Uso de Livy API para enviar y ejecutar trabajos de Spark
Nota:
Livy API for Fabric Data Engineering está en versión preliminar.
Se aplica a:✅ Ingeniería de datos y ciencia de datos en Microsoft Fabric
Empiece a trabajar con Livy API for Fabric Data Engineering mediante la creación de una instancia de Lakehouse; autenticación con un token de aplicación de Microsoft Entra; envíe trabajos por lotes o de sesión desde un cliente remoto al proceso de Fabric Spark. También descubrirá el punto de conexión de Livy API; enviar trabajos; y supervise los resultados.
Requisitos previos
Capacidad de Fabric Premium o prueba con una instancia de LakeHouse
Habilitación de Configuración de administrador de inquilinos para Livy API (versión preliminar)
Un cliente remoto, como Visual Studio Code con compatibilidad con cuadernos de Jupyter Notebook, PySpark y Biblioteca de autenticación de Microsoft (MSAL) para Python
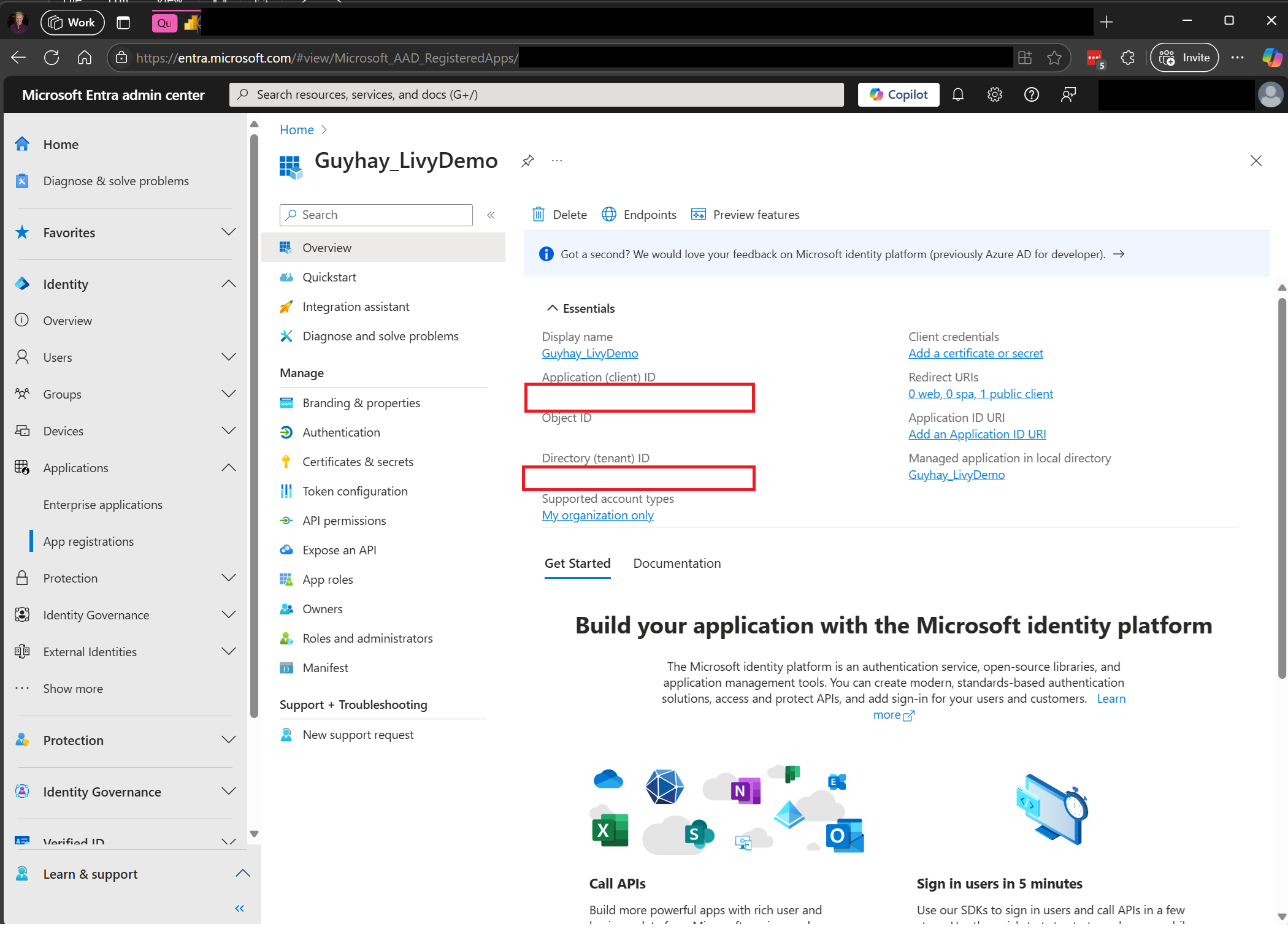
Se requiere un token de aplicación de Microsoft Entra para acceder a la API de REST de Fabric. Registro de una aplicación en la plataforma de identidad de Microsoft
Elección de un cliente de API de REST
Puede usar varios lenguajes de programación o clientes de GUI para interactuar con los puntos de conexión de la API de REST. En este artículo, usaremos Visual Studio Code. Visual Studio Code debe configurarse con Cuadernos de Jupyter Notebook, PySpark, y la Biblioteca de autenticación de Microsoft (MSAL) para Python
Autorización de las solicitudes de Livy API
Para trabajar con las API de Fabric, incluida la API de Livy, primero debe crear una aplicación de Microsoft Entra y obtener un token. La aplicación debe registrarse y configurarse adecuadamente para realizar llamadas API en Fabric. Para más información, consulte Registro de una aplicación con la plataforma de identidad de Microsoft.
Hay muchos permisos de ámbito de Microsoft Entra necesarios para ejecutar trabajos de Livy. Este es un ejemplo de código de Spark simple + acceso de almacenamiento + SQL:
- Code.AccessAzureDataExplorer.All
- Code.AccessAzureDataLake.All
- Code.AccessAzureKeyvault.All
- Code.AccessFabric.All
- Code.AccessStorage.All
- Item.ReadWrite.All
