¿Qué es nativo de la nube?
Sugerencia
Este contenido es un extracto del libro electrónico “Architecting Cloud Native .NET Applications for Azure” (Diseño de la arquitectura de aplicaciones .NET nativas en la nube para Azure), disponible en Documentos de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

Deje lo que esté haciendo y pida a sus compañeros que definan el término "Nativo en la nube". Hay muchas posibilidades de que obtenga varias respuestas diferentes.
Comencemos por una definición simple:
La arquitectura y las tecnologías nativas de la nube son un enfoque para diseñar, construir y manejar las cargas de trabajo que están integradas en la nube y aprovechar al máximo el modelo de informática en la nube.
Cloud Native Computing Foundation ofrece la definición oficial:
Las tecnologías nativas de la nube permiten a las organizaciones crear y ejecutar aplicaciones escalables en entornos modernos y dinámicos, como nubes públicas, privadas e híbridas. Los contenedores, las mallas de servicio, los microservicios, la infraestructura inmutable y las API declarativas son ejemplos de este enfoque.
Estas técnicas permiten sistemas de acoplamiento flexible resistentes, administrables y observables. Su combinación con una automatización sólida, permite a los ingenieros realizar cambios de alto impacto de forma frecuente y predecible con un mínimo esfuerzo.
Nativo de la nube tiene mucho que ver con la velocidad y la agilidad. Los sistemas empresariales han pasado de habilitar las funcionalidades empresariales a ser armas de transformación estratégica que aumentan la velocidad y aceleran el crecimiento de las empresas. Es imperativo conseguir nuevas ideas para que la comercialización se realice de inmediato.
Al mismo tiempo, los sistemas empresariales se han vuelto cada vez más complejos y los usuarios más exigentes y esperan respuestas rápidas a sus problemas, características innovadoras y un tiempo de inactividad cero. Actualmente, los problemas de rendimiento, los errores recurrentes y la incapacidad para moverse rápidamente son factores inaceptables que harán que los usuarios empiecen a pensar en irse a la competencia. Los sistemas nativos de la nube están diseñados para adoptar cambios rápidos a gran escala y para ofrecer resistencia.
Estas son algunas de las empresas que han implementado técnicas nativas de la nube. Piense en la velocidad, agilidad y escalabilidad que han logrado.
| Compañía | Experiencia |
|---|---|
| Netflix | Tiene más de 600 servicios en producción. Realiza implementaciones 100 veces al día. |
| Uber | Tiene más de 1000 servicios en producción. Realiza implementaciones varios miles veces cada semana. |
| Tiene más de 3000 servicios en producción. Realiza implementaciones 1000 veces al día. |
Como puede ver, Netflix, Uber y WeChat exponen sistemas nativos en la nube que constan de muchos servicios independientes. Este estilo arquitectónico les permite responder rápidamente a las condiciones de mercado. De esta forma pueden actualizar instantáneamente pequeñas áreas de cualquier aplicación dinámica y compleja sin necesidad de volver a implementarla por completo. Escalan los servicios uno a uno cuando sea necesario.
Los pilares de los elementos nativos de la nube
La velocidad y agilidad de los elementos nativos de la nube nativa se deben a muchos factores, y el más importante es la infraestructura de la nube. Pero hay más: otros cinco pilares básicos que se muestran en la figura 1-3 también proporcionan la base para los sistemas nativos de la nube.
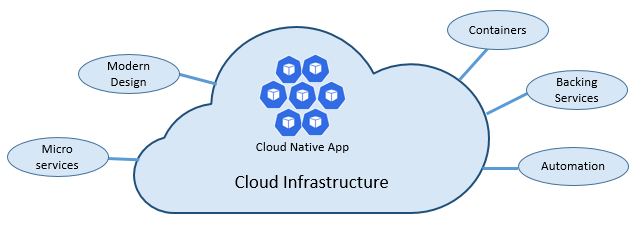
Figura 1-3. Pilares básicos de los elementos nativos de la nube
Dediquemos un tiempo a comprender mejor la importancia de cada uno de estos pilares.
La nube
Los sistemas nativos de la nube aprovechan al máximo el modelo de servicio en la nube.
Están diseñados para prosperar en un entorno dinámico y virtualizado en la nube y usan ampliamente la infraestructura de proceso de plataforma como servicio (PaaS) y los servicios administrados. Tratan la infraestructura subyacente como descartable (aprovisionada en minutos y cambiada de tamaño, escalada o destruida a petición) a través de la automatización.
Tenga en cuenta la diferencia entre cómo tratamos las mascotas y los productos básicos. En un centro de datos tradicional, los servidores se tratan como mascotas: una máquina física, con un nombre significativo y cuidado. Para escalarlos, agregue más recursos a la misma máquina (escalado vertical). Si el servidor deja de funcionar correctamente, solucione el problema. Si el servidor deja de estar disponible, todo el mundo se da cuenta.
El modelo de servicio de productos básicos es diferente. Cada instancia se aprovisiona como una máquina virtual o un contenedor. Son idénticas y se les asigna un identificador del sistema, como Service-01, Service-02, etc. Puede escalar mediante la creación de más instancias (escalado horizontal). Nadie sabe cuándo una instancia deja de estar disponible.
