Adición de un origen de Apache Kafka a una secuencia de eventos (versión preliminar)
En este artículo se muestra cómo agregar el origen de Apache Kafka a una secuencia de eventos.
Apache Kafka es una plataforma distribuida de código abierto para crear sistemas de datos escalables y en tiempo real. Al integrar Apache Kafka como origen dentro del flujo de eventos, puede traer sin problemas eventos en tiempo real de Apache Kafka y procesarlos antes de enrutarlos a varios destinos dentro de Fabric.
Nota:
Este origen no se admite en las siguientes regiones de su capacidad de área de trabajo: Oeste de EE. UU. 3, Oeste de Suiza.
Requisitos previos
- Acceso al área de trabajo de Fabric con permisos de colaborador o superior.
- Un clúster de Apache Kafka en ejecución.
- Apache Kafka debe ser accesible públicamente y no estar detrás de un firewall o protegido en una red virtual.
Nota:
El número máximo de orígenes y destinos para una secuencia de eventos es 11.
Adición de Apache Kafka como origen
En Inteligencia en tiempo real de Fabric, seleccione Eventstream para crear un flujo de eventos.
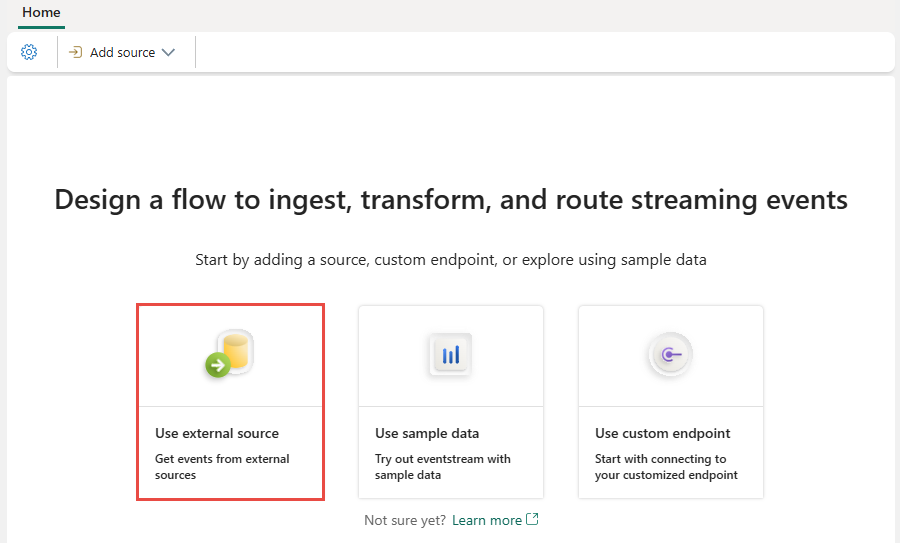
En la siguiente pantalla, seleccione Agregar origen externo.
Configuración y conexión a Apache Kafka
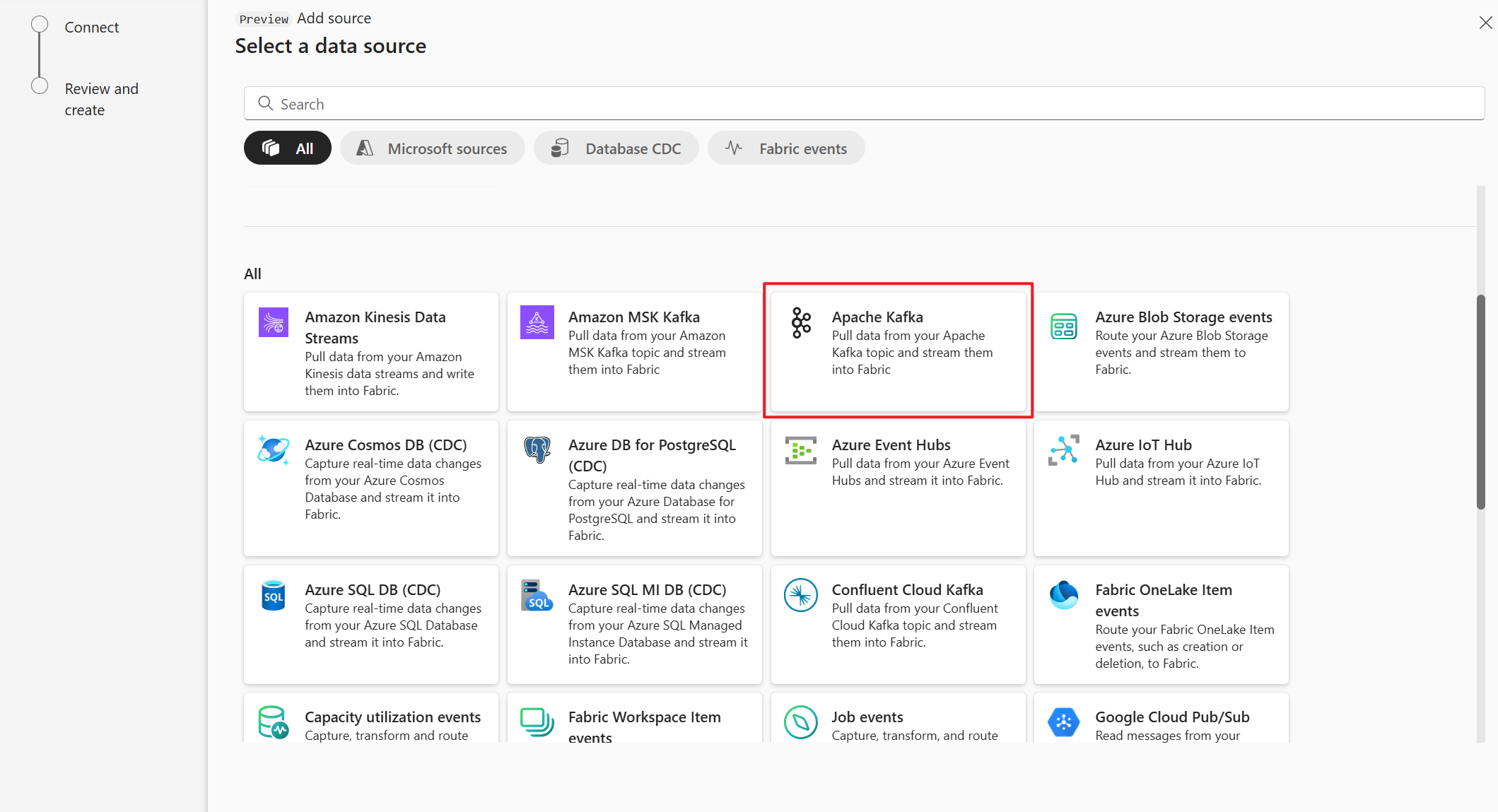
En la página Seleccionar un origen de datos, seleccione Apache Kafka.
En la página Conectar, seleccione Nueva conexión.
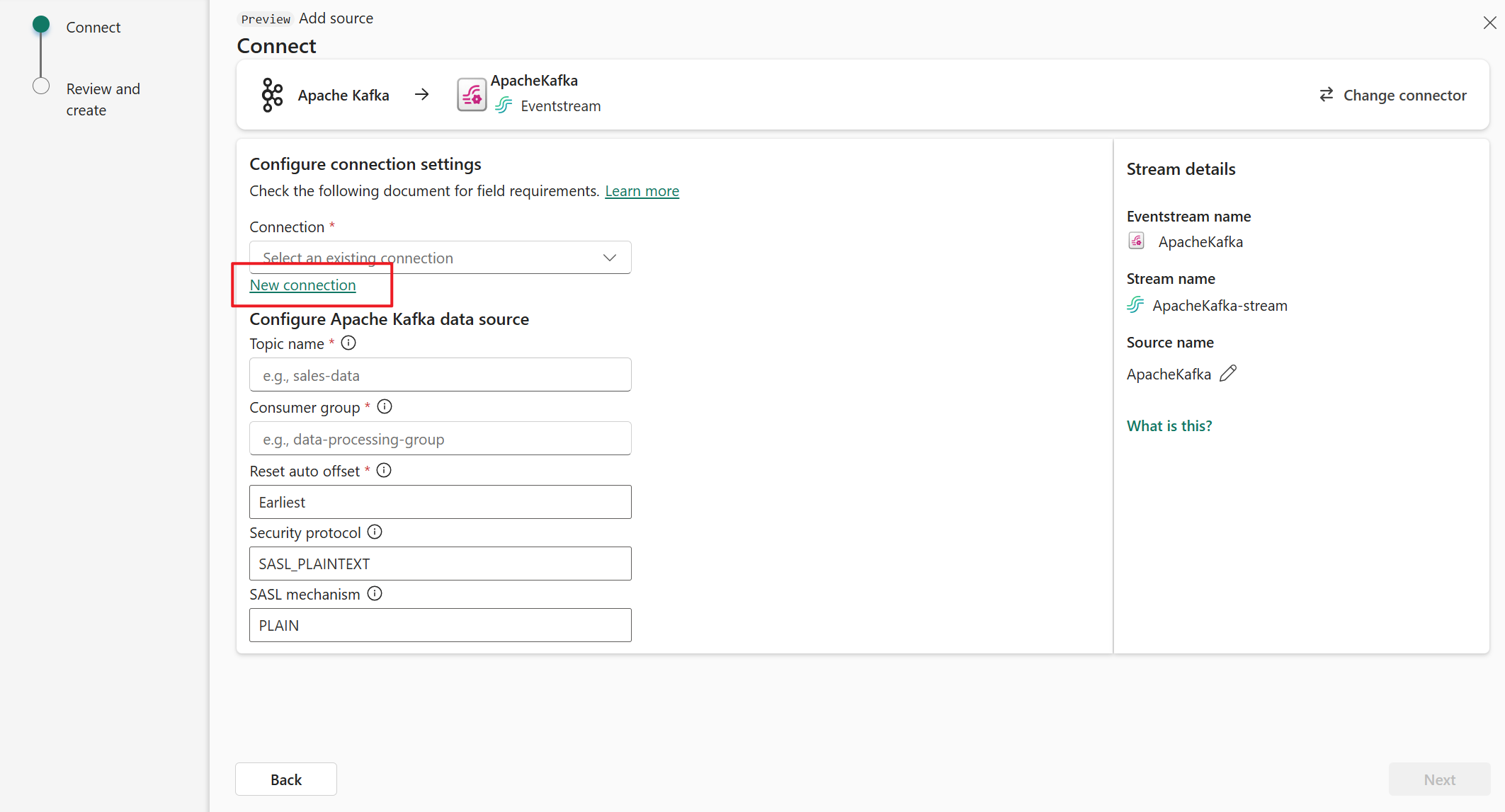
En la sección Configuración de conexión, en Arranque de servidor, escriba la dirección del servidor de Apache Kafka.

