, NLPIngestionService usa el campo parent_meta_lastUpdated en las tres tablas de almacén de lago plata. Este seguimiento garantiza que el documento de origen DocumentReference, que es el recurso principal, se almacene primero para mantener la integridad referencial. Este proceso ayuda a evitar incoherencias en los datos y recursos huérfanos.
Importante
Actualmente, Text Analytics for Health devuelve vocabularios enumerados en la Documentación de vocabulario de Metathesaurus de UMLS. Para obtener instrucciones sobre estos vocabularios, consulte Importar datos desde UMLS.
Para la versión preliminar, usamos las terminologías de SNOMED-CT (Nomenclatura sistematizada de medicina - Términos clínicos), LOINC (Identificadores, nombres y códigos de observación lógica) y RxNorm que se incluyen con el conjunto de datos de ejemplo de OMOP según la orientación de Observational Health Data Sciences and Informatics (OHDSI).
Transformación de OMOP
Las soluciones de datos de atención sanitaria en Microsoft Fabric también proporcionan otra capacidad para las transformaciones de Observational Medical Outcomes Partnership (OMOP). Al ejecutar esta capacidad, la transformación subyacente del almacén de lago platea al almacén de lago oro OMOP también transforma la salida estructurada y aplanada del análisis de notas clínicas no estructuradas. La transformación lee la tabla nlpentity del almacén de lago de plata y asigna la salida a la tabla NOTE_NLP del almacén de lago OMOP.
Para obtener más información, consulte Información general de las transformaciones de OMOP.
Este es el esquema para las salidas NLP estructuradas, con la correspondiente asignación de columnas NOTE_NLP al modelo de datos común OMOP:
| Referencia de documento plano | Descripción | Asignación Note_NLP | Datos de ejemplo |
|---|---|---|---|
| id | Identificador único para la entidad Clave compuesta de parent_id, offset y length. |
note_nlp_id |
1380 |
| parent_id | Clave externa del texto documentreferencecontent aplanado del que se extrajo el término. | note_id |
625 |
| texto | Texto de entidad tal como aparece en el documento. | lexical_variant |
Sin alergias conocidas |
| Desplazamiento | Desplazamiento de caracteres del término extraído en el texto documentreferencecontent de entrada. | offset |
294 |
| data_source_entity_id | Id. de la entidad en el catálogo de origen especificado. | note_nlp_concept_id y note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | La fecha de procesamiento del análisis de texto de documentreferencecontent. | nlp_date_time y nlp_date |
2023-05-17T00:00:00.0000000 |
| modelo | Nombre y versión del sistema de NLP (Nombre del sistema de PNL de Text Analytics for Health y la versión). | nlp_system |
MSFT TA4H |

Límites de servicio de Text Analytics for Health
- El número máximo de caracteres por documento está limitado a 125 000.
- El tamaño máximo de los documentos contenidos en toda la solicitud está limitado a 1 MB.
- El número máximo de documentos por solicitud está limitado a:
- 25 para la API basada en web.
- 1000 para el contenedor.