El modelo de productos básicos adopta una infraestructura inmutable. Los servidores no se reparan ni modifican. Si alguno no funciona o requiere actualización, se destruye y se aprovisiona uno nuevo (todo ello a través de la automatización).
Los sistemas nativos en la nube adoptan el modelo de servicio de productos básicos. Siguen ejecutándose cuando la infraestructura se escala o se reduce horizontalmente, independientemente de las máquinas en las que se ejecutan.
La plataforma en la nube de Azure admite este tipo de infraestructura, de gran elasticidad, con funcionalidades de escalado automático, recuperación automática y supervisión.
Diseño moderno
¿Cómo diseñaría una aplicación nativa de la nube? ¿Qué aspecto tendría la arquitectura? ¿Qué principios, patrones y procedimientos recomendados cumpliría? ¿Qué problemas operativos y de infraestructura serían importantes?
La metodología Twelve-Factor App
Twelve-Factor Application es una metodología ampliamente aceptada para crear aplicaciones en la nube. Describe un conjunto de principios y prácticas que los desarrolladores siguen para construir aplicaciones optimizadas para los modernos entornos de nube. Se presta especial atención a la portabilidad entre entornos y a la automatización declarativa.
Aunque se puede aplicar a cualquier aplicación basada en Web, muchos profesionales consideran que Twelve-Factor es una base sólida para crear aplicaciones nativas de la nube. Los sistemas creados sobre estos principios pueden realizar implementaciones y escalar rápidamente, así como agregar características para reaccionar rápidamente a los cambios en el mercado.
En la tabla siguiente se resalta la metodología Twelve-Factor:
| Factor | Explicación |
|---|---|
| 1: Código base | Un código base único para cada microservicio, almacenado en su propio repositorio. Se realiza su seguimiento con el control de versiones, se puede implementar en varios entornos (control de calidad, almacenamiento provisional, producción). |
| 2: Dependencias | Cada microservicio aísla y empaqueta sus propias dependencias y realiza los cambios sin que ello afecte a todo el sistema. |
| 3: Configuraciones | La información de configuración se saca del microservicio y se externaliza a través de una herramienta de administración de configuración que está fuera del código. La misma implementación se puede propagar entre entornos con la configuración correcta aplicada. |
| 4: Servicios de respaldo | Los recursos auxiliares (almacenes de datos, cachés, agentes de mensajes) deben exponerse mediante una dirección URL direccionable. Al hacerlo, se desacopla el recurso de la aplicación, lo que permite que se pueda intercambiar. |
| 5: Compilación, publicación y ejecución | Cada versión debe aplicar una separación estricta entre las fases de compilación, versión y ejecución. Todos deben etiquetarse con un identificador único y permitir la reversión. Los sistemas de integración continua y entrega continua modernos ayudan a cumplir este principio. |
| 6: Procesos | Cada microservicio debe ejecutarse en su propio proceso, aislado de otros servicios en ejecución. Externalice el estado necesario en un servicio de respaldo, como una caché distribuida o un almacén de datos. |
| 7: Enlace a puerto | Todos los microservicios deben ser independientes de sus interfaces y funcionalidad expuestas en su propio puerto. Al hacerlo se proporciona aislamiento de otros microservicios. |
| 8: Simultaneidad | Cuando hay que aumentar la capacidad, escale horizontalmente los servicios entre varios procesos idénticos (copias), en lugar de escalar verticalmente una sola instancia grande en la máquina más eficaz disponible. Desarrolle la aplicación para que sea simultánea, lo que permite que el escalado horizontal en entornos en la nube se realice sin ningún problema. |
| 9: Descartabilidad | Las instancias de servicio deben poder descartarse. Favorezca el inicio rápido para aumentar las oportunidades de escalabilidad y los apagados correctos, con el fin de salir del sistema en un estado correcto. Este requisito lo cumplen de forma inherente los contenedores de Docker, junto con un orquestador. |
| 10: Paridad desarrollo/producción | Durante el ciclo de vida de la aplicación es preciso que los entornos sean lo más parecidos posible, ya que así se evitan los costosos accesos directos. El uso de contenedores puede contribuir considerablemente a lograr este objetivo, ya que promueven el mismo entorno de ejecución. |
| 11 - Registro | Trate los registros generados por los microservicios como flujos de eventos. Procéselos con un agregador de eventos. Propague los datos de registro a herramientas de minería de datos o de administración de registros como Azure Monitor o Splunk y, finalmente, al archivo a largo plazo. |
| 12: Procesos de administración | Ejecute tareas de administración, como la limpieza de datos o el análisis informático, como procesos puntuales. Use herramientas independientes para invocar a estas tareas desde el entorno de producción, pero de forma independiente a la aplicación. |
En el libro Beyond the Twelve-Factor App, el autor, Kevin Hoffman, detalla los doce factores originales (escrito en 2011). Además, trata tres factores adicionales que reflejan el diseño moderno de aplicaciones en la nube actuales.
| Nuevo factor | Explicación |
|---|---|
| 13: Primero la API | Haga que todo sea un servicio. Asuma que su código lo van a consumir un cliente front-end, una puerta de enlace u otro servicio. |
| 14: Telemetría | En una estación de trabajo, tiene gran visibilidad de cualquier aplicación, así como de su comportamiento. Sin embargo, en la nube, no sucede lo mismo. Asegúrese de que el diseño incluye la recopilación de datos de supervisión, específicos del dominio y del sistema o del estado. |
| 15: Autenticación o autorización | Implemente la identidad desde el principio. Tenga en cuenta las características de RBAC (control de acceso basado en rol) disponibles en nubes públicas. |
Tanto en este capítulo como a lo largo de todo el libro se hará mención a muchos de estos factores.
