Tutorial: Limpieza de datos con dependencias funcionales
En este tutorial, usará dependencias funcionales para la limpieza de datos. Existe una dependencia funcional cuando una columna de un modelo semántico (conjunto de datos de Power BI) es una función de otra columna. Por ejemplo, una columna de código postal podría determinar los valores de una columna de ciudad. Una dependencia funcional se manifiesta como una relación uno a varios entre los valores de dos o más columnas dentro de un DataFrame. En este tutorial se usa el conjunto de datos de Synthea para mostrar cómo las relaciones funcionales pueden ayudar a detectar problemas de calidad de datos.
En este tutorial, aprenderá a:
- Aplique sus conocimientos de dominio para formular hipótesis sobre las dependencias funcionales de un modelo semántico.
- Familiarícese con los componentes de la biblioteca Python de vínculo semántico (SemPy), que le ayudará a automatizar el análisis de calidad de los datos. Estos componentes incluyen:
- FabricDataFrame: una estructura similar a Pandas mejorada con información semántica adicional.
- Funciones útiles que automatizan la evaluación de hipótesis sobre dependencias funcionales y que identifican infracciones de relaciones en los modelos semánticos.
Requisitos previos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Cambie a la experiencia de ciencia de datos de Synapse mediante el conmutador de experiencia en el lado izquierdo de la página principal.

- Seleccione Áreas de trabajo en el panel de navegación izquierdo para buscar y seleccionar el área de trabajo. Esta área de trabajo se convertirá en el área de trabajo actual.
Seguimiento en el cuaderno
El cuaderno data_cleaning_functional_dependencies_tutorial.ipynb acompaña a este tutorial.
Para abrir el cuaderno complementario para este tutorial, siga las instrucciones en Preparación del sistema para los tutoriales de ciencia de datos para importar el cuaderno en el área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar una instancia de LakeHouse al cuaderno antes de empezar a ejecutar código.
Configuración del cuaderno
En esta sección, configurará un entorno de cuaderno con los módulos y los datos necesarios.
- Para Spark 3.4 y versiones posteriores, el vínculo semántico está disponible en el entorno de ejecución predeterminado al usar Fabric y no es necesario instalarlo. Si usa Spark 3.3 o inferior, o si desea actualizar a la versión más reciente del vínculo semántico, puede ejecutar el comando:
python %pip install -U semantic-link
Realice las importaciones necesarias de módulos que necesitará más adelante:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaIncorpore los datos de ejemplo. En este tutorial, usará el conjunto de datos Synthea de registros médicos sintéticos (versión reducida, para simplificar):
download_synthea(which='small')
Exploración de los datos
Inicialice un
FabricDataFramecon el contenido del archivo providers.csv:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Compruebe si hay problemas de calidad de datos con la función
find_dependenciesde SemPy mediante el trazado de un gráfico de dependencias funcionales detectadas automáticamente:deps = providers.find_dependencies() plot_dependency_metadata(deps)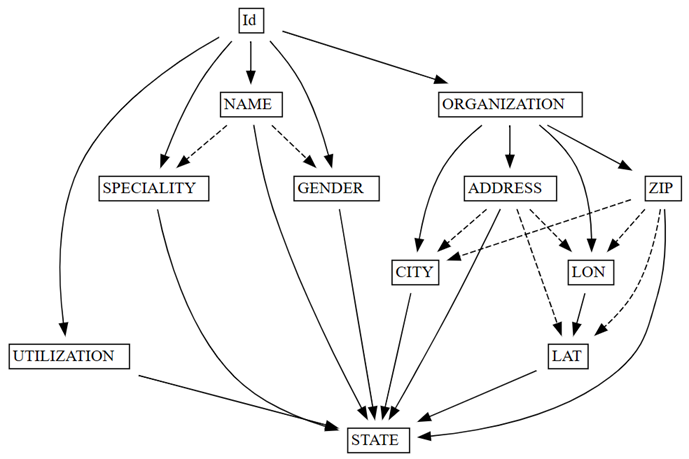
El gráfico de dependencias funcionales muestra que
IddeterminaNAMEyORGANIZATION(indicado por las flechas sólidas), que es lo previsto, ya queIdes único:Confirme que
Idsea único:providers.Id.is_uniqueEl código devuelve
Truepara confirmar queIdes único.

