Transformación de datos con Apache Spark y consulta con SQL
En esta guía, hará lo siguiente:
Cargar datos en OneLake con el explorador de archivos de OneLake.
Usar un cuaderno de Fabric para leer datos en OneLake y reescribir como una tabla delta.
Analizar y transformar datos con Spark mediante un cuaderno de Fabric.
Consultar una copia de datos en OneLake con SQL.
Requisitos previos
Antes de comenzar:
Descargar e instalar el explorador de archivos de OneLake.
Crear un área de trabajo con un elemento de lago de datos.
Descargar el conjunto de datos WideWorldImportersDW. Puede usar el Explorador de Azure Storage para conectarse a
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityy descargar el conjunto de archivos csv. También puede usar sus propios datos csv y actualizar los detalles según sea necesario.
Nota:
Siempre cree, cargue o cree un acceso directo a los datos de Delta-Parquet directamente en la sección Tablas del lago de datos. No anide las tablas en las subcarpetas de la sección Tablas, ya que el lago de datos no la reconocerá como una tabla y la etiquetará como No identificada.
Carga, lectura, análisis y consulta de datos
En el explorador de archivos de OneLake, vaya al lago de datos y, en el directorio
/Files, cree un subdirectorio denominadodimension_city.
Copie los archivos csv de ejemplo en el directorio
/Files/dimension_cityde OneLake mediante el explorador de archivos de OneLake.
Vaya al lago de datos en el servicio Power BI y vea los archivos.
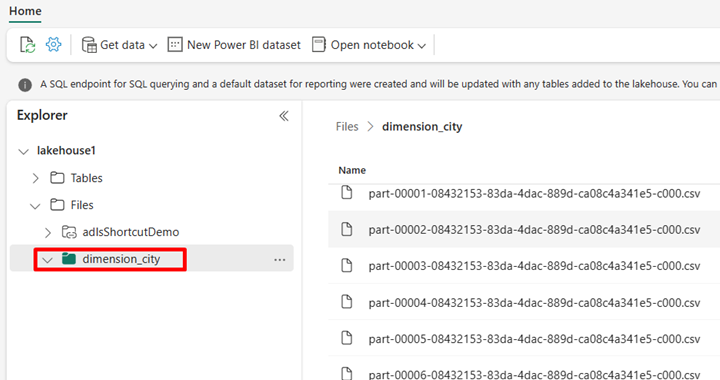
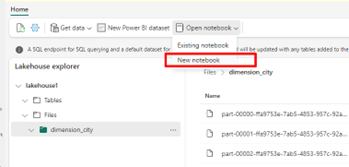
Seleccione Abrir cuaderno y , después, Nuevo cuaderno para crear un cuaderno.
Con el cuaderno de Fabric, convierta los archivos csv en formato delta. El siguiente fragmento de código lee los datos del directorio creado por el usuario
/Files/dimension_cityy lo convierte en una tabla deltadim_city.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Para ver la nueva tabla, actualice la vista del
/Tablesdirectorio.
Consulte la tabla con SparkSQL en el mismo cuaderno de Fabric.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Modifique la tabla delta agregando una nueva columna denominada newColumn con un tipo de datos entero. Establezca el valor 9 para todos los registros de esta columna recién agregada.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;También puede acceder a cualquier tabla delta en OneLake a través de un punto de conexión de análisis SQL. Este punto de conexión de análisis SQL hace referencia a la misma copia física de la tabla delta en OneLake y ofrece la experiencia de T-SQL. Seleccione el punto de conexión de análisis SQL para lakehouse1 y, a continuación, seleccione Nueva consulta SQL para consultar la tabla mediante T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