Marco de arquitectura de Azure
El diseño y la implementación de cargas de trabajo basadas en la nube puede ser complicado, especialmente cuando se implementa la arquitectura nativa de la nube. Microsoft proporciona procedimientos recomendados estándar del sector para que pueden ayudarle tanto a usted como a su equipo a ofrecer soluciones sólidas en la nube.
Microsoft Well-Architected Framework proporciona un conjunto de principios rectores que se pueden usar para mejorar la calidad de cualquier carga de trabajo nativa de la nube. Dicho marco consta de cinco pilares de excelencia de la arquitectura:
| Principios | Descripción |
|---|---|
| Administración de costos | Céntrese en generar un valor incremental desde el principio. Aplique los principios de Build-Measure-Learn para reducir el tiempo de comercialización y evite soluciones que requieran mucho capital. Utilice una estrategia de pago por uso para invertir a medida que escala horizontalmente, en lugar de ofrecer una gran inversión por adelantado. |
| Excelencia operativa | Automatice el entorno y las operaciones para aumentar la velocidad y reducir la posibilidad de error humano. Revierta las actualizaciones de problemas o póngalas al día rápidamente. Implemente la supervisión y el diagnóstico desde el principio. |
| Eficiencia del rendimiento | Satisfaga de forma eficaz las demandas que se colocan en las cargas de trabajo. Favorezca el escalado horizontal y diséñelo en los sistemas. Realice continuamente pruebas de rendimiento y carga para identificar potenciales cuellos de botella. |
| Confiabilidad | Cree cargas de trabajo que sean resistentes y que estén disponibles. La resistencia permite a las cargas de trabajo recuperarse de errores y seguir funcionando. La disponibilidad garantiza a los usuarios el acceso a su carga de trabajo en todo momento. Diseñe aplicaciones para detectar errores y recuperarse de ellos. |
| Seguridad | Implemente la seguridad en todo el ciclo de vida de una aplicación, desde el diseño y la implementación hasta las operaciones. Preste mucha atención a la administración de identidades, el acceso a la infraestructura, la seguridad de las aplicaciones y la soberanía y el cifrado de datos. |
Para empezar, Microsoft proporciona un conjunto de evaluaciones en línea que le ayudan a evaluar las cargas de trabajo actuales en la nube con los cinco pilares bien diseñados.
Microservicios
Los sistemas nativos de la nube utilizan microservicios, un estilo arquitectónico popular para construir aplicaciones modernas.
Los microservicios se crean como un conjunto distribuido de pequeños servicios independientes que interactúan a través de un tejido compartido y comparten las siguientes características:
Cada uno de ellos implementa una funcionalidad empresarial específica dentro de un contexto de dominio mayor.
Todos ellos se desarrollan de forma autónoma y se pueden implementar de forma independiente.
Todos ellos encapsulan su propia tecnología de almacenamiento de datos, dependencias y plataforma de programación.
Cada uno de ellos se ejecuta en su propio proceso y se comunica con otros mediante protocolos de comunicación estándar como HTTP/HTTPS, gRPC, WebSockets o AMQP.
Se unen para formar una aplicación.
La figura 1-4 muestra el contraste entre un enfoque de aplicación monolítica y un enfoque de microservicios. Observe que el monolito se compone de una arquitectura en capas, que se ejecuta en un único proceso. Normalmente consume una base de datos relacional. Sin embargo, el enfoque de microservicios separa la funcionalidad en servicios independientes, cada uno con su propia lógica, estado y datos. Cada microservicio hospeda su propio almacén de datos.

Figura 1-4. Arquitectura monolítica frente a arquitectura de microservicios
Fíjese en la forma en que los microservicios promueven el principio de Procesos de Twelve-Factor Application, que ya se han descrito en el capítulo.
El factor 6 especifica: "Cada microservicio debe ejecutarse en su propio proceso, aislado de otros servicios en ejecución."
¿Por qué microservicios?
Los microservicios proporcionan agilidad.
En este mismo capítulo hemos comparado una aplicación de comercio electrónico creada como monolito con la misma creada con microservicios. En el ejemplo, hemos visto algunas ventajas claras:
Cada microservicio tiene un ciclo de vida autónomo y puede evolucionar de forma independiente e implementarse con frecuencia. No tiene que esperar a que una versión trimestral implemente una nueva característica o actualización. Puede actualizar un área pequeña de una aplicación activa con menos riesgo de que todo el sistema resulte afectado. La actualización se puede realizar sin una reimplementación completa de la aplicación.
Cada microservicio se puede escalar de forma independiente. En lugar de escalar toda la aplicación como una sola unidad, solo se escalan horizontalmente los servicios que requieren más potencia de procesamiento para satisfacer los niveles de rendimiento deseados y los acuerdos de nivel de servicio. El escalado específico proporciona un mayor control del sistema y ayuda a reducir los costos generales a medida que escala partes del sistema, no todo él.
