Uso de Livy API para enviar y ejecutar trabajos por lotes de Livy
Nota:
Livy API para Ingeniería de datos de Fabric está en versión preliminar.
Se aplica a:✅ Ingeniería de datos y ciencia de datos en Microsoft Fabric
Envíe trabajos por lotes de Spark mediante Livy API para Ingeniería de datos de Fabric.
Requisitos previos
Fabric Premium o Capacidad de prueba con una instancia de almacén de lago de datos.
Habilite la Configuración de administrador de inquilinos para Livy API (versión preliminar).
Un cliente remoto, como Visual Studio Code con cuadernos de Jupyter Notebook, PySpark y la biblioteca de autenticación de Microsoft (MSAL) para Python.
Se requiere un token de aplicación de Microsoft Entra para acceder a la API de REST de Fabric. Registro de una aplicación en la Plataforma de identidad de Microsoft.
Algunos datos de su instancia de almacén de lago de datos, en este ejemplo se usa NYC Taxi & Limousine Commission green_tripdata_2022_08 un archivo parquet cargado en el almacén de lago de datos.
Livy API define un punto de conexión unificado para las operaciones. Reemplace los marcadores de posición {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID}y {Fabric_LakehouseID} por los valores adecuados al seguir los ejemplos de este artículo.
Configuración de Visual Studio Code para la sesión por lotes de Livy API
Seleccione Configuración de almacén de lago de datos en el almacén de lago de datos de Fabric.

Vaya a la sección punto de conexión de Livy.
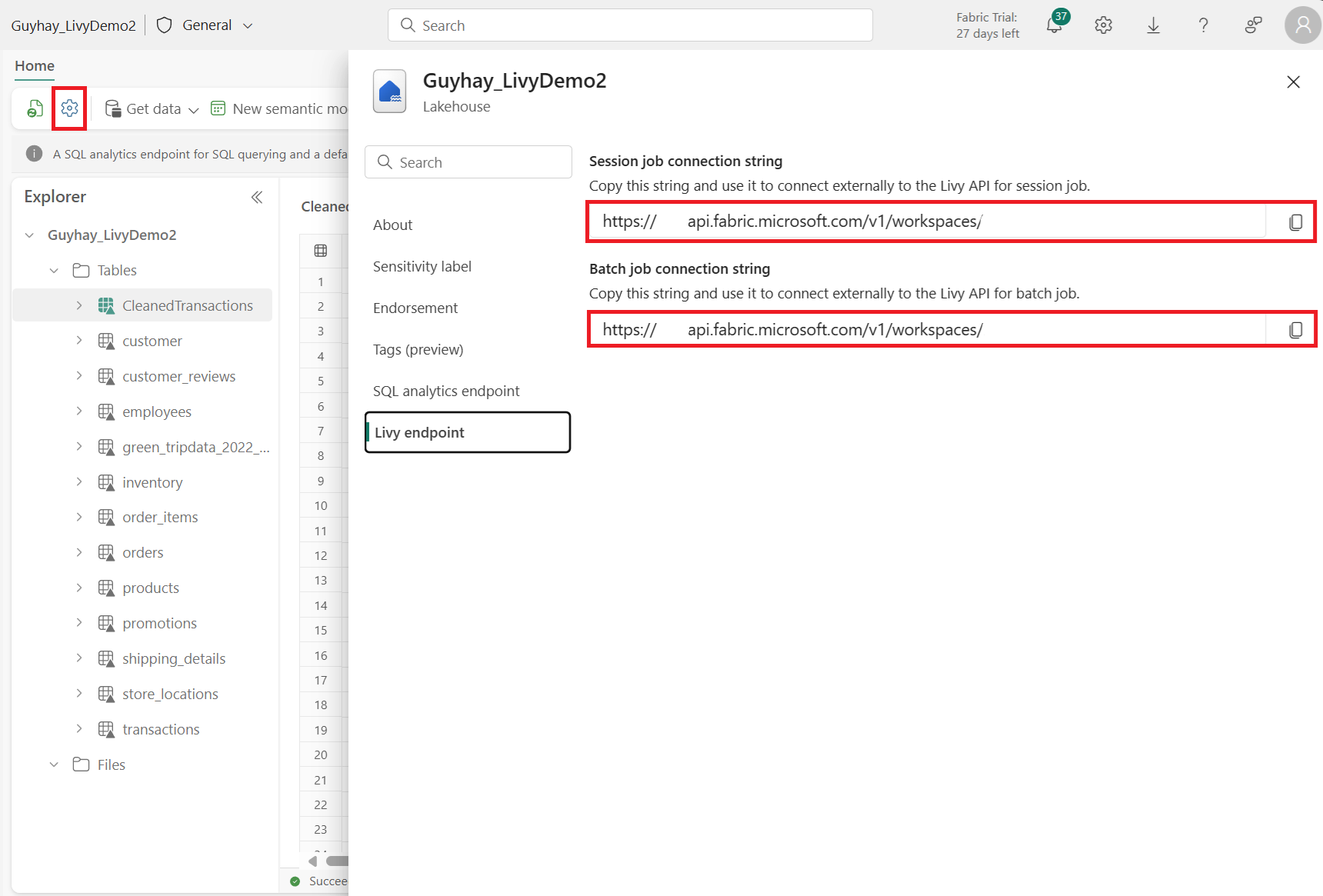
Copie la cadena de conexión del trabajo por lotes (segundo cuadro rojo de la imagen) en el código.
