El proceso de las canalizaciones de implementación
El proceso de implementación permite clonar el contenido de una fase de la implementación de canalización a otra, normalmente del desarrollo a la prueba y de la prueba a la producción.
Durante la implementación, Microsoft Fabric copia el contenido de la fase origen a la del destino. Las conexiones entre los elementos copiados se conservan durante el proceso de copia. Fabric también aplica las reglas de implementación configuradas al contenido actualizado en la fase de destino. La implementación del contenido puede tardar un tiempo, en función del número de elementos que se implementan. Durante este tiempo, puede ir a otras páginas del portal, pero no puede usar el contenido en la fase de destino.
También puede implementar contenido mediante programación, con las API REST de canalizaciones de implementación. Puede obtener más información sobre este proceso en Automatización de la canalización de implementación mediante API y Azure DevOps.
Nota
La nueva interfaz de usuario de canalización de implementación está actualmente en versión preliminar. Para activar o usar la nueva interfaz de usuario, consulte Comenzar a usar la nueva interfaz de usuario.
Hay dos partes principales en el proceso de canalizaciones de implementación:
Definir la estructura de canalización de implementación
Al crear una canalización, define cuántas fases desea y cómo deben llamarse. También puede hacer pública una o varias fases. El número de fases y sus nombres son permanentes, y no se pueden cambiar después de crear la canalización. Sin embargo, puede cambiar el estado público de una fase en cualquier momento.
Para definir una canalización, siga las instrucciones de Creación de una canalización de implementación.
Agregar contenido a las fases
Puede agregar contenido a una fase de canalización de dos maneras:
Asignar un área de trabajo a una fase vacía
Al asignar contenido en una fase vacía, se crea un área de trabajo nueva en una capacidad para la fase en la que se implementa. Todos los metadatos de los informes, paneles y modelos semánticos del área de trabajo original se copian en la nueva área de trabajo de la fase en la que se va a implementar.
Una vez completada la implementación, actualice los modelos semánticos para que pueda usar el contenido recién copiado. La actualización de modelos semánticos es necesaria porque los datos no se copian de una fase a otra. Para comprender qué propiedades de elemento se copian durante el proceso de implementación y cuáles no, revise la sección Propiedades de elemento copiadas durante la implementación.
Para obtener instrucciones sobre cómo asignar y cancelar la asignación de áreas de trabajo a fases de canalización de implementación, consulte Asignación de un área de trabajo a una canalización de implementación de Microsoft Fabric.
Crear un área de trabajo
La primera vez que implemente contenido, las canalizaciones de implementación comprueban si tiene permisos.
Si tiene permisos, el contenido del área de trabajo se copia en la fase en la que se está realizando la implementación, y se crea una nueva área de trabajo en esa fase en la capacidad.
Si no tiene permisos, el área de trabajo se crea, pero el contenido no se copia. Puede pedir a un administrador de capacidad que agregue el área de trabajo a una capacidad o solicitar permisos de asignación para la capacidad. Más adelante, cuando el área de trabajo esté asignada a una capacidad, puede implementar contenido en esta área de trabajo.
Si usa Premium por usuario (PPU), el área de trabajo se crea automáticamente en PPU. En tales casos, no se requieren permisos. Sin embargo, si crea un área de trabajo con una PPU, solo otros usuarios de PPU pueden acceder a él. Además, solo los usuarios de PPU pueden consumir contenido creado en estas áreas de trabajo.
Propiedad del área de trabajo y del contenido
El usuario de implementación se convierte automáticamente en el propietario de los modelos semánticos clonados y en el único administrador del área de trabajo nueva.
Implementar contenido de una fase a otra
Hay varias maneras de implementar contenido de una fase a otra. Puede implementar todo el contenido o seleccionar los elementos que desea implementar.
Puede implementar contenido en cualquier fase adyacente, en cualquier dirección.
La implementación de contenido desde una canalización de producción de trabajo a una fase que tiene un área de trabajo existente, incluye los pasos siguientes:
Implementación de contenido nuevo como adición al que ya existe.
Implementación de contenido actualizado para reemplazar parte del que ya existe.
Proceso de implementación
Cuando el contenido de la fase origen se copia en la fase de destino, Fabric identifica el contenido existente en la fase de destino y lo sobrescribe. Para identificar qué elemento de contenido debe sobrescribirse, las canalizaciones de implementación usan la conexión entre el elemento primario y sus clones. Esta conexión se mantiene cuando se crea contenido nuevo. La operación de sobrescritura solo sobrescribe el contenido del elemento. El identificador, la dirección URL y los permisos del elemento permanecen inalterados.
En la fase de destino, las propiedades de elemento que no se copian permanecen como estaban antes de la implementación. El nuevo contenido y los nuevos elementos se copian desde la fase origen hasta la fase de destino.
Enlace automático
En Fabric, cuando los elementos están conectados, uno de los elementos depende del otro. Por ejemplo, un informe siempre depende del modelo semántico al que está conectado. Un modelo semántico puede depender de otro modelo semántico y también se puede conectar a varios informes que dependan de él. Si hay una conexión entre dos elementos, las canalizaciones de implementación siempre intentarán mantener esta conexión.
Enlace automático en la misma área de trabajo
Durante la implementación, las canalizaciones de implementación comprueban las dependencias. La implementación se realiza correctamente o se produce un error, según la ubicación del elemento que proporciona los datos de los que depende el elemento implementado.