Una excelente guía de referencia para conocer los microservicios es .NET Microservices: Architecture for Containerized .NET Applications. El libro profundiza en el diseño y la arquitectura de microservicios. Es un complemento para una arquitectura de referencia de microservicios de pila completa, que está disponible como descarga gratuita en Microsoft.
Desarrollo de microservicios
Los microservicios se pueden crear en cualquier plataforma de desarrollo moderna.
La plataforma Microsoft .NET es una excelente opción. Es gratis y código abierto, y tiene muchas características integradas que simplifican el desarrollo de microservicios. .NET es multiplataforma. Las aplicaciones se pueden compilar y ejecutar en Windows, macOS y la mayoría de las distribuciones de Linux.
.NET es muy eficaz y sus resultados en las comparaciones con Node.js y otras plataformas competidoras son buenos. Resulta interesante indicar que TechEmpower llevó a cabo un amplio conjunto de pruebas comparativas de rendimiento en muchas plataformas y marcos de aplicaciones web. .NET ha puntuado en los 10 principales aspectos que se analizaron muy por encima de Node.js y otras plataformas competidoras.
Microsoft y la comunidad de .NET de GitHub mantienen .NET.
Desafíos de los microservicios
Aunque los microservicios nativos de la nube distribuidos pueden proporcionar una gran agilidad y velocidad, presentan muchos desafíos:
Comunicación
¿Cómo se comunicarán las aplicaciones cliente front-end con microservicios principales de back-end? ¿Permitirá la comunicación directa? O bien, ¿podría abstraer los microservicios de back-end con una fachada de puerta de enlace que proporcione flexibilidad, control y seguridad?
¿Cómo se comunican los microservicios back-end entre ellos? ¿Permitirá llamadas HTTP directas que puedan aumentar el acoplamiento y afectar al rendimiento y a la agilidad? ¿O podría considerar la posibilidad de usar una mensajería desacoplada con tecnologías de cola y tema?
La comunicación se trata en el capítulo Patrones de comunicación nativos de la nube.
Resistencia
Una arquitectura de microservicios mueve el sistema de la comunicación de red In-Process a Out-Of-Process. En una arquitectura distribuida, ¿qué ocurre cuando el servicio B no responde a una llamada de red procedente del servicio A? O ¿qué ocurre cuando el servicio C deja de estar disponible temporalmente y se bloquean otros servicios que lo llaman?
La resistencia se trata en el capítulo Resistencia nativa de la nube.
Datos distribuidos
Por diseño, cada microservicio encapsula sus propios datos, y expone las operaciones a través de su interfaz pública. En ese caso, ¿cómo se consultan datos o se implementan transacciones en varios servicios?
Los datos distribuidos se tratan en el capítulo Patrones de datos nativos de la nube.
Secretos
¿Cómo almacenarán y administrarán de forma segura los microservicios tanto los secretos como los datos de configuración confidenciales?
Los secretos se tratan en detalle en Seguridad nativa de la nube.
Administración de la complejidad con Dapr