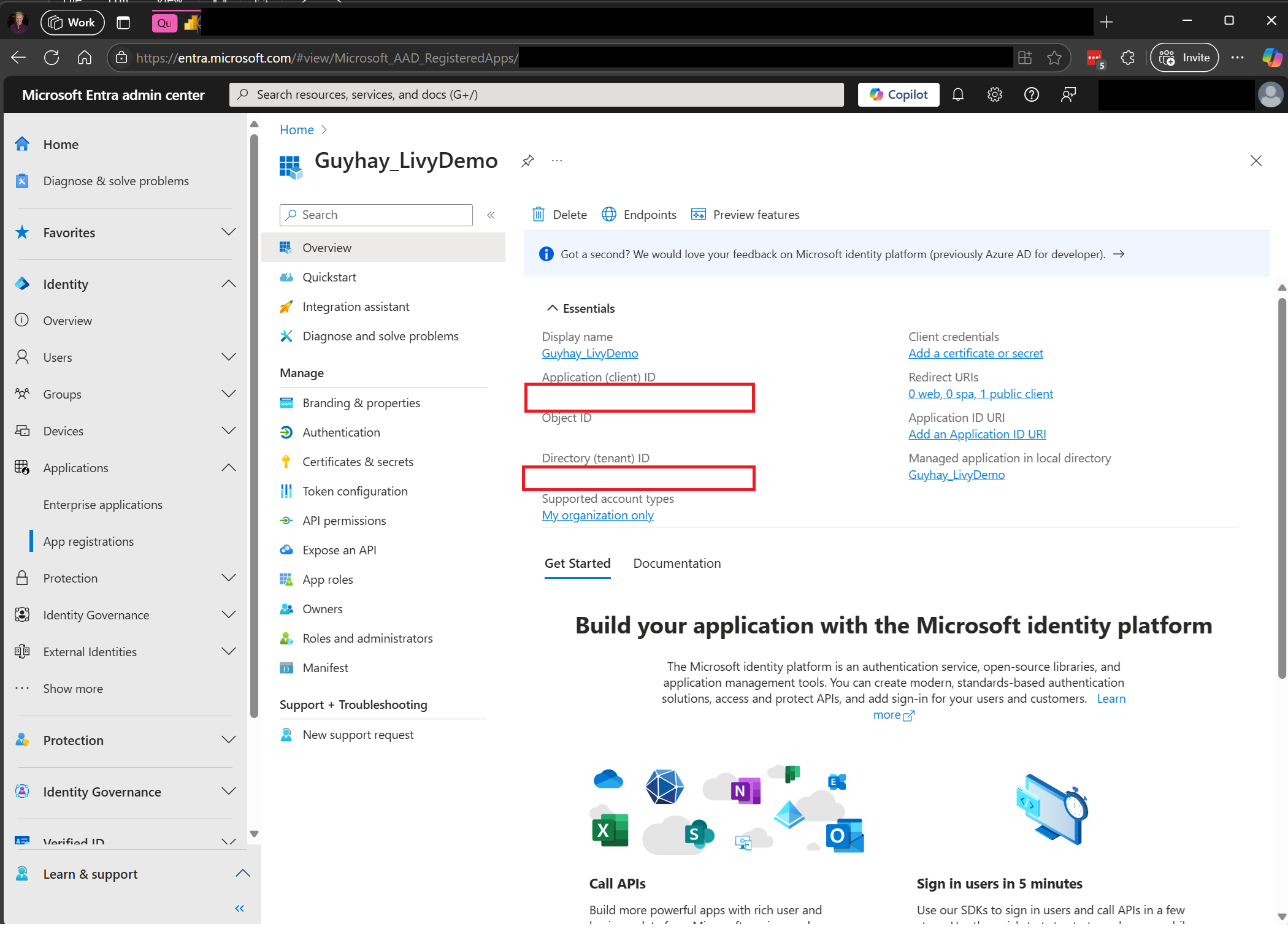
Vaya a Centro de administración de Microsoft Entra y copie el identificador de aplicación (cliente) y el identificador de directorio (inquilino) en el código.



