Ingesta de datos en OneLake y análisis con Azure Databricks
En esta guía, hará lo siguiente:
Cree una canalización en un área de trabajo e ingiera datos en OneLake en formato Delta.
Lea y modifique una tabla Delta en OneLake con Azure Databricks.
Requisitos previos
Antes de comenzar, debe tener:
Un área de trabajo con un elemento de Lakehouse.
Un área de trabajo premium de Azure Databricks. Solo las áreas de trabajo premium de Azure Databricks admiten el acceso directo de credenciales de Microsoft Entra. Al crear el clúster, habilite el paso de credenciales de Azure Data Lake Storage en las Opciones avanzadas.
Un conjunto de datos de muestra.
Ingesta de datos y modificación de la tabla Delta
Vaya a su almacén de lago en el servicio Power BI y seleccione Obtener datos y, a continuación, seleccione Nueva canalización de datos.
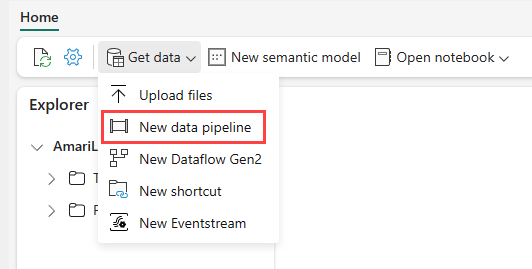
En el símbolo del sistema Nueva canalización, escriba un nombre para la nueva canalización y, a continuación, seleccione Crear.
Para este ejercicio, seleccione los datos de ejemplo NYC Taxi: Verde como origen de datos y, a continuación, seleccione Siguiente.
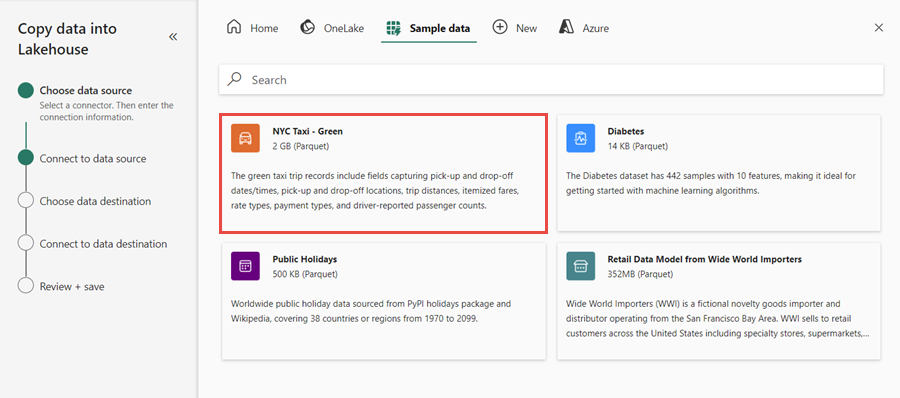
En la pantalla de vista previa, seleccione Siguiente.
Para el destino de datos, seleccione el nombre del almacén de lago que desea usar para almacenar los datos de la tabla OneLake Delta. Puede elegir un almacén de lago existente o crear uno nuevo.
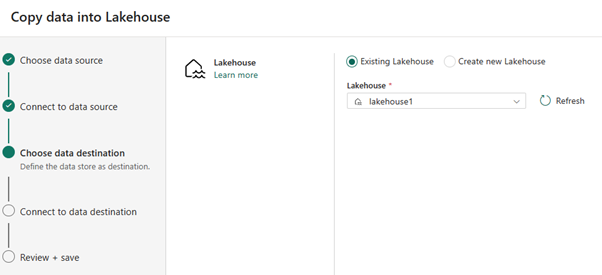
Seleccione dónde quiere almacenar la salida. Elija Tablas como carpeta raíz y escriba "nycsample" como nombre de tabla.
En la pantalla Revisar y guardar, seleccione Iniciar transferencia de datos inmediatamente y, a continuación, seleccione Guardar y ejecutar.
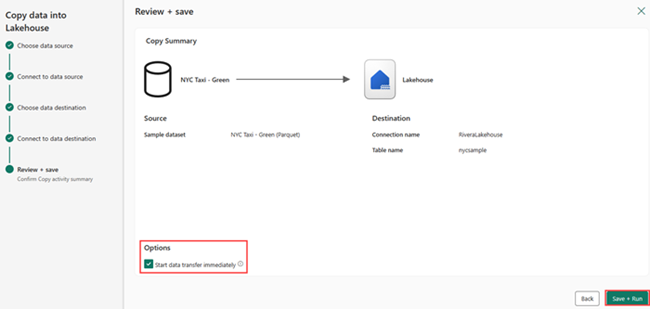
Una vez completado el trabajo, vaya a su almacén de lago y vea la tabla delta que aparece en la /carpeta Tables.
Haga clic con el botón derecho en el nombre de la tabla creada, seleccione Propiedades y copie la ruta de acceso del sistema de archivos de objetos binarios de Azure (ABFS).
Abra el cuaderno de Azure Databricks. Lea la tabla Delta en OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Actualice los datos de la tabla Delta cambiando un valor de campo.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;