Dapr es un entorno de ejecución de aplicaciones distribuido de código abierto. Gracias a una arquitectura de componentes que se pueden conectar, simplifica drásticamente los entresijos que hay tras las aplicaciones distribuidas. Proporciona un pegamento dinámico que une cualquier aplicación y las funcionalidades de infraestructura y los componentes preintegrados del runtime de Dapr. En la figura 1-5 se muestra Dapr a 20 000 pies.
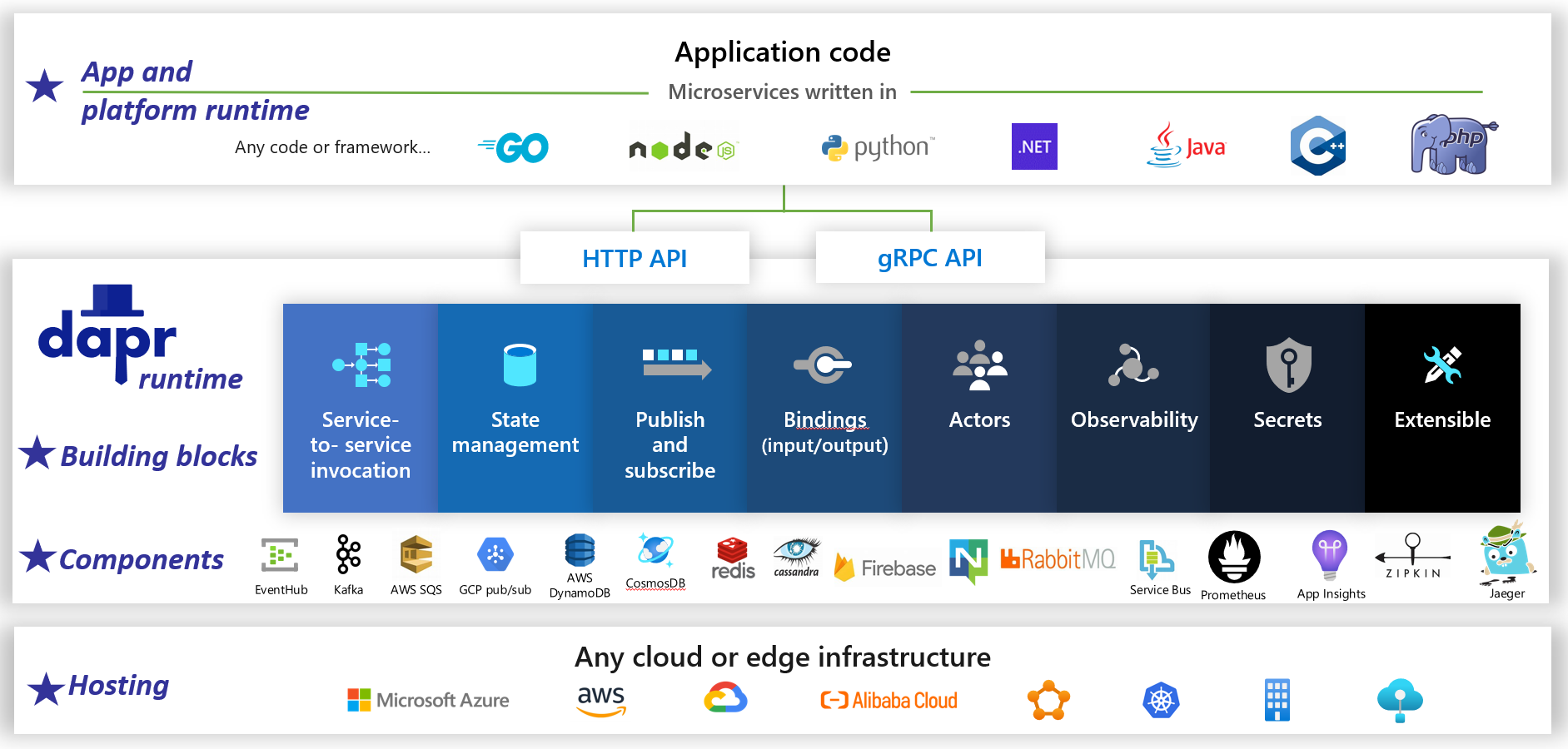 Figura 1-5. Dapr a 20 000 pies.
Figura 1-5. Dapr a 20 000 pies.
Fíjese que en la primera fila de la imagen, Dapr proporciona los SDK específicos del lenguaje de varias plataformas de desarrollo conocidas. Dapr v1 incluye compatibilidad con .NET, Go, Node.js, Python, PHP, Java y JavaScript.
Aunque los SDK específicos del lenguaje facilitan su trabajo a los desarrolladores, Dapr es independiente de la plataforma. Visto más de cerca, el modelo de programación de Dapr expone funcionalidades a través de protocolos de comunicación HTTP/gRPC estándar. Cualquier plataforma de programación puede llamar a Dapr a través de sus API nativas HTTP y gRPC.
Los cuadros azules del centro de la imagen son los bloques de creación de Dapr. Cada uno de ellos expone código estructural pregenerado para una funcionalidad de aplicación distribuida que la aplicación puede consumir.
La fila de componentes representa un gran conjunto de componentes de infraestructura predefinidos que la aplicación puede consumir. Piense en los componentes como código de infraestructura que no tiene que escribir.
En la fila de abajo se resalta la portabilidad de Dapr y los entornos en los que se puede ejecutar.
De cara al futuro, Dapr tiene el potencial de tener un profundo impacto en el desarrollo de aplicaciones nativas de la nube.
Contenedores
Es habitual escuchar el término contenedor en cualquier conversación sobre elementos nativos de la nube. En el libro Cloud Native Patterns, su autor, Cornelia Davis, indica que los contenedores son un gran habilitador de software nativo en la nube". Cloud Native Computing Foundation coloca la contenedorización de microservicios como primer paso en su mapa de elementos nativos de la nube (una guía para las empresas que comienzan su recorrido por los elementos nativos de la nube).
{kind=link}
La contenedorización de microservicios es una labor simple y directa. El código, sus dependencias y el runtime se empaquetan en un binario denominado imagen de contenedor. Las imágenes se almacenan en un registro de contenedor, que actúa como repositorio o biblioteca para imágenes. Los registros se pueden ubicar en el equipo de desarrollo, en el centro de datos o en una nube pública. Docker mantiene un registro público a través de Docker Hub. La nube de Azure cuenta con un registro de contenedor privado para almacenar imágenes de contenedor cerca de las aplicaciones en la nube que las ejecutarán.
Cuando una aplicación se inicia o escala, la imagen de contenedor se transforma en una instancia de contenedor en ejecución. La instancia se ejecuta en cualquier equipo que tenga instalado un motor en tiempo de ejecución de contenedor. Puede haber tantas instancias del servicio en contenedor como sean necesarias.
En la figura 1-6 se muestran tres microservicios diferentes, cada uno de ellos en su propio contenedor, y todos ellos se ejecutan en un único host.