Creación de una carga de Spark y carga en el almacén de lago de datos
Cree un cuaderno
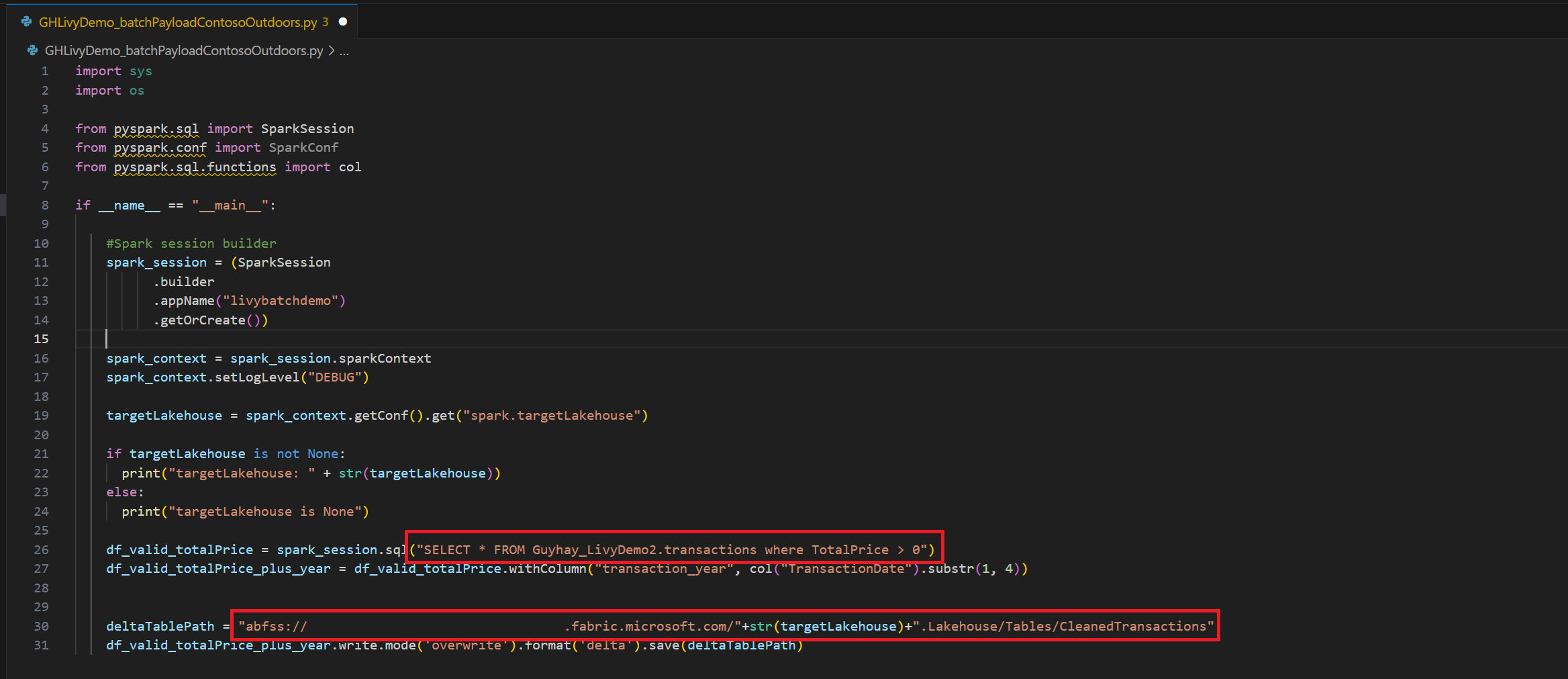
.ipynben Visual Studio Code e inserte el siguiente códigoimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM Guyhay_LivyDemo2.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Guarde el archivo de Python localmente. Esta carga de código de Python contiene dos instrucciones Spark que funcionan en los datos de un almacén de lago de datos y deben cargarse en su almacén de lago de datos. Necesitará la ruta de acceso de ABFS de la carga para hacer referencia en el trabajo por lotes de Livy API en Visual Studio Code.
