Exploración de datos en la base de datos reflejada con cuadernos
Puede explorar los datos replicados desde la base de datos reflejada con consultas de Spark en cuadernos.
Los cuadernos son un elemento de código eficaz para que pueda desarrollar trabajos de Apache Spark y experimentos de aprendizaje automático en los datos. Puede usar cuadernos en Fabric Lakehouse para explorar las tablas reflejadas.
Requisitos previos
- Complete el tutorial para crear una base de datos reflejada a partir de la base de datos de origen.
- Tutorial: Configuración de la base de datos reflejada de Microsoft Fabric para Azure Cosmos DB (versión preliminar)
- Tutorial: Configuración de bases de datos reflejadas en Microsoft Fabric desde Azure Databricks (versión preliminar)
- Tutorial: Configuración de bases de datos reflejadas en Microsoft Fabric desde Azure SQL Database
- Tutorial: Configuración de bases de datos reflejadas de Microsoft Fabric desde Azure SQL Managed Instance (versión preliminar)
- Tutorial: Configuración de bases de datos reflejadas de Microsoft Fabric desde Snowflake
Crear un acceso directo
En primer lugar, debe crear un acceso directo desde las tablas reflejadas en Lakehouse y, después, crear cuadernos con consultas de Spark en Lakehouse.
En el portal de Fabric, abra Ingeniero de datos.
Si aún no tiene una instancia de Lakehouse creada, seleccione Lakehouse y cree una instancia de Lakehouse; para ello, asígnele un nombre.
