Tutorial: Descubrir relaciones en el conjunto de datos Synthea mediante el vínculo semántico
En este tutorial se muestra cómo detectar relaciones en el conjunto de datos público synthea, mediante el vínculo semántico.
Al trabajar con nuevos datos o trabajar sin un modelo de datos existente, puede resultar útil detectar relaciones automáticamente. Esta detección de relaciones puede ayudarle a:
- comprender el modelo en un nivel alto,
- obtener más información durante el análisis de datos exploratorios,
- validar datos actualizados o nuevos, datos entrantes y
- limpiar datos.
Incluso si las relaciones se conocen de antemano, una búsqueda de relaciones puede ayudar a comprender mejor el modelo de datos o la identificación de problemas de calidad de los datos.
En este tutorial, comenzará con un ejemplo de línea base simple en el que experimentará con solo tres tablas para que las conexiones entre ellas sean fáciles de seguir. A continuación, se muestra un ejemplo más complejo con un conjunto de tablas más grande.
En este tutorial, aprenderá a:
- Use componentes de la biblioteca de Python del vínculo semántico (SemPy) que admiten la integración con Power BI y ayudan a automatizar el análisis de datos. Estos componentes incluyen:
- FabricDataFrame: una estructura similar a Pandas mejorada con información semántica adicional.
- Funciones para extraer modelos semánticos de un espacio de trabajo de Fabric en tu cuaderno.
- Funciones que automatizan la detección y visualización de relaciones en los modelos semánticos.
- Solucionar problemas en el proceso de descubrimiento de relaciones para los modelos semánticos con múltiples tablas e interdependencias.
Prerrequisitos
Obtenga una suscripción a Microsoft Fabric . También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Use el conmutador de experiencia en la parte inferior izquierda de la página principal para cambiar a Fabric.

- Seleccione Áreas de trabajo en el panel de navegación izquierdo para buscar y seleccionar el área de trabajo. Esta área de trabajo se convertirá en el área de trabajo actual.
Seguimiento en el cuaderno
El cuaderno relationships_detection_tutorial.ipynb acompaña a este tutorial.
Para abrir el cuaderno complementario de este tutorial, siga las instrucciones de Preparación del sistema para los tutoriales de ciencia de datos a fin de importar el cuaderno a su área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar una instancia de lakehouse al cuaderno antes de empezar a ejecutar código.
Configuración del cuaderno
En esta sección, configurará un entorno de cuaderno con los módulos y datos necesarios.
Instale
SemPydesde PyPI mediante la funcionalidad de instalación en línea%pipen el cuaderno:%pip install semantic-linkRealice las importaciones necesarias de los módulos SemPy que necesitará más adelante:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Importe Pandas para aplicar una opción de configuración que ayude con el formato de salida:
import pandas as pd pd.set_option('display.max_colwidth', None)Incorpore los datos de ejemplo. En este tutorial, usará el conjunto de datos Synthea de registros médicos sintéticos (versión pequeña para simplificar):
download_synthea(which='small')
Detección de relaciones en un pequeño subconjunto de tablas de Synthea
Seleccione tres tablas de un conjunto mayor:
patientsespecifica la información del pacienteencountersespecifica los pacientes que tuvieron encuentros médicos (por ejemplo, una cita médica, un procedimiento)providersespecifica qué proveedores médicos atendieron a los pacientes
La tabla
encountersresuelve una relación de varios a varios entrepatientsyproviders, y se puede describir como una entidad asociativa:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')Busque relaciones entre las tablas mediante la función
find_relationshipsde SemPy:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsVisualice las relaciones DataFrame como un grafo mediante la función
plot_relationship_metadatade SemPy.plot_relationship_metadata(suggested_relationships)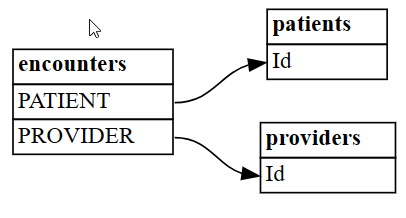
La función establece la jerarquía de relaciones desde el lado izquierdo hasta el lado derecho, que corresponde a las tablas "from" y "to" de la salida. En otras palabras, las tablas de origen independientes del lado izquierdo usan sus claves externas para apuntar a sus tablas de dependencias de destino en el lado derecho. Cada cuadro de entidad muestra columnas que participan en el lado de origen o de destino de una relación.
De forma predeterminada, las relaciones se generan como "m:1" (no como "1:m") o "1:1". Las relaciones "1:1" se pueden generar de una o ambas maneras, dependiendo de si la proporción de valores asignados a todos los valores supera
coverage_thresholden una o ambas direcciones. Más adelante en este tutorial, tratarás el caso menos frecuente de las relaciones "m:m".

Solución de problemas de detección de relaciones
En el ejemplo de referencia se muestra una detección exitosa de relaciones en datos limpios Synthea. En la práctica, los datos rara vez están limpios, lo que impide la detección correcta. Hay varias técnicas que pueden ser útiles cuando los datos no están limpios.
