Transformar datos mediante bdt
Nota:
El trabajo de Apache Airflow funciona con Apache Airflow.
dbt(Data Build Tool) es una interfaz de línea de comandos (CLI) de código abierto que simplifica la transformación y el modelado de datos dentro de almacenes de datos administrando código SQL complejo de una manera estructurada y fácil de mantener. Permite a los equipos de datos crear transformaciones fiables y que se pueden probar en el núcleo de sus canalizaciones analíticas.
Cuando se empareja con Apache Airflow, las funcionalidades de transformación de dbt se mejoran mediante las características de programación, organización y administración de tareas de Airflow. Este enfoque combinado, mediante la experiencia de transformación de dbt junto con la administración de flujos de trabajo de Airflow, ofrece canalizaciones de datos eficaces y sólidas, lo que en última instancia conduce a decisiones controladas por datos más rápidas y más detalladas.
En este tutorial se muestra cómo crear un DAG de Apache Airflow que usa dbt para transformar los datos almacenados en Microsoft Fabric Data Warehouse.
Requisitos previos
Para empezar, debe completar los siguientes requisitos previos:
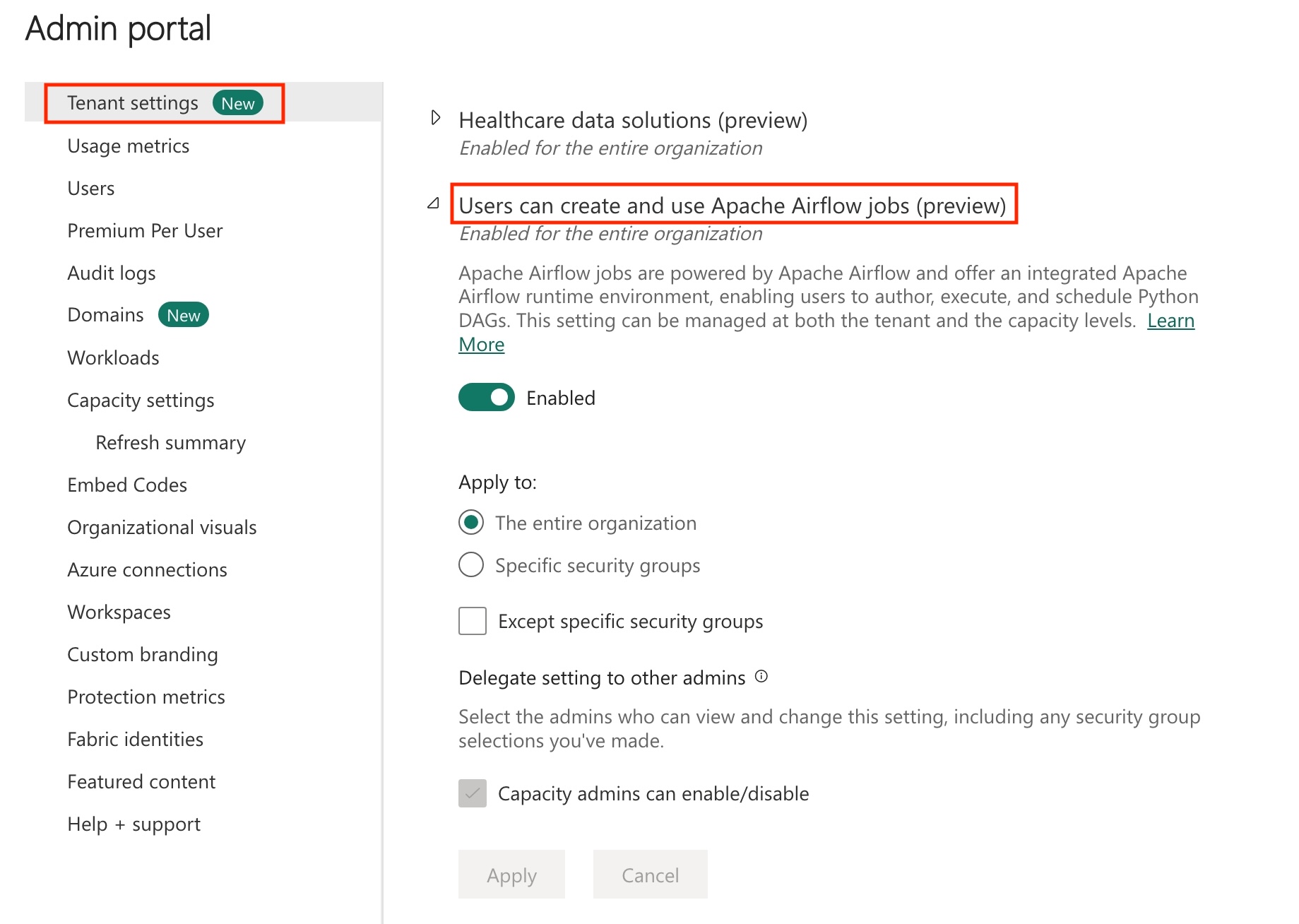
Habilite el trabajo de Apache Airflow en el inquilino.