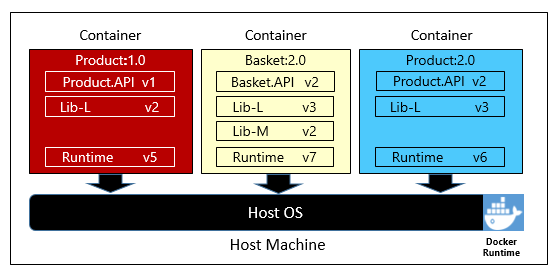
Figura 1-6. Varios contenedores ejecutándose en un host de contenedor.
Fíjese en la forma en que cada contenedor mantiene su propio conjunto de dependencias y runtime, que pueden ser diferentes de los demás. Aquí se ven diferentes versiones del microservicio Product que se ejecutan en el mismo host. Cada contenedor comparte un sector del sistema operativo de host subyacente, la memoria y el procesador, pero todos están aislados de los demás.
Fíjese en la forma en que el modelo de contenedor adopta el principio Dependencias de Twelve-Factor Application.
El factor 2 especifica que "Cada microservicio aísla y empaqueta sus propias dependencias y realiza los cambios sin que ello afecte a todo el sistema."
Los contenedores admiten cargas de trabajo de Linux y Windows. La nube de Azure utiliza abiertamente ambas. Resulta interesante que sea Linux, no Windows Server, el que se ha convertido en el sistema operativo más popular en Azure.
Aunque existen varios proveedores de contenedores, Docker ha sido quien se ha llevado la parte más grande del pastel del mercado. La empresa ha sido una gran impulsora del movimiento de contenedores de software. Se ha convertido en el estándar de facto para el empaquetamiento, implementar y ejecutar aplicaciones nativas de nube.
¿Por qué contenedores?
Los contenedores proporcionan portabilidad y garantizan la coherencia entre entornos. Al encapsular todo en un único paquete, aísle el microservicio y sus dependencias de la infraestructura subyacente.
El contenedor se puede implementar en cualquier entorno que hospede el motor en tiempo de ejecución de Docker. Las cargas de trabajo en contenedores también eliminan el gasto que supone configurar previamente cada entorno con marcos, bibliotecas de software y motores en tiempo de ejecución.
Al compartir el sistema operativo subyacente y los recursos del host, los contenedores tienen una superficie mucho menor que las máquinas virtuales completas. Al reducirse el tamaño aumenta la densidad, o el número de microservicios, que un host determinado puede ejecutarse a la vez.
Orquestación de contenedores
Aunque las herramientas como Docker crean imágenes y ejecutan contenedores, también necesita herramientas para administrarlas. La administración de contenedores se realiza con un programa de software especial denominado orquestador de contenedores. Cuando se trabaja a escala con muchos contenedores que se ejecutan de forma independiente, la orquestación es esencial.
En la figura 1-7 se muestran las tareas de administración que automatizan los orquestadores de contenedores.
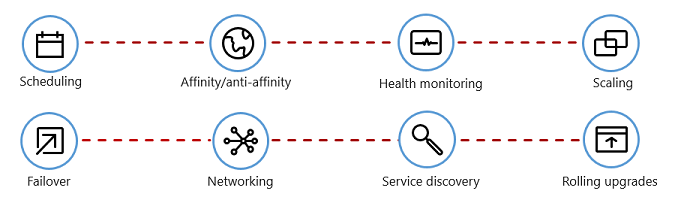
Figura 1-7. Qué hacen los orquestadores de contenedores
En la tabla siguiente se describen las tareas de orquestación comunes.
| Tareas | Explicación |
|---|---|
| Scheduling | Aprovisionamiento automático de instancias de contenedor. |
| Afinidad/antiafinidad | Aprovisione contenedores que estén cerca o lejos unos de otros, lo que ayuda a la disponibilidad y el rendimiento. |
| Supervisión del estado | Detección y corrección de errores de forma automática. |
| Conmutación por error | Aprovisionamiento automático de cualquier instancia con errores en una máquina en buen estado. |
| Ampliación | Agregue o quite automáticamente una instancia de contenedor para satisfacer la demanda. |
| Redes | Administre una superposición de red para la comunicación de los contenedores. |
| Detección de servicios | Habilite los contenedores para que se puedan localizar entre ellos. |
| Actualizaciones sucesivas | Coordine las actualizaciones incrementales con una implementación sin tiempo de inactividad. Revierta automáticamente los cambios problemáticos. |
Tenga en cuenta que los orquestadores de contenedores usan los principios de Descartabilidad y Simultaneidad de Twelve-Factor Application.
El factor 9 especifica que "Las instancias de servicio deben poder descartarse, lo que propicia arranques rápidos y, en consecuencia, aumenta las oportunidades de escalabilidad y los apagados correctos para dejar el sistema en un estado correcto". Los contenedores de Docker junto con un orquestador cumplen inherentemente este requisito".
El factor 8 especifica que "Los servicios se escalan horizontalmente en un gran número de procesos pequeños idénticos (copias), en lugar de escalar verticalmente una sola instancia grande en la máquina más eficaz disponible".
Aunque existen varios orquestadores de contenedores, Kubernetes se ha convertido en el estándar de facto para el mundo nativo de la nube. Es una plataforma portable, ampliable y de código abierto para administrar cargas de trabajo en contenedores.