Cargue la carga de Python en la sección de archivos del almacén de lago de datos. > Obtener datos > Cargar archivos > haga clic en el cuadro Archivos/entrada.
Después de que el archivo esté en la sección Archivos de su almacén de lago de datos, haga clic en los tres puntos situados a la derecha del nombre de archivo de carga y seleccione Propiedades.
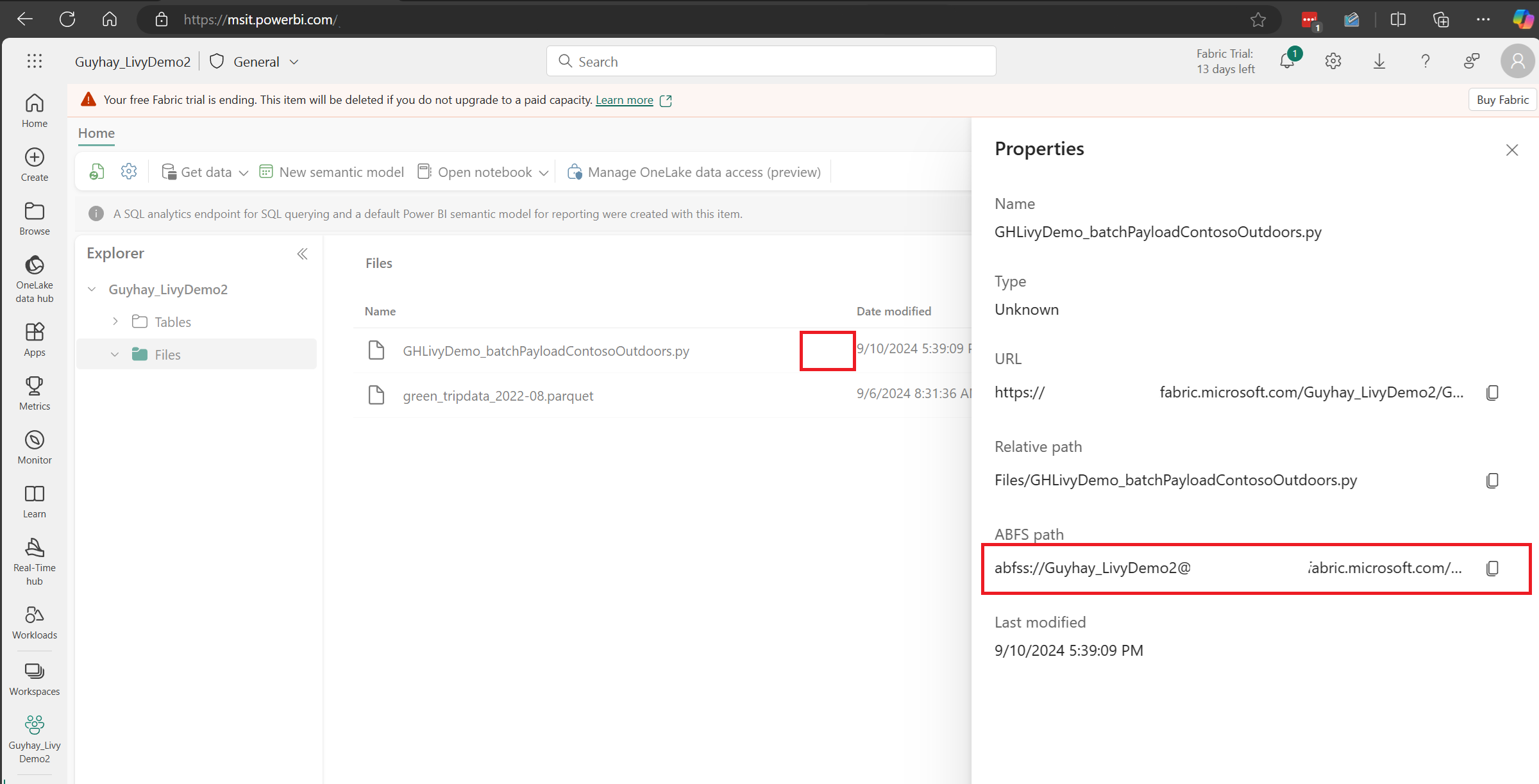
Copie esta ruta de acceso de ABFS a la celda de Notebook en el paso 1.