- Lakehouse.Execute.All
- Lakehouse.Read.All
- Workspace.ReadWrite.All

Nota:
Durante la versión preliminar pública, agregaremos algunos ámbitos granulares adicionales y, si usa este enfoque, cuando agreguemos estos ámbitos adicionales, se interrumpirá la aplicación Livy. Compruebe esta lista, ya que se actualizará con los ámbitos adicionales.
Algunos clientes quieren permisos más pormenorizados que la lista anterior. Puede quitar Item.ReadWrite.All y reemplazar por estos permisos de ámbito más granulares:
- Code.AccessAzureDataExplorer.All
- Code.AccessAzureDataLake.All
- Code.AccessAzureKeyvault.All
- Code.AccessFabric.All
- Code.AccessStorage.All
- Lakehouse.Execute.All
- Lakehouse.ReadWrite.All
- Workspace.ReadWrite.All
- Notebook.ReadWrite.All
- SparkJobDefinition.ReadWrite.All
- MLModel.ReadWrite.All
- MLExperiment.ReadWrite.All
- Dataset.ReadWrite.All
Después de registrar la aplicación, necesitará tanto el identificador de aplicación (cliente) como el identificador de directorio (inquilino).
El usuario autenticado que llama a Livy API debe ser un miembro del área de trabajo donde tanto la API como los elementos del origen de datos se encuentran con un rol colaborador. Para más información, consulte Proporcionar acceso a los usuarios a las áreas de trabajo en Power BI.
Detección del punto de conexión de Fabric Livy API
Se requiere un artefacto de Lakehouse para acceder al punto de conexión de Livy. Una vez creado Lakehouse, el punto de conexión de Livy API se puede ubicar en el panel de configuración.

El punto de conexión de Livy API seguiría este patrón:
https://api.fabric.microsoft.com/v1/workspaces/<ws_id>/lakehouses/<lakehouse_id>/livyapi/versions/2023-12-01/
La dirección URL se anexa con <sesiones> o <lotes> en función de lo que elija.
Integración con entornos de Fabric
Para cada área de trabajo de Fabric, se aprovisiona un grupo de inicio predeterminado, la ejecución de todo el código de spark usa este grupo de inicio de forma predeterminada. Puede usar entornos de Fabric para personalizar los trabajos de Spark de Livy API.
Envío de trabajos de Livy API
Ahora que ha completado la configuración de Livy API, puede optar por enviar trabajos por lotes o de sesión.