En la sección Credenciales de conexión, si tiene una conexión existente al clúster de Apache Kafka, selecciónela en la lista desplegable de Conexión. De lo contrario, siga estos pasos:
- Para Nombre de conexión, introduzca un nombre para la conexión.
- En Tipo de autenticación, confirme que está seleccionada la clave de API.
- En Clave y Secreto, escriba la clave de API y el secreto de clave.
Seleccione Conectar.
Ahora, en la página Conectar, sigue estos pasos.
En Tema, escriba el tema de Kafka.
En Grupo de consumidores, escriba el grupo de consumidores del clúster de Apache Kafka. Este campo proporciona un grupo de consumidores dedicado para obtener eventos.
Seleccione Restablecer desplazamiento automático para especificar dónde empezar a leer desplazamientos si no hay ninguna confirmación.
En Protocolo de seguridad, el valor predeterminado es SASL_PLAINTEXT.
Nota:
Actualmente, el origen de Apache Kafka solo admite la transmisión de datos sin cifrar (SASL_PLAINTEXT y PLAINTEXT) entre el clúster de Apache Kafka y Eventstream. La compatibilidad con la transmisión de datos cifrada a través de SSL estará disponible pronto.
El mecanismo SASL predeterminado suele ser PLAIN, a menos que se configure lo contrario. Puede seleccionar el mecanismo SCRAM-SHA-256 o SCRAM-SHA-512 que se adapte a sus requisitos de seguridad.

Seleccione Siguiente. En la pantalla Revisar y crear, revise el resumen y, a continuación, seleccione Agregar.

Visualización de eventstream actualizado
Puede ver el origen de Apache Kafka agregado a la secuencia de eventos en Modo de edición.

Después de completar estos pasos, el origen de Apache Kafka está disponible para su visualización en la vista en directo.

Contenido relacionado
Otros conectores:
- Flujos de datos de Amazon Kinesis
- Azure Cosmos DB
- Azure Event Hubs
- Azure IoT Hub
- Captura de datos modificados de la base de datos Azure SQL
- Punto de conexión personalizado
- Google Cloud Pub/Sub
- CDC de base de datos de MySQL
- CDC de base de datos de PostgreSQL
- Datos de ejemplo
- Eventos de Azure Blob Storage
- Evento de área de trabajo de Fabric