Análisis en profundidad de las dependencias funcionales
El gráfico de dependencias funcionales también muestra que ORGANIZATION determina ADDRESS y ZIP, según lo previsto. Sin embargo, puede esperar que ZIP también determine CITY, pero la flecha discontinua indica que la dependencia solo es aproximada, apuntando hacia un problema de calidad de datos.
Hay otras peculiaridades en el gráfico. Por ejemplo, NAME no determina GENDER, Id, SPECIALITY o ORGANIZATION. Quizás valga la pena investigar cada una de estas peculiaridades.
Observe más detalladamente la relación aproximada entre
ZIPyCITY, mediante la funciónlist_dependency_violationsde SemPy para ver una lista tabular de infracciones:providers.list_dependency_violations('ZIP', 'CITY')Dibuje un gráfico con la función de visualización
plot_dependency_violationsde SemPy. Este gráfico es útil si el número de infracciones es pequeño:providers.plot_dependency_violations('ZIP', 'CITY')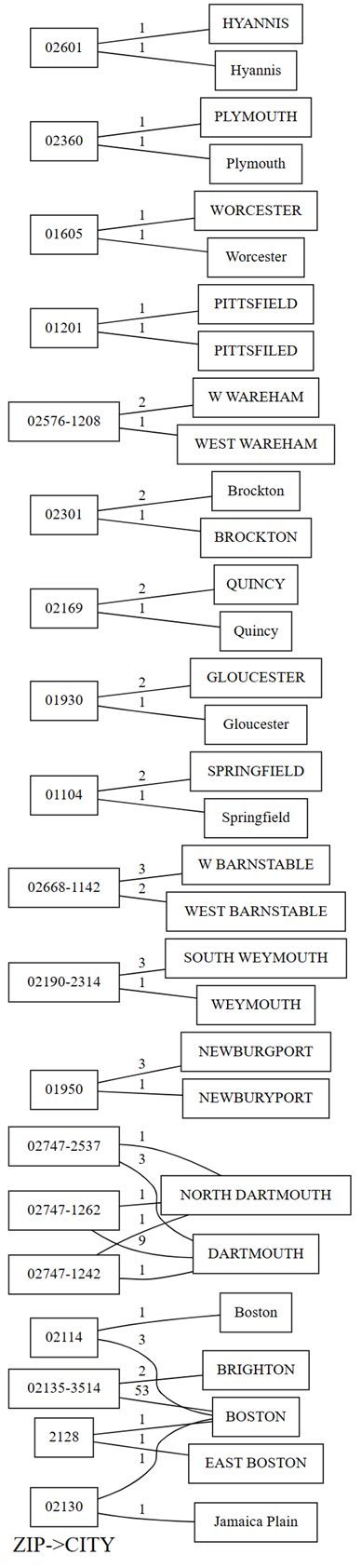
El gráfico de infracciones de dependencia muestra los valores de
ZIPen el lado izquierdo y los valores deCITYen el lado derecho. Un borde conecta un código postal en el lado izquierdo del trazado con una ciudad en el lado derecho, si hay una fila que contiene estos dos valores. Los bordes se anotan con el recuento de dichas filas. Por ejemplo, hay dos filas con el código postal 02747-1242, una fila con la ciudad "NORTH DARTHMOUTH" y la otra con la ciudad "DARTHMOUTH", como se muestra en el trazado anterior y el código siguiente:Confirme las observaciones anteriores realizadas con el trazado de infracciones de dependencia mediante la ejecución del código siguiente:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()El trazado también muestra que entre las filas que tienen
CITYcomo "DARTHMOUTH", nueve filas tienen unZIP02747-1262; una fila tiene unZIP02747-1242; y una fila tiene unZIP02747-2537. Confirme estas observaciones con el código siguiente:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Hay otros códigos postales asociados a "DARTMOUTH", pero estos códigos postales no se muestran en el gráfico de infracciones de dependencia, ya que no sugieren problemas de calidad de datos. Por ejemplo, el código postal "02747-4302" está asociado de forma única a "DARTMOUTH" y no aparece en el gráfico de infracciones de dependencia. Ejecute el código siguiente para confirmarlo:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Resumen de problemas de calidad de datos detectados con SemPy
Volviendo al gráfico de infracciones de dependencia, puede ver que hay varios problemas de calidad de datos interesantes presentes en este modelo semántico:
- Algunos nombres de ciudad están en mayúsculas. Este problema es fácil de corregir mediante métodos de cadena.
