Patrones de resistencia de las aplicaciones
Sugerencia
Este contenido es un extracto del libro electrónico “Architecting Cloud Native .NET Applications for Azure” (Diseño de la arquitectura de aplicaciones .NET nativas en la nube para Azure), disponible en Documentos de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

La primera línea de defensa es la resistencia de las aplicaciones.
Aunque podría invertir mucho tiempo escribiendo su propio marco de resistencia, estos productos ya existen. Polly es una biblioteca completa de resistencia de .NET y control de errores transitorios que permite a los desarrolladores expresar directivas de resistencia de forma fluida y segura para subprocesos. Polly tiene como destino las aplicaciones compiladas con .NET Framework o .NET 7. En la tabla siguiente se describen las características de resistencia, denominadas policies, disponibles en la biblioteca de Polly. Se pueden aplicar de forma individual o agrupada.
| Directiva | Experiencia |
|---|---|
| Volver a intentar | Configura las operaciones de reintento en las operaciones designadas. |
| Disyuntor | Bloquea las operaciones solicitadas durante un período predefinido cuando los errores superan un umbral configurado |
| Tiempo de espera | Establece el límite durante el cual un autor de la llamada puede esperar una respuesta. |
| Compartimentado | Restringe las acciones a un conjunto de recursos de tamaño fijo para evitar que las llamadas con error saturen un recurso. |
| Cache | Almacena las respuestas automáticamente. |
| Reserva | Define el comportamiento estructurado tras un error. |
Tenga en cuenta cómo en la ilustración anterior se aplican las directivas de resistencia a los mensajes de solicitud, tanto si proceden de un cliente externo como de un servicio back-end. El objetivo es compensar la solicitud de un servicio que podría estar momentáneamente no disponible. Estas interrupciones de corta duración normalmente se manifiestan con los códigos de estado HTTP que se muestran en la tabla siguiente.
| Código de estado HTTP | Causa |
|---|---|
| 404 | No encontrado |
| 408 | Tiempo de espera de solicitud |
| 429 | Demasiadas solicitudes (lo más probable es que se haya limitado) |
| 502 | Puerta de enlace incorrecta |
| 503 | Servicio no disponible |
| 504 | Tiempo de espera de la puerta de enlace |
Pregunta: ¿Reintentaría un código de estado HTTP de 403 - Prohibido? No. Aquí, el sistema funciona correctamente, pero se informa al autor de la llamada de que no están autorizados para realizar la operación solicitada. Se debe tener cuidado de reintentar solo las operaciones causadas por errores.
Como se recomienda en el capítulo 1, los desarrolladores de Microsoft que construyen aplicaciones nativas de nube deben orientarse a la plataforma .NET. La versión 2.1 introdujo la biblioteca HTTPClientFactory para crear instancias de cliente HTTP para interactuar con recursos basados en direcciones URL. Sustituyendo a la clase original HTTPClient, la clase factory admite muchas características mejoradas, una de las cuales es la estrecha integración con la biblioteca de resistencia Polly. Con ella, puede definir fácilmente directivas de resistencia en la clase Startup de la aplicación para controlar errores parciales y problemas de conectividad.
A continuación, vamos a expandir los patrones de reintentos y disyuntores.
Patrón Retry
En un entorno nativo de nube distribuido, las llamadas a servicios y recursos en la nube pueden producir un error debido a errores transitorios (de corta duración), que normalmente se corrigen después de un breve período de tiempo. La implementación de una estrategia de reintento ayuda a un servicio nativo en la nube a mitigar estos escenarios.
El patrón de reintento permite a un servicio reintentar una operación de solicitud con error un número de veces (configurable) con un tiempo de espera exponencialmente creciente. En la figura 6-2 se muestra un reintento en acción.