Nota:
Dado que el trabajo de Apache Airflow está en estado de versión preliminar, debe habilitarlo a través del administrador de inquilinos. Si ya ve trabajo de Apache Airflow, es posible que el administrador de inquilinos ya lo haya habilitado.
Vaya a Administración Portal ->Configuración del inquilino ->En Microsoft Fabric -> expanda la sección "Los usuarios pueden crear y usar el trabajo de Apache Airflow (versión preliminar)".
Seleccione Aplicar.
Creación de la entidad de servicio. Agregue la entidad de servicio como
Contributoren el área de trabajo donde se crea el almacenamiento de datos.Si no tiene uno, cree un almacenamiento de Fabric. Ingiera los datos de muestra en el almacén mediante la canalización de datos. Para este tutorial, utilizamos la muestra de NYC Taxi-Green.

Transformación de los datos almacenados en Fabric Warehouse mediante dbt
Esta sección le lleva por los siguientes pasos:
- Especificación de los requisitos.
- Crear un proyecto de dbt en el almacenamiento administrado de Fabric que proporcionado el trabajo de Apache Airflow.
- Creación de un DAG de Apache Airflow para orquestar trabajos de dbt
Especificación de los requisitos
Cree un archivo requirements.txt en la carpeta dags. Agregue los siguientes paquetes como requisitos de Apache Airflow.
astronomer-cosmos: este paquete se utiliza para ejecutar los proyectos principales de dbt como grupos de tareas y DAG de Apache Airflow.
dbt-fabric: este paquete se usa para crear un proyecto de dbt, que luego se puede implementar en un almacenamiento de datos de Fabric.
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Creación de un proyecto de dbt en el almacenamiento administrado de Fabric que proporciona el trabajo de Apache Airflow
En esta sección, creamos un proyecto dbt de ejemplo en el trabajo de Apache Airflow para el conjunto de datos
nyc_taxi_greencon la siguiente estructura de directorios.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetCree la carpeta denominada
nyc_taxi_greenen la carpetadagscon el archivoprofiles.yml. Esta carpeta contiene todos los archivos necesarios para el proyecto de dbt.
Copie el contenido siguiente en
profiles.yml. Este archivo de configuración contiene los detalles y las perfiles de conexión de base de datos que utiliza dbt. Actualice los valores del marcador de posición y guarde el archivo.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>Cree el archivo