El elemento vinculado existe en la fase de destino: las canalizaciones de implementación conectan automáticamente (enlace automático) el elemento implementado al elemento del que depende en la fase implementada. Por ejemplo, si implementa un informe paginado desde el desarrollo hasta las pruebas y está conectado a un modelo semántico que previamente se ha implementado en la fase de pruebas, se conecta automáticamente a ese modelo semántico.
El elemento vinculado no existe en la fase de destino: se producirá un error en las canalizaciones de implementación si un elemento tiene una dependencia de otro y el elemento que proporciona los datos no está implementado y no reside en la fase de destino. Por ejemplo, si implementa un informe desde el desarrollo a las pruebas y la fase de pruebas no contiene su modelo semántico, se producirá un error en la implementación. Para evitar implementaciones con errores debido a que no se implementan elementos dependientes, use el botón Seleccionar relacionados. Seleccionar relacionados selecciona automáticamente todos los elementos relacionados que proporcionan dependencias a los elementos que va a implementar.
El enlace automático solo funciona con elementos que son compatibles con las canalizaciones de implementación y residen en Fabric. Para ver las dependencias de un elemento, seleccione Ver linaje en el menú Más opciones del elemento.
Enlace automático entre áreas de trabajo
Las canalizaciones de implementación enlazan elementos conectados entre canalizaciones, si se encuentran en la misma fase de canalización. Al implementar estos elementos, las canalizaciones de implementación intentan establecer una conexión nueva entre el elemento implementado y el elemento al que está conectado en la otra canalización. Por ejemplo, si tiene un informe en la fase de prueba de la canalización A que está conectado a un modelo semántico en la fase de prueba de la canalización B, las canalizaciones de implementación reconocerán esta conexión.
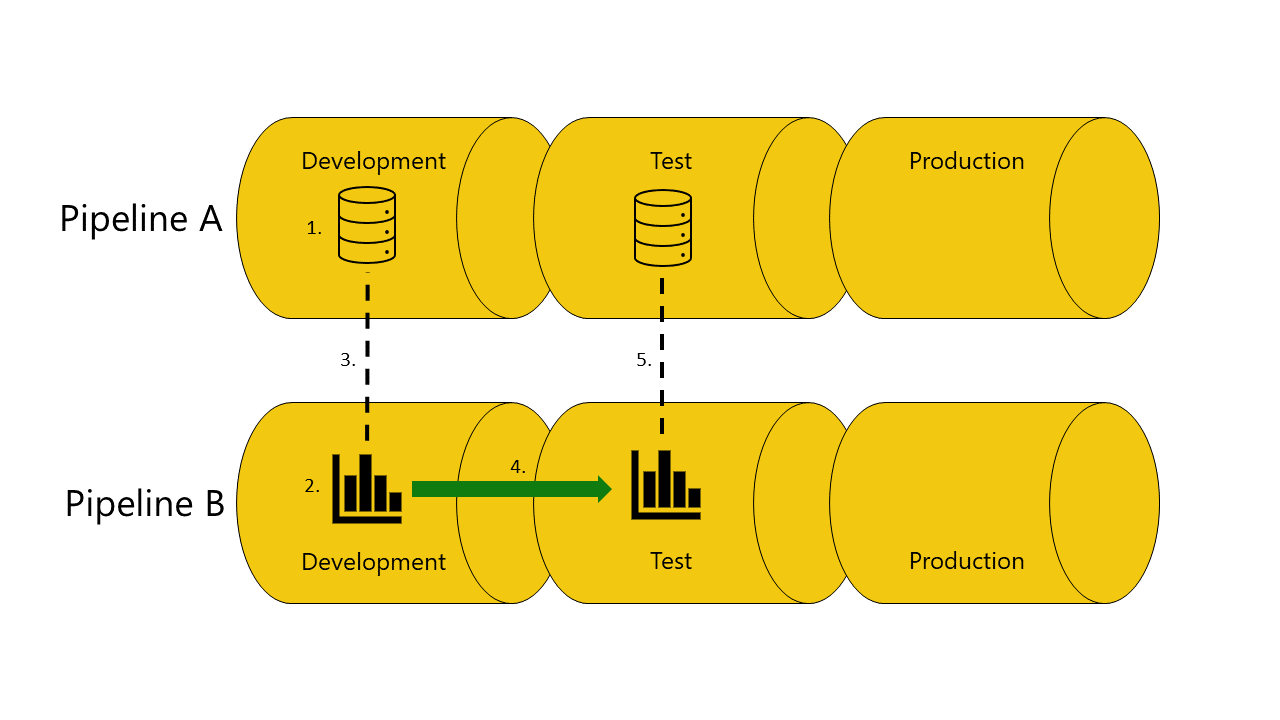
Este es un ejemplo con ilustraciones que le ayudarán a demostrar cómo funciona el enlace automático entre canalizaciones:
Tiene un modelo semántico en la fase de desarrollo de la canalización A.
También tiene un informe en la fase de desarrollo de la canalización B.
El informe de la canalización B está conectado al modelo semántico de la canalización A. El informe depende de este modelo semántico.
El informe se implementa en la canalización B desde la fase de desarrollo a la fase de prueba.
