Almacenamiento en caché en una aplicación nativa en la nube
Sugerencia
Este contenido es un extracto del libro electrónico “Architecting Cloud Native .NET Applications for Azure” (Diseño de la arquitectura de aplicaciones .NET nativas en la nube para Azure), disponible en Documentos de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

Las ventajas del almacenamiento en caché se comprenden bien. La técnica funciona copiando temporalmente los datos a los que se accede con frecuencia desde un almacén de datos back-end a un almacenamiento rápido que se encuentra más cerca de la aplicación. El almacenamiento en caché a menudo se implementa donde...
- Los datos permanecen relativamente estáticos.
- El acceso a los datos es lento, especialmente en comparación con la velocidad de la memoria caché.
- Los datos están sujetos a altos niveles de contención.
¿Por qué?
Como se describe en la guía de almacenamiento en caché de Microsoft, el almacenamiento en caché puede aumentar el rendimiento, la escalabilidad y la disponibilidad de microservicios individuales y el sistema en su conjunto. Reduce la latencia y la contención de controlar grandes volúmenes de solicitudes simultáneas en un almacén de datos. A medida que aumenta el volumen de datos y el número de usuarios, mayores son las ventajas del almacenamiento en caché.
El almacenamiento en caché es más eficaz cuando un cliente lee repetidamente los datos inmutables o que cambian con poca frecuencia. Entre los ejemplos se incluye información de referencia, como la información de precios y productos o recursos estáticos compartidos que cuesta construir.
Aunque los microservicios deben estar sin estado, una caché distribuida puede admitir el acceso simultáneo a los datos de estado de sesión cuando sea absolutamente necesario.
Considera también la posibilidad de almacenar en caché para evitar cálculos repetitivos. Si una operación transforma los datos o realiza un cálculo complicado, almacena en caché el resultado de las solicitudes posteriores.
Arquitectura de almacenamiento en caché
Las aplicaciones nativas en la nube suelen implementar una arquitectura de almacenamiento en caché distribuida. La memoria caché se hospeda como un servicio de respaldo basado en la nube, independiente de los microservicios. En la figura 5-15 se muestra la arquitectura.
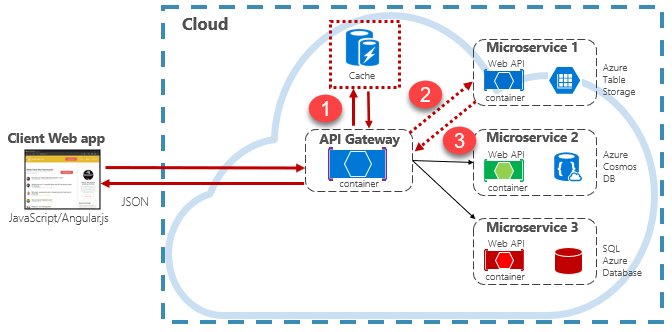
Figure 5-15: Almacenamiento en caché en una aplicación nativa en la nube
En la ilustración anterior, observa cómo la memoria caché es independiente y compartida por los microservicios. En este escenario, la puerta de enlace de API invoca la memoria caché. Como se describe en el capítulo 4, la puerta de enlace actúa como front-end para todas las solicitudes entrantes. La caché distribuida aumenta la capacidad de respuesta del sistema devolviendo los datos almacenados en caché siempre que sea posible. Además, separar la memoria caché de los servicios permite que la memoria caché se escale o se escale horizontalmente de forma independiente para satisfacer mayores demandas de tráfico.
En la ilustración anterior se presenta un patrón de almacenamiento en caché común conocido como patrón cache-aside. Para una solicitud entrante, primero debes consultar la memoria caché (paso 1) para obtener una respuesta. Si se encuentra, los datos se devuelven inmediatamente. Si los datos no existen en la memoria caché (lo que se conoce como error de caché), se recupera de una base de datos local en un servicio de bajada (paso 2). A continuación, se escribe en la memoria caché para futuras solicitudes (paso 3) y se devuelve al autor de la llamada. Se debe tener cuidado para expulsar periódicamente los datos almacenados en caché para que el sistema permanezca oportuno y coherente.
A medida que crece una memoria caché compartida, podría resultar beneficioso crear particiones de sus datos en varios nodos. Si lo haces, puedes ayudar a minimizar la contención y mejorar la escalabilidad. Muchos servicios de almacenamiento en caché admiten la capacidad de agregar (y de quitar) nodos dinámicamente y de reequilibrar los datos entre las particiones. Este enfoque normalmente implica la agrupación en clústeres. La agrupación en clústeres expone una colección de nodos federados como una caché única sin problemas. Internamente, sin embargo, los datos se dispersan por los nodos siguiendo una estrategia de distribución predefinida que equilibra la carga uniformemente.
Azure Cache for Redis
Azure Cache for Redis es un servicio de agente de mensajería y almacenamiento en caché de datos seguro, totalmente administrado por Microsoft. Consumido como una oferta de plataforma como servicio (PaaS), proporciona un alto rendimiento y un acceso de baja latencia a los datos. El servicio es accesible para cualquier aplicación dentro o fuera de Azure.
El servicio Azure Cache for Redis administra el acceso a los servidores de Redis de código abierto hospedados en centros de datos de Azure. El servicio actúa como una fachada que proporciona administración, control de acceso y seguridad. El servicio admite de forma nativa un amplio conjunto de estructuras de datos, incluidas cadenas, hashes, listas y conjuntos. Si la aplicación ya usa Redis, funcionará tal cual con Azure Cache for Redis.
Azure Cache for Redis es más que un servidor de caché simple. Puede admitir una serie de escenarios para mejorar una arquitectura de microservicios:
- Un almacén de datos en memoria
- Una base de datos no relacional distribuida
- Un agente de mensajes
- Un servidor de configuración o detección
En escenarios avanzados, se puede conservar una copia de los datos almacenados en caché en el disco. Si un evento catastrófico deshabilita tanto la caché de réplica como la principal, se reconstruye la memoria caché con la instantánea más reciente.
Azure Redis Cache está disponible en varias configuraciones predefinidas y planes de tarifa. El nivel Premium incluye muchas características de nivel empresarial, como la agrupación en clústeres, la persistencia de datos, la replicación geográfica y el aislamiento de red virtual.