Creación de una sesión por lotes de Spark de Livy API
Cree un cuaderno
.ipynben Visual Studio Code e inserte el siguiente código.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Ejecute la celda del cuaderno; debería aparecer un elemento emergente en el explorador, lo que le permite elegir la identidad con la que iniciar sesión.
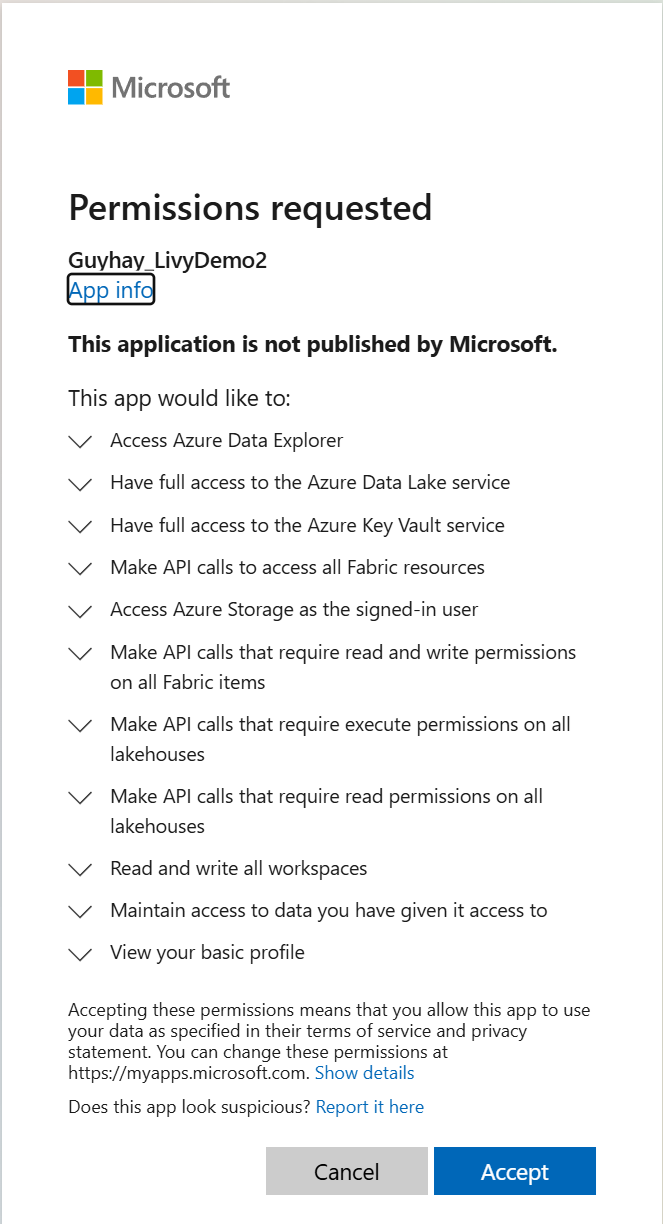
Después de elegir la identidad con la que iniciar sesión, también se le pedirá que apruebe los permisos de la API de registro de aplicaciones de Microsoft Entra.
Cierre la ventana del explorador después de completar la autenticación.

En Visual Studio Code, debería ver el token de Microsoft Entra devuelto.
Agregue otra celda del cuaderno e inserte este código.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Ejecute la celda del cuaderno; debería ver dos líneas impresas a medida que se crea el trabajo por lotes de Livy.
