Tutorial: Configuración de dbt para el almacén de datos de Fabric
Se aplica a:✅Almacenamiento de Microsoft Fabric
Este tutorial le guía por la configuración de dbt e implementación del primer proyecto en una instancia de Fabric Warehouse.
Introducción
dbt (Herramienta de compilación de datos) es un marco de código abierto que simplifica la transformación de datos y la ingeniería de análisis. Se centra en las transformaciones basadas en SQL dentro de la capa de análisis, tratando SQL como código. dbt admite el control de versiones, la modularización, las pruebas y la documentación.
El adaptador de dbt para Microsoft Fabric se puede usar para crear proyectos dbt, que luego se pueden implementar en una instancia de Fabric Data Warehouse.
También puede cambiar la plataforma de destino para el proyecto dbt simplemente cambiando el adaptador, por ejemplo; un proyecto creado para el grupo de SQL dedicado de Azure Synapse se puede actualizar en unos segundos a una instancia de Fabric Data Warehouse.
Requisitos previos para el adaptador de dbt para Microsoft Fabric
Siga esta lista para instalar y configurar los requisitos previos de dbt:
La última versión del adaptador dbt-fabric del repositorio PyPI (Python Package Index) mediante
pip install dbt-fabric.pip install dbt-fabricNota:
Cambiando
pip install dbt-fabricapip install dbt-synapsey siguiendo las siguientes instrucciones, puede instalar el adaptador dbt para el grupo SQL dedicado de Synapse .Asegúrese de verificar que dbt-fabric y sus dependencias estén instaladas mediante el comando
pip list:pip listSe debe devolver una larga lista de los paquetes y las versiones actuales de este comando.
Si aún no tiene una, cree un Warehouse. Puede utilizar la capacidad de prueba para este ejercicio: regístrese para la prueba gratuita de Microsoft Fabric , cree un área de trabajo y, a continuación, cree un almacén.
Introducción al adaptador de dbt-fabric
Este aprendizaje utiliza Visual Studio Code, pero puede utilizar la herramienta que prefiera.
Clone el proyecto jaffle_shop demo dbt en la máquina.
- Puede clonar un repositorio con el control de origen integrado de Visual Studio Code .
- O, por ejemplo, puede utilizar el comando
git clone:
git clone https://github.com/dbt-labs/jaffle_shop.gitAbra la carpeta de proyecto
jaffle_shopen Visual Studio Code.
Puede omitir el registro si ya ha creado un almacén.
Cree un archivo
profiles.yml. Añada la siguiente configuración aprofiles.yml. Este archivo configura la conexión al almacenamiento en Microsoft Fabric mediante el adaptador dbt-fabric.config: partial_parse: true jaffle_shop: target: fabric-dev outputs: fabric-dev: authentication: CLI database: <put the database name here> driver: ODBC Driver 18 for SQL Server host: <enter your SQL analytics endpoint here> schema: dbo threads: 4 type: fabricNota:
Cambie el
typedefabricasynapsepara cambiar el adaptador de base de datos a Azure Synapse Analytics, si lo desea. Cualquier plataforma de datos del proyecto DBT existente se puede actualizar cambiando el adaptador de base de datos. Para obtener más información, consulte la lista dbt de plataformas de datos compatibles .Autentíquese en Azure en el terminal de Visual Studio Code.
- Ejecute
az loginen la terminal de Visual Studio Code si está utilizando la autenticación de Azure CLI. - Para la autenticación de la entidad de servicio o de otra instancia de Microsoft Entra ID (anteriormente Azure Active Directory) en Microsoft Fabric, consulte Configuración de dbt (Herramienta de complicación de datos) y Configuraciones de recursos de dbt. Para más información, vea Autenticación de Microsoft Entra como alternativa a la autenticación de SQL en Microsoft Fabric.