Podría hospedar su propia instancia de Kubernetes, pero en ese caso sería responsable del aprovisionamiento y la administración de sus recursos (lo que puede resultar complejo). La nube de Azure incluye Kubernetes como servicio administrado. Tanto Azure Kubernetes Service (AKS) como Red Hat OpenShift (ARO) en Azure permiten sacar el máximo partido de las características y la eficacia de Kubernetes como servicio administrado, y sin tener que instalarlo y mantenerlo.
La orquestación de contenedores se trata en detalle en Escalado de aplicaciones nativas de la nube.
Servicios de respaldo
Los sistemas nativos de la nube dependen de muchos recursos auxiliares diferentes, como almacenes de datos, agentes de mensajes, supervisión y servicios de identidad. Estos servicios se conocen como servicios de respaldo.
En la figura 1-8 se muestran muchos servicios de respaldo comunes que consumen los sistemas nativos de la nube.
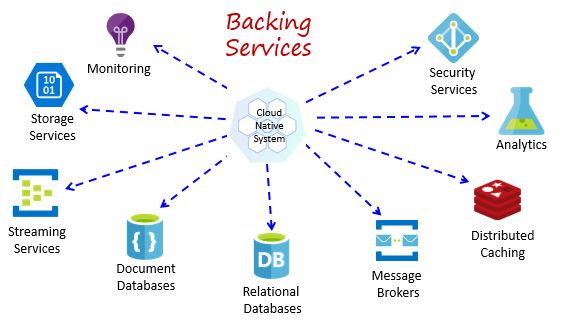
Figura 1-8. Servicios de respaldo comunes
Puede hospedar sus propios servicios de respaldo, pero en ese caso sería el responsable de las licencias, el aprovisionamiento y la administración de esos recursos.
Los proveedores de servicios en la nube ofrecen una gran variedad de servicios de respaldo administrados. De esta forma, en lugar de poseer el servicio, simplemente lo consume. El proveedor opera el recurso a escala y asume la responsabilidad del rendimiento, de la seguridad y del mantenimiento. La supervisión, redundancia y disponibilidad están integradas en el servicio. Los proveedores garantizan no solo el rendimiento del nivel de servicio, sino también el soporte técnico de sus servicios administrados (el cliente abre una incidencia y ellos corrigen el problema).
Los sistemas nativos de la nube favorecen los servicios de respaldo administrados de los proveedores de nube. El ahorro, tanto en tiempo como en mano de obra, pueden ser considerable. El riesgo operativo de hospedar su propios servicios y los problemas que pueden aparecer pueden hacer que llegue a resultar muy caro rápidamente.
Un procedimiento recomendado es tratar los servicios de respaldo como recursos asociados, enlazados dinámicamente a microservicios con información de configuración (una dirección URL y credenciales) almacenada en una configuración externa. Estas instrucciones se pueden encontrar en la sección Twelve-Factor Application de este mismo capítulo.
El factor 4 especifica que los servicios de respaldo "deben exponerse a través de una dirección URL direccionable. Al hacerlo, se desacopla el recurso de la aplicación, por lo que se puede intercambiar."
El factor 3 especifica que "La información de configuración se saca del microservicio y se externaliza a través de una herramienta de administración de configuración que está fuera del código."
Con este patrón, cualquier servicio de respaldo se puede asociar y desasociar sin que sea preciso realizar cambios en el código. Cualquier microservicio se puede promover de QA a un entorno de ensayo. Actualice la configuración del microservicio para que apunte a los servicios de respaldo del almacenamiento provisional e inserte la configuración en el contenedor a través de una variable de entorno.
Los proveedores de servicios en la nube proporcionan API para que pueda comunicarse con sus servicios de respaldo propietarios. Estas bibliotecas encapsulan la complejidad y los entresijos de los servicios propietarios. Sin embargo, la comunicación directa con estas API acoplará estrechamente el código a un servicio de respaldo específico. Esta es una práctica ampliamente aceptada para aislar los detalles de implementación de la API del proveedor. Introduzca una capa de intermediación o una API intermedia, exponiendo operaciones genéricas al código de servicio y encapsulando el código del proveedor dentro de ella. Este acoplamiento flexible permite intercambiar un servicio de respaldo por otro o mover el código a otro entorno en la nube sin tener que realizar cambios en el código del servicio principal. Dapr, del que ya se ha ofrecido información, sigue este modelo con su conjunto de bloques de creación precompilados.
Por último, los servicios de respaldo también promueven el principio de Falta de estado de Twelve-Factor Application, que ya se ha explicado en este mismo capítulo.
El factor 6 especifica que: "Cada microservicio debe ejecutarse en su propio proceso, aislado de otros servicios en ejecución. Externalice el estado necesario en un servicio de respaldo, como una caché distribuida o un almacén de datos".
Los servicios de respaldo se describen en Patrones de datos nativos de la nube y Patrones de comunicación nativos de la nube.
Automatización
Como ha visto, los sistemas nativos de la nube usan microservicios, contenedores y un moderno diseño del sistema para lograr velocidad y agilidad. Pero eso es solo parte de la historia. ¿Cómo se aprovisionan los entornos en la nube en los que se ejecutan estos sistemas? ¿Cómo se implementan rápidamente las características y actualizaciones de las aplicaciones? ¿Cómo se completa la imagen?