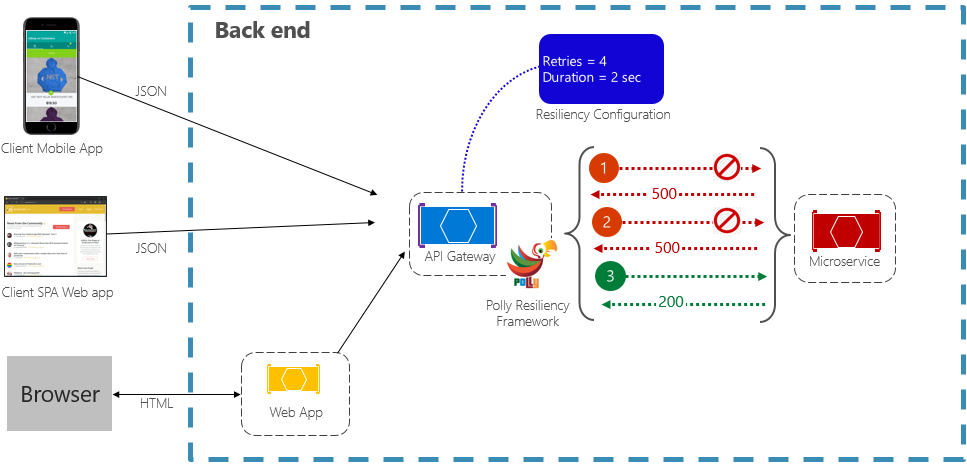
Figura 6-2. Patrón de reintento en acción
En la ilustración anterior, se ha implementado un patrón de reintento para una operación de solicitud. Está configurado para permitir hasta cuatro reintentos antes de que se produzca un error con un intervalo de retroceso (tiempo de espera) a partir de dos segundos, lo que duplica exponencialmente cada intento posterior.
- Se produce un error en la primera invocación y devuelve un código de estado HTTP de 500. La aplicación espera dos segundos y vuelve a intentar la llamada.
- La segunda invocación también produce un error y devuelve un código de estado HTTP de 500. La aplicación ahora duplica el intervalo de retroceso en cuatro segundos y vuelve a intentar la llamada.
- Por último, la tercera llamada se realiza correctamente.
- En este escenario, la operación de reintento habría intentado hasta cuatro reintentos al duplicar la duración del retroceso antes de producir un error en la llamada.
- Si se produjo un error en el cuarto reintento, se invocaría una directiva de reserva para controlar correctamente el problema.
Es importante aumentar el período de retroceso antes de reintentar la llamada para permitir que el tiempo de servicio sea autocorrección. Se recomienda implementar un retroceso exponencialmente creciente (duplicando el período en cada reintento) para permitir un tiempo de corrección adecuado.
Patrón de disyuntor
Aunque el patrón de reintento puede ayudar a salvar una solicitud entrelazada en un error parcial, hay situaciones en las que los errores pueden deberse a eventos imprevistos que requerirán períodos de tiempo más largos para resolverse. La gravedad de estos errores puede ir desde una pérdida parcial de conectividad hasta el fallo total del servicio. En estas situaciones, no tiene sentido que una aplicación vuelva a intentar continuamente una operación que es poco probable que se ejecute correctamente.
Para empeorar las cosas, la ejecución de operaciones de reintento continuos en un servicio que no responde puede llevarle a un escenario de denegación de servicio autoimpuesto en el que se inunda el servicio con llamadas continuas que agotan recursos, como memoria, subprocesos y conexiones de base de datos, lo que provoca un error en partes no relacionadas del sistema que usan los mismos recursos.
En estas situaciones, podría ser preferible para la operación dejar de funcionar de inmediato y solo intentar invocar el servicio si es probable que pueda ejecutarse correctamente.
El patrón de disyuntor puede impedir que una aplicación intente ejecutar repetidamente una operación que es probable que no se ejecute correctamente. Después de un número predefinido de llamadas con error, bloquea todo el tráfico al servicio. Periódicamente, permitirá una llamada de prueba para determinar si el error se ha resuelto. En la figura 6-3 se muestra el patrón de disyuntor en acción.