La implementación se realiza correctamente o no, en función de si tiene o no una copia del modelo semántico, ya que depende de la fase de prueba de la canalización A:
Si tiene una copia del modelo semántico, el informe dependerá de la fase de prueba de la canalización A:
La implementación se realiza correctamente y las canalizaciones de implementación conectarán (enlace automático) el informe en la fase de prueba de la canalización B al modelo semántico en la fase de prueba de la canalización A.
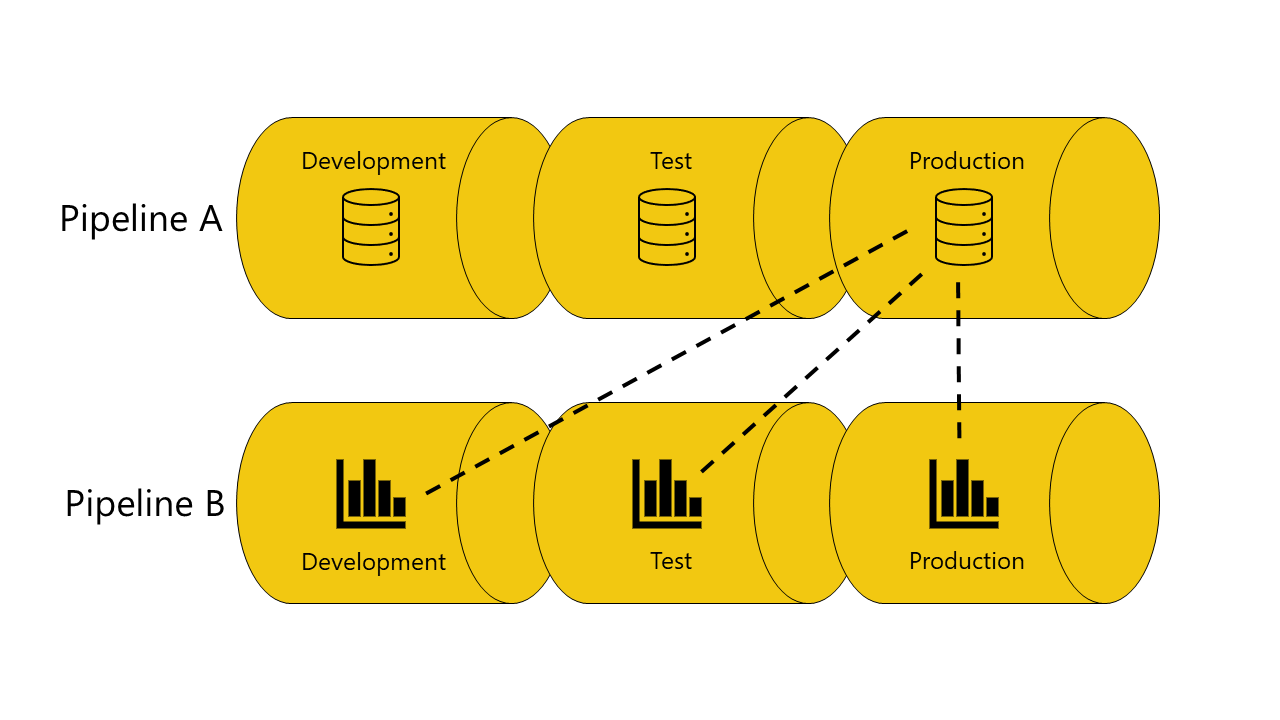
Si no tiene ninguna copia del modelo semántico, el informe dependerá de la fase de prueba de la canalización A:
Se produce un error en la implementación porque las canalizaciones de implementación no pueden conectar (enlace automático) el informe en la fase de prueba de la canalización B al modelo semántico del que depende en la fase de prueba de la canalización A.

Evasión del uso del enlace automático
En algunos casos, es posible que no quiera usar el enlace automático. Por ejemplo, si tiene una canalización para desarrollar modelos semánticos organizativos y otra para crear informes. En este caso, es posible que quiera que todos los informes estén siempre conectados a modelos semánticos en la fase de producción de la canalización a la que pertenecen. En este caso, evite usar la característica de enlace automático.
Hay tres métodos que puedes usar para evitar el uso del enlace automático:
No conecte el elemento a las fases correspondientes. Cuando los elementos no están conectados en la misma fase, las canalizaciones de implementación mantienen la conexión original. Por ejemplo, si tiene un informe en la fase de desarrollo de la canalización B que está conectado a un modelo semántico en la fase de producción de la canalización A. Al implementar el informe en la fase de prueba de la canalización B, permanece conectado al modelo semántico en la fase de producción de la canalización A.
Defina una regla de parámetros. Esta opción no está disponible para los informes. Solo puede usarlo con modelos semánticos y flujos de datos.
Conecte los informes, paneles y mosaicos a un modelo semántico o flujo de datos delegado que no esté conectado a ninguna canalización.
Enlace automático y parámetros
Los parámetros se pueden usar para controlar las conexiones entre modelos semánticos o flujos de datos y los elementos de los que dependen. Cuando un parámetro controla la conexión, el enlace automático tras la implementación no tendrá lugar, incluso aunque la conexión incluya un parámetro que se aplique al identificador del modelo semántico, del flujo de datos o al del área de trabajo. En tales casos, deberá volver a enlazar los elementos después de la implementación. Para ello, debe cambiar el valor del parámetro o usar reglas de parámetro.