Entre en la práctica ampliamente aceptada de Infraestructura como código o IaC.
Con IaC, se automatiza el aprovisionamiento de plataformas y la implementación de aplicaciones. Básicamente, aplica prácticas de ingeniería de software como pruebas y control de versiones a las prácticas de DevOps. La infraestructura y las implementaciones son automatizadas, coherentes y repetibles.
Automatización de infraestructura
Las herramientas como Azure Resource Manager, Azure Bicep, Terraform de HashiCorp y la CLI de Azure permiten crear scripts en forma declarativa en la infraestructura en la nube que necesite. Los nombres de recursos, las ubicaciones, las capacidades y los secretos se parametrizan y dinámicamente. El script tiene versiones y se inserta en el repositorio del control de código fuente como un artefacto del proyecto. El script se invoca para aprovisionar una infraestructura coherente y repetible en entornos del sistema, como control de calidad, ensayo y producción.
En segundo plano, IaC es idempotente, lo que significa que se puede ejecutar el mismo script una y otra vez sin efectos secundarios. Si el equipo necesita realizar cualquier cambio, edite el script y vuelva a ejecutarlo. Solo se ven afectados los recursos actualizados.
En el artículo ¿Qué es la infraestructura como código?, su autor Sam Guckenheimer describe cómo los equipos que implementan IaC pueden ofrecer entornos estables rápidamente y a escala. Evitan la configuración manual de entornos y aplican la coherencia mediante la representación del estado deseado de sus entornos a través del código. Las implementaciones de infraestructura con IaC son repetibles y evitan problemas en tiempo de ejecución causados por el desviado de configuración o dependencias que faltan. Los equipos de DevOps pueden trabajar junto con un conjunto unificado de prácticas y herramientas para ofrecer aplicaciones y su infraestructura de apoyo de forma rápida, confiable y a escala".
Automatización de implementaciones
Twelve-Factor Application, que ya se ha descrito, llama a pasos independientes al transformar el código completado en una aplicación en ejecución.
El factor 5 especifica que "Cada versión debe aplicar una separación estricta entre las fases de compilación, versión y ejecución. Cada una de ellas debe etiquetarse con un identificador único y permitir la reversión".
Los sistemas de integración continua y entrega continua modernos ayudan a cumplir este principio. Proporcionan pasos independientes para la compilación y entrega que ayudan a garantizar un código coherente y de calidad que esté disponible para los usuarios.
En la figura 1-9 se muestra la separación en el proceso de implementación.
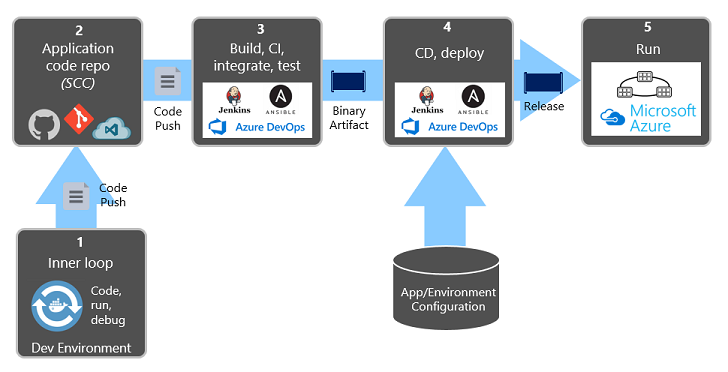
Figura 1-9. Pasos de implementaciones en una canalización de integración continua y entrega continua
En la ilustración anterior, preste especial atención a la separación de tareas:
- El desarrollador crea una característica en su entorno de desarrollo, para lo que realiza una iteración en lo que se denomina el "bucle interno" de codificación, ejecución y depuración.
- Tras finalizar, el código se inserta en un repositorio de código, como GitHub, Azure DevOps o BitBucket.
- Dicha inserción desencadena una fase de compilación que transforma el código en un artefacto binario. El trabajo se implementa con una canalización de integración continua (CI). Compila, prueba y empaqueta automáticamente la aplicación.
- En la fase de lanzamiento, se toma el artefacto binario, se aplica información de configuración externa del entorno y de la aplicación y se genera una versión inmutable. La versión se implementa en un entorno especificado. El trabajo se implementa con una canalización de entrega continua (CD). Todas las versiones deben poder identificarse. Por ejemplo, se debe poder afirmar: "Esta implementación ejecuta la versión 2.1.1 de la aplicación".
- Por último, la característica publicada se ejecuta en el entorno de ejecución de destino. Las versiones son inmutables, lo que significa que cualquier cambio debe crear una versión.
Mediante la aplicación de estas prácticas, las organizaciones han evolucionado radicalmente la forma de envío del software. Muchos han pasado de las versiones trimestrales a las actualizaciones a petición. El objetivo es detectar los problemas al principio del ciclo de desarrollo, cuando cuesta menos solucionarlos. Cuanto mayor sea la duración entre las integraciones, más costará resolver los problemas. Con la coherencia en el proceso de integración, los equipos pueden confirmar los cambios de código con mayor frecuencia, lo que mejora tanto la colaboración como la calidad del software.
La infraestructura como código y la automatización de implementaciones, junto con GitHub y Azure DevOps, se describen con detalle en DevOps.