- Ejecute
Ahora está listo para probar la conectividad. Ejecute
dbt debugen el terminal de Visual Studio Code para probar la conectividad con su almacén.dbt debug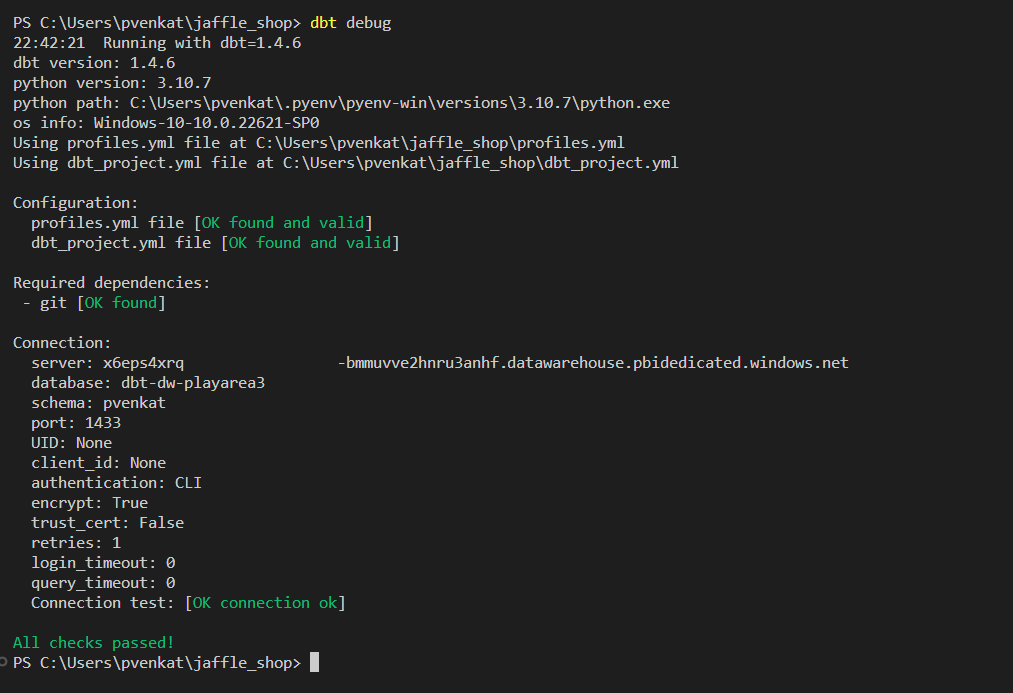
Todas las comprobaciones se pasan, lo que significa que puede conectar el almacén mediante el adaptador dbt-fabric desde el proyecto de
jaffle_shopdbt.Ahora, es el momento de probar si el adaptador funciona o no. Primero ejecute
dbt seedpara insertar datos de muestra en el almacén.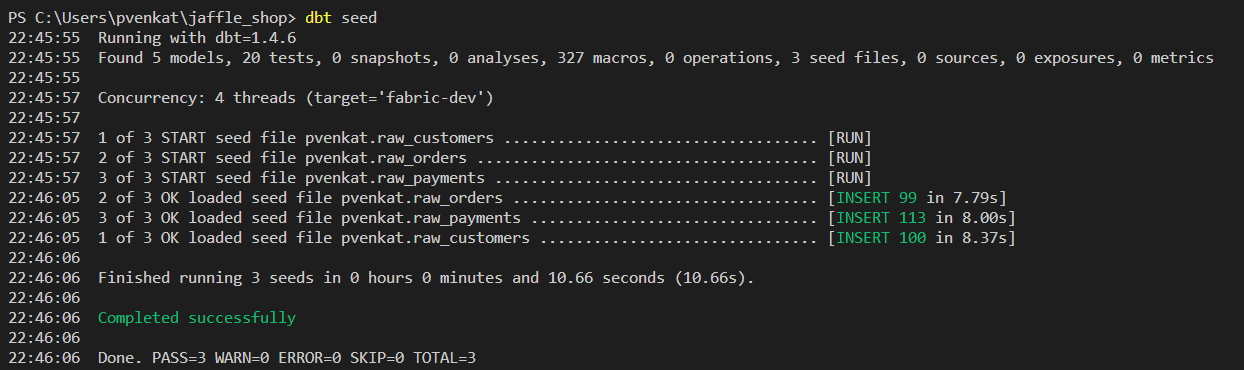
Ejecute
dbt runpara validar los datos contra algunas pruebas.dbt run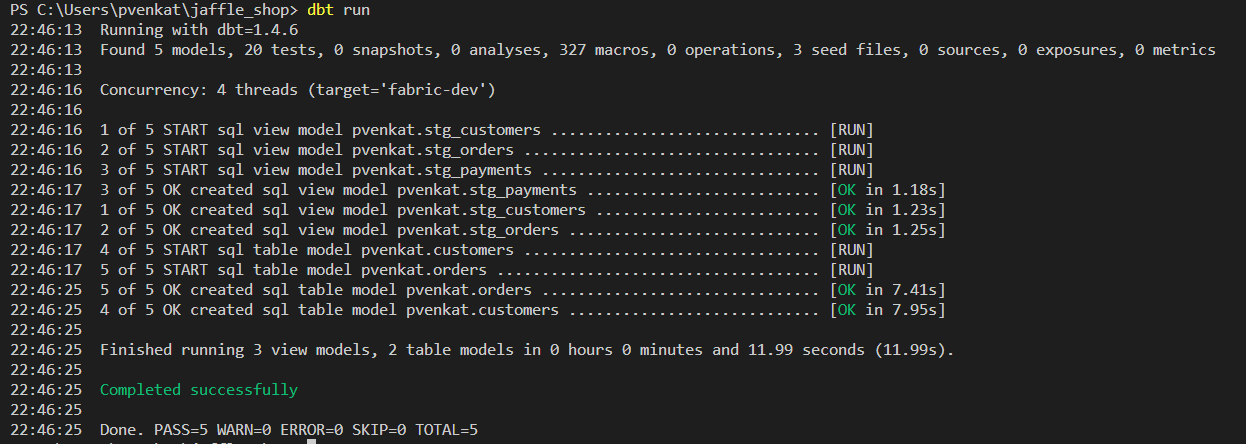
Ejecute
dbt testpara ejecutar los modelos definidos en el proyecto dbt de demostración.dbt test




Ahora ha implementado un proyecto de dbt en Fabric Data Warehouse.
Movimiento entre almacenes diferentes
Es sencillo mover el proyecto dbt entre diferentes almacenes. Un proyecto dbt en cualquier almacenamiento compatible se puede migrar rápidamente con este proceso de tres pasos:
Instale el nuevo adaptador. Para obtener más información e instrucciones de instalación completas, consulte Adaptadores dbt .
Actualice la propiedad
typeen el archivoprofiles.yml.Compile el proyecto.
dbt en Fabric Data Factory
Cuando se integra con Apache Airflow, un popular sistema de administración de flujos de trabajo, dbt se convierte en una herramienta eficaz para orquestar transformaciones de datos. Las funcionalidades de programación y administración de tareas de Airflow permiten a los equipos de datos automatizar las ejecuciones de dbt. Garantiza actualizaciones de datos periódicas y mantiene un flujo coherente de datos de alta calidad para el análisis y los informes. Este enfoque combinado, mediante la experiencia de transformación de dbt con la administración del flujo de trabajo de Airflow, ofrece canalizaciones de datos eficaces y sólidas, lo que en última instancia conduce a decisiones controladas por datos más rápidas y detalladas.