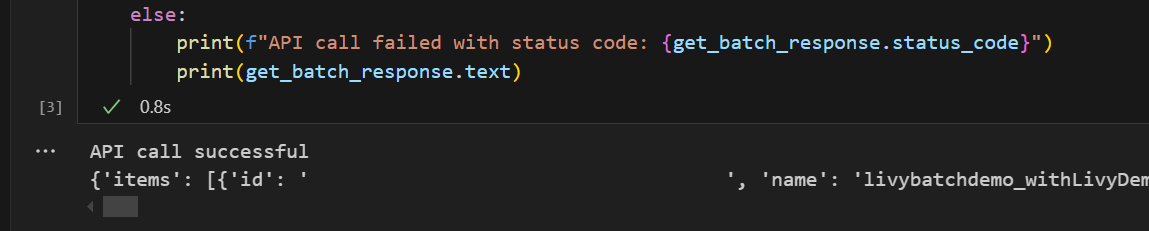





Envío de una instrucción spark.sql mediante la sesión por lotes de Livy API
Agregue otra celda del cuaderno e inserte este código.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Ejecute la celda del cuaderno; verá varias líneas impresas a medida que se crea y ejecuta el trabajo por lotes de Livy.

Vuelva a su almacén de lago de datos para ver los cambios.

Visualización de los trabajos en el centro de supervisión