Seleccione Obtener datos ->Nueva combinación de teclas.
Seleccione Microsoft OneLake.
Puede ver todas las bases de datos reflejadas en el área de trabajo de Fabric.
Seleccione la base de datos reflejada que quiere agregar a Lakehouse como combinación de teclas.
Seleccione las tablas deseadas de la base de datos reflejada.
Seleccione Siguiente y, después, Crear.
En el Explorador, ahora puede ver los datos de la tabla seleccionados en la instancia de Lakehouse.
Sugerencia
Puede agregar otros datos directamente en Lakehouse o traer combinaciones de teclas como S3 o ADLS Gen2. Puede ir al punto de conexión de SQL Analytics de Lakehouse y unir los datos en todos estos orígenes con datos reflejados sin problemas.
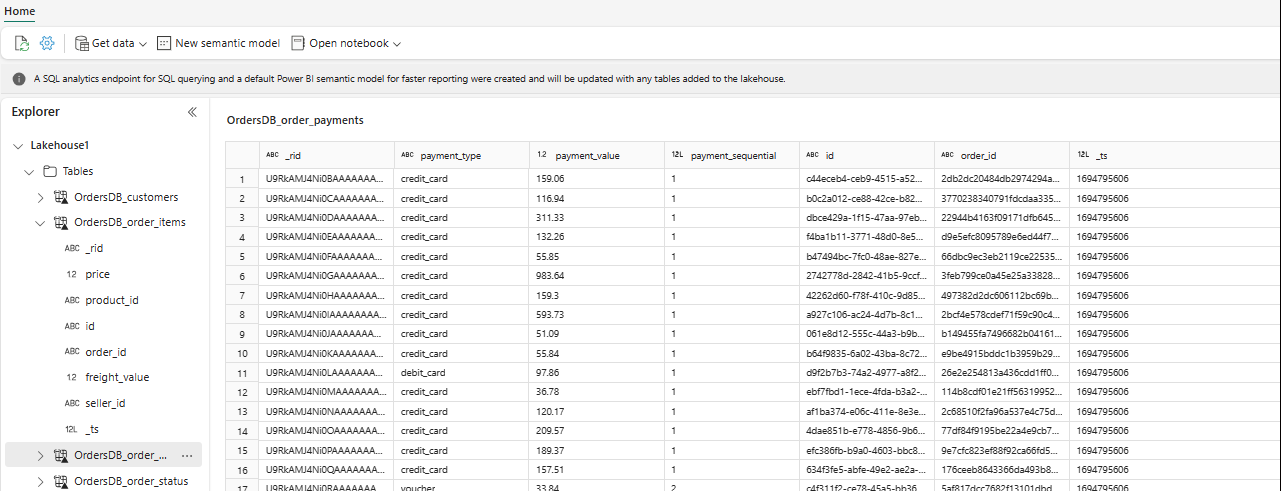
Para explorar estos datos en Spark, seleccione los
...puntos situados junto a cualquier tabla. Seleccione Nuevo cuaderno o Cuaderno existente para comenzar el análisis.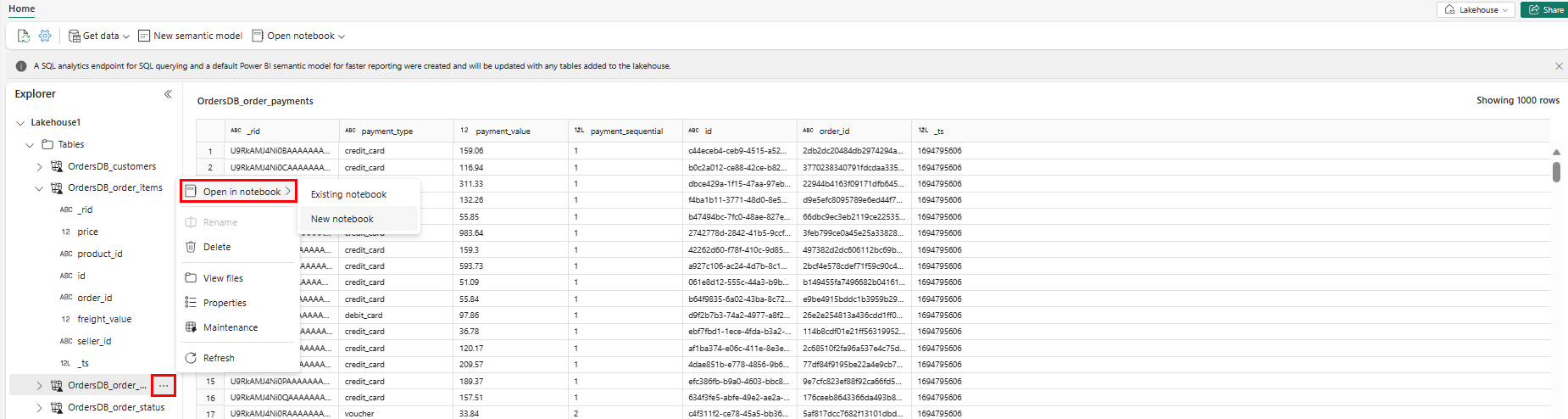
El cuaderno se abrirá automáticamente y cargará el DataFrame con una consulta
SELECT ... LIMIT 1000de Spark SQL.- Los nuevos cuadernos pueden tardar hasta dos minutos en cargarse completamente. Puede evitar este retraso mediante un cuaderno existente con una sesión activa.
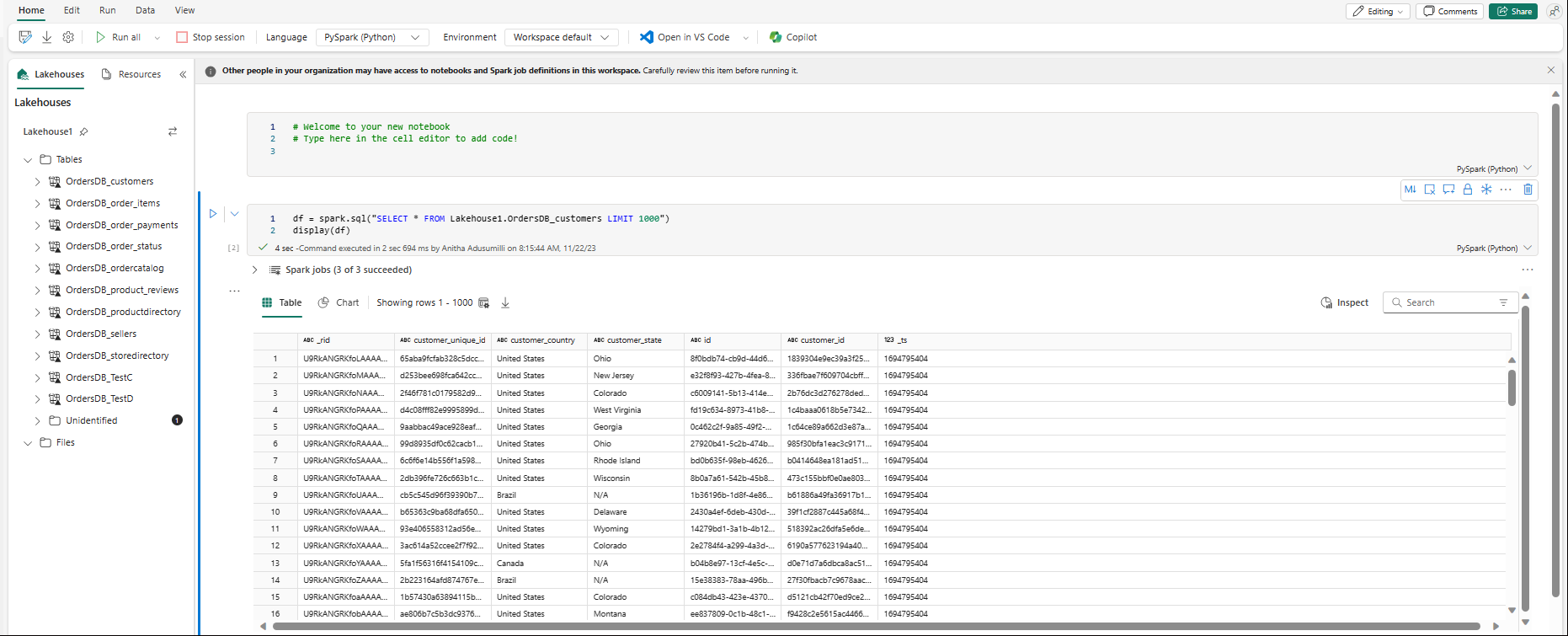
- Los nuevos cuadernos pueden tardar hasta dos minutos en cargarse completamente. Puede evitar este retraso mediante un cuaderno existente con una sesión activa.