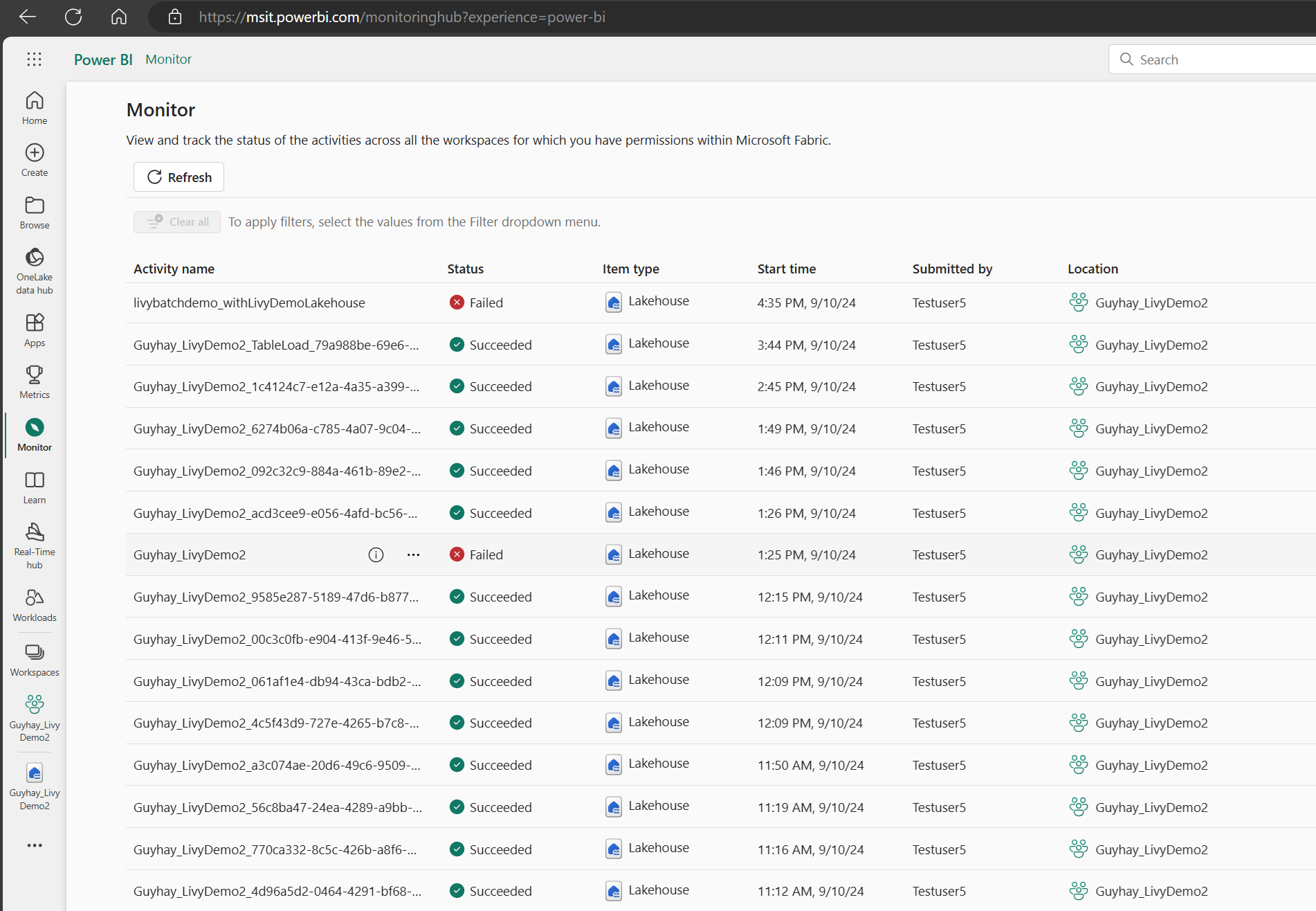
Supervisión del historial de solicitudes
Puede usar el Centro de supervisión para ver los envíos anteriores de Livy API y depurar los errores de envío.
Contenido relacionado
- Documentación de la API REST de Apache Livy
- Introducción a la configuración de administrador de la Capacidad de Fabric
- Configuración de la gestión del área de trabajo de Apache Spark en Microsoft Fabric
- Registro de una aplicación en la plataforma de identidad de Microsoft
- Introducción al permiso y consentimiento de Microsoft Entra
- Ámbitos de API de REST de Fabric
- Resumen de supervisión de Apache Spark
- Detalles de la aplicación Apache Spark