Puede acceder al centro de supervisión para ver varias actividades de Apache Spark al seleccionar Supervisar en los vínculos de navegación del lado izquierdo.
Cuando se complete el estado del trabajo por lotes, puede ver el estado de la sesión; para ello, vaya a Monitor.
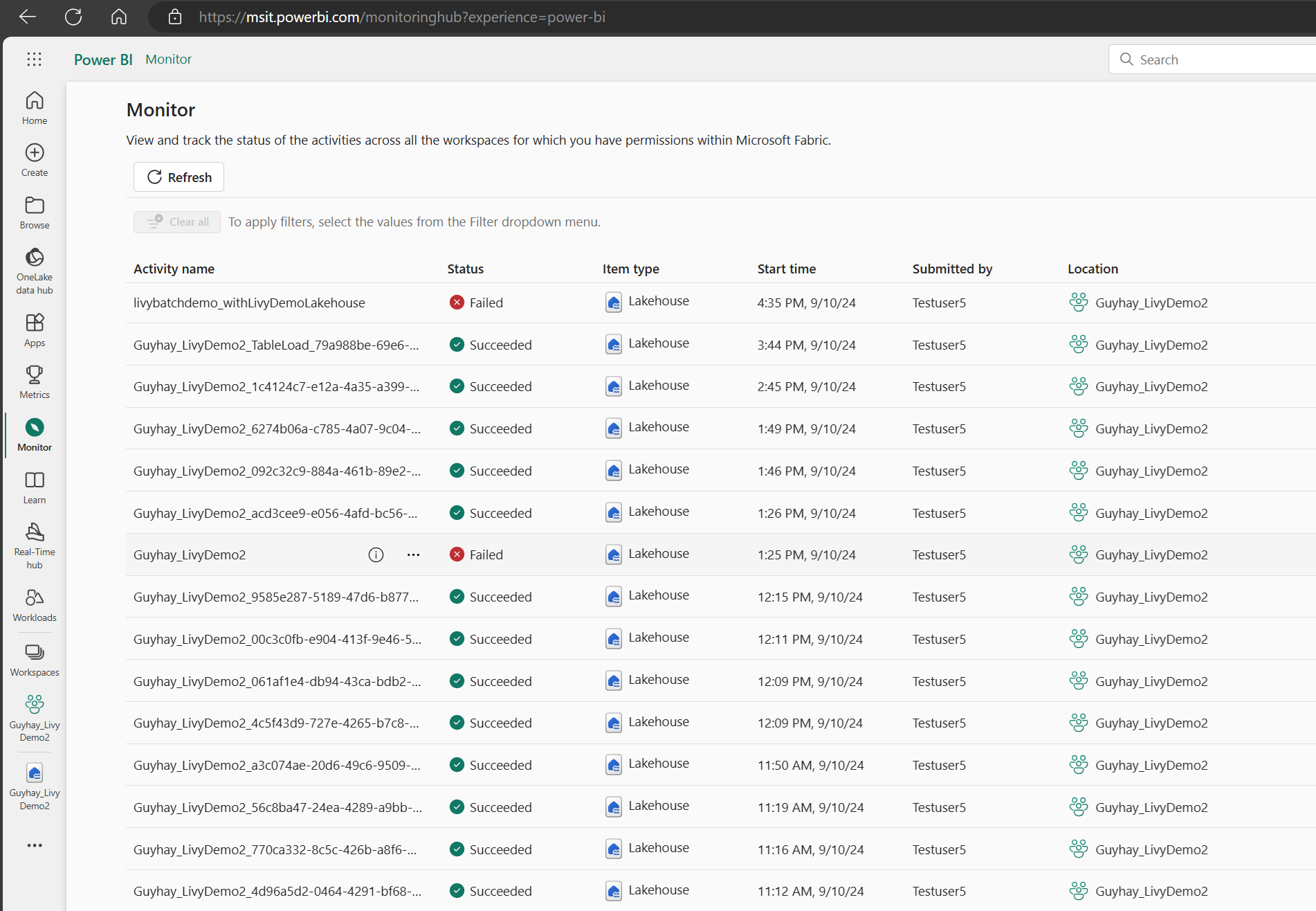
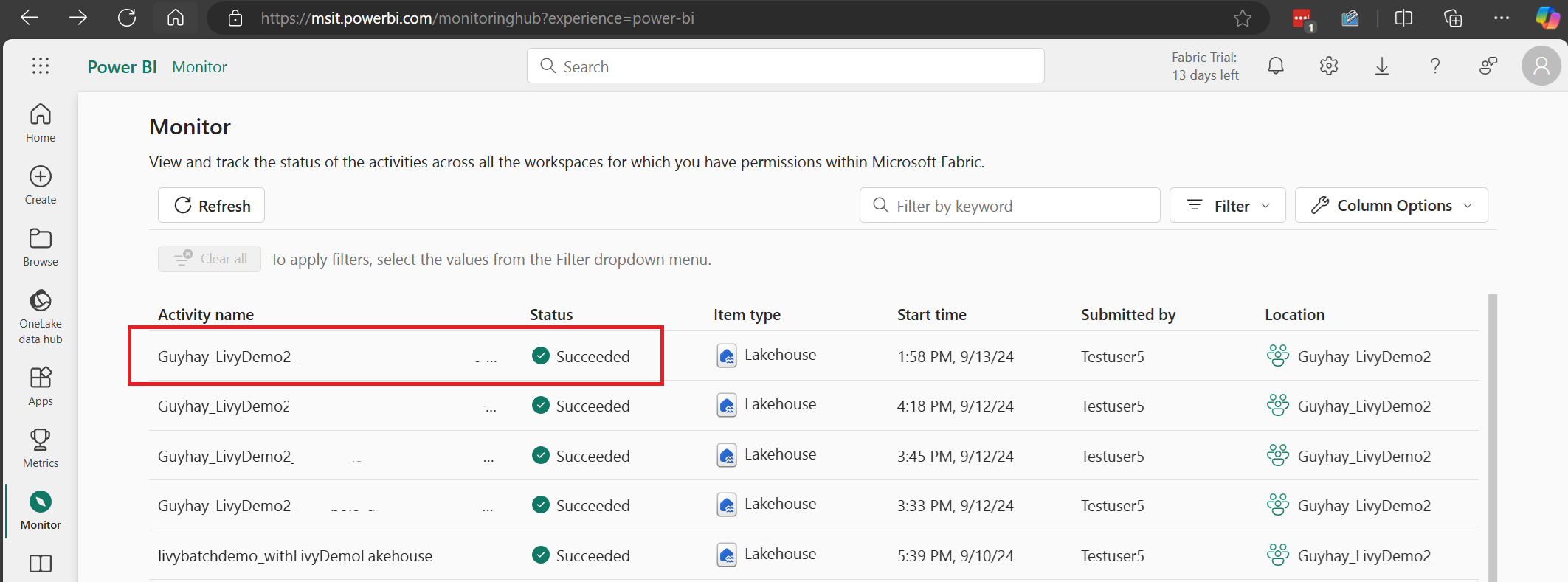
Seleccione y abra el nombre de la actividad más reciente.