En esta sección de este tutorial se aborda la detección de relaciones cuando el modelo semántico contiene datos sucios.
Comience manipulando los dataframes originales para obtener datos "sucios" e imprima el tamaño de los datos sucios.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Para comparar, los tamaños de impresión de las tablas originales:
print(len(patients)) print(len(providers))Busque relaciones entre las tablas mediante la función
find_relationshipsde SemPy:find_relationships([patients_dirty, providers_dirty, encounters])La salida del código muestra que no se detectan relaciones debido a los errores que introdujo anteriormente para crear el modelo semántico "sucio".
Uso de la validación
La validación es la mejor herramienta para solucionar errores de detección de relaciones porque:
- Informa claramente por qué una relación determinada no sigue las reglas de clave foránea, por lo cual no puede ser detectada.
- Se ejecuta rápidamente con modelos semánticos grandes porque solo se centra en las relaciones declaradas y no realiza una búsqueda.
La validación puede usar cualquier DataFrame con columnas similares a las generadas por find_relationships. En el código siguiente, el suggested_relationships DataFrame hace referencia a patients en lugar de patients_dirty, pero puede establecer un alias en los objetos DataFrame con un diccionario:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Criterios de búsqueda flexible
En situaciones más confusas, puede intentar relajar los criterios de búsqueda. Este método aumenta la posibilidad de falsos positivos.
Establezca
include_many_to_many=Truey evalúe si ayuda a:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Los resultados muestran que se detectó la relación de
encountersapatients, pero hay dos problemas:- La relación indica una dirección de
patientsaencounters, que es un inverso de la relación esperada. Esto se debe a que todos lospatientsresultaron estar cubiertos porencounters(Coverage Fromes 1,0), mientras queencounterssolo están cubiertos parcialmente porpatients(Coverage To= 0,85), ya que faltan filas correspondientes a los pacientes. - Se produce una coincidencia accidental en una columna de cardinalidad baja
GENDER, que coincide por nombre y valor en ambas tablas, pero no es una relación "m:1" de interés. La cardinalidad baja se indica medianteUnique Count FromyUnique Count Tocolumnas.
- La relación indica una dirección de
Vuelva a ejecutar
find_relationshipspara buscar solo las relaciones "m:1", pero con uncoverage_threshold=0.5inferior:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)El resultado muestra la dirección correcta de las relaciones de
encountersaproviders. Sin embargo, no se detecta la relación deencountersapatients, porquepatientsno es única, por lo que no puede estar en el lado "Uno" de la relación "m:1".Flexibilice tanto
include_many_to_many=Truecomocoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Ahora ambas relaciones de interés son visibles, pero hay mucho más ruido:
- Está presente una coincidencia de cardinalidad baja en
GENDER. - Aparece una coincidencia de cardinalidad más alta de "m:m" en
ORGANIZATIONlo que hace que sea evidente queORGANIZATIONse trate probablemente de una columna desnormalizada en ambas tablas.
- Está presente una coincidencia de cardinalidad baja en
Empareja los nombres de columnas
De forma predeterminada, SemPy considera que solo coincide con atributos que muestran similitud de nombres, aprovechando el hecho de que los diseñadores de bases de datos suelen asignar nombres a las columnas relacionadas de la misma manera. Este comportamiento ayuda a evitar relaciones falsas, que se producen con más frecuencia con claves de enteros de cardinalidad baja. Por ejemplo, si hay 1,2,3,...,10 categorías de productos y 1,2,3,...,10 códigos de estado de pedido, se confundirán entre sí al examinar solo las asignaciones de valores sin tener en cuenta los nombres de las columnas. Las relaciones falsas no deberían ser un problema con las claves de tipo GUID.
SemPy examina una similitud entre los nombres de columna y los nombres de tabla. La coincidencia es aproximada y no distingue mayúsculas de minúsculas. Omite las subcadenas de "decorador" más frecuentes, como "id", "code", "name", "key", "pk" o "fk". Como resultado, los casos de coincidencia más típicos son:
- Un atributo denominado "column" en la entidad "foo" coincide con un atributo denominado "column" (también "COLUMN" o "Column") en la entidad "bar".
- Un atributo denominado "column" en la entidad "foo" coincide con un atributo denominado "column_id" en "bar".
- Un atributo denominado "bar" en la entidad "foo" coincide con un atributo denominado "code" en "bar".
Al buscar nombres de columna coincidentes primero, la detección se ejecuta más rápido.