Apache Airflow es una plataforma de código abierto que se usa para crear, programar y supervisar flujos de trabajo de datos complejos mediante programación. Permite definir un conjunto de tareas, denominadas operadores, que se pueden combinar en grafos acíclicos dirigidos (DAG) para representar canalizaciones de datos.
Para obtener más información sobre cómo poner en marcha dbt con el almacén, consulte el artículo sobre cómo transformar datos mediante dbt con Data Factory en Microsoft Fabric.
Consideraciones
Aspectos importantes que se deben tener en cuenta al usar el adaptador de dbt-fabric:
Revise las limitaciones actuales en el almacenamiento de datos de Microsoft Fabric .
Fabric admite la autenticación de Microsoft Entra ID (anteriormente Azure Active Directory) para entidades de seguridad de usuario, identidades de usuario y entidades de servicio. El modo de autenticación recomendado para trabajar interactivamente en el almacenamiento es la CLI (interfaces de línea de comandos) y usar entidades de servicio para la automatización.
Revise los comandos T-SQL (Transact-SQL) no admitidos en Fabric Data Warehouse.
Algunos comandos T-SQL son compatibles con el adaptador de estructura dbt-fabric mediante comandos
Create Table as Select(CTAS),DROPyCREATEcomoALTER TABLE ADD/ALTER/DROP COLUMN,MERGE,TRUNCATEysp_rename.Revise Tipos de datos no admitidos para obtener información sobre los tipos de datos admitidos y no admitidos.
Puede registrar problemas en el adaptador dbt-fabric de GitHub visitando Issues · microsoft/dbt-fabric · GitHub.