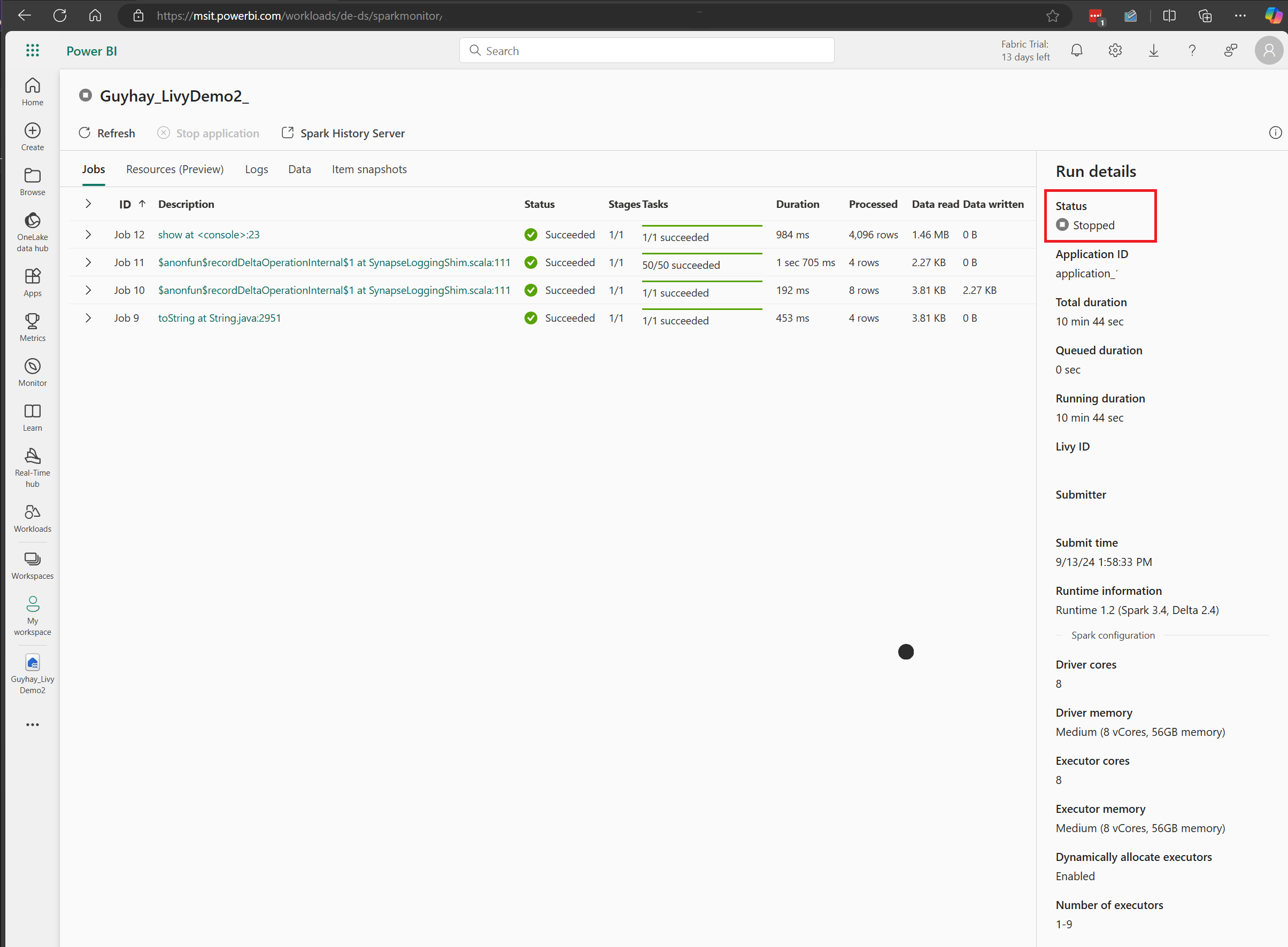
En este caso de sesión de Livy API, puede ver el envío por lotes anterior, los detalles de ejecución, las versiones de Spark y la configuración. Observe el estado detenido en la parte superior derecha.
Para volver a resumir todo el proceso, necesita un cliente remoto, como Visual Studio Code, un token de aplicación de Microsoft Entra, la dirección URL del punto de conexión de Livy API, la autenticación en el almacén de lago de datos, una carga de Spark en el almacén de lago de datos y, por último, una sesión de Livy API por lotes.