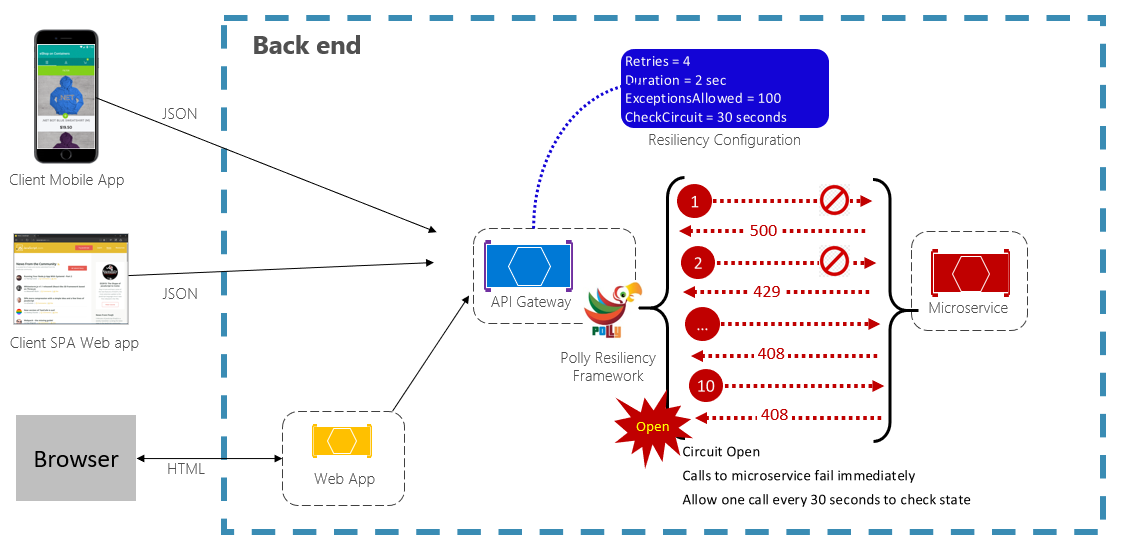
Figura 6-3. Patrón de disyuntor en acción
En la ilustración anterior, se ha agregado un patrón de disyuntor al patrón de reintento original. Tenga en cuenta cómo después de 100 solicitudes con error, los disyuntores se abren y ya no permiten llamadas al servicio. El valor CheckCircuit, establecido en 30 segundos, especifica la frecuencia con la que la biblioteca permite que una solicitud continúe con el servicio. Si esa llamada se realiza correctamente, el circuito se cierra y el servicio vuelve a estar disponible para el tráfico.
Tenga en cuenta que la intención del patrón de disyuntor es diferente a la del patrón de reintento. El patrón de reintento permite a una aplicación reintentar una operación con la expectativa de que se realizará correctamente. El patrón de disyuntor impide que una aplicación haga una operación que es probable que no se pueda realizar. Normalmente, una aplicación combinará estos dos patrones mediante el patrón de reintento para invocar una operación a través de un disyuntor.
Pruebas de resistencia
Las pruebas de resistencia no siempre se pueden realizar de la misma manera que se prueba la funcionalidad de la aplicación (mediante la ejecución de pruebas unitarias, pruebas de integración, etc.). En su lugar, debe comprobar cómo se realiza la carga de trabajo de un extremo a otro en condiciones de error que solo se producen de forma intermitente. Por ejemplo: insertar errores bloqueando procesos, certificados expirados, hacer que los servicios dependientes no estén disponibles, etc. Los marcos como chaos-monkey se pueden usar para estas pruebas de caos.
La resistencia de la aplicación es una debe para controlar las operaciones solicitadas problemáticas. Pero es solo la mitad de la historia. A continuación, tratamos las características de resistencia disponibles en la nube de Azure.