Nota
Si usa reglas de parámetro para volver a enlazar elementos, los parámetros deben ser de tipo Text.
Actualizando datos
Los datos del elemento de destino, como un modelo semántico o un flujo de datos, se conservan siempre que sea posible. Si no hay ningún cambio en un elemento que contiene los datos, los datos se conservan como estaban antes de la implementación.
En muchos casos, cuando se realiza un pequeño cambio, como agregar o quitar una tabla, Fabric conserva los datos originales. Para interrumpir los cambios de esquema o los cambios en la conexión del origen de datos, se requiere una actualización completa.
Requisitos para la implementación en una fase con un área de trabajo existente
Cualquier usuario con licencia que sea colaborador de las áreas de trabajo de implementación de origen y de destino, puede implementar contenidos que residan en una capacidad en un escenario con un área de trabajo existente. Para más información, revise la sección Permisos.
Carpetas en canalizaciones de implementación (versión preliminar)
Las carpetas permiten a los usuarios organizar y administrar de forma eficaz los elementos del área de trabajo de una manera familiar. Al implementar contenido que contiene carpetas en una fase diferente, se aplica automáticamente la jerarquía de carpetas de los elementos aplicados.
Representación de carpetas
- Nueva interfaz de usuario de representación de carpetas
- Interfaz de usuario original de representación de carpetas
El contenido del área de trabajo se muestra como está estructurado en el área de trabajo. Las carpetas se muestran y para ver sus elementos debe seleccionar la carpeta. La ruta de acceso completa de un elemento se muestra en la parte superior de la lista de elementos. Puesto que una implementación es solo de elementos, unicamente puede seleccionar una carpeta que contenga elementos admitidos. Seleccionar una carpeta para la implementación significa seleccionar todos sus elementos y subcarpetas con sus elementos para una implementación.
Esta imagen muestra el contenido de una carpeta dentro del área de trabajo. El nombre de ruta de acceso completo de la carpeta se muestra en la parte superior de la lista.
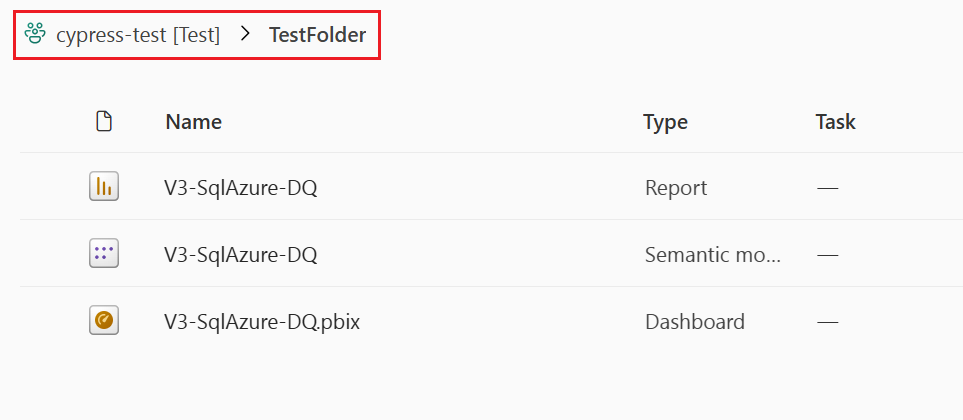
En Canalizaciones de implementación, las carpetas se consideran parte del nombre de un elemento (un nombre de elemento incluye su ruta de acceso completa). Cuando se implementa un elemento, después de cambiar su ruta de acceso (movido de la carpeta A a la carpeta B, por ejemplo), las canalizaciones de implementación aplican este cambio a su elemento emparejado durante la implementación: el elemento emparejado se moverá también a la carpeta B. Si la carpeta B no existe en la fase en la que estamos implementando, se crea primero en su área de trabajo. Las carpetas solo se pueden ver y administrar en la página del área de trabajo.
Implemente elementos dentro de una carpeta desde esa carpeta. No se pueden implementar elementos de jerarquías diferentes al mismo tiempo.
Identificación de elementos que se movieron a carpetas diferentes
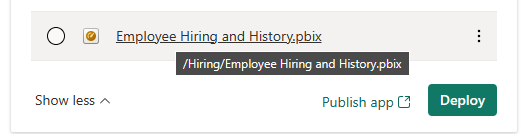
Dado que las carpetas se consideran parte del nombre del elemento, los elementos que se mueven a otra carpeta del área de trabajo se identifican en la página Canalizaciones de implementación como Diferentecuando se comparan. Este elemento no aparece en la ventana de comparación, ya que no es un cambio de esquema, sino un cambio de configuración.
- Elemento de carpeta movida en la nueva interfaz de usuario
- Elemento de carpeta movida en la interfaz de usuario original

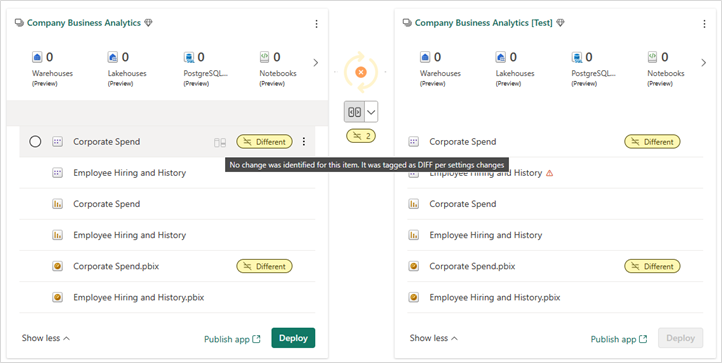
Las carpetas individuales no se pueden implementar manualmente en canalizaciones de implementación. Su implementación se desencadena automáticamente cuando se implementa al menos uno de sus elementos.
La jerarquía de carpetas de elementos emparejados solo se actualiza durante la implementación. Durante la asignación, después del proceso de emparejamiento, la jerarquía de elementos emparejados aún no se actualiza.
Dado que una carpeta solo se implementa si se implementa uno de sus elementos, no se puede implementar una carpeta vacía.
La implementación de uno de varios elementos en una carpeta también actualiza la estructura de los elementos que no se implementan en la fase de destino aunque no se implementen los propios elementos.
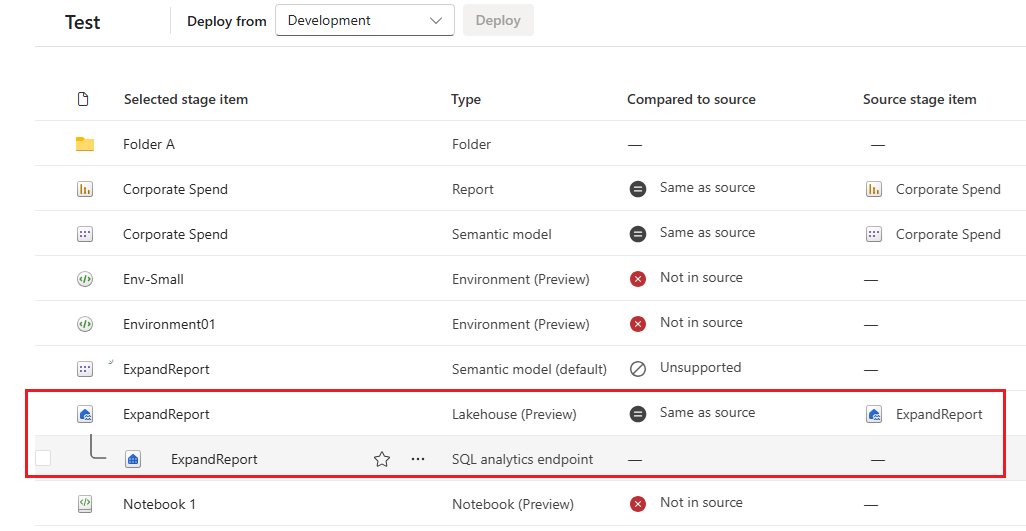
Representación de elementos primarios y secundarios
Solo aparecen en la nueva interfaz de usuario. Tiene el mismo aspecto que en el área de trabajo. El elemento secundario no se implementa, pero se vuelve a crear en la fase de destino
Propiedades de elemento copiadas durante la implementación
Para ver una lista de elementos admitidos, consulte Elementos admitidos de canalizaciones de implementación.
Durante la implementación, las siguientes propiedades de elemento se copian y se sobrescriben las propiedades de elemento en la fase de destino:
Orígenes de datos (las reglas de implementación se admiten)
Parámetros (se admiten reglas de implementación)
Objetos visuales de informe
Páginas del informe
Iconos de panel
Metadatos de modelo
Relaciones de elemento
Las etiquetas de confidencialidadsolo se copian cuando se cumple una de las condiciones siguientes. Si estas condiciones no se cumplen, las etiquetas de confidencialidad no se copian durante la implementación.
Se implementa un nuevo elemento o se implementa un elemento existente en una fase vacía.
Nota
En los casos en los que el etiquetado predeterminado está habilitado en el inquilino y la etiqueta predeterminada es válida, si el elemento que se implementa es un modelo semántico o flujo de datos, la etiqueta se copia del elemento de origen solo si la etiqueta tiene protección. Si la etiqueta no está protegida, la etiqueta predeterminada se aplica al modelo semántico de destino recién creado o al flujo de datos.
El elemento de origen tiene una etiqueta con protección y el elemento de destino, no. En este caso, aparece una ventana emergente que solicita consentimiento para invalidar la etiqueta de confidencialidad de destino.
Propiedades de elemento que no se copian
Las siguientes propiedades de elemento no se copian durante la implementación:
Datos: los datos no se copian. Solo se copian los metadatos
URL
Id.
Permisos: para un área de trabajo o un elemento específico
Configuración del área de trabajo: cada fase tiene su propia área de trabajo
Contenido y configuración de la aplicación: para actualizar sus aplicaciones, consulte Actualización del contenido a aplicaciones de Power BI
Las siguientes propiedades de modelo semántico tampoco se copian durante la implementación:
Asignación de roles
Programación de la actualización
Credenciales del origen de datos
Configuración del almacenamiento en caché de consultas (se puede heredar de la capacidad)
Configuración de aprobación
Características de modelos semánticos admitidas
Las canalizaciones de implementación admiten muchas características de los modelos semánticos. En esta sección se muestran dos características de modelos semánticos que pueden mejorar la experiencia de las canalizaciones de implementación:
Actualización incremental
Las canalizaciones de implementación admiten la actualización incremental, una característica que permite que los modelos semánticos de gran tamaño sean más rápidos y confiables, con un menor consumo.
Con las canalizaciones de implementación, puede hacer actualizaciones en un modelo semántico con una actualización incremental mientras conserva los datos y las particiones. Al implementar el modelo semántico, se copia la directiva.
Para comprender cómo se comporta la actualización incremental con los flujos de datos, vea ¿Por qué veo dos orígenes de datos conectados a mi flujo de datos después de usar reglas de flujo de datos?
Nota
La configuración de actualización incremental no se copia en Gen 1.
Activación de la actualización incremental en una canalización
Para habilitar la actualización incremental, configúrela en Power BI Desktop y, a continuación, publique el modelo semántico. Después de publicar, la directiva de actualización incremental es similar en toda la canalización y solo se puede crear en Power BI Desktop.
Una vez configurada la canalización con una actualización incremental, se recomienda usar el siguiente flujo:
Realice cambios en el archivo .pbix en Power BI Desktop. Para evitar tiempos de espera largos, puede realizar cambios mediante una muestra de los datos.
Cargue el archivo .pbix en la primera fase (normalmente de desarrollo).
Implemente el contenido en la siguiente fase. Después de la implementación, los cambios hechos se aplicarán a todo el modelo semántico que esté usando.
Revise los cambios realizados en cada fase y, después de comprobarlos, implemente en la siguiente fase hasta que llegue a la fase final.
Ejemplos de uso
A continuación se muestran algunos ejemplos de cómo puedes integrar la actualización incremental con canalizaciones de implementación.
Cree una nueva canalización y conéctela a un área de trabajo con un modelo semántico que tenga habilitada la actualización incremental.
Habilite la actualización incremental en un modelo semántico que ya esté en un área de trabajo de desarrollo.
Cree una canalización a partir de un área de trabajo de producción que tenga un modelo semántico que use la actualización incremental. Por ejemplo, asigne el área de trabajo a la fase de producciónde una nueva canalización y use la implementación hacia atrás para realizar la implementación en la fase de prueba y, a continuación, en la fase de desarrollo.
Publique un modelo semántico que use la actualización incremental en un área de trabajo que forme parte de una canalización existente.
Limitaciones de actualización incremental
Para la actualización incremental, las canalizaciones de implementación solo admiten los modelos semánticos que usen metadatos de modelos semánticos mejorados. Todos los modelos semánticos creados o modificados con Power BI Desktop implementan automáticamente metadatos de modelos semánticos mejorados.
Al volver a publicar un modelo semántico en una canalización activa con la actualización incremental habilitada, los siguientes cambios producen un error de implementación debido a la posible pérdida de datos:
Vuelva a publicar un modelo semántico que no use la actualización incremental para reemplazar un modelo semántico que tenga habilitada la actualización incremental.
Cambiar el nombre de una tabla que tiene habilitada la actualización incremental.
Cambiar el nombre de las columnas no calculadas de una tabla con la actualización incremental habilitada.
Se permiten otros cambios, como agregar una columna, quitar una columna y cambiar el nombre de una columna calculada. Pero si los cambios afectan a la pantalla, debe actualizar antes de que el cambio sea visible.
Modelos compuestos
El uso de modelos compuestos puede configurar un informe con varias conexiones de datos.
Puedes usar la funcionalidad de modelos compuestos para conectar un modelo semántico de Fabric a un modelo semántico externo como Azure Analysis Services. Para obtener más información, consulte Uso de DirectQuery para modelos semánticos de Fabric y Azure Analysis Services.
En una canalización de implementación, puede usar modelos compuestos para conectar un modelo semántico a otro modelo semántico de Fabric externo a la canalización.
Agregaciones automáticas
Las agregaciones automáticas se construyen sobre agregaciones definidas por el usuario y usan el aprendizaje automático para optimizar de forma continua los modelos semánticos de DirectQuery a fin de lograr el máximo rendimiento de las consultas de informes.
Cada modelo semántico mantiene sus agregaciones automáticas tras la implementación. Las canalizaciones de implementación no cambian la agregación automática de un modelo semántico. Esto significa que si implementa un modelo semántico con una agregación automática, la agregación automática en la fase de destino permanece tal como está y la agregación automática implementada desde la fase de origen no se sobrescribe.
Para habilitar las agregaciones automáticas, siga las instrucciones de Configuración de agregaciones automáticas.
Tablas híbridas
Las tablas híbridas son tablas con actualización incremental que pueden tener particiones de consulta directa y de importación. Durante una implementación limpia se copian tanto la directiva de actualización como las particiones de tablas híbridas. Al implementar en una fase de canalización que ya tiene particiones de tablas híbridas, solo se copia la directiva de actualización. Para actualizar las particiones, actualice la tabla.
Actualización del contenido a aplicaciones de Power BI
Las aplicaciones de Power BI son la manera recomendada de distribuir contenido a los consumidores de Fabric gratuitos. Puede actualizar el contenido de las aplicaciones de Power BI mediante una canalización de implementación, lo que le proporciona más control y flexibilidad en lo que se refiere al ciclo de vida de la aplicación.
Cree una aplicación para cada fase de canalización de implementación; de esta forma puede probar cada actualización desde el punto de vista de un usuario final. Use el botón Publicar o Ver en la tarjeta del área de trabajo para publicar o ver la aplicación en una fase de canalización específica.
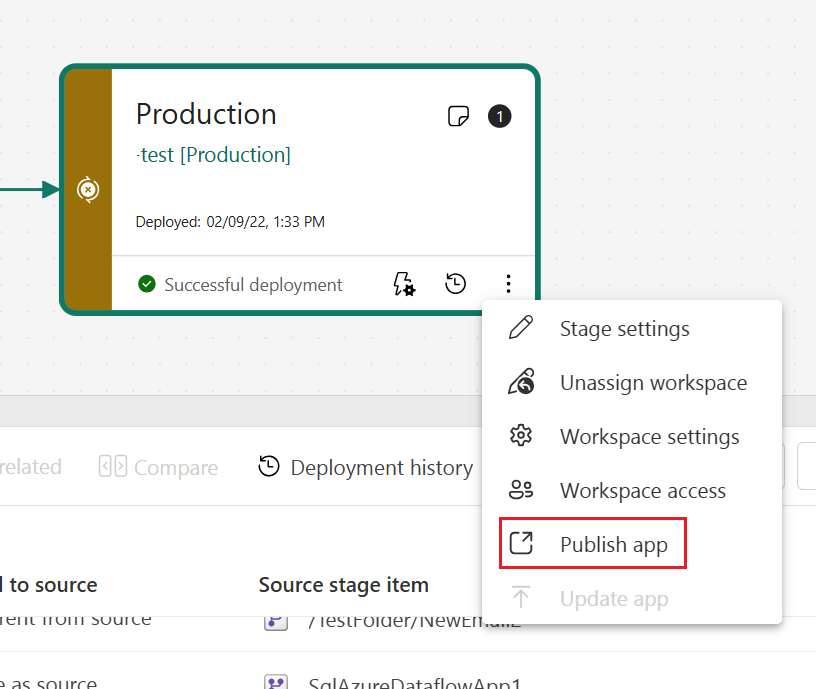

En la fase de producción, también puede actualizar la página de la aplicación en Fabric para que las actualizaciones de contenido estén disponibles para los usuarios de la aplicación.
- Actualizar la aplicación: nueva interfaz de usuario
- Actualizar la aplicación: interfaz de usuario original


Importante
El proceso de implementación no incluye la actualización del contenido o la configuración de la aplicación. Para aplicar cambios al contenido o la configuración, debe actualizar manualmente la aplicación en la fase de canalización requerida.
Permisos
Los permisos son necesarios para la canalización y para las áreas de trabajo que se le asignan. Los permisos de canalización y los permisos del área de trabajo se conceden y administran por separado.
Las canalizaciones solo tienen un permiso, Administrador, que es necesario para compartir, editar y eliminar una canalización.
Las áreas de trabajo tienen permisos diferentes, también denominados roles. Los roles del área de trabajo determinan el nivel de acceso a un área de trabajo de una canalización.
Las canalizaciones de implementación no admiten grupos de Microsoft 365 como administradores de canalización.
Para realizar la implementación desde una fase a otra en la canalización, debe ser un administrador de canalización y un colaborador, miembro o administrador de las áreas de trabajo asignadas a las fases implicadas. Por ejemplo, un administrador de canalización que no tiene asignado un rol de área de trabajo puede ver la canalización y compartirla. Pero este usuario no puede ver el contenido del área de trabajo en la canalización, o en el servicio de Power BI, ni puede realizar implementaciones.
Tabla de permisos
En esta sección se describen los permisos de canalización de implementación. Los permisos que se enumeran en esta sección pueden tener aplicaciones diferentes en otras características de Fabric.
El permiso de canalización de implementación más bajo es administrador de canalización y es necesario para todas las operaciones de canalización de implementación.
| Usuario | Permisos de canalización | Comentarios |
|---|---|---|
| Administrador de canalización |
|
El acceso a la canalización no concede permisos para ver o realizar acciones en el contenido del área de trabajo. |
| Visor del área de trabajo (y administrador de canalización) |
|
Los miembros del área de trabajo que tienen asignado el rol Visor sin permisos de compilación no pueden acceder al modelo semántico ni editar el contenido del área de trabajo. |
| Colaborador del área de trabajo (y administrador de canalización) |
|
|
| Miembro del área de trabajo (y administrador de canalización) |
|
Si la opción Bloquear el intento de volver a publicar y deshabilitar la actualización del paquete, que se encuentra en la sección Seguridad de modelo semántico del inquilino, está habilitada, solo los propietarios de modelos semánticos podrán actualizarlos. |
| Administrador del área de trabajo (y administrador de canalización) |
|
Permisos concedidos
Al implementar elementos de Power BI, la propiedad del elemento implementado puede cambiar. Revise la tabla siguiente para comprender quién puede implementar cada elemento y cómo la implementación afecta a la propiedad del elemento.
| Elemento de Fabric | Permiso necesario para implementar un elemento existente | Propiedad del elemento después implementar por primera vez | Propiedad del elemento después de implementar en una fase con el elemento |
|---|---|---|---|
| Modelo semántico | Miembro del área de trabajo | El usuario que ha realizado la implementación se convierte en el propietario | Sin cambios |
| Flujo de datos | Propietario del flujo de datos | El usuario que ha realizado la implementación se convierte en el propietario | Sin cambios |
| Data mart | Propietario de Datamart | El usuario que ha realizado la implementación se convierte en el propietario | Sin cambios |
| Informe paginado | Miembro del área de trabajo | El usuario que ha realizado la implementación se convierte en el propietario | El usuario que ha realizado la implementación se convierte en el propietario |
Permisos necesarios para acciones populares
En la tabla siguiente se enumeran los permisos necesarios para las acciones populares de canalización de implementación. A menos que se especifique lo contrario, para cada acción necesita todos los permisos enumerados.
| Acción | Permisos necesarios |
|---|---|
| Visualización de la lista de canalizaciones de la organización | No se requiere ninguna licencia (usuario gratuito) |
| Crear una canalización | Un usuario con una de las licencias siguientes:
|
| Eliminación de una canalización | Administrador de canalización |
| Adición o eliminación de un usuario de canalización | Administrador de canalización |
| Asignación de un área de trabajo a una fase |
|
| Desasignación de un área de trabajo de una fase | Uno de los siguientes roles:
|
| Implementación en una fase vacía /véase nota) |
|
| Implementar elementos en la siguiente fase (consulte la nota) |
|
| Visionado o establecimiento de una regla |
|
| Administración de la configuración de la canalización | Administrador de canalización |
| Visualización de una fase de canalización |
|
| Visualización de la lista de elementos de una fase | Administrador de canalización |
| Comparación de dos fases |
|
| Visualización del historial de implementaciones | Administrador de canalización |
Nota
Para implementar contenido en el entorno GCC, debe ser al menos miembro del área de trabajo de origen y de destino. Todavía no se admite la implementación como colaborador.
Consideraciones y limitaciones
En esta sección se enumeran la mayoría de las limitaciones de las canalizaciones de implementación.
- El área de trabajo debe residir en una capacidad de Fabric.
- Actualmente, al implementar un área de trabajo en un área de trabajo de destino existente en otra región, es posible que no haya una advertencia en el cuadro de diálogo de implementación.
- El número máximo de elementos que se pueden implementar en una sola implementación es 300.
- No se admite la descarga de un archivo .pbix después de la implementación.
- Los grupos de Microsoft 365 no se admiten como administradores de canalización.
- Al implementar un elemento de Power BI por primera vez, si otro elemento de la fase de destino tiene el mismo nombre y tipo (por ejemplo, si ambos archivos son informes), se produce un error en la implementación.
- Para obtener una lista de las limitaciones de las áreas de trabajo, vea Limitaciones de asignación del área de trabajo.
- Para ver la lista de elementos admitidos, consulte Elementos admitidos. No se admite ningún elemento que no esté en la lista.
- Se produce un error en la implementación si alguno de los elementos tiene dependencias circulares o propias (por ejemplo, el elemento A hace referencia al elemento B y el elemento B, al elemento A).
- No se admiten informes PBIR.
Limitaciones del modelo semántico
No se pueden implementar los conjuntos de datos que usan la conectividad de datos en tiempo real.
No se admite un modelo semántico con modo de conectividad DirectQuery o Compuesto que use tablas de variación o de fecha y hora automáticas. Para obtener más información, consulte ¿Qué puedo hacer si tengo un conjunto de datos con el modo de conectividad DirectQuery o compuesto que usa tablas de variación o calendario?.
Durante la implementación, si el modelo semántico de destino usa una conexión dinámica, el modelo semántico de origen también debe usar este modo de conexión.
Después de la implementación, no se admite la descarga de un modelo semántico (desde la fase en la que se ha implementado).
Para consultar una lista de las limitaciones de las reglas de implementación, vea Limitaciones de las reglas de implementación.
Si el enlace automático está activado, haga lo siguiente:
- No se admiten consultas nativas ni DirectQuery juntas. Esto incluye conjuntos de datos de proxy.
- La conexión del origen de datos debe ser el primer paso de la expresión mashup.
Cuando se implementa un modelo semántico de Direct Lake, no se enlaza automáticamente a los elementos de la fase de destino. Por ejemplo, si un LakeHouse es un origen para un modelo semántico de DirectLake y ambos se implementan en la siguiente fase, el modelo semántico de DirectLake en la fase de destino seguirá enlazado a LakeHouse en la fase de origen. Utilice reglas de datasource para vincularlo a un elemento de la etapa de destino. Otros tipos de modelos semánticos se enlazan automáticamente al elemento enlazado en la fase de destino.
Limitaciones de los flujos de datos
La configuración de actualización incremental no se copia en Gen 1.
Al implementar un flujo de datos en una fase vacía, las canalizaciones de implementación crean una área de trabajo y establecen el almacenamiento del flujo de datos en un almacenamiento de blobs de Fabric. El almacenamiento de blobs se usa incluso si el área de trabajo de origen está configurada para usar Azure Data Lake Storage Gen2 (ADLS Gen2).
La entidad de servicio no se admite para los flujos de datos.
No se admite la implementación del modelo de datos común (CDM).
Para obtener las limitaciones de las reglas de canalización de implementación que afectan a los flujos de datos, consulte Limitaciones de las reglas de implementación.
Si se actualiza un flujo de datos durante la implementación, se produce un error en la implementación.
Al comparar fases durante la actualización del flujo de datos, los resultados son impredecibles.
Limitaciones de Datamart
No se puede implementar un datamart con etiquetas de confidencialidad.
Para implementar un datamart, debes ser el propietario del datamart.