- Algunos nombres de ciudad tienen calificadores (o prefijos), como "North" y "East". Por ejemplo, el código postal "2128" se asigna a "EAST BOSTON" una vez y a "BOSTON" una vez. Se produce un problema similar entre "NORTH DARTHMOUTH" y "DARTHMOUTH". Puede intentar quitar estos calificadores o asignar los códigos postales a la ciudad que se repite más veces.
- Hay errores tipográficos en algunas ciudades, como "PITTSFIELD" frente a "PITTSFILED" y "NEWBURGPORT" frente a "NEWBURYPORT". Para "NEWBURGPORT", este error tipográfico podría corregirse mediante el uso de la opción que se repite más veces. Para "PITTSFIELD", el hecho de tener solo una aparición hace que sea mucho más difícil realizar la desambiguación automática sin conocimiento externo ni el uso de un modelo de lenguaje.
- A veces, los prefijos como "West" se abrevian a una sola letra "W". Este problema podría corregirse con un reemplazo simple, si todas las apariciones de "W" se refieren a "West".
- El código postal "02130" se asigna a "BOSTON" una vez y a "Jamaica Plain" una vez. Este problema no es fácil de corregir, pero si hay más datos, la asignación a la opción que se repite más veces podría ser una posible solución.
Limpiar los datos
Corrija los problemas de mayúsculas y minúsculas cambiando todas las mayúsculas y minúsculas al tipo título:
providers['CITY'] = providers.CITY.str.title()Vuelva a ejecutar la detección de infracciones para observar que algunas de las ambigüedades han desaparecido (el número de infracciones es menor):
providers.list_dependency_violations('ZIP', 'CITY')En este momento, puede depurar los datos de forma más manual, pero una posible tarea de limpieza de datos consiste en quitar filas que infringen las restricciones funcionales entre las columnas de los datos mediante la función
drop_dependency_violationsde SemPy.Para cada valor de la variable determinante,
drop_dependency_violationsfunciona seleccionando el valor que se repite más veces de la variable dependiente y quitando todas las filas con otros valores. Solo debe aplicar esta operación si confía en que esta heurística estadística producirá los resultados correctos de los datos. De lo contrario, debe escribir su propio código para controlar las infracciones detectadas según sea necesario.Ejecute la función
drop_dependency_violationsen las columnasZIPyCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Indique las infracciones de dependencia entre
ZIPyCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')El código devuelve una lista vacía para indicar que no hay más infracciones de la restricción funcional CITY -> ZIP.
Contenido relacionado
Consulte otros tutoriales para el vínculo semántico/SemPy:
- Tutorial: Análisis de dependencias funcionales en un modelo semántico de ejemplo
- Tutorial: Extracción y cálculo de medidas de Power BI de un cuaderno de Jupyter
- Tutorial: Detección de relaciones en un modelo semántico mediante el vínculo semántico
- Tutorial: Detección de relaciones en el conjunto de datos de Synthea con el vínculo semántico
- Tutorial: Validación de datos mediante SemPy y Great Expectations (GX)