dbt_project.ymly copie el siguiente contenido. Este archivo especifica la configuración del proyecto.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tableCree la carpeta
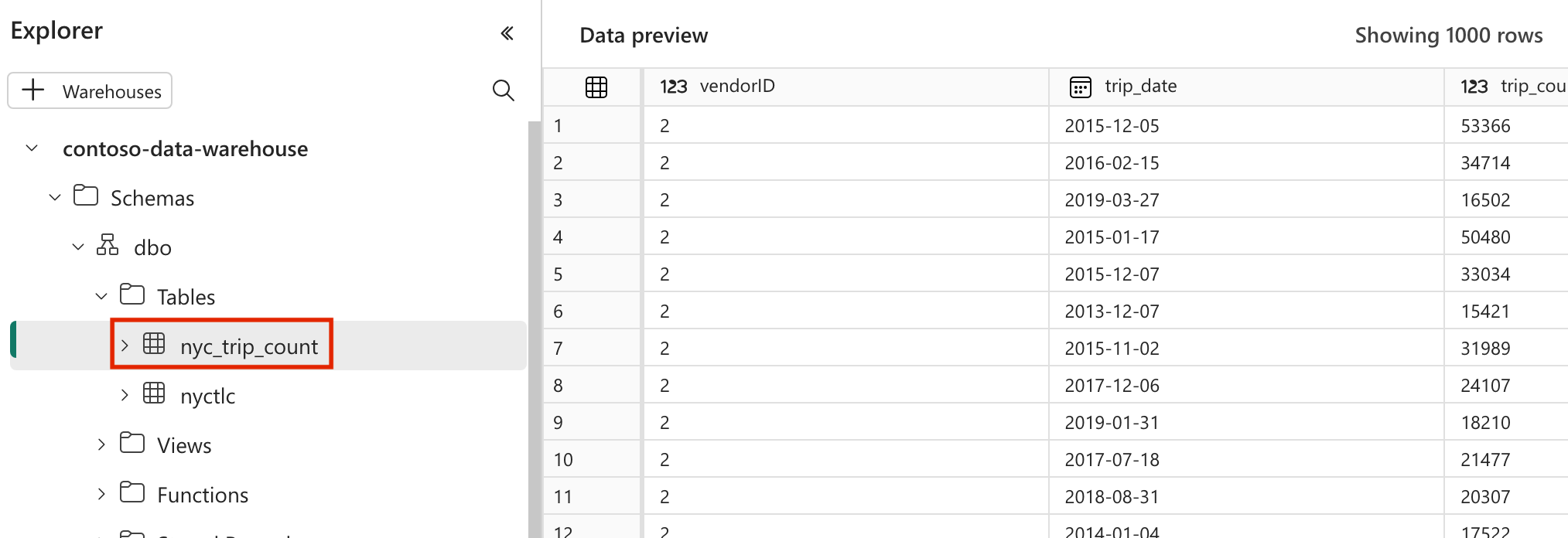
modelsen la carpetanyc_taxi_green. En este tutorial, creamos el modelo de muestra en el archivo denominadonyc_trip_count.sqlque crea la tabla que muestra el número de viajes por día y proveedor. Copie el siguiente contenido en el archivo.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Creación de un DAG de Apache Airflow para orquestar trabajos de dbt
Crea el archivo denominado
my_cosmos_dag.pyen la carpetadagsy pega el siguiente contenido en ella.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
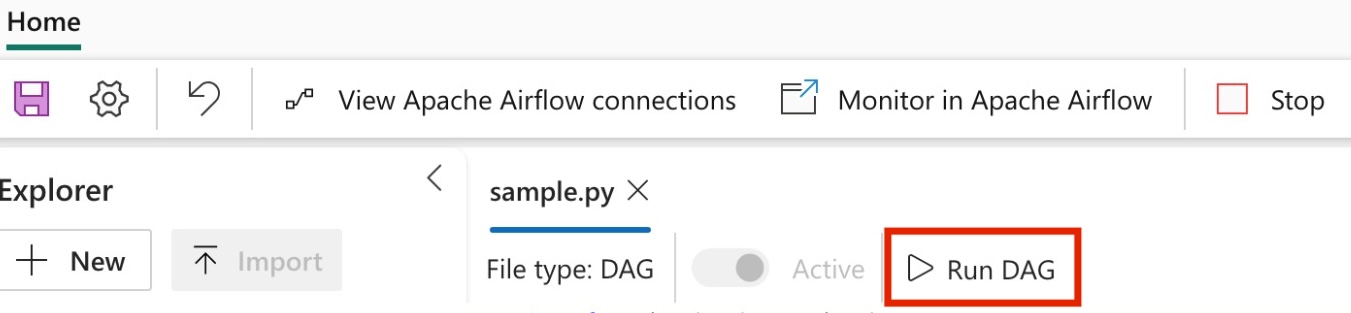
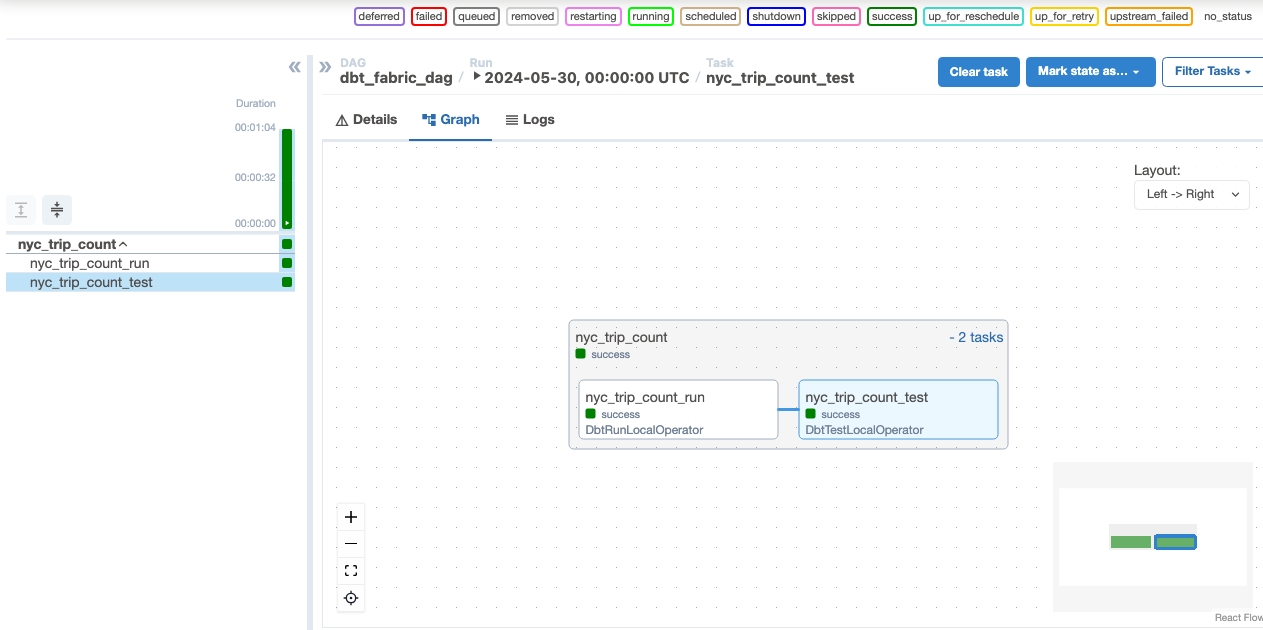
Ejecución del DAG
Ejecuta el DAG en el trabajo de Apache Airflow.
Para ver el dag cargado en la interfaz de usuario de Apache Airflow, haga clic en
Monitor in Apache Airflow.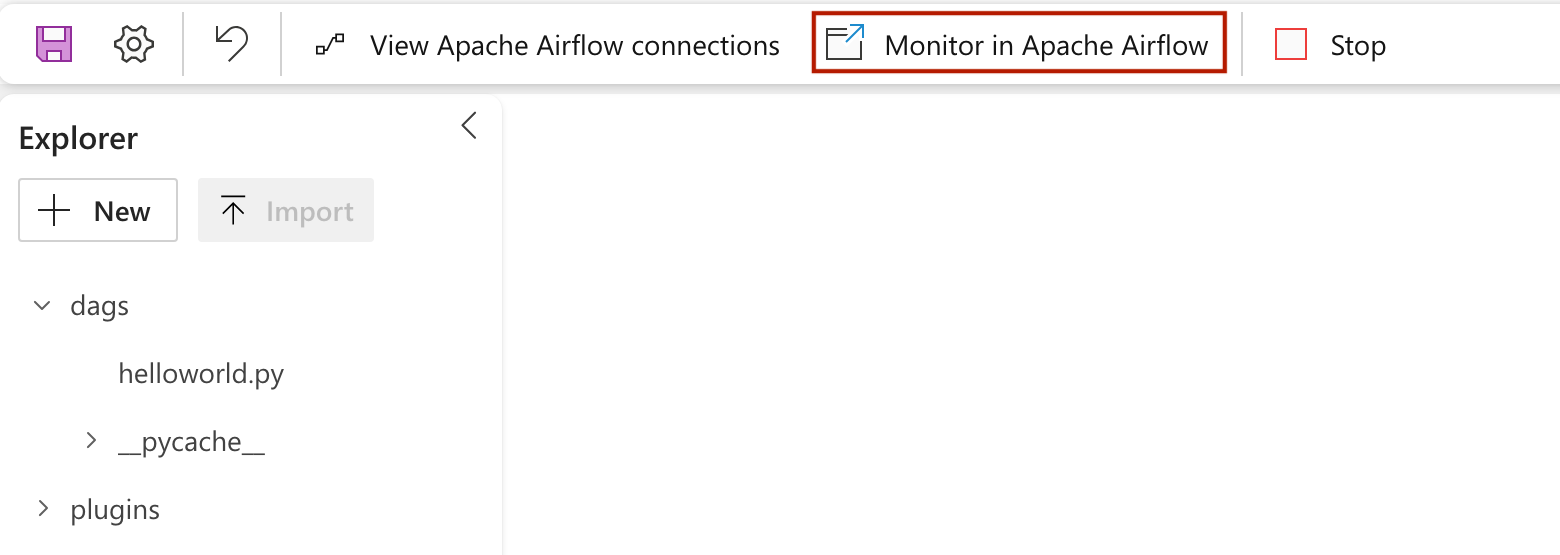



Validación de los datos
- Después de una ejecución correcta, para validar los datos, puede ver la nueva tabla denominada "nyc_trip_count.sql" creada en el almacenamiento de datos de Fabric.