Empareja los nombres de las columnas:
- Para comprender qué columnas se seleccionan para su posterior evaluación, use la opción
verbose=2(verbose=1enumera solo las entidades que se están procesando). - El parámetro
name_similarity_thresholddetermina cómo se comparan las columnas. El umbral de 1 indica que solo se está interesado en la coincidencia del 100 %.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);La ejecución con una similitud del 100 % no tiene en cuenta las pequeñas diferencias entre los nombres. En tu ejemplo, las tablas tienen una forma plural con sufijo "s", lo que resulta en que no hay una coincidencia exacta. Esto se controla bien con la
name_similarity_threshold=0.8predeterminada.- Para comprender qué columnas se seleccionan para su posterior evaluación, use la opción
Vuelva a ejecutar con el
name_similarity_threshold=0.8predeterminado :find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Tenga en cuenta que el identificador de la forma plural
patientsahora se compara con el singularpatientsin agregar demasiadas otras comparaciones falsas al tiempo de ejecución.Vuelva a ejecutar con el
name_similarity_threshold=0predeterminado :find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Cambiar
name_similarity_thresholda 0 es el otro extremo e indica que desea comparar todas las columnas. Esto rara vez es necesario y da como resultado un mayor tiempo de ejecución y coincidencias espurias que deben revisarse. Observe el número de comparaciones en la salida detallada.
Resumen de sugerencias de solución de problemas
- Comience desde una coincidencia exacta para las relaciones "m:1" (es decir, el
include_many_to_many=Falsey elcoverage_threshold=1.0predeterminados). Esto suele ser lo que quieres. - Use un enfoque estrecho en subconjuntos más pequeños de tablas.
- Use la validación para detectar problemas de calidad de datos.
- Use
verbose=2si quiere comprender qué columnas se consideran para la relación. Esto puede dar lugar a una gran cantidad de resultados. - Tenga en cuenta las desventajas de los argumentos de búsqueda.
include_many_to_many=Trueycoverage_threshold<1.0pueden producir relaciones falsas que pueden ser más difíciles de analizar y que deban filtrarse.
Detección de relaciones en el conjunto de datos completo de Synthea
El ejemplo de línea base simple era una herramienta de aprendizaje y solución de problemas cómoda. En la práctica, puede empezar desde un modelo semántico, como el conjunto de datos completo Synthea, que tiene muchas más tablas. Explore el conjunto de datos completo synthea como se indica a continuación.
Lea todos los archivos del directorio synthea/csv .
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Busque relaciones entre las tablas mediante la función
find_relationshipsde SemPy:suggested_relationships = find_relationships(all_tables) suggested_relationshipsVisualizar relaciones:
plot_relationship_metadata(suggested_relationships)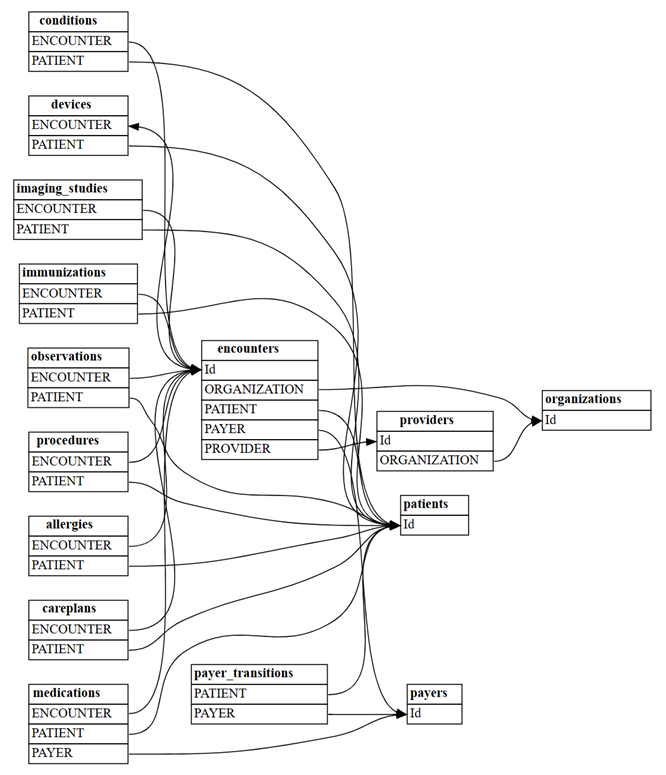
Cuente cuántas relaciones "m:m" nuevas se detectarán con
include_many_to_many=True. Estas relaciones son adicionales a las relaciones "m:1" mostradas anteriormente; por lo tanto, debe filtrar pormultiplicity:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Puede ordenar los datos de relación por varias columnas para comprender mejor su naturaleza. Por ejemplo, puede optar por ordenar la salida por
Row Count FromyRow Count To, lo que ayuda a identificar las tablas más grandes.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)En un modelo semántico diferente, quizás sería importante centrarse en el número de valores NULL
Null Count FromoCoverage To.Este análisis puede ayudarle a comprender si alguna de las relaciones podría no ser válida y si necesita quitarlas de la lista de candidatos.

Contenido relacionado
Explora otros tutoriales de enlace semántico / SemPy:
- Tutorial : Limpieza de datos con dependencias funcionales
- Tutorial: Análisis de dependencias funcionales en un modelo semántico de ejemplo
- Tutorial: Descubre relaciones en un modelo semántico utilizando el vínculo semántico
- Tutorial de : Extracción y cálculo de medidas de Power BI desde un cuaderno de Jupyter