Habilitar registros
Siga estos pasos para habilitar el registro de solicitudes y respuestas para la API de Text Analytics for Health:
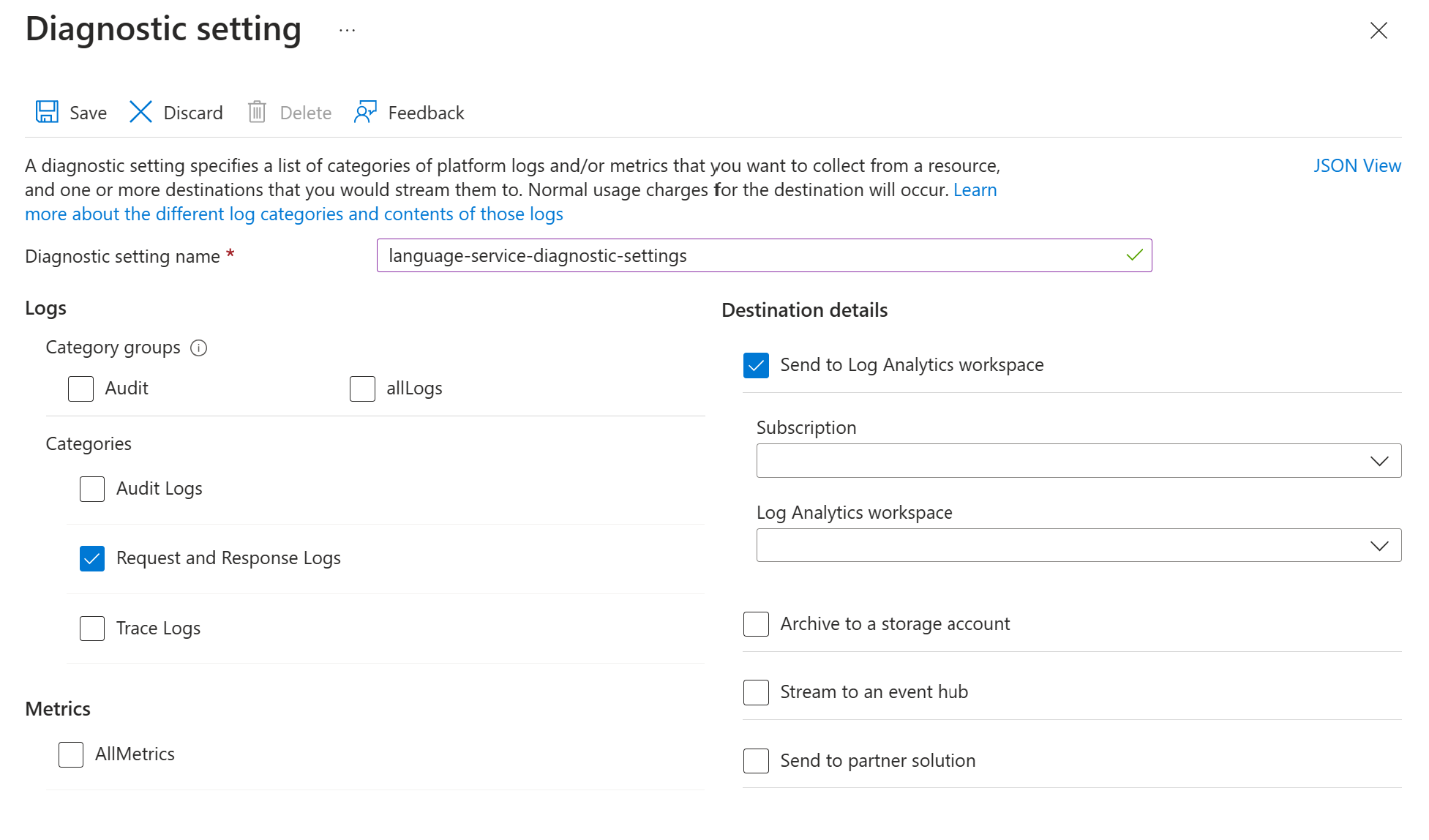
Habilite la configuración de diagnóstico para el recurso de servicio de idioma de Azure siguiendo las instrucciones de Habilitar el registro de diagnóstico para servicios de Azure AI. Este recurso es el mismo servicio de idioma que creó durante el paso de implementación Configurar el servicio de idioma de Azure.
- Escriba un nombre para la configuración de diagnóstico.
- Establezca la categoría en Registros de solicitud y respuesta.
- Para obtener detalles sobre el destino, seleccione Enviar al área de trabajo de Log Analytics y seleccione el área de trabajo de Log Analytics requerida. Si no tiene un espacio de trabajo, siga las indicaciones para crear uno.
- Guardar la configuración.
Vaya a la sección Configuración de NLP en el cuaderno del servicio de ingesta de NLP. Actualice el valor del parámetro de configuración
enable_text_analytics_logsaTrue. Para obtener más información acerca de este cuaderno, consulte Revisar la configuración del cuaderno.

Ver registros en Azure Log Analytics
Para explorar los datos de análisis de registros:
- Navegue a su espacio de trabajo de Log Analytics.
- Busque y seleccione Registros. En esta página, puede ejecutar consultas en sus registros.
Consulta de ejemplo
A continuación se muestra una consulta básica de Kusto que puede usar para explorar los datos de registro. Esta consulta de ejemplo recupera todas las solicitudes con error del proveedor de recursos de Cognitive Services Azure en el último día, agrupadas por tipo de error:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature