Resistencia de la plataforma Azure
Sugerencia
Este contenido es un extracto del libro electrónico “Architecting Cloud Native .NET Applications for Azure” (Diseño de la arquitectura de aplicaciones .NET nativas en la nube para Azure), disponible en Documentos de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

La compilación de una aplicación confiable en la nube es diferente al desarrollo clásico de las aplicaciones locales. Aunque históricamente se compraba hardware de gama superior para escalar verticalmente, en un entorno de nube se escala horizontalmente. En vez de intentar evitar los errores, el objetivo es minimizar sus efectos y que el sistema se mantenga estable.
Dicho esto, las aplicaciones confiables en la nube tienen varias características distintivas:
- Son resistentes, se recuperan limpiamente de los problemas y siguen funcionando.
- Tienen alta disponibilidad y se ejecutan según lo previsto en un estado correcto, sin tiempos de inactividad significativos.
Comprender cómo funcionan juntas estas características (y cómo influyen en el coste) es esencial para compilar una aplicación confiable y nativa de nube. A continuación, veremos las formas en que puede compilar resistencia y disponibilidad en las aplicaciones nativas de nube, gracias al provecho que puede sacar de las características de la nube de Azure.
Diseño con resistencia
Hemos dicho que la resistencia permite que la aplicación reaccione ante errores y siga siendo funcional. En las Notas del producto para la resistencia en Azure se dan instrucciones para lograr resistencia en la plataforma Azure. Estas son algunas recomendaciones fundamentales:
Errores de hardware. Compile redundancia en la aplicación mediante la implementación de componentes en distintos dominios de error. Por ejemplo, asegúrese de que las máquinas virtuales de Azure se colocan en bastidores diferentes mediante Conjuntos de disponibilidad.
Errores de los centros de datos. Compile redundancia en la aplicación con zonas de aislamiento de errores en los centros de datos. Por ejemplo, asegúrese de que las máquinas virtuales de Azure se colocan en distintos centros de datos con aislamiento por error mediante Azure Availability Zones.
Errores en regiones. Replique los datos y los componentes en otra región para que las aplicaciones se puedan recuperar rápidamente. Por ejemplo, use Azure Site Recovery para replicar máquinas virtuales de Azure en otra región de Azure.
Carga pesada. Equilibre la carga en las instancias para controlar los picos de uso. Por ejemplo, coloque dos o más máquinas virtuales de Azure detrás de un equilibrador de carga para distribuir el tráfico por todas las máquinas virtuales.
Eliminación accidental o daños en los datos. Realice una copia de seguridad de los datos para que se puedan restaurar si se producen eliminaciones o daños. Por ejemplo, use Azure Backup para realizar copias de seguridad periódicas de las máquinas virtuales de Azure.
Diseño con redundancia
Los errores varían en el ámbito del impacto. Un error de hardware, como un disco con errores, puede afectar a un nodo único de un clúster. Un error de conmutador de red podría afectar a toda una estantería de servidor. Los errores menos habituales, como los cortes de luz, podrían interrumpir la actividad de un centro de datos completo. Es aún más improbable que una región deje de estar disponible.
La redundancia es una forma de proporcionar resistencia a la aplicación. El nivel exacto de redundancia necesaria depende de los requisitos empresariales y afectará tanto al coste como a la complejidad del sistema. Por ejemplo, las implementaciones en varias regiones son más caras y más complicadas de administrar que las de una sola región. Necesitará procedimientos operativos para administrar la conmutación por error y la conmutación por recuperación. El coste adicional y la complejidad podrían estar justificados para algunos escenarios empresariales, pero no para otros.
Para diseñar la arquitectura de la redundancia... ¿Debe identificar las rutas críticas de la aplicación y, después, determinar si hay redundancia en cada punto de la ruta de acceso? Si se produce un error en un subsistema, ¿la aplicación conmutará por error a otro elemento? Por último, necesita una comprensión clara de esas características integradas en la plataforma en la nube de Azure, para poder sacar provecho de ellas y así cumplir con los requisitos de redundancia. Estas son algunas recomendaciones para diseñar la arquitectura de la redundancia:
Implemente varias instancias de servicios. Si la aplicación depende de una única instancia de un servicio, crea un único punto de error. El aprovisionamiento de varias instancias mejora tanto la resistencia como la escalabilidad. Al hospedar en Azure Kubernetes Service, puede configurar mediante declaración instancias redundantes (conjuntos de réplicas) en el archivo de manifiesto de Kubernetes. El valor del recuento de réplicas se puede administrar mediante programación, en el portal o mediante características de escalado automático.
Sacar provecho de un equilibrador de carga. El equilibrio de carga distribuye las solicitudes de la aplicación en instancias de servicio correctas y elimina automáticamente de la rotación las instancias incorrectas. Al hacer la implementación en Kubernetes, el equilibrio de carga se puede especificar en el archivo de manifiesto de Kubernetes, en la sección Servicios.
Planificación de la implementación en varias regiones. Si implementa su aplicación en una sola región y dicha región deja de estar disponible, la aplicación tampoco estará disponible. Esto puede ser inaceptable según los términos de los contratos de nivel de servicio de su aplicación. Para evitar esa situación, considere la posibilidad de implementar la aplicación y sus servicios en varias regiones. Por ejemplo, un clúster de Azure Kubernetes Service (AKS) se implementa en una sola región. Para proteger el sistema de un error que se deba a la región, puede implementar la aplicación en varios clústeres de AKS, en distintas regiones, y usar la característica Regiones emparejadas para coordinar las actualizaciones de la plataforma y priorizar los esfuerzos de recuperación.
Habilitación de la replicación geográfica. La replicación geográfica para servicios como Azure SQL Database y Cosmos DB creará réplicas secundarias de los datos en varias regiones. Aunque ambos servicios replicarán automáticamente los datos dentro de la misma región, la replicación geográfica le protege contra una interrupción regional, ya que le permite conmutar por error a una región secundaria. Otro procedimiento recomendado para la replicación geográfica se centra en el almacenamiento de imágenes de contenedor. Para implementar un servicio en AKS, debe almacenar y extraer la imagen de un repositorio. Azure Container Registry se integra con AKS y puede almacenar imágenes de contenedor de forma segura. Para mejorar el rendimiento y la disponibilidad, considere la opción de replicar geográficamente sus imágenes en un registro de cada región en la que haya un clúster de AKS. Así, cada clúster de AKS extrae imágenes de contenedor del registro de contenedor local que se halle en su región, como se muestra en la figura 6-4:
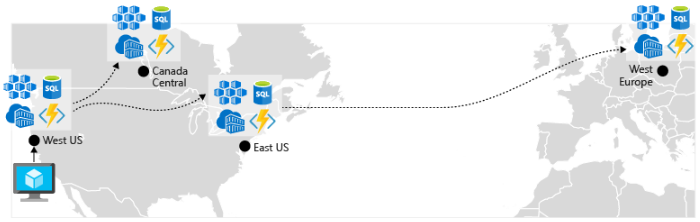
Figura 6-4. Recursos replicados en varias regiones
- Implementa un equilibrador de carga de tráfico DNS.Azure Traffic Manager proporciona alta disponibilidad para las aplicaciones críticas mediante el equilibrio de carga en el nivel DNS. Puede enrutar el tráfico a diferentes regiones en función de la geografía, el tiempo de respuesta del clúster e incluso el estado del punto de conexión de la aplicación. Por ejemplo, Azure Traffic Manager puede dirigir a los clientes a la instancia de la aplicación y al clúster de AKS más próximos. Si tiene varios clústeres de AKS en distintas regiones, use Traffic Manager para controlar cómo fluye el tráfico a las aplicaciones que se ejecutan en cada clúster. En la figura 6-5 se muestra este escenario.
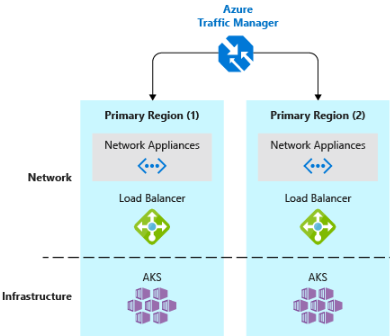
Figura 6-5. AKS y Azure Traffic Manager
Diseño para escalabilidad
La nube se basa en el escalado. La capacidad de aumentar o disminuir los recursos del sistema para abordar la carga creciente o decreciente del sistema es un principio clave de la nube de Azure. Sin embargo, para escalar eficazmente una aplicación, necesita comprender las características de escalado de cada servicio de Azure que incluya en la aplicación. Estas son recomendaciones para implementar de forma eficaz el escalado en el sistema.
Diseño para el escalado. Una aplicación debe diseñarse para el escalado. Para iniciarse, los servicios deben estar sin estado para que las solicitudes se puedan enrutar a cualquier instancia. Tener servicios sin estado también significa que la adición o eliminación de una instancia no supone efectos negativos para los usuarios actuales.
Cargas de trabajo de particiones. La descomposición de dominios en microservicios independientes y autosuficientes permite que cada servicio se escale independientemente de otros. Normalmente, los servicios tendrán necesidades y requisitos de escalabilidad diferentes. La creación de particiones permite escalar solo lo que se debe escalar, sin el coste innecesario de escalar una aplicación completa.
Se prioriza el escalado horizontal. Las aplicaciones basadas en la nube priorizan el escalado horizontal de los recursos, en detrimento del escalado vertical. El escalado horizontal implica agregar más recursos de servicio a un sistema existente para satisfacer y compartir un nivel de rendimiento deseado. El escalado vertical implica reemplazar los recursos existentes por un hardware más eficaz (más discos, más memoria y más núcleos de procesamiento). El escalado horizontal se puede invocar automáticamente con las características de escalado automático disponibles en algunos recursos de la nube de Azure. El escalado horizontal en varios recursos también agrega redundancia al sistema en su totalidad. Por último, el escalado vertical de un único recurso suele ser más caro que el escalado horizontal en muchos recursos más pequeños. En la figura 6-6 se muestran los dos enfoques:
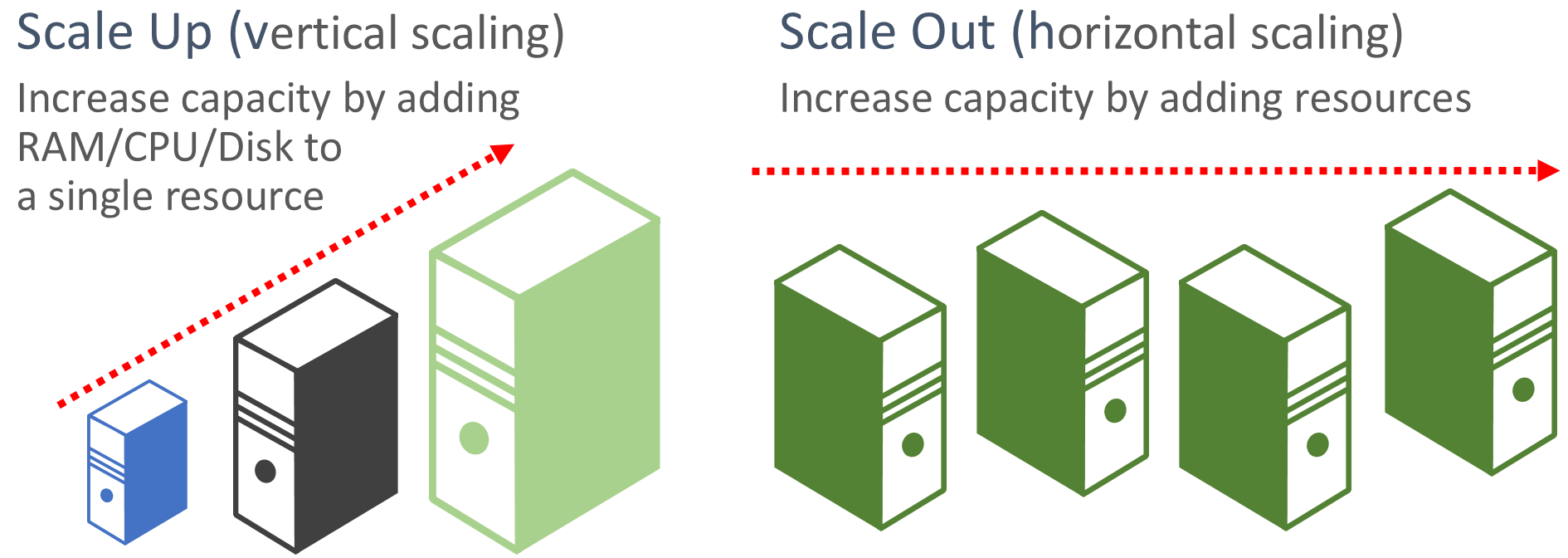
Figura 6-6. Escalado vertical versus escalado horizontal
Escale proporcionalmente. Al escalar un servicio, piense en base a conjuntos de recursos. Si escala considerablemente un servicio específico, ¿qué impacto tendrá en los almacenes de datos de back-end, las memorias caché y los servicios dependientes? Algunos recursos, como Cosmos DB, pueden escalar horizontalmente de manera proporcional, pero muchos otros no. Es bueno asegurarse de que un recurso no se escale horizontalmente hasta un punto en el que agote otros recursos asociados.
Evite la afinidad. Un procedimiento recomendado es asegurarse de que un nodo no requiere afinidad local, a menudo denominada “sticky session” (sesión fija). Una solicitud debe ser capaz de enrutarse a cualquier instancia. Si necesita conservar el estado, este debe guardarse en una caché distribuida, como Azure Redis Cache.
Aprovechar las características de escalado automático de la plataforma. Use las características de escalado automático integradas siempre que sea posible, en vez de mecanismos personalizados o de terceros. Siempre que sea posible, use reglas de escalado programadas para garantizar que los recursos están disponibles sin retrasos iniciales, pero agregue escalado automático reactivo a las reglas, cuando sea apropiado, para hacer frente a cambios inesperados en la demanda. Para más información, consulte Guía de escalado automático.
Escalado horizontal repentino. Una última práctica es escalar horizontalmente de forma repentina para poder satisfacer rápidamente picos inmediatos en el tráfico sin perder actividad del negocio. Después, se reduce horizontalmente (es decir, se quitan instancias innecesarias) con cautela para mantener el sistema estable. Una manera sencilla de implementar esto es usando el período de recuperación, que es el tiempo de espera entre las operaciones de escalado. Establézcalo en cinco minutos para agregar recursos y en 15 minutos como tope para quitar instancias.
Reintento integrado en los servicios
Uno de los procedimientos recomendados que mencionamos en una sección anterior es la implementación de operaciones de reintento en la programación. Tenga en cuenta que muchos servicios de Azure y sus SDK de cliente correspondientes también incluyen mecanismos de reintento. En la lista siguiente se resumen las características de reintento de los muchos servicios de Azure que se describen en este libro:
Azure Cosmos DB. La clase DocumentClient de la API de cliente reintenta automáticamente los intentos con errores. El número de reintentos y el tiempo de espera máximo son configurables. Las excepciones producidas por la API de cliente son solicitudes que superan lo marcado en la directiva de reintentos o errores no transitorios.
Azure Redis Cache. El cliente de Redis StackExchange usa una clase de administrador de conexiones que incluye reintentos de los intentos erróneos. El número de reintentos, la directiva de reintentos específica y el tiempo de espera son configurables.
Azure Service Bus. El cliente de Service Bus expone una clase RetryPolicy que se puede configurar con un intervalo de espera, un recuento de reintentos y TerminationTimeBuffer, que especifica el tiempo máximo que puede tardar una operación. La directiva predeterminada es nueve reintentos como máximo, con un período de espera de 30 segundos entre intentos.
Azure SQL Database. Se proporciona compatibilidad con reintentos al usar la biblioteca de Entity Framework Core.
Azure Storage. La biblioteca cliente de Storage admite operaciones de reintento. Las estrategias varían entre tablas, blobs y colas de Azure Storage. Además, los reintentos alternativos cambian entre las ubicaciones de los servicios de almacenamiento principal y secundario cuando se habilita la característica de redundancia geográfica.
Azure Event Hubs. La biblioteca cliente del Centro de eventos cuenta con una propiedad RetryPolicy, que incluye una característica de